Scoren van machine learning-modellen met PREDICT in Microsoft Fabric
Met Microsoft Fabric kunnen gebruikers machine learning-modellen operationeel maken met de schaalbare PREDICT-functie. Deze functie ondersteunt batchgewijs scoren in elke rekenengine. Gebruikers kunnen batchvoorspellingen rechtstreeks genereren vanuit een Microsoft Fabric-notebook of op de itempagina van een bepaald ML-model.
In dit artikel leert u hoe u PREDICT kunt toepassen door zelf code te schrijven of door gebruik te maken van een begeleide gebruikersinterface-ervaring waarmee batchscores voor u worden verwerkt.
Vereisten
Haal een Microsoft Fabric-abonnement op. Of meld u aan voor een gratis proefversie van Microsoft Fabric.
Meld u aan bij Microsoft Fabric.
Gebruik de ervaringswisselaar aan de linkerkant van de startpagina om over te schakelen naar Fabric.

Beperkingen
- De functie PREDICT wordt momenteel ondersteund voor deze beperkte set ML-modelsmaak:
- CatBoost
- Keras
- LightGBM
- ONNX
- Profeet
- PyTorch
- SKLearn
- Spark
- Statsmodels
- TensorFlow
- XGBoost
- PREDICT vereist dat u ML-modellen opslaat in de MLflow-indeling, waarbij de handtekeningen zijn ingevuld
- PREDICT biedt geen ondersteuning voor ML-modellen met multitensor-invoer of -uitvoer
Predict aanroepen vanuit een notebook
PREDICT ondersteunt MLflow-verpakte modellen in het Microsoft Fabric-register. Als er al een getraind en geregistreerd ML-model bestaat in uw werkruimte, kunt u doorgaan naar stap 2. Zo niet, dan biedt stap 1 voorbeeldcode om u te begeleiden bij het trainen van een voorbeeld van een logistiek regressiemodel. U kunt dit model gebruiken om batchvoorspellingen te genereren aan het einde van de procedure.
Train een ML-model en registreer het bij MLflow. In het volgende codevoorbeeld wordt de MLflow-API gebruikt om een machine learning-experiment te maken en vervolgens een MLflow-uitvoering te starten voor een logistiek regressiemodel van scikit-learn. De modelversie wordt vervolgens opgeslagen en geregistreerd in het Microsoft Fabric-register. Ga naar het trainen van ML-modellen met scikit-learn-resource voor meer informatie over trainingsmodellen en het bijhouden van uw eigen experimenten.
import mlflow import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.datasets import load_diabetes from mlflow.models.signature import infer_signature mlflow.set_experiment("diabetes-demo") with mlflow.start_run() as run: lr = LogisticRegression() data = load_diabetes(as_frame=True) lr.fit(data.data, data.target) signature = infer_signature(data.data, data.target) mlflow.sklearn.log_model( lr, "diabetes-model", signature=signature, registered_model_name="diabetes-model" )Laden in testgegevens als een Spark DataFrame. Als u batchvoorspellingen wilt genereren met het ML-model dat in de vorige stap is getraind, hebt u testgegevens nodig in de vorm van een Spark DataFrame. Vervang in de volgende code de
testvariabele waarde door uw eigen gegevens.# You can substitute "test" below with your own data test = spark.createDataFrame(data.frame.drop(['target'], axis=1))Maak een
MLFlowTransformerobject om het ML-model te laden voor deductie. Als u eenMLFlowTransformerobject wilt maken om batchvoorspellingen te genereren, moet u deze acties uitvoeren:- geef de
testDataFrame-kolommen op die u nodig hebt als modelinvoer (in dit geval allemaal) - kies een naam voor de nieuwe uitvoerkolom (in dit geval
predictions) - geef de juiste modelnaam en modelversie op voor het genereren van deze voorspellingen.
