Incrementeel vernieuwen in Dataflow Gen2 (preview)
In dit artikel introduceren we incrementele gegevensvernieuwing in Dataflow Gen2 voor de Data Factory van Microsoft Fabric. Wanneer u gegevensstromen gebruikt voor gegevensopname en -transformatie, zijn er scenario's waarin u specifiek alleen nieuwe of bijgewerkte gegevens moet vernieuwen, met name naarmate uw gegevens blijven groeien. Met de functie incrementeel vernieuwen wordt deze behoefte aangepakt door u de vernieuwingstijden te beperken, de betrouwbaarheid te verbeteren door langdurige bewerkingen te voorkomen en het resourcegebruik te minimaliseren.
Vereisten
Als u incrementeel vernieuwen wilt gebruiken in Dataflow Gen2, moet u voldoen aan de volgende vereisten:
- U moet een Fabric-capaciteit hebben.
- Uw gegevensbron ondersteunt vouwen (aanbevolen) en moet een datum/datum/datum/tijd-kolom bevatten die kan worden gebruikt om de gegevens te filteren.
- U moet een gegevensbestemming hebben die ondersteuning biedt voor incrementeel vernieuwen. Ga naar Destination Support voor meer informatie.
- Voordat u aan de slag gaat, moet u ervoor zorgen dat u de beperkingen van incrementeel vernieuwen hebt gecontroleerd. Ga naar Beperkingen voor meer informatie.
Doelondersteuning
De volgende gegevensbestemmingen worden ondersteund voor incrementeel vernieuwen:
- Infrastructuurwarehouse
- Azure SQL Database
- Azure Synapse Analytics
Andere bestemmingen, zoals Lakehouse, kunnen worden gebruikt in combinatie met incrementeel vernieuwen met behulp van een tweede query die verwijst naar de gefaseerde gegevens om de gegevensbestemming bij te werken. Op deze manier kunt u incrementeel vernieuwen nog steeds gebruiken om de hoeveelheid gegevens te verminderen die moet worden verwerkt en opgehaald uit het bronsysteem. Maar u moet een volledige vernieuwing uitvoeren van de gefaseerde gegevens naar de gegevensbestemming.
Incrementeel vernieuwen gebruiken
Maak een nieuwe Dataflow Gen2 of open een bestaande Dataflow Gen2.
Maak in de gegevensstroomeditor een nieuwe query waarmee de gegevens die u incrementeel wilt vernieuwen, worden opgehaald.
Controleer het voorbeeld van de gegevens om ervoor te zorgen dat de query gegevens retourneert die een kolom DateTime, Date of DateTimeZone bevatten die u kunt gebruiken om de gegevens te filteren.
Zorg ervoor dat de query volledig wordt gevouwen, wat betekent dat de query volledig naar het bronsysteem wordt gepusht. Als de query niet volledig wordt gevouwen, moet u de query wijzigen zodat deze volledig wordt gevouwen. U kunt ervoor zorgen dat de query volledig wordt gevouwen door de querystappen in de queryeditor te controleren.
Klik met de rechtermuisknop op de query en selecteer Incrementeel vernieuwen.
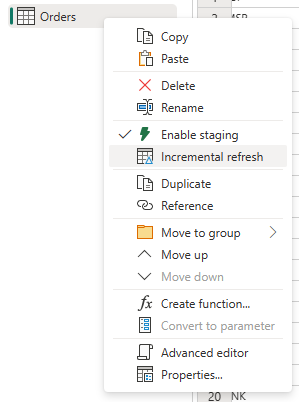
Geef de vereiste instellingen op voor incrementeel vernieuwen.
