Gegevens transformeren door een Azure HDInsight-activiteit uit te voeren
Met de Azure HDInsight-activiteit in Data Factory voor Microsoft Fabric kunt u de volgende Azure HDInsight-taaktypen indelen:
- Hive-query's uitvoeren
- Een MapReduce-programma aanroepen
- Pig-query's uitvoeren
- Een Spark-programma uitvoeren
- Een Hadoop Stream-programma uitvoeren
Dit artikel bevat een stapsgewijze handleiding waarin wordt beschreven hoe u een Azure HDInsight-activiteit maakt met behulp van de Data Factory-interface.
Vereisten
Om aan de slag te gaan, moet u aan de volgende vereisten voldoen:
- Een tenantaccount met een actief abonnement. Gratis een account maken
- Er wordt een werkruimte gemaakt.
Een Azure HDInsight-activiteit (HDI) toevoegen aan een pijplijn met ui
Maak een nieuwe gegevenspijplijn in uw werkruimte.
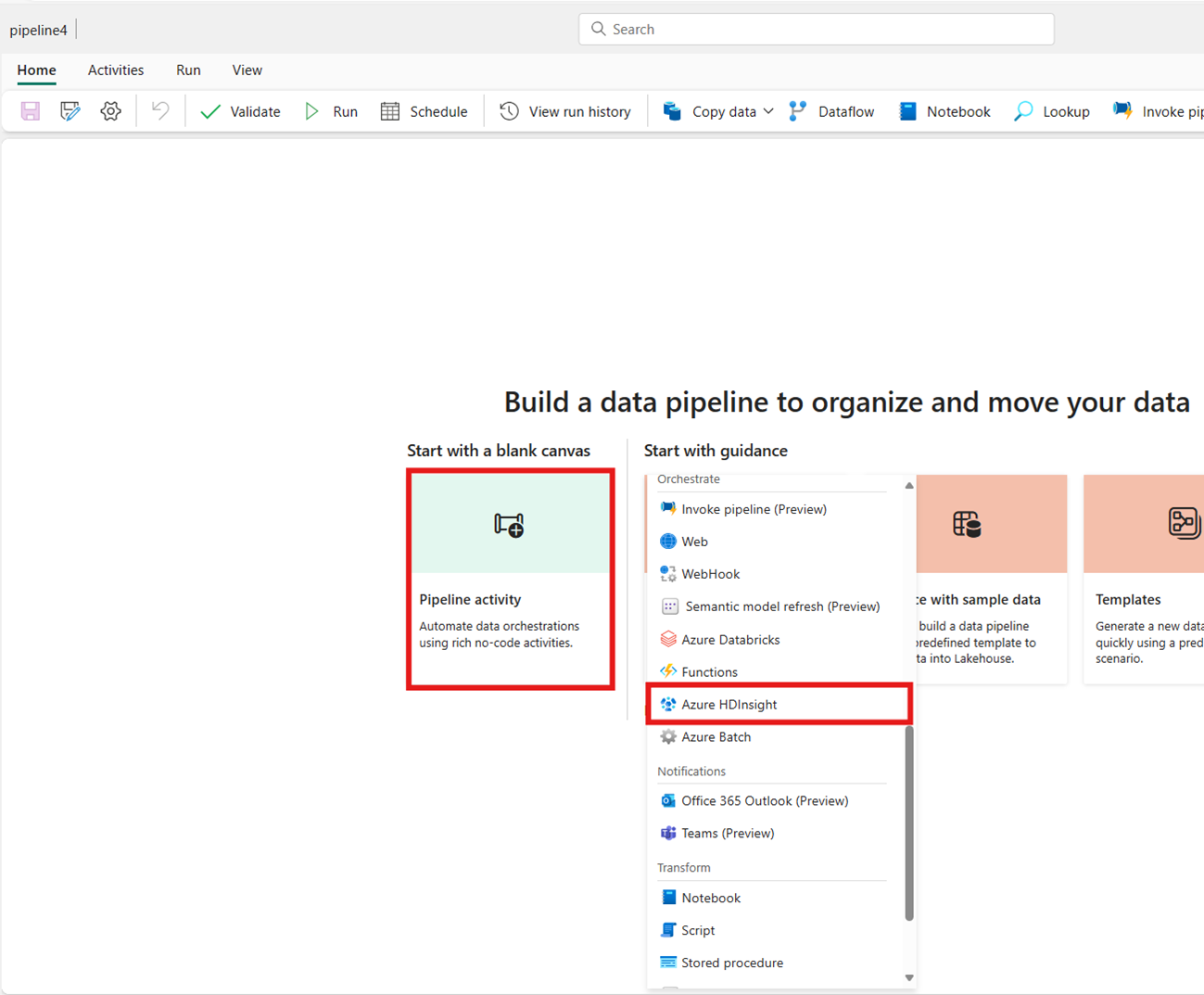
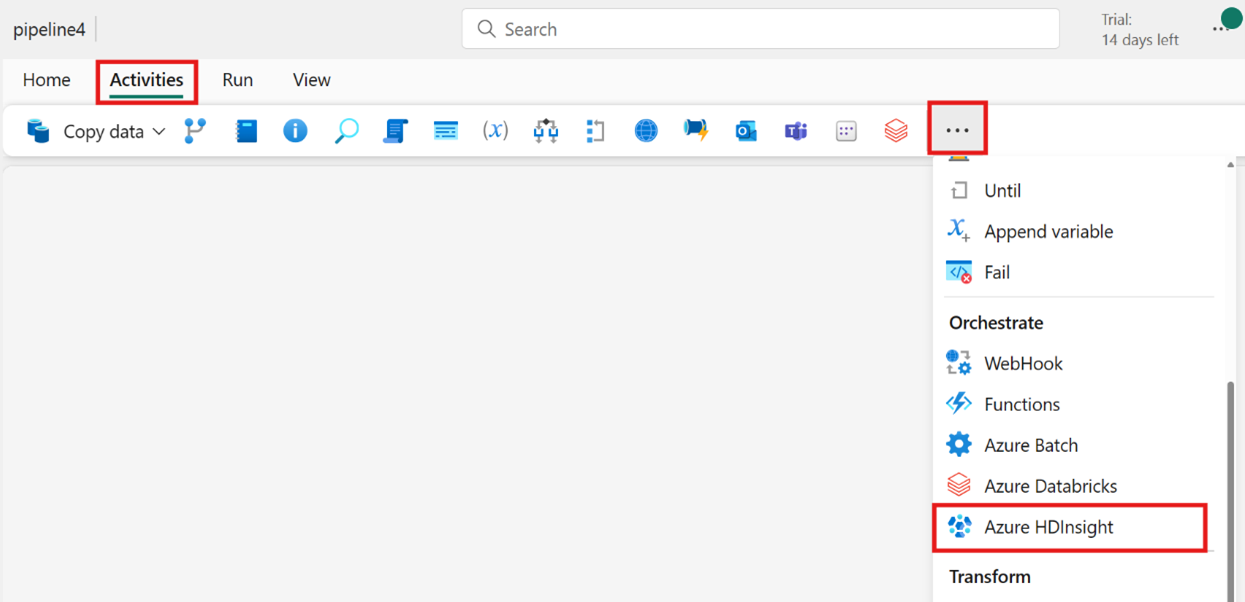
Zoek op de startpagina naar Azure HDInsight en selecteer deze of selecteer de activiteit op de balk Activiteiten om deze toe te voegen aan het pijplijncanvas.
De activiteit maken op basis van de kaart van het startscherm:
De activiteit maken vanuit de activiteitenbalk:
Selecteer de nieuwe Azure HDInsight-activiteit op het canvas van de pijplijneditor als deze nog niet is geselecteerd.
