Gegevens transformeren met dbt
Notitie
Apache Airflow-taak wordt mogelijk gemaakt door Apache Airflow.
dbt(Data Build Tool) is een opensource-opdrachtregelinterface (CLI) die gegevenstransformatie en modellering in datawarehouses vereenvoudigt door complexe SQL-code op een gestructureerde, onderhoudbare manier te beheren. Hiermee kunnen gegevensteams betrouwbare, testbare transformaties maken in de kern van hun analytische pijplijnen.
Wanneer dbt is gekoppeld aan Apache Airflow, worden de transformatiemogelijkheden van dbt verbeterd door de functies voor planning, indeling en taakbeheer van Airflow. Deze gecombineerde aanpak, met behulp van de expertise van dbt op het gebied van transformatie naast het werkstroombeheer van Airflow, levert efficiënte en robuuste gegevenspijplijnen, wat uiteindelijk leidt tot snellere en inzichtelijkere beslissingen op basis van gegevens.
In deze zelfstudie ziet u hoe u een Apache Airflow DAG maakt die dbt gebruikt om gegevens te transformeren die zijn opgeslagen in het Microsoft Fabric-datawarehouse.
Vereisten
Om aan de slag te gaan, moet u aan de volgende vereisten voldoen:
Schakel de Apache Airflow-taak in uw tenant in.
Notitie
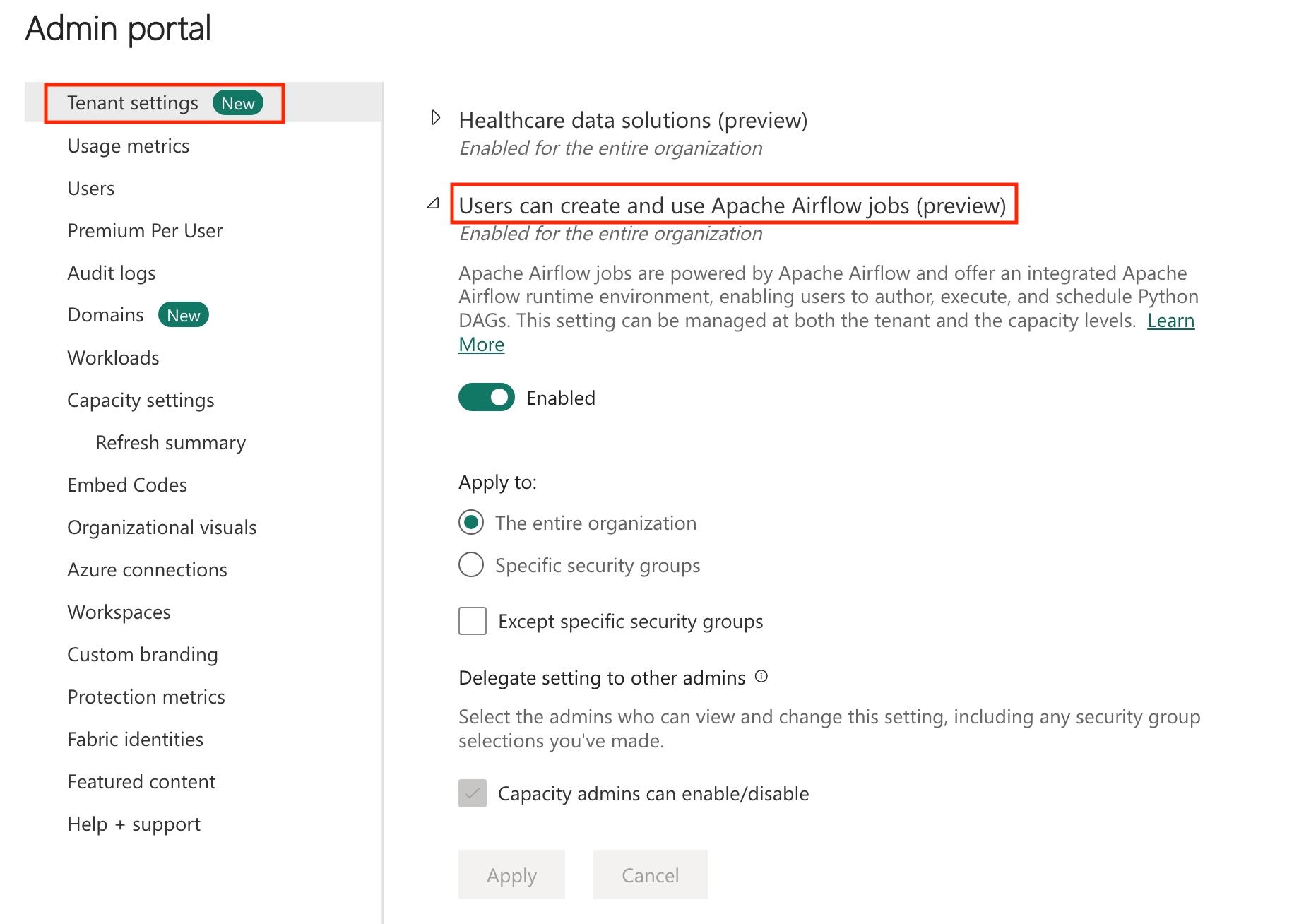
Omdat de Apache Airflow-taak de preview-status heeft, moet u deze inschakelen via uw tenantbeheerder. Als u de Apache Airflow-taak al ziet, heeft uw tenantbeheerder deze mogelijk al ingeschakeld.