Als u uw eigen ML-model gebruikt, vervangt u de waarden voor de invoerkolommen, de naam van de uitvoerkolom, de modelnaam en de modelversie.
from synapse.ml.predict import MLFlowTransformer # You can substitute values below for your own input columns, # output column name, model name, and model version model = MLFlowTransformer( inputCols=test.columns, outputCol='predictions', modelName='diabetes-model', modelVersion=1 )- geef de
Genereer voorspellingen met behulp van de functie PREDICT. Als u de functie PREDICT wilt aanroepen, gebruikt u de Transformer-API, de Spark SQL-API of een door de gebruiker gedefinieerde PySpark-functie (UDF). In de volgende secties ziet u hoe u batchvoorspellingen genereert met de testgegevens en het ML-model dat in de vorige stappen is gedefinieerd, met behulp van de verschillende methoden om de functie PREDICT aan te roepen.
VOORSPELLEN met de Transformer-API
Met deze code wordt de functie PREDICT aangeroepen met de Transformer-API. Als u uw eigen ML-model gebruikt, vervangt u de waarden voor het model en testgegevens.
# You can substitute "model" and "test" below with values
# for your own model and test data
model.transform(test).show()
VOORSPELLEN met de Spark SQL-API
Met deze code wordt de functie PREDICT aangeroepen met de Spark SQL-API. Als u uw eigen ML-model gebruikt, vervangt u de waarden voor en model_namemodel_versionvervangt u de waarden door featuresde kolom modelnaam, modelversie en functiekolommen.
Notitie
Het gebruik van de Spark SQL-API voor het genereren van voorspellingen vereist nog steeds het maken van een MLFlowTransformer object (zoals wordt weergegeven in stap 3).
from pyspark.ml.feature import SQLTransformer
# You can substitute "model_name," "model_version," and "features"
# with values for your own model name, model version, and feature columns
model_name = 'diabetes-model'
model_version = 1
features = test.columns
sqlt = SQLTransformer().setStatement(
f"SELECT PREDICT('{model_name}/{model_version}', {','.join(features)}) as predictions FROM __THIS__")
# You can substitute "test" below with your own test data
sqlt.transform(test).show()
VOORSPELLEN met een door de gebruiker gedefinieerde functie
Met deze code wordt de functie PREDICT aangeroepen met een PySpark UDF. Als u uw eigen ML-model gebruikt, vervangt u de waarden voor het model en de functies.
from pyspark.sql.functions import col, pandas_udf, udf, lit
# You can substitute "model" and "features" below with your own values
my_udf = model.to_udf()
features = test.columns
test.withColumn("PREDICT", my_udf(*[col(f) for f in features])).show()
PREDICT-code genereren op de itempagina van een ML-model
Op de itempagina van elk ML-model kunt u een van deze opties kiezen om batchvoorspelling te starten voor een specifieke modelversie, met de functie PREDICT:
- Kopieer een codesjabloon naar een notebook en pas de parameters zelf aan
- Een begeleide ui-ervaring gebruiken om PREDICT-code te genereren
Een begeleide gebruikersinterface-ervaring gebruiken
In de begeleide gebruikersinterface wordt u begeleid bij de volgende stappen:
- De brongegevens selecteren voor scoren
- De gegevens correct toewijzen aan de invoer van uw ML-model
- Geef de bestemming op voor de uitvoer van uw model
- Een notebook maken waarin PREDICT wordt gebruikt om voorspellingsresultaten te genereren en op te slaan
Als u de begeleide ervaring wilt gebruiken,
Navigeer naar de itempagina voor een bepaalde ML-modelversie.
Selecteer dit model toepassen in de vervolgkeuzelijst Deze versie toepassen in de wizard.

Bij de stap Invoertabel selecteren wordt het venster ML-modelvoorspellingen toepassen geopend.
Selecteer een invoertabel uit een lakehouse in uw huidige werkruimte.

Selecteer Volgende om naar de stap Invoerkolommen toewijzen te gaan.