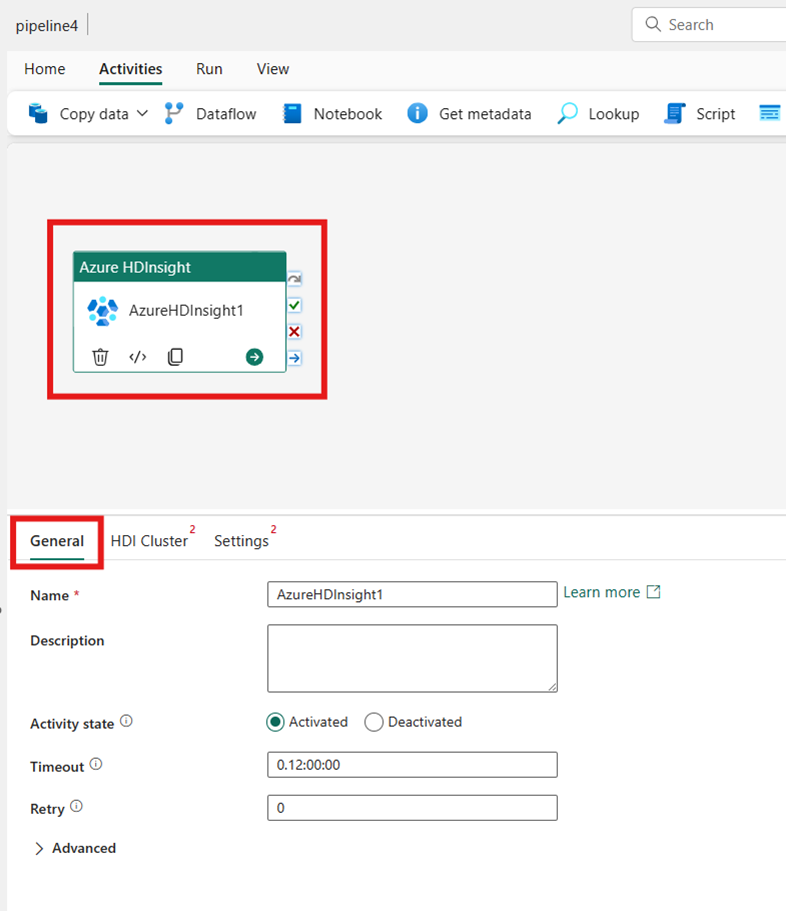
Raadpleeg de richtlijnen voor algemene instellingen voor het configureren van de opties op het tabblad Algemene instellingen .

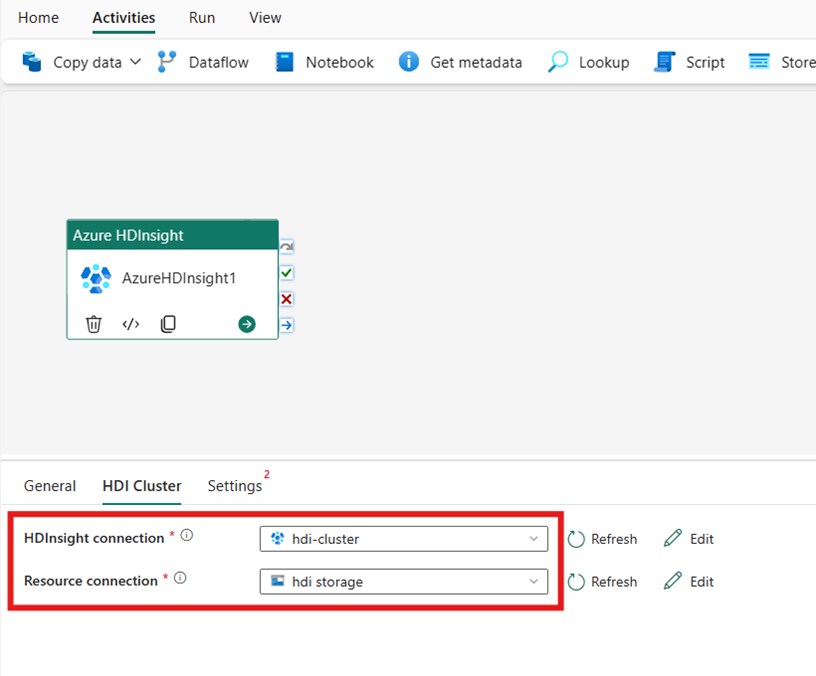
Het HDI-cluster configureren
Selecteer het tabblad HDI-cluster . Vervolgens kunt u een bestaande of een nieuwe HDInsight-verbinding maken.
Kies voor de resourceverbinding de Azure Blob Storage die verwijst naar uw Azure HDInsight-cluster. U kunt een bestaand Blob-archief kiezen of een nieuwe maken.