Ga naar de beheerportal -> Tenantinstellingen -> Vouw onder Microsoft Fabric> de sectie 'Gebruikers kunnen Apache Airflow-taak maken en gebruiken (preview)' uit.
Selecteer Toepassen.
Maak de service-principal. Voeg de service-principal toe als in
Contributorde werkruimte waarin u datawarehouse maakt.Als u er nog geen hebt, maakt u een Fabric-magazijn. De voorbeeldgegevens opnemen in het magazijn met behulp van een gegevenspijplijn. Voor deze zelfstudie gebruiken we het NYC Taxi-Green-voorbeeld .

De gegevens die zijn opgeslagen in fabricwarehouse transformeren met behulp van dbt
In deze sectie wordt u begeleid bij de volgende stappen:
- Geef de vereisten op.
- Maak een dbt-project in de beheerde infrastructuuropslag die wordt geleverd door de Apache Airflow-taak.
- Een Apache Airflow DAG maken om dbt-taken te organiseren
De vereisten opgeven
Maak een bestand requirements.txt in de dags map. Voeg de volgende pakketten toe als Vereisten voor Apache Airflow.
astronom-cosmos: Dit pakket wordt gebruikt om uw dbt-kernprojecten uit te voeren als Apache Airflow-dags en -taakgroepen.
dbt-fabric: dit pakket wordt gebruikt voor het maken van een dbt-project, dat vervolgens kan worden geïmplementeerd in een Fabric Data Warehouse
astronomer-cosmos==1.0.3 dbt-fabric==1.5.0
Maak een dbt-project in de beheerde infrastructuuropslag die wordt geleverd door de Apache Airflow-taak.