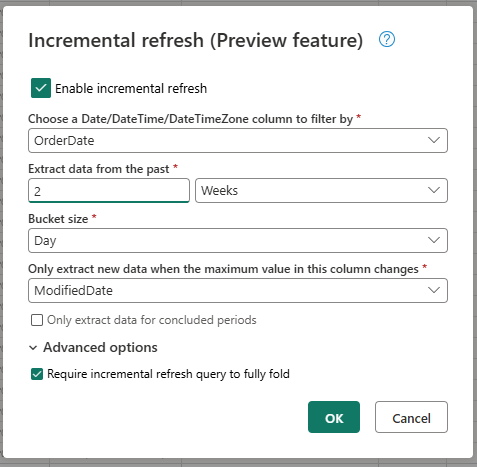
- Kies een Datum/tijd-kolom waarop u wilt filteren.
- Gegevens uit het verleden extraheren.
- Bucketgrootte.
- Extraheer alleen nieuwe gegevens wanneer de maximumwaarde in deze kolom verandert.
Configureer indien nodig de geavanceerde instellingen.
- Incrementele vernieuwingsquery vereisen om volledig te worden gevouwen.
Selecteer OK om de instellingen op te slaan.
Als u wilt, kunt u nu een gegevensbestemming voor de query instellen. Zorg ervoor dat u deze instelling uitvoert vóór de eerste incrementele vernieuwing, omdat anders uw gegevensbestemming alleen de incrementeel gewijzigde gegevens bevat sinds de laatste vernieuwing.
Publiceer de Gegevensstroom Gen2.
Nadat u incrementeel vernieuwen hebt geconfigureerd, worden de gegevens door de gegevensstroom automatisch incrementeel vernieuwd op basis van de instellingen die u hebt opgegeven. De gegevensstroom haalt alleen de gegevens op die zijn gewijzigd sinds de laatste vernieuwing. De gegevensstroom wordt dus sneller uitgevoerd en verbruikt minder resources.
Hoe incrementeel vernieuwen achter de schermen werkt
Incrementeel vernieuwen werkt door de gegevens op te delen in buckets op basis van de kolom DateTime. Elke bucket bevat de gegevens die zijn gewijzigd sinds de laatste vernieuwing. De gegevensstroom weet wat er is gewijzigd door de maximumwaarde in de kolom te controleren die u hebt opgegeven. Als de maximumwaarde voor die bucket is gewijzigd, haalt de gegevensstroom de hele bucket op en vervangt de gegevens in de bestemming. Als de maximumwaarde niet is gewijzigd, haalt de gegevensstroom geen gegevens op. De volgende secties bevatten een algemeen overzicht van hoe incrementeel vernieuwen stapsgewijs werkt.
Eerste stap: De wijzigingen evalueren
Wanneer de gegevensstroom wordt uitgevoerd, worden eerst de wijzigingen in de gegevensbron geëvalueerd. Deze evaluatie wordt uitgevoerd door de maximumwaarde in de kolom DateTime te vergelijken met de maximumwaarde in de vorige vernieuwing. Als de maximumwaarde is gewijzigd of als het de eerste vernieuwing is, markeert de gegevensstroom de bucket als gewijzigd en vermeldt deze voor verwerking. Als de maximumwaarde niet is gewijzigd, slaat de gegevensstroom de bucket over en verwerkt deze niet.
Tweede stap: de gegevens ophalen
De gegevensstroom is nu klaar om de gegevens op te halen. Hiermee worden de gegevens opgehaald voor elke bucket die is gewijzigd. De gegevensstroom voert dit parallel uit om de prestaties te verbeteren. De gegevensstroom haalt de gegevens op uit het bronsysteem en laadt deze in het faseringsgebied. De gegevensstroom haalt alleen de gegevens op die zich binnen het bucketbereik bevindt. Met andere woorden, de gegevensstroom haalt alleen de gegevens op die zijn gewijzigd sinds de laatste vernieuwing.
Laatste stap: De gegevens in de gegevensbestemming vervangen
De gegevensstroom vervangt de gegevens in de bestemming door de nieuwe gegevens. De gegevensstroom gebruikt de replace methode om de gegevens in de bestemming te vervangen. Dat wil gezegd, de gegevensstroom verwijdert eerst de gegevens in de bestemming voor die bucket en voegt vervolgens de nieuwe gegevens in. De gegevensstroom heeft geen invloed op de gegevens die zich buiten het bucketbereik bevinden. Als u dus gegevens hebt in de bestemming die ouder is dan de eerste bucket, heeft de incrementele vernieuwing geen invloed op deze gegevens.