Instellingen configureren
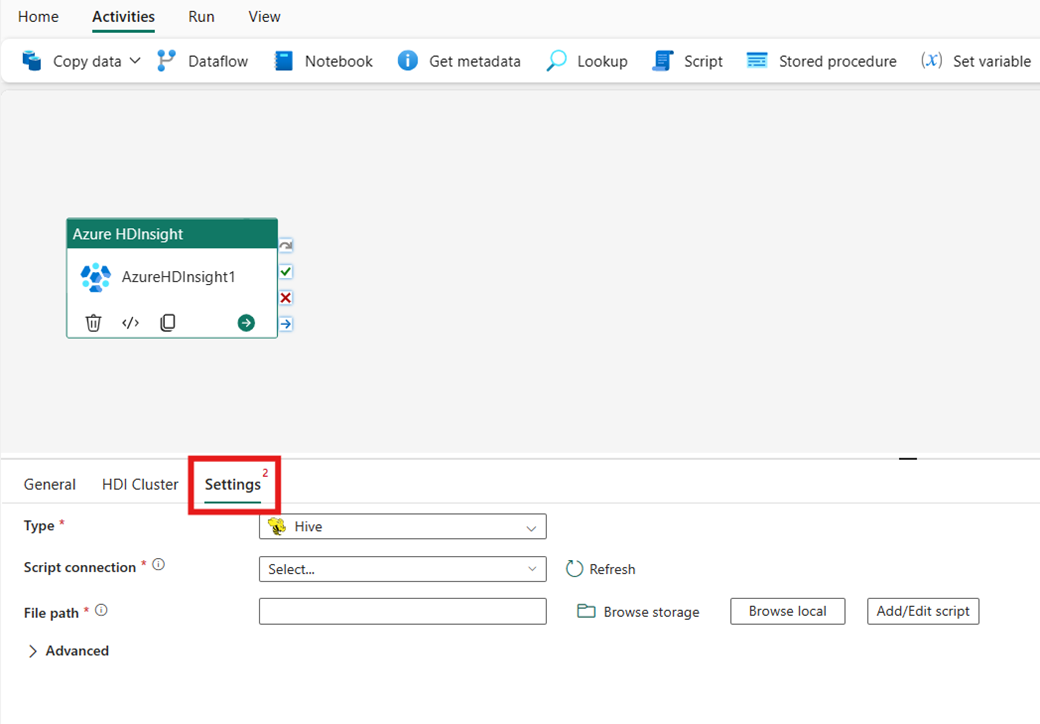
Selecteer het tabblad Instellingen om de geavanceerde instellingen voor de activiteit weer te geven.
Alle geavanceerde clustereigenschappen en dynamische expressies die worden ondersteund in de gekoppelde Azure Data Factory- en Synapse Analytics HDInsight-service , worden nu ook ondersteund in de Azure HDInsight-activiteit voor Data Factory in Microsoft Fabric, onder de sectie Geavanceerd in de gebruikersinterface. Deze eigenschappen ondersteunen eenvoudig te gebruiken aangepaste, geparameteriseerde expressies met dynamische inhoud.
Clustertype
Als u instellingen voor uw HDInsight-cluster wilt configureren, kiest u eerst het type uit de beschikbare opties, waaronder Hive, Kaart reduce, Pig, Spark en Streaming.
Hive