In deze sectie maken we een dbt-voorbeeldproject in de Apache Airflow-taak voor de gegevensset
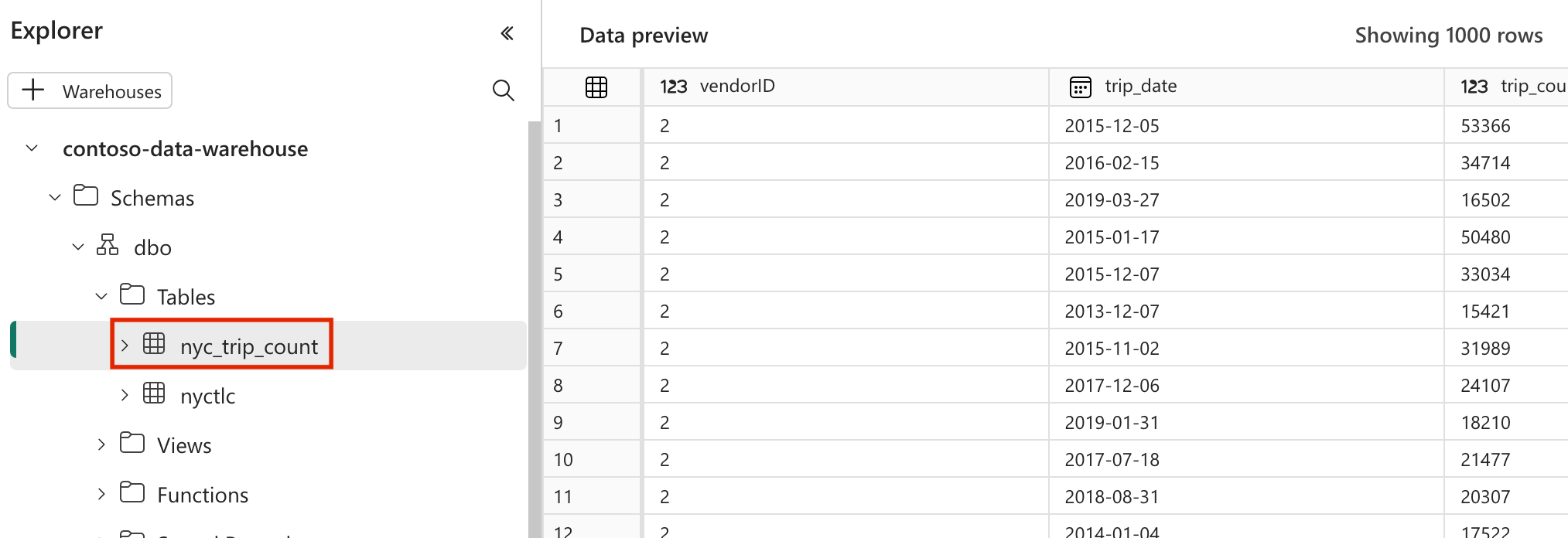
nyc_taxi_greenmet de volgende mapstructuur.dags |-- my_cosmos_dag.py |-- nyc_taxi_green | |-- profiles.yml | |-- dbt_project.yml | |-- models | | |-- nyc_trip_count.sql | |-- targetMaak de map met de naam
nyc_taxi_greenin dedagsmap metprofiles.ymlhet bestand. Deze map bevat alle bestanden die vereist zijn voor het dbt-project.
Kopieer de volgende inhoud naar de
profiles.yml. Dit configuratiebestand bevat databaseverbindingsgegevens en -profielen die worden gebruikt door dbt. Werk de waarden van de tijdelijke aanduidingen bij en sla het bestand op.config: partial_parse: true nyc_taxi_green: target: fabric-dev outputs: fabric-dev: type: fabric driver: "ODBC Driver 18 for SQL Server" server: <sql connection string of your data warehouse> port: 1433 database: "<name of the database>" schema: dbo threads: 4 authentication: ServicePrincipal tenant_id: <Tenant ID of your service principal> client_id: <Client ID of your service principal> client_secret: <Client Secret of your service principal>Maak het
dbt_project.ymlbestand en kopieer de volgende inhoud. Dit bestand geeft de configuratie op projectniveau aan.name: "nyc_taxi_green" config-version: 2 version: "0.1" profile: "nyc_taxi_green" model-paths: ["models"] seed-paths: ["seeds"] test-paths: ["tests"] analysis-paths: ["analysis"] macro-paths: ["macros"] target-path: "target" clean-targets: - "target" - "dbt_modules" - "logs" require-dbt-version: [">=1.0.0", "<2.0.0"] models: nyc_taxi_green: materialized: tableMaak de
