Best practices voor gegevensharmonisatie
Wanneer u regels instelt om uw gegevens te harmoniseren in een klantprofiel, kunt u het beste rekening houden met de volgende best practices:
Tijd om te harmoniseren afstemmen met volledige afstemming