Als u Hive kiest voor Type, wordt met de activiteit een Hive-query uitgevoerd. U kunt desgewenst de scriptverbinding opgeven die verwijst naar een opslagaccount dat het Hive-type bevat. Standaard wordt de opslagverbinding die u hebt opgegeven op het tabblad HDI-cluster gebruikt. U moet opgeven welk bestandspad moet worden uitgevoerd in Azure HDInsight. U kunt desgewenst meer configuraties opgeven in de sectie Geavanceerd , foutopsporingsgegevens, time-out van query's, argumenten, parameters en variabelen.
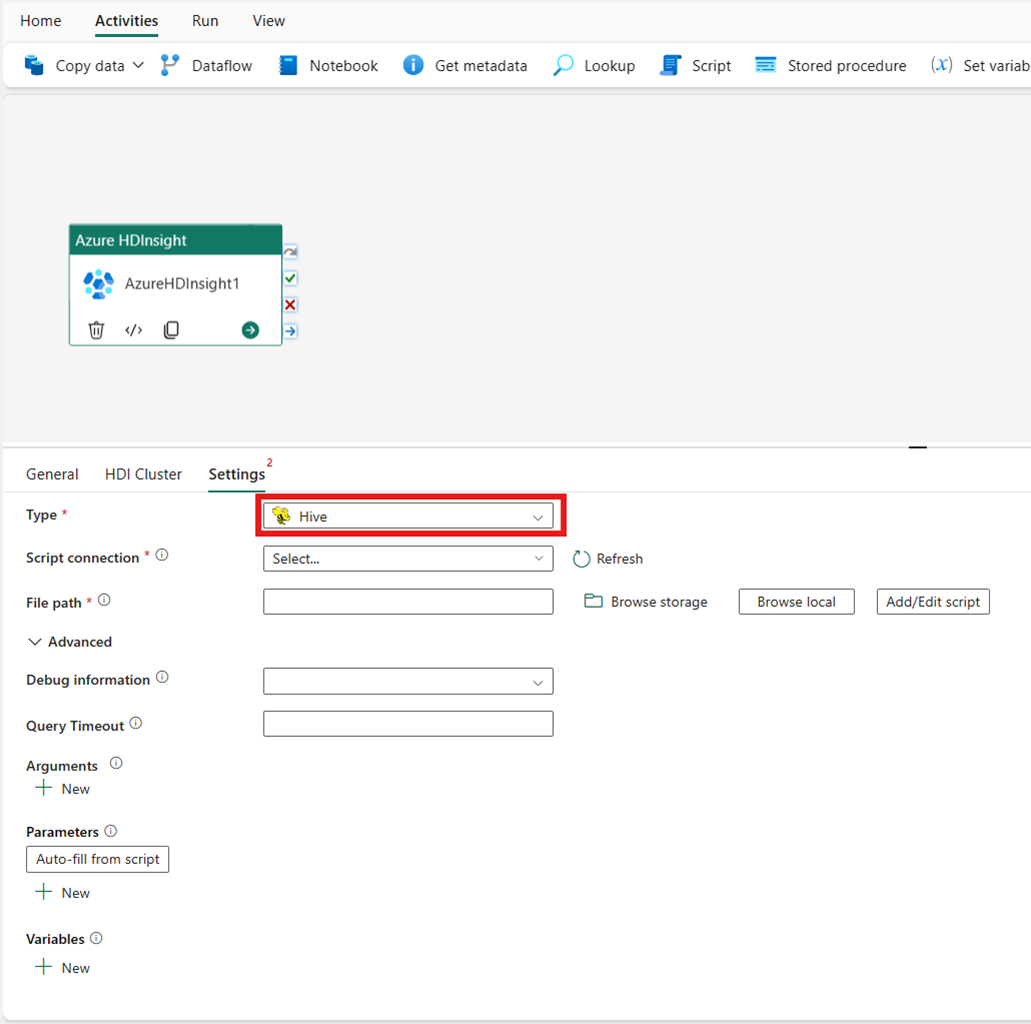
Kaart reduce
Als u Map Reduce voor Type kiest, roept de activiteit een Programma voor Kaart reduce aan. U kunt desgewenst opgeven in de Jar-verbinding die verwijst naar een opslagaccount met het type Toewijzings reduce. Standaard wordt de opslagverbinding die u hebt opgegeven op het tabblad HDI-cluster gebruikt. U moet de