Uitleg over instellingen voor incrementeel vernieuwen
Als u incrementeel vernieuwen wilt configureren, moet u de volgende instellingen opgeven.
Algemene instellingen
De algemene instellingen zijn vereist en geven de basisconfiguratie op voor incrementeel vernieuwen.
Kies een Datum/tijd-kolom waarop u wilt filteren
Deze instelling is vereist en geeft de kolom op die gegevensstromen gebruiken om de gegevens te filteren. Deze kolom moet een kolom DateTime, Date of DateTimeZone zijn. De gegevensstroom gebruikt deze kolom om de gegevens te filteren en haalt alleen de gegevens op die zijn gewijzigd sinds de laatste vernieuwing.
Gegevens uit het verleden extraheren
Deze instelling is vereist en geeft aan hoe ver terug in de tijd de gegevensstroom moet worden geëxtraheerd. Deze instelling wordt gebruikt om de initiële gegevensbelasting op te halen. De gegevensstroom haalt alle gegevens op uit het bronsysteem dat zich binnen het opgegeven tijdsbereik bevindt. Mogelijke waarden zijn:
- x dagen
- x weken
- x maanden
- x kwartalen
- x jaar
Als u bijvoorbeeld 1 maand opgeeft, haalt de gegevensstroom alle nieuwe gegevens op uit het bronsysteem dat zich binnen de afgelopen maand bevindt.
Bucketgrootte
Deze instelling is vereist en geeft de grootte op van de buckets die door de gegevensstroom worden gebruikt om de gegevens te filteren. De gegevensstroom verdeelt de gegevens in buckets op basis van de kolom DateTime. Elke bucket bevat de gegevens die zijn gewijzigd sinds de laatste vernieuwing. De bucketgrootte bepaalt hoeveel gegevens in elke iteratie worden verwerkt. Een kleinere bucket betekent dat de gegevensstroom minder gegevens verwerkt in elke iteratie, maar het betekent ook dat er meer iteraties nodig zijn om alle gegevens te verwerken. Een grotere bucket betekent dat de gegevensstroom meer gegevens in elke iteratie verwerkt, maar dat betekent ook dat er minder iteraties nodig zijn om alle gegevens te verwerken.
Alleen nieuwe gegevens extraheren wanneer de maximumwaarde in deze kolom wordt gewijzigd
Deze instelling is vereist en geeft de kolom op die door de gegevensstroom wordt gebruikt om te bepalen of de gegevens zijn gewijzigd. De gegevensstroom vergelijkt de maximumwaarde in deze kolom met de maximumwaarde in de vorige vernieuwing. Als de maximumwaarde wordt gewijzigd, haalt de gegevensstroom de gegevens op die zijn gewijzigd sinds de laatste vernieuwing. Als de maximumwaarde niet wordt gewijzigd, haalt de gegevensstroom geen gegevens op.
Alleen gegevens extraheren voor geconcludeerde perioden
Deze instelling is optioneel en geeft aan of de gegevensstroom alleen gegevens voor geconcludeerde perioden mag extraheren. Als deze instelling is ingeschakeld, haalt de gegevensstroom alleen gegevens op voor perioden die zijn afgesloten. De gegevensstroom extraheert dus alleen gegevens voor perioden die zijn voltooid en die geen toekomstige gegevens bevatten. Als deze instelling is uitgeschakeld, extraheert de gegevensstroom gegevens voor alle perioden, inclusief perioden die niet zijn voltooid en toekomstige gegevens bevatten.
Als u bijvoorbeeld een datum/tijd-kolom hebt die de datum van de transactie bevat en u alleen volledige maanden wilt vernieuwen, kunt u deze instelling inschakelen in combinatie met de bucketgrootte van month. De gegevensstroom extraheert daarom alleen gegevens voor volledige maanden en extraheert geen gegevens voor onvolledige maanden.
