Wat is autotune voor Apache Spark-configuraties in Fabric?
Automatisch afstemmen past de Apache Spark-configuratie automatisch aan om de uitvoering van de werkbelasting te versnellen en de algehele prestaties te optimaliseren. Autotune bespaart tijd en resources in vergelijking met handmatig afstemmen, wat veel inspanning, resources, tijd en experimenten vereist. Autotune gebruikt historische uitvoeringsgegevens van uw workloads om iteratief de meest effectieve configuraties voor een specifieke workload te detecteren en toe te passen.
Notitie
De functie voor het afstemmen van automatisch afstemmen van query's in Microsoft Fabric is momenteel in preview. Autotune is beschikbaar in alle productieregio's, maar is standaard uitgeschakeld. U kunt deze activeren via de Spark-configuratie-instelling binnen de omgeving of binnen één sessie door de betreffende Spark-instelling op te slaan in uw Spark-notebook of Spark-taakdefinitiecode.
Queryafstemming
Automatisch afstemmen configureert drie Apache Spark-instellingen voor elk van uw query's afzonderlijk:
spark.sql.shuffle.partitions- Hiermee stelt u het aantal partities in voor gegevens shuffling tijdens joins of aggregaties. De standaardwaarde is 200.spark.sql.autoBroadcastJoinThreshold- Hiermee stelt u de maximale tabelgrootte in bytes in die worden uitgezonden naar alle werkknooppunten wanneer de joinbewerking wordt uitgevoerd. De standaardwaarde is 10 MB.spark.sql.files.maxPartitionBytes- Definieert het maximum aantal bytes dat in één partitie moet worden ingepakt bij het lezen van bestanden. Werkt voor parquet-, JSON- en ORC-bestandsbronnen. De standaardwaarde is 128 MB.
Tip
Bij het automatisch afstemmen van query's worden afzonderlijke query's onderzocht en wordt voor elke query een uniek ML-model gebouwd. Het is specifiek gericht op:
- Terugkerende query's
- Langlopende query's (query's met meer dan 15 seconden uitvoering)
- Apache Spark SQL API-query's (met uitzondering van query's die zijn geschreven in de RDD-API, die zeer zeldzaam zijn), maar we optimaliseren alle query's, ongeacht de taal (Scala, PySpark, R, Spark SQL)
Deze functie is compatibel met notebooks, Apache Spark-taakdefinities en pijplijnen. De voordelen variëren op basis van de complexiteit van de query, de gebruikte methoden en de structuur. Uitgebreide tests hebben aangetoond dat de grootste voordelen worden gerealiseerd met query's met betrekking tot verkennende gegevensanalyse, zoals het lezen van gegevens, het uitvoeren van joins, aggregaties en sorteren.
Op AI gebaseerde intuïtiefheid achter de Autotune
De functie voor automatisch afstemmen maakt gebruik van een iteratief proces om de queryprestaties te optimaliseren. Het begint met een standaardconfiguratie en maakt gebruik van een machine learning-model om de effectiviteit te evalueren. Wanneer een gebruiker een query verzendt, haalt het systeem de opgeslagen modellen op op basis van de vorige interacties. Er worden mogelijke configuraties gegenereerd rond een standaardinstelling met de naam centroid. De beste kandidaat die door het model wordt voorspeld, wordt toegepast. Na het uitvoeren van de query worden de prestatiegegevens teruggestuurd naar het systeem om het model te verfijnen.
De feedbacklus verschuift geleidelijk het zwaartepunt naar optimale instellingen. Het verfijnt de prestaties in de loop van de tijd en minimaliseert het risico op regressie. Continue updates op basis van gebruikersquery's maken verfijning van prestatiebenchmarks mogelijk. Bovendien werkt het proces de zwaartepuntsconfiguraties bij om ervoor te zorgen dat het model stapsgewijs naar efficiëntere instellingen gaat. Dit wordt bereikt door eerdere prestaties te evalueren en deze te gebruiken om toekomstige aanpassingen te begeleiden. Hierbij worden alle gegevenspunten gebruikt om de impact van afwijkingen te beperken.