modelsmap in denyc_taxi_greenmap. Voor deze zelfstudie maken we het voorbeeldmodel in het bestand met de naamnyc_trip_count.sqlwaarmee de tabel wordt gemaakt met het aantal ritten per dag per leverancier. Kopieer de volgende inhoud in het bestand.with new_york_taxis as ( select * from nyctlc ), final as ( SELECT vendorID, CAST(lpepPickupDatetime AS DATE) AS trip_date, COUNT(*) AS trip_count FROM [contoso-data-warehouse].[dbo].[nyctlc] GROUP BY vendorID, CAST(lpepPickupDatetime AS DATE) ORDER BY vendorID, trip_date; ) select * from final


Een Apache Airflow DAG maken om dbt-taken te organiseren
Maak het bestand met de naam
my_cosmos_dag.pyindagsde map en plak de volgende inhoud erin.import os from pathlib import Path from datetime import datetime from cosmos import DbtDag, ProjectConfig, ProfileConfig, ExecutionConfig DEFAULT_DBT_ROOT_PATH = Path(__file__).parent.parent / "dags" / "nyc_taxi_green" DBT_ROOT_PATH = Path(os.getenv("DBT_ROOT_PATH", DEFAULT_DBT_ROOT_PATH)) profile_config = ProfileConfig( profile_name="nyc_taxi_green", target_name="fabric-dev", profiles_yml_filepath=DBT_ROOT_PATH / "profiles.yml", ) dbt_fabric_dag = DbtDag( project_config=ProjectConfig(DBT_ROOT_PATH,), operator_args={"install_deps": True}, profile_config=profile_config, schedule_interval="@daily", start_date=datetime(2023, 9, 10), catchup=False, dag_id="dbt_fabric_dag", )
Uw DAG uitvoeren
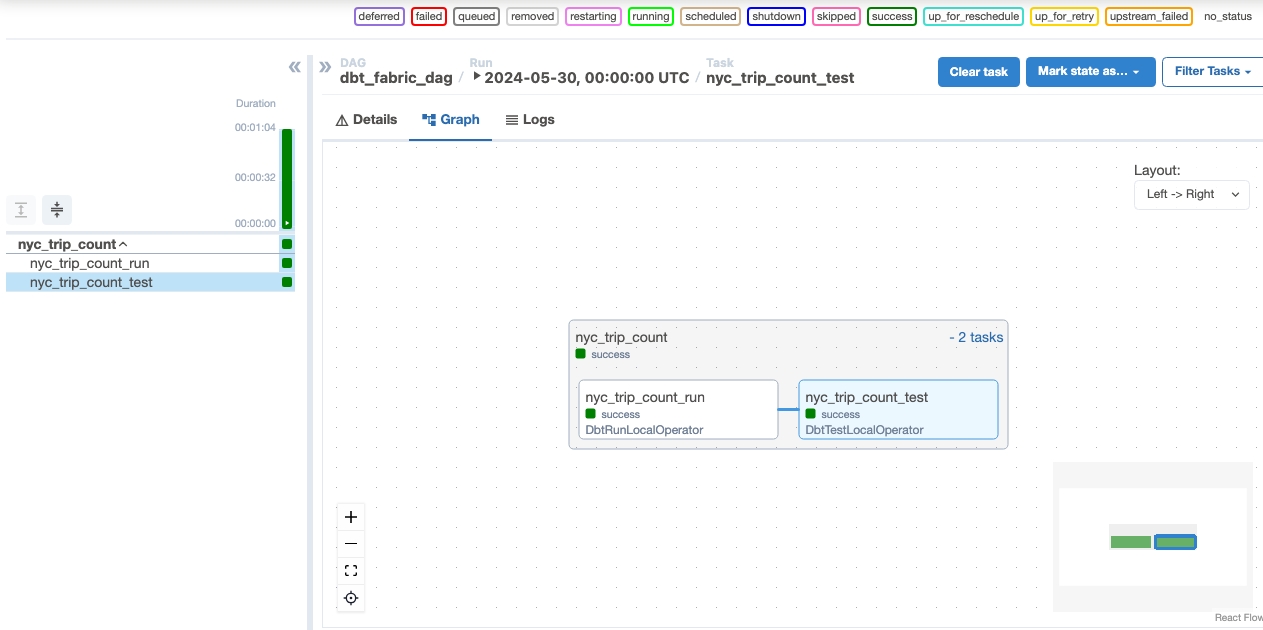
Voer de DAG uit in Apache Airflow-taak.