klassenaam en het bestandspad opgeven dat moet worden uitgevoerd in Azure HDInsight. U kunt desgewenst meer configuratiedetails opgeven, zoals het importeren van Jar-bibliotheken, foutopsporingsgegevens, argumenten en parameters onder de sectie Geavanceerd .
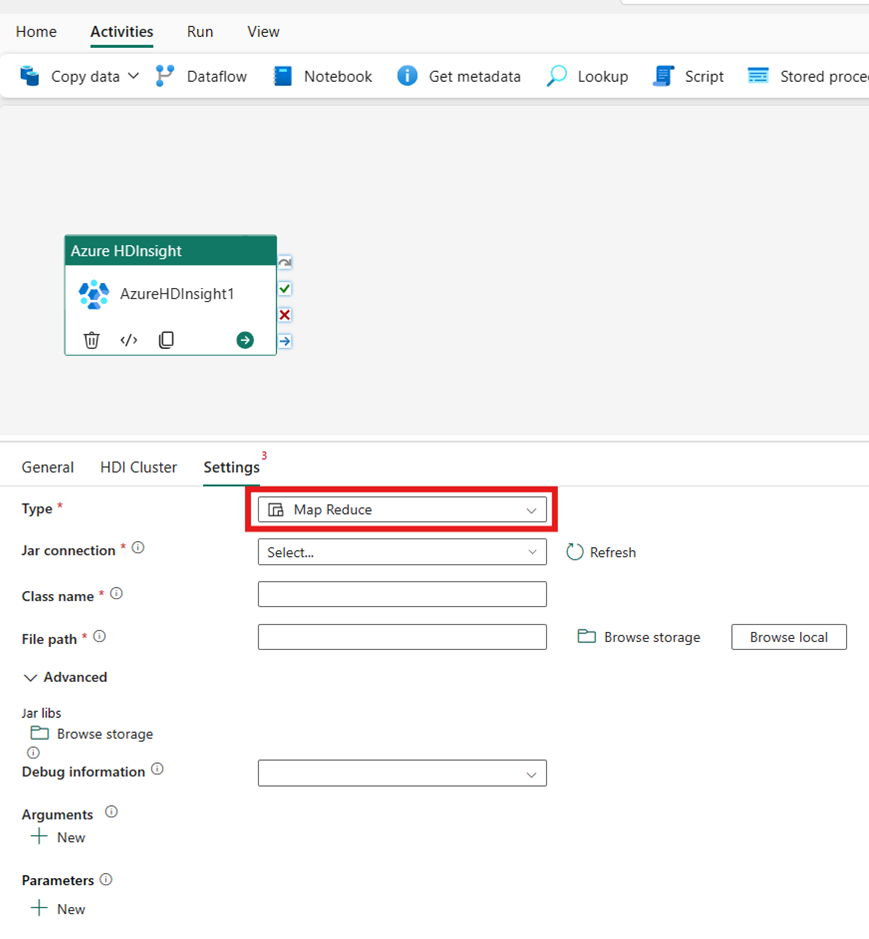
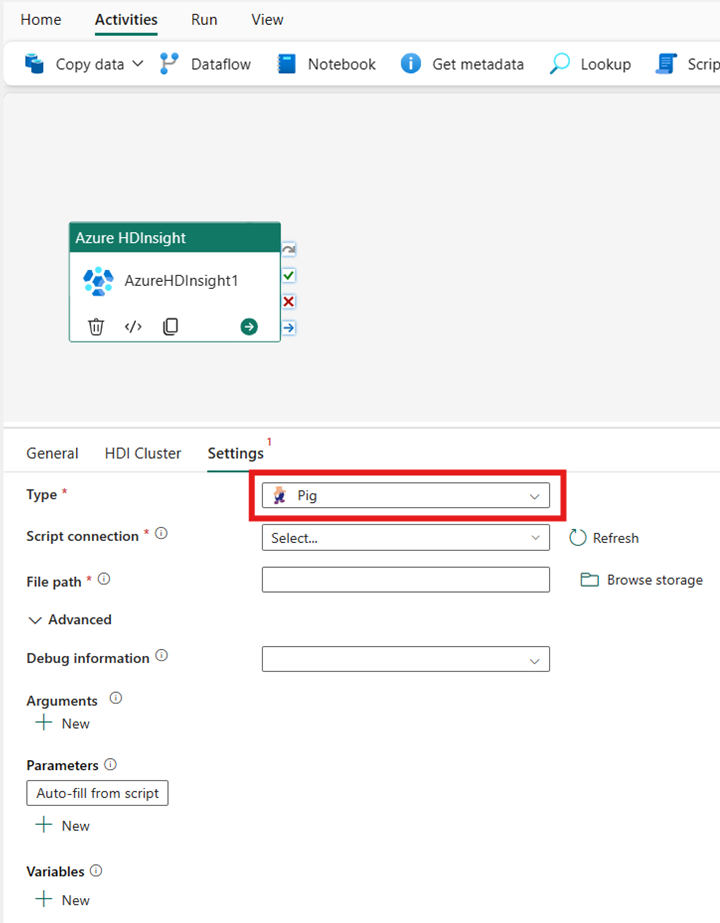
Pig
Als u Pig kiest voor Type, roept de activiteit een Pig-query aan. U kunt desgewenst de scriptverbindingsinstelling opgeven die verwijst naar het opslagaccount dat het pig-type bevat. Standaard wordt de opslagverbinding die u hebt opgegeven op het tabblad HDI-cluster gebruikt. U moet opgeven welk bestandspad moet worden uitgevoerd in Azure HDInsight. U kunt desgewenst meer configuraties opgeven, zoals foutopsporingsgegevens, argumenten, parameters en variabelen in de sectie Geavanceerd .