Geavanceerde instellingen
Sommige instellingen worden beschouwd als geavanceerd en zijn niet vereist voor de meeste scenario's.
Incrementele vernieuwingsquery vereisen om volledig te worden gevouwen
Deze instelling is optioneel en geeft aan of de query die wordt gebruikt voor incrementeel vernieuwen volledig moet worden gevouwen. Als deze instelling is ingeschakeld, moet de query die wordt gebruikt voor incrementeel vernieuwen volledig worden gevouwen. Met andere woorden, de query moet volledig naar het bronsysteem worden gepusht. Als deze instelling is uitgeschakeld, hoeft de query die wordt gebruikt voor incrementeel vernieuwen, niet volledig te vouwen. In dit geval kan de query gedeeltelijk naar het bronsysteem worden gepusht. We raden u ten zeerste aan deze instelling in te schakelen om de prestaties te verbeteren om te voorkomen dat onnodige en niet-gefilterde gegevens worden opgehaald.
Beperkingen
Alleen op SQL gebaseerde gegevensbestemmingen worden ondersteund
Op dit moment worden alleen op SQL gebaseerde gegevensbestemmingen ondersteund voor incrementeel vernieuwen. U kunt dus alleen Fabric Warehouse, Azure SQL Database of Azure Synapse Analytics gebruiken als gegevensbestemming voor incrementeel vernieuwen. De reden voor deze beperking is dat deze gegevensbestemmingen ondersteuning bieden voor op SQL gebaseerde bewerkingen die vereist zijn voor incrementeel vernieuwen. We gebruiken verwijder- en invoegbewerkingen om de gegevens in de gegevensbestemming te vervangen, die niet parallel op andere gegevensbestemmingen kunnen worden uitgevoerd.
De gegevensbestemming moet worden ingesteld op een vast schema
De gegevensbestemming moet worden ingesteld op een vast schema, wat betekent dat het schema van de tabel in de gegevensbestemming moet worden opgelost en niet kan worden gewijzigd. Als het schema van de tabel in de gegevensbestemming is ingesteld op dynamisch schema, moet u het wijzigen in een vast schema voordat u incrementeel vernieuwen configureert.
De enige ondersteunde updatemethode in de gegevensbestemming is replace
De enige ondersteunde updatemethode in de gegevensbestemming is replace, wat betekent dat de gegevensstroom de gegevens voor elke bucket in de gegevensbestemming vervangt door de nieuwe gegevens. Gegevens die zich buiten het bucketbereik bevinden, worden echter niet beïnvloed. Dus als u gegevens in de gegevensbestemming hebt die ouder zijn dan de eerste bucket, heeft de incrementele vernieuwing geen invloed op deze gegevens.
Maximum aantal buckets is 50 voor één query en 150 voor de hele gegevensstroom
Het maximum aantal buckets per query dat door de gegevensstroom wordt ondersteund, is 50. Als u meer dan 50 buckets hebt, moet u de bucketgrootte vergroten of het bucketbereik verkleinen om het aantal buckets te verlagen. Voor de hele gegevensstroom is het maximum aantal buckets 150. Als u meer dan 150 buckets in de gegevensstroom hebt, moet u het aantal incrementele vernieuwingsquery's verminderen of de bucketgrootte vergroten om het aantal buckets te verminderen.
Verschillen tussen incrementeel vernieuwen in Dataflow Gen1 en Dataflow Gen2
Tussen Gegevensstroom Gen1 en Gegevensstroom Gen2 zijn er enkele verschillen in hoe incrementeel vernieuwen werkt. In de volgende lijst worden de belangrijkste verschillen uitgelegd tussen incrementeel vernieuwen in Dataflow Gen1 en Dataflow Gen2.