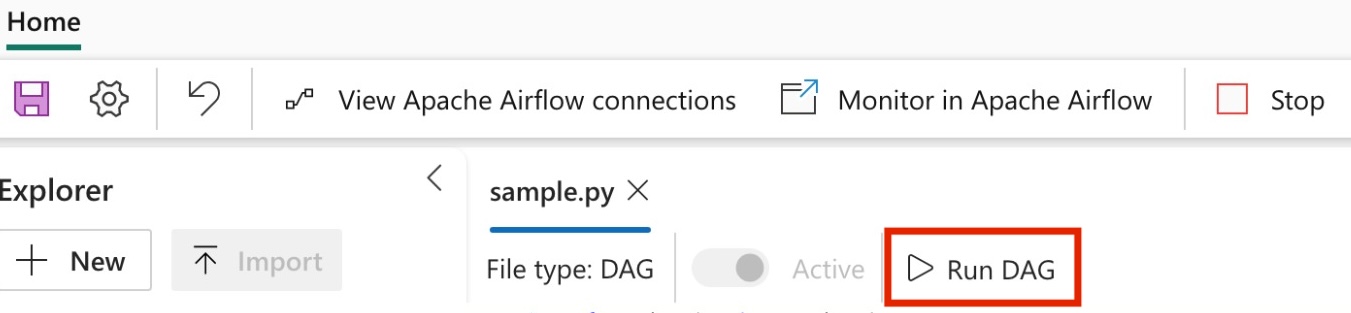
Klik op om uw dag te zien die is geladen in de Apache Airflow-gebruikersinterface
Monitor in Apache Airflow.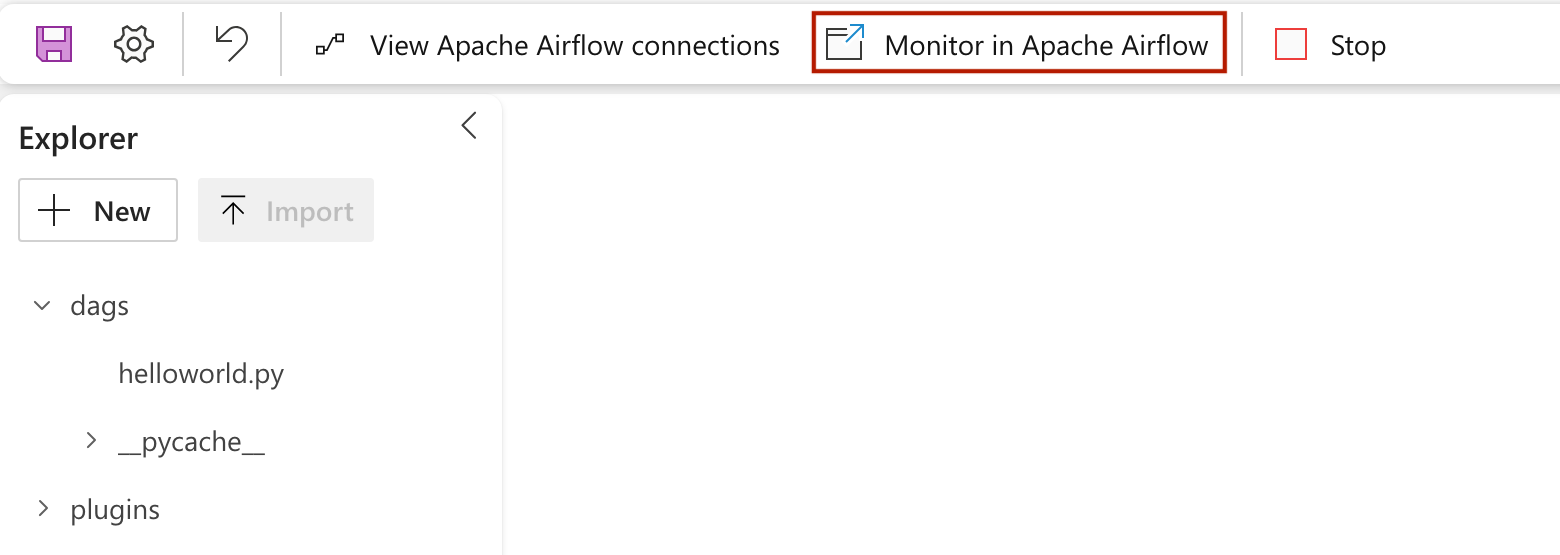



Uw gegevens valideren
- Na een geslaagde uitvoering kunt u de nieuwe tabel met de naam 'nyc_trip_count.sql' zien die is gemaakt in uw Fabric-datawarehouse om uw gegevens te valideren.