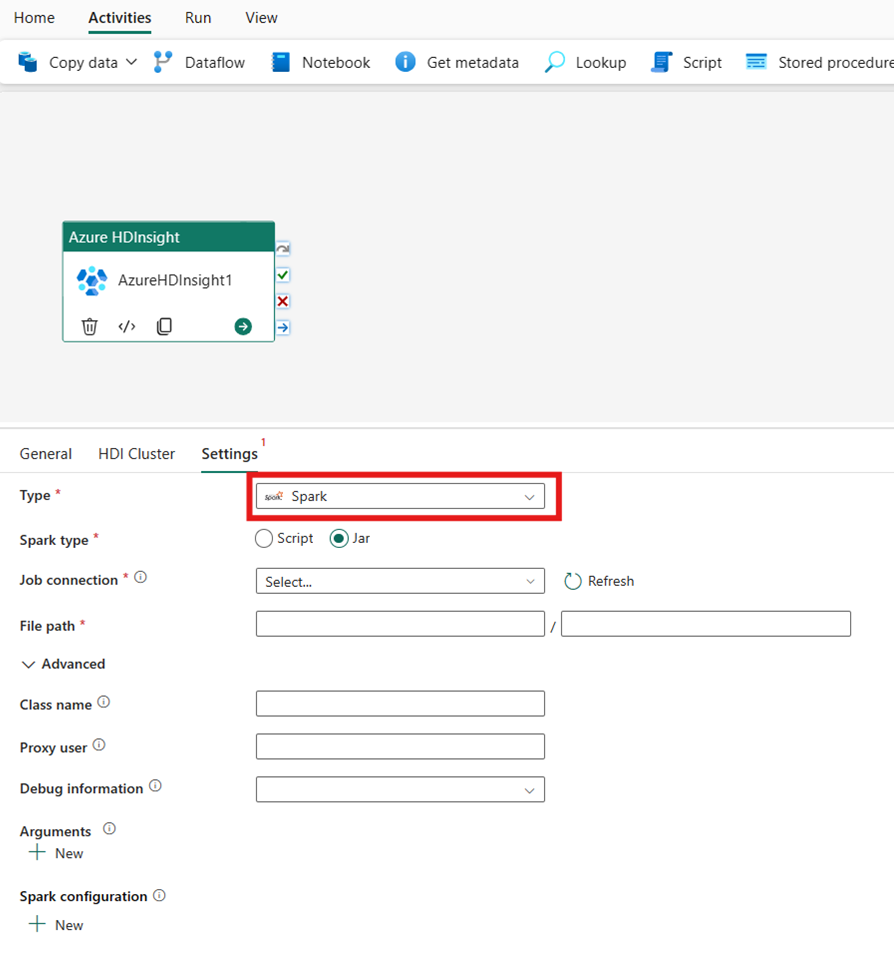
Spark
Als u Spark kiest voor Type, roept de activiteit een Spark-programma aan. Selecteer Script of Jar voor het Spark-type. U kunt desgewenst de taakverbinding opgeven die verwijst naar het opslagaccount dat het Spark-type bevat. Standaard wordt de opslagverbinding die u hebt opgegeven op het tabblad HDI-cluster gebruikt. U moet opgeven welk bestandspad moet worden uitgevoerd in Azure HDInsight. U kunt desgewenst meer configuraties opgeven, zoals klassenaam, proxygebruiker, foutopsporingsgegevens, argumenten en spark-configuratie in de sectie Geavanceerd.
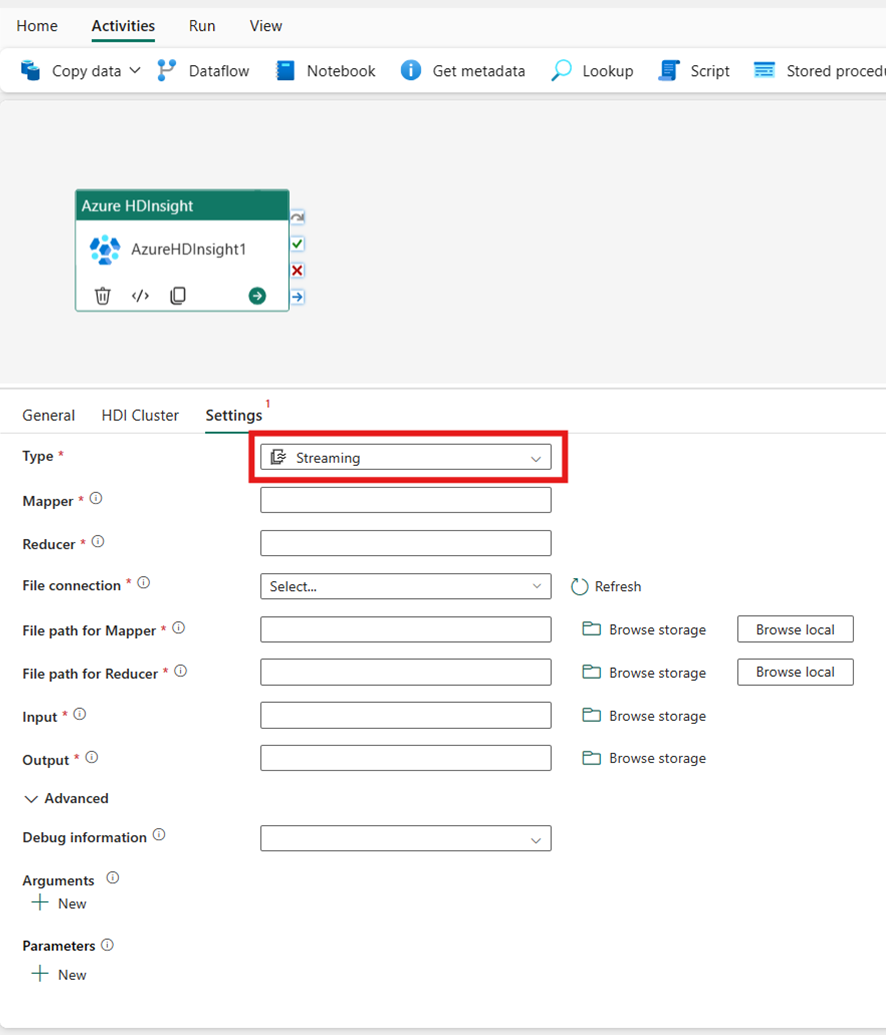
Streaming
Als u Streaming voor Type kiest, roept de activiteit een streamingprogramma aan. Geef de namen van Mapper en Reducer op en u kunt desgewenst de bestandsverbinding opgeven die verwijst naar het opslagaccount dat het streamingtype bevat. Standaard wordt de opslagverbinding die u hebt opgegeven op het tabblad HDI-cluster gebruikt. U moet het bestandspad voor Mapper en het bestandspad opgeven om Reducer uit te voeren in Azure HDInsight. Neem ook de invoer- en uitvoeropties voor het WASB-pad op. U kunt desgewenst meer configuraties opgeven, zoals foutopsporingsgegevens, argumenten en parameters in de sectie Geavanceerd.
Naslaginformatie over eigenschappen
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | Voor Hadoop Streaming-activiteit is het activiteitstype HDInsightStreaming | Ja |
| Mapper | Hiermee geeft u de naam van het uitvoerbare mapper-bestand | Ja |
| Reducer | Hiermee geeft u de naam van het uitvoerbare reductieprogramma | Ja |
| combinatie | Hiermee geeft u de naam van het uitvoerbare combinatieprogramma | Nee |