Vanuit een verantwoord AI-perspectief bevat de functie Autotune transparantiemechanismen die zijn ontworpen om u op de hoogte te houden van uw gegevensgebruik en -voordelen. De beveiliging en privacy zijn afgestemd op de standaarden van Microsoft. Doorlopende bewaking onderhoudt de prestaties en systeemintegriteit na de lancering.
Automatisch afstemmen inschakelen
Autotune is beschikbaar in alle productieregio's, maar is standaard uitgeschakeld. U kunt deze activeren via de Spark-configuratie-instelling in de omgeving. Als u Autotune wilt inschakelen, maakt u een nieuwe omgeving of stelt u voor de bestaande omgeving de Spark-eigenschap spark.ms.autotune.enabled = true in, zoals wordt weergegeven in de onderstaande schermopname. Deze instelling wordt vervolgens overgenomen door alle notebooks en taken die in die omgeving worden uitgevoerd, zodat ze automatisch worden afgestemd.

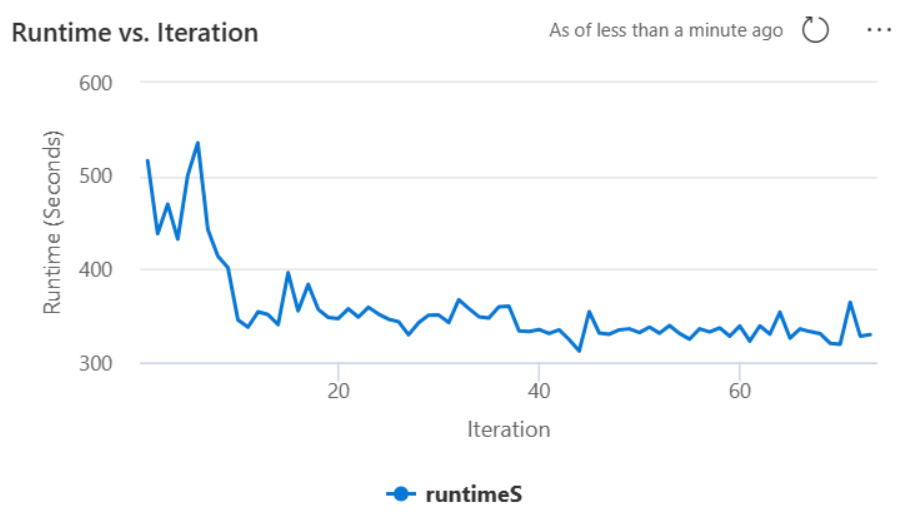
Autotune bevat een ingebouwd mechanisme voor het bewaken van prestaties en het detecteren van prestatieregressies. Als een query bijvoorbeeld een ongebruikelijk grote hoeveelheid gegevens verwerkt, wordt Autotune automatisch gedeactiveerd. Het vereist doorgaans 20 tot 25 iteraties om de optimale configuratie te leren en te identificeren.
Notitie
De Autotune is compatibel met Fabric Runtime 1.1 en Runtime 1.2. Autotune werkt niet wanneer de modus voor hoge gelijktijdigheid of wanneer het privé-eindpunt is ingeschakeld. Autotune kan echter naadloos worden geïntegreerd met automatisch schalen, ongeacht de configuratie.
U kunt automatisch afstemmen in één sessie inschakelen door de betreffende Spark-instelling op te geven in uw Spark-notebook of Spark-taakdefinitiecode.
%%sql
SET spark.ms.autotune.enabled=TRUE
U kunt Autotune beheren via Spark-instellingen voor uw respectieve Spark-notebook of Spark-taakdefinitiecode. Als u Autotune wilt uitschakelen, voert u de volgende opdrachten uit als de eerste cel (notebook) of regel van de code (SJD).