Wijs kolomnamen uit de brontabel toe aan de invoervelden van het ML-model, die worden opgehaald uit de handtekening van het model. U moet een invoerkolom opgeven voor alle vereiste velden van het model. Daarnaast moeten de gegevenstypen van de bronkolom overeenkomen met de verwachte gegevenstypen van het model.
Tip
De wizard vult deze toewijzing vooraf in als de namen van de invoertabelkolommen overeenkomen met de kolomnamen die zijn vastgelegd in de ML-modelhandtekening.

Selecteer Volgende om naar de stap Uitvoertabel maken te gaan.
Geef een naam op voor een nieuwe tabel in het geselecteerde lakehouse van uw huidige werkruimte. In deze uitvoertabel worden de invoerwaarden van uw ML-model opgeslagen en worden de voorspellingswaarden aan die tabel toegevoegd. De uitvoertabel wordt standaard gemaakt in hetzelfde lakehouse als de invoertabel. U kunt het doel lakehouse wijzigen.

Selecteer Volgende om naar de stap Uitvoerkolommen toewijzen te gaan.
Gebruik de opgegeven tekstvelden om de kolommen van de uitvoertabel een naam te geven waarin de voorspellingen van het ML-model worden opgeslagen.

Selecteer Volgende om naar de stap Notitieblok configureren te gaan.