- Incrementeel vernieuwen is nu een eersteklas functie in Dataflow Gen2. In Dataflow Gen1 moest u incrementeel vernieuwen configureren nadat u de gegevensstroom hebt gepubliceerd. In Dataflow Gen2 is incrementeel vernieuwen nu een eersteklas functie die u rechtstreeks in de gegevensstroomeditor kunt configureren. Deze functie maakt het eenvoudiger om incrementeel vernieuwen te configureren en vermindert het risico op fouten.
- In Gegevensstroom Gen1 moest u het historische gegevensbereik opgeven toen u incrementeel vernieuwen hebt geconfigureerd. In Dataflow Gen2 hoeft u het historische gegevensbereik niet op te geven. De gegevensstroom verwijdert geen gegevens uit de bestemming die zich buiten het bucketbereik bevindt. Als u dus gegevens hebt in de bestemming die ouder is dan de eerste bucket, heeft de incrementele vernieuwing geen invloed op deze gegevens.
- In Gegevensstroom Gen1 moest u de parameters voor de incrementele vernieuwing opgeven bij het configureren van incrementele vernieuwing. In Gegevensstroom Gen2 hoeft u de parameters voor incrementeel vernieuwen niet op te geven. De gegevensstroom voegt automatisch de filters en parameters toe als de laatste stap in de query. U hoeft dus niet handmatig de parameters voor incrementeel vernieuwen op te geven.
Veelgestelde vragen
Ik heb een waarschuwing ontvangen dat ik dezelfde kolom heb gebruikt voor het detecteren van wijzigingen en filteren. Wat betekent dit?
Als u een waarschuwing krijgt dat u dezelfde kolom hebt gebruikt voor het detecteren van wijzigingen en filteren, betekent dit dat de kolom die u hebt opgegeven voor het detecteren van wijzigingen ook wordt gebruikt voor het filteren van de gegevens. Dit gebruik wordt niet aanbevolen, omdat dit kan leiden tot onverwachte resultaten. In plaats daarvan raden we u aan een andere kolom te gebruiken voor het detecteren van wijzigingen en het filteren van de gegevens. Als de gegevens tussen buckets worden verplaatst, kan de gegevensstroom de wijzigingen mogelijk niet correct detecteren en mogelijk dubbele gegevens in uw bestemming maken. U kunt deze waarschuwing oplossen met behulp van een andere kolom voor het detecteren van wijzigingen en het filteren van de gegevens. U kunt de waarschuwing ook negeren als u zeker weet dat de gegevens niet veranderen tussen vernieuwingen voor de kolom die u hebt opgegeven.
Ik wil incrementeel vernieuwen gebruiken met een gegevensbestemming die niet wordt ondersteund. Wat kan ik doen?
Als u incrementeel vernieuwen wilt gebruiken met een gegevensbestemming die niet wordt ondersteund, kunt u incrementeel vernieuwen inschakelen voor uw query en een tweede query gebruiken die verwijst naar de gefaseerde gegevens om het gegevensdoel bij te werken. Op deze manier kunt u incrementeel vernieuwen nog steeds gebruiken om de hoeveelheid gegevens te verminderen die moet worden verwerkt en opgehaald uit het bronsysteem, maar u moet een volledige vernieuwing uitvoeren van de gefaseerde gegevens naar de gegevensbestemming. Zorg ervoor dat u het venster en de bucketgrootte juist instelt, omdat we niet garanderen dat de gegevens in fasering buiten het bucketbereik worden bewaard.
Hoe kan ik weten of voor mijn query incrementeel vernieuwen is ingeschakeld?
U kunt zien of incrementeel vernieuwen is ingeschakeld voor uw query door het pictogram naast de query in de gegevensstroomeditor te controleren. Als het pictogram een blauwe driehoek bevat, wordt incrementeel vernieuwen ingeschakeld. Als het pictogram geen blauwe driehoek bevat, is incrementeel vernieuwen niet ingeschakeld.
Mijn bron krijgt te veel aanvragen wanneer ik incrementeel vernieuwen gebruik. Wat kan ik doen?