%%sql
SET spark.ms.autotune.enabled=FALSE
Casestudy
Bij het uitvoeren van een Apache Spark-query maakt autotune een aangepast ML-model dat is toegewezen aan het optimaliseren van de uitvoering van de query. Hiermee worden querypatronen en resourcebehoeften geanalyseerd. Overweeg een eerste query die een gegevensset filtert op basis van een specifiek kenmerk, zoals een land. Hoewel in dit voorbeeld geografische filtering wordt gebruikt, is het principe universeel van toepassing op elk kenmerk of elke bewerking in de query:
%%pyspark
df.filter(df.country == "country-A")
Autotune leert van deze query en optimaliseert volgende uitvoeringen. Wanneer de query bijvoorbeeld verandert door de filterwaarde te wijzigen of een andere gegevenstransformatie toe te passen, blijft de structurele essentie van de query vaak consistent:
%%pyspark
df.filter(df.country == "country-B")
Ondanks wijzigingen identificeert autotune de fundamentele structuur van de nieuwe query, het implementeren van eerder geleerde optimalisaties. Deze mogelijkheid zorgt voor een duurzame hoge efficiëntie zonder dat handmatige herconfiguratie nodig is voor elke nieuwe query-iteratie.
Logboeken
Voor elk van uw query's bepaalt autotune de meest optimale instellingen voor drie Spark-configuraties. U kunt de voorgestelde instellingen bekijken door naar de logboeken te navigeren. De configuraties die door autotune worden aanbevolen, bevinden zich in de stuurprogrammalogboeken, met name die vermeldingen die beginnen met [Autotune].

U vindt verschillende typen vermeldingen in uw logboeken. Hieronder ziet u de belangrijkste:
| -Status | Beschrijving |
|---|---|
| AUTOTUNE_DISABLED | Overgeslagen. Autotune is uitgeschakeld; voorkomen dat telemetriegegevens worden opgehaald en queryoptimalisatie wordt geoptimaliseerd. Schakel Autotune in om de mogelijkheden ervan volledig te gebruiken en tegelijkertijd de privacy van klanten te respecteren.' |
| QUERY_TUNING_DISABLED | Overgeslagen. Automatisch afstemmen van query's is uitgeschakeld. Schakel deze in om instellingen voor uw Spark SQL-query's af te stemmen. |
| QUERY_PATTERN_NOT_MATCH | Overgeslagen. Het querypatroon komt niet overeen. Autotune is effectief voor alleen-lezenquery's. |
| QUERY_DURATION_TOO_SHORT | Overgeslagen. De queryduur is te kort om te optimaliseren. Voor automatisch afstemmen zijn langere query's vereist voor effectieve afstemming. Query's moeten ten minste 15 seconden worden uitgevoerd. |
| QUERY_TUNING_SUCCEED | Geslaagd. Het afstemmen van query's is voltooid. Optimale spark-instellingen toegepast. |
Transparantienotitie
In overeenstemming met de verantwoordelijke AI-standaard is dit gedeelte gericht op het verduidelijken van het gebruik en de validatie van de functie Autotune, het bevorderen van transparantie en het inschakelen van geïnformeerde besluitvorming.
Doel van Autotune
Autotune is ontwikkeld om de efficiëntie van Apache Spark-werkbelastingen te verbeteren, voornamelijk voor gegevensprofessionals. De belangrijkste functies zijn:
- Het afstemmen van de Apache Spark-configuratie automatiseren om de uitvoeringstijden te verminderen.
- Minimaliseer handmatige afstemmingsinspanningen.
- Gebruik van historische workloadgegevens om configuraties iteratief te verfijnen.
Validatie van Autotune
Autotune heeft uitgebreide tests ondergaan om de effectiviteit en veiligheid ervan te garanderen:
- Strenge tests met diverse Spark-workloads om de efficiëntie van het afstemmingsalgoritmen te controleren.
- Benchmarking op basis van standaardmethoden voor Spark-optimalisatie om prestatievoordelen te demonstreren.
- Praktijkcasestudies waarin de praktische waarde van Autotune wordt benadrukt.
- Naleving van strikte beveiligings- en privacynormen om gebruikersgegevens te beschermen.
Gebruikersgegevens worden uitsluitend gebruikt om de prestaties van uw workload te verbeteren, met robuuste beveiligingen om misbruik of blootstelling van gevoelige informatie te voorkomen.