Geef een naam op voor een nieuw notebook waarmee de gegenereerde PREDICT-code wordt uitgevoerd. In deze stap wordt een voorbeeld van de gegenereerde code weergegeven. Desgewenst kunt u de code naar het klembord kopiëren en in een bestaand notitieblok plakken.
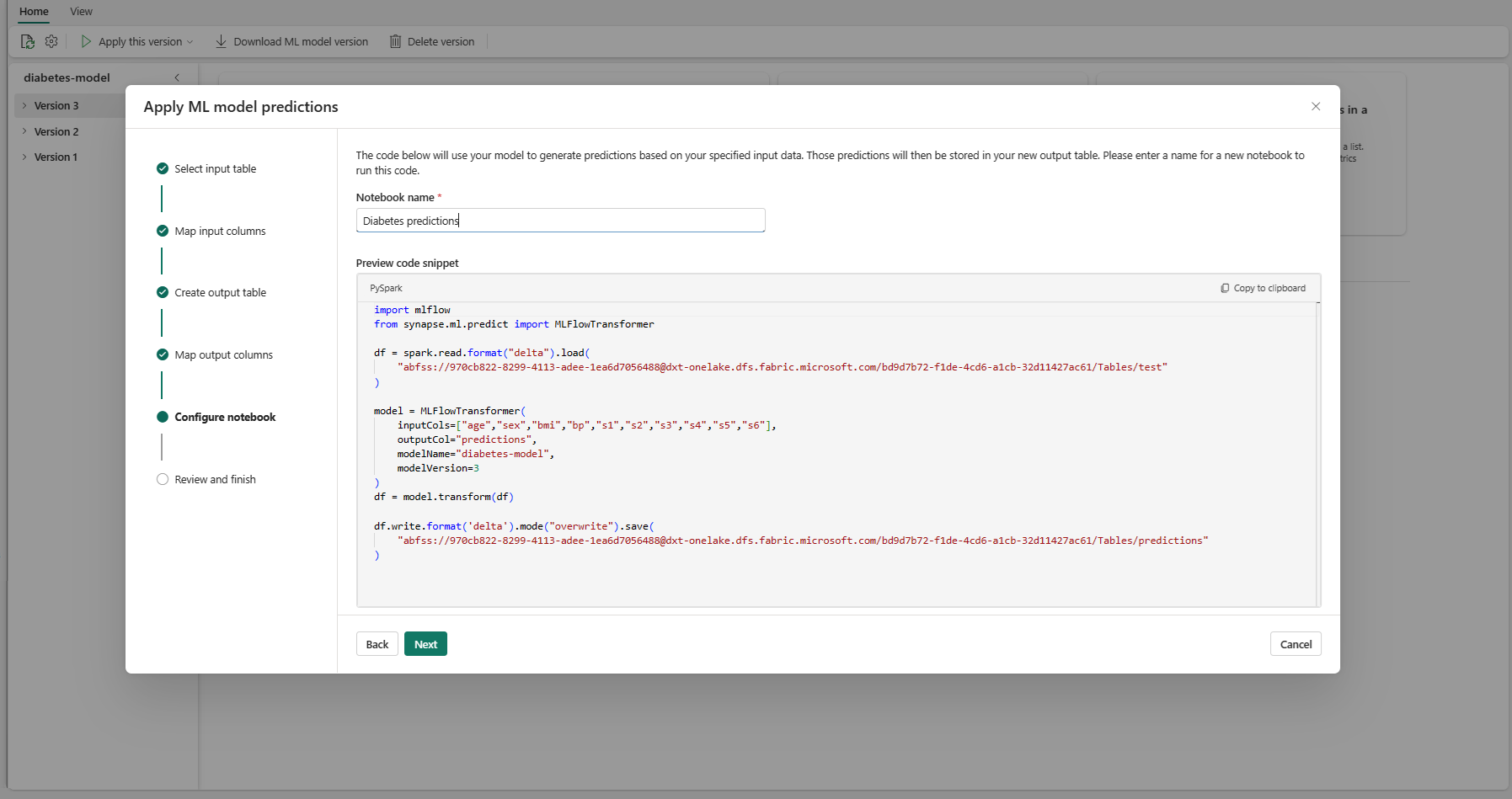
Selecteer Volgende om naar de stap Controleren en voltooien te gaan.
Controleer de details op de overzichtspagina en selecteer Notitieblok maken om het nieuwe notitieblok met de gegenereerde code toe te voegen aan uw werkruimte. U wordt rechtstreeks naar dat notebook geleid, waar u de code kunt uitvoeren om voorspellingen te genereren en op te slaan.
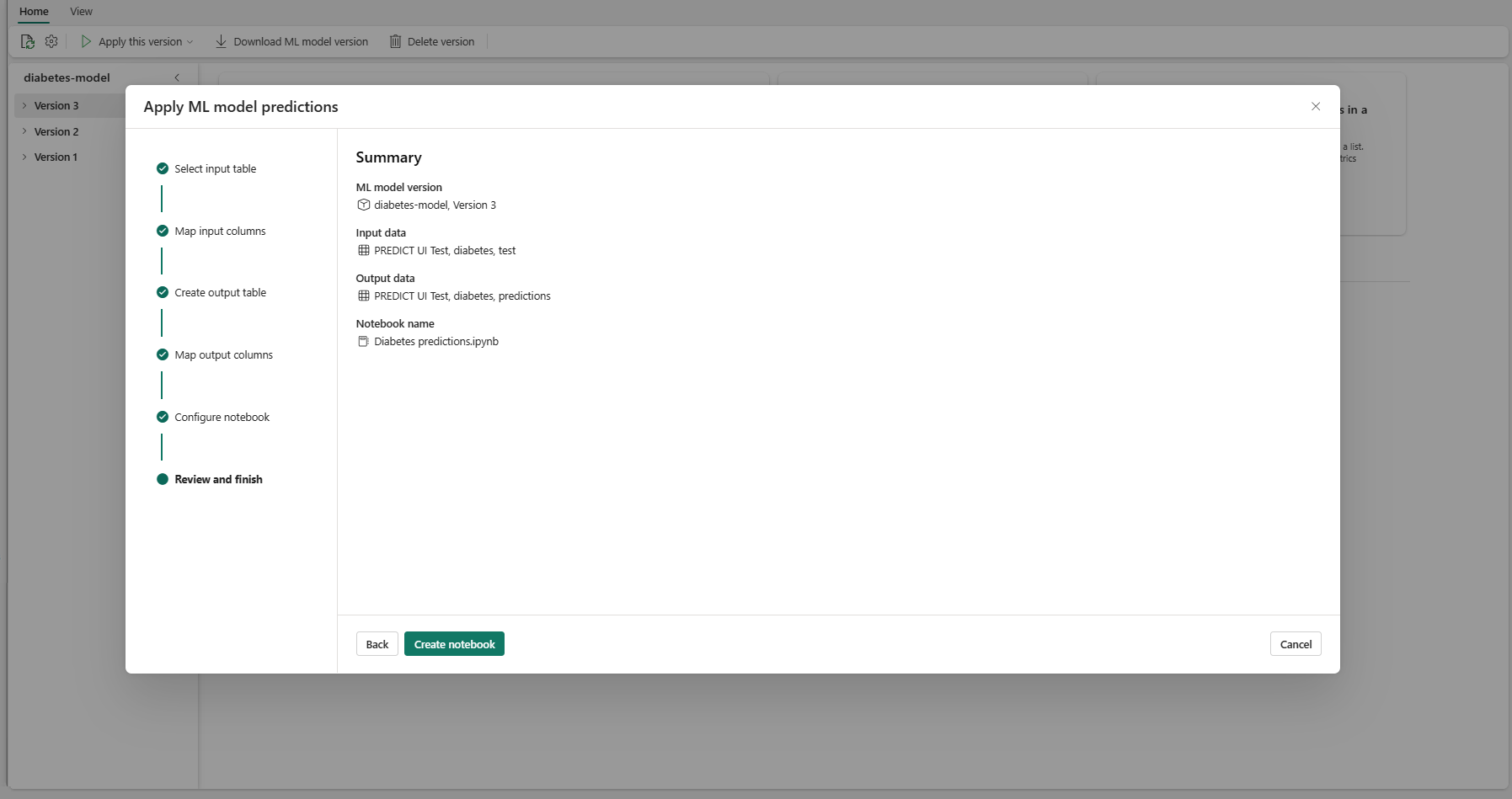







Een aanpasbare codesjabloon gebruiken
Een codesjabloon gebruiken voor het genereren van batchvoorspellingen:
- Ga naar de itempagina voor een bepaalde ML-modelversie.
- Selecteer Code kopiëren die u wilt toepassen in de vervolgkeuzelijst Deze versie toepassen. Met de selectie kunt u een aanpasbare codesjabloon kopiëren.
U kunt deze codesjabloon in een notebook plakken om batchvoorspellingen te genereren met uw ML-model. Als u de codesjabloon wilt uitvoeren, moet u de volgende waarden handmatig vervangen:
-
<INPUT_TABLE>: Het bestandspad voor de tabel die invoer levert aan het ML-model -
<INPUT_COLS>: Een matrix met kolomnamen uit de invoertabel die moet worden ingevoerd in het ML-model -
<OUTPUT_COLS>: Een naam voor een nieuwe kolom in de uitvoertabel waarin voorspellingen worden opgeslagen -
<MODEL_NAME>: De naam van het ML-model dat moet worden gebruikt voor het genereren van voorspellingen -
<MODEL_VERSION>: De versie van het ML-model die moet worden gebruikt voor het genereren van voorspellingen -
<OUTPUT_TABLE>: Het bestandspad voor de tabel waarin de voorspellingen worden opgeslagen

import mlflow
from synapse.ml.predict import MLFlowTransformer
df = spark.read.format("delta").load(
<INPUT_TABLE> # Your input table filepath here
)
model = MLFlowTransformer(
inputCols=<INPUT_COLS>, # Your input columns here
outputCol=<OUTPUT_COLS>, # Your new column name here
modelName=<MODEL_NAME>, # Your ML model name here
modelVersion=<MODEL_VERSION> # Your ML model version here
)
df = model.transform(df)
df.write.format('delta').mode("overwrite").save(
<OUTPUT_TABLE> # Your output table filepath here
)