| bestandsverbinding | Verwijzing naar een gekoppelde Azure Storage-service die wordt gebruikt om de Mapper-, Combiner- en Reducer-programma's op te slaan die moeten worden uitgevoerd. | Nee |
| Hier worden alleen Azure Blob Storage- en ADLS Gen2-verbindingen ondersteund. Als u deze verbinding niet opgeeft, wordt de opslagverbinding die is gedefinieerd in de HDInsight-verbinding gebruikt. | ||
| filePath | Geef een matrix van pad op naar de Mapper-, Combiner- en Reducer-programma's die zijn opgeslagen in Azure Storage waarnaar wordt verwezen door de bestandsverbinding. | Ja |
| input | Hiermee geeft u het WASB-pad naar het invoerbestand voor mapper. | Ja |
| output | Hiermee geeft u het WASB-pad naar het uitvoerbestand voor de reducer. | Ja |
| getDebugInfo | Hiermee geeft u op wanneer de logboekbestanden worden gekopieerd naar de Azure Storage die wordt gebruikt door het HDInsight-cluster (of) dat is opgegeven door scriptLinkedService. | Nee |
| Toegestane waarden: Geen, Altijd of Fout. Standaardwaarde: Geen. | ||
| Argumenten | Hiermee geeft u een matrix van argumenten voor een Hadoop-taak. De argumenten worden doorgegeven als opdrachtregelargumenten aan elke taak. | Nee |
| Definieert | Geef parameters op als sleutel-waardeparen voor verwijzingen in het Hive-script. | Nee |
De pijplijn opslaan en uitvoeren of plannen
Nadat u andere activiteiten hebt geconfigureerd die vereist zijn voor uw pijplijn, gaat u naar het tabblad Start boven aan de pijplijneditor en selecteert u de knop Opslaan om uw pijplijn op te slaan. Selecteer Uitvoeren om het rechtstreeks uit te voeren of Plan om deze te plannen. U kunt hier ook de uitvoeringsgeschiedenis bekijken of andere instellingen configureren.