We hebben een instelling toegevoegd waarmee u het maximum aantal parallelle queryevaluaties kunt instellen. Deze instelling vindt u in de algemene instellingen van de gegevensstroom. Door deze waarde in te stellen op een lager getal, kunt u het aantal aanvragen dat naar het bronsysteem wordt verzonden verminderen. Deze instelling kan helpen het aantal gelijktijdige aanvragen te verminderen en de prestaties van het bronsysteem te verbeteren. Als u het maximum aantal parallelle queryuitvoeringen wilt instellen, gaat u naar de algemene instellingen van de gegevensstroom, gaat u naar het tabblad Schaal en stelt u het maximum aantal parallelle queryevaluaties in. U wordt aangeraden deze limiet niet in te schakelen, tenzij u problemen ondervindt met het bronsysteem.
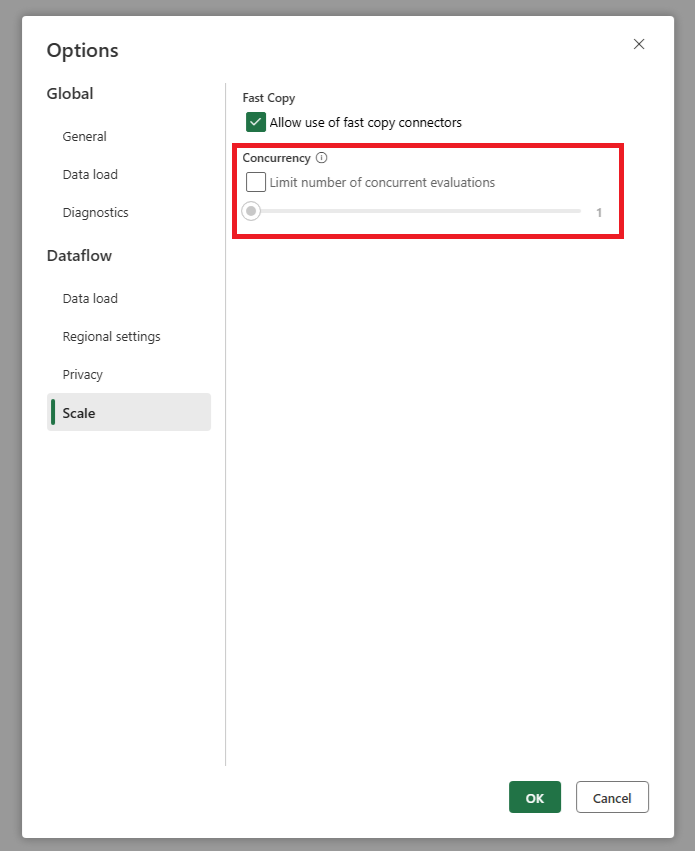
Ik wil incrementeel vernieuwen gebruiken, maar ik zie dat het na inschakelen langer duurt voordat de gegevensstroom is vernieuwd. Wat kan ik doen?
Incrementeel vernieuwen, zoals beschreven in dit artikel, is ontworpen om de hoeveelheid gegevens te verminderen die moeten worden verwerkt en opgehaald uit het bronsysteem. Als het echter langer duurt voordat de gegevensstroom wordt vernieuwd nadat u incrementeel vernieuwen hebt ingeschakeld, kan het zijn dat de extra overhead van het controleren of gegevens zijn gewijzigd en de verwerking van de buckets hoger is dan de tijd die is opgeslagen door minder gegevens te verwerken. In dit geval raden we u aan de instellingen voor incrementeel vernieuwen te bekijken en deze aan te passen aan uw scenario. U kunt bijvoorbeeld de bucketgrootte vergroten om het aantal buckets en de overhead van de verwerking ervan te verminderen. U kunt ook het aantal buckets verminderen door de bucketgrootte te vergroten. Als u na het aanpassen van de instellingen nog steeds lage prestaties ondervindt, kunt u incrementeel vernieuwen uitschakelen en in plaats daarvan een volledige vernieuwing gebruiken, omdat dit mogelijk efficiënter is in uw scenario.