Een notebook gebruiken om gegevens in uw lakehouse te laden
In deze zelfstudie leert u hoe u gegevens in uw Fabric Lakehouse kunt lezen/schrijven met een notebook. Fabric ondersteunt Spark-API en Pandas-API om dit doel te bereiken.
Gegevens laden met een Apache Spark-API
Gebruik in de codecel van het notebook het volgende codevoorbeeld om gegevens uit de bron te lezen en te laden in bestanden, tabellen of beide secties van uw lakehouse.
Als u de locatie wilt opgeven waaruit u wilt lezen, kunt u het relatieve pad gebruiken als de gegevens afkomstig zijn uit het standaard lakehouse van uw huidige notebook. Als de gegevens afkomstig zijn uit een ander lakehouse, kunt u ook het absolute ABFS-pad (Azure Blob File System) gebruiken. Kopieer dit pad vanuit het contextmenu van de gegevens.
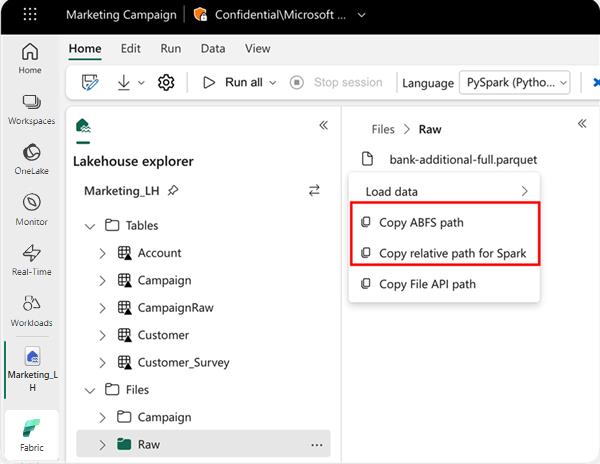
ABFS-pad kopiëren: met deze optie wordt het absolute pad van het bestand geretourneerd.
Relatief pad voor Spark kopiëren: met deze optie wordt het relatieve pad van het bestand in uw standaard lakehouse geretourneerd.
df = spark.read.parquet("location to read from")
# Keep it if you want to save dataframe as CSV files to Files section of the default lakehouse
df.write.mode("overwrite").format("csv").save("Files/ " + csv_table_name)
# Keep it if you want to save dataframe as Parquet files to Files section of the default lakehouse
df.write.mode("overwrite").format("parquet").save("Files/" + parquet_table_name)
# Keep it if you want to save dataframe as a delta lake, parquet table to Tables section of the default lakehouse
df.write.mode("overwrite").format("delta").saveAsTable(delta_table_name)
# Keep it if you want to save the dataframe as a delta lake, appending the data to an existing table
df.write.mode("append").format("delta").saveAsTable(delta_table_name)
Gegevens laden met Pandas-API
Ter ondersteuning van pandas-API wordt het standaard lakehouse automatisch gekoppeld aan het notebook. Het koppelpunt is '/lakehouse/default/'. U kunt dit koppelpunt gebruiken om gegevens van/naar het standaard lakehouse te lezen/schrijven. De optie Bestands-API-pad kopiëren in het contextmenu retourneert het pad van de bestands-API vanaf dat koppelpunt. Het pad dat wordt geretourneerd vanuit de optie ABFS-pad kopiëren, werkt ook voor pandas-API.
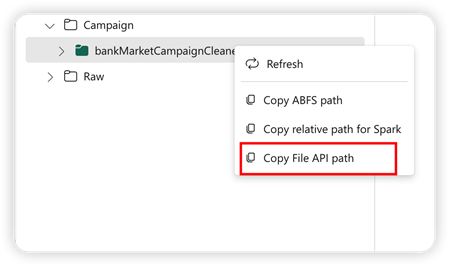
Bestands-API-pad kopiëren: met deze optie wordt het pad onder het koppelpunt van het standaard lakehouse geretourneerd.
# Keep it if you want to read parquet file with Pandas from the default lakehouse mount point
import pandas as pd
df = pd.read_parquet("/lakehouse/default/Files/sample.parquet")
# Keep it if you want to read parquet file with Pandas from the absolute abfss path
import pandas as pd
df = pd.read_parquet("abfss://DevExpBuildDemo@msit-onelake.dfs.fabric.microsoft.com/Marketing_LH.Lakehouse/Files/sample.parquet")
Tip
Voor Spark-API gebruikt u de optie ABFS-pad kopiëren of relatief pad kopiëren voor Spark om het pad van het bestand op te halen. Voor Pandas-API gebruikt u de optie ABFS-pad kopiëren of bestands-API-pad kopiëren om het pad van het bestand op te halen.
De snelste manier om de code te laten werken met Spark-API of Pandas-API is door de optie gegevens laden te gebruiken en de API te selecteren die u wilt gebruiken. De code wordt automatisch gegenereerd in een nieuwe codecel van het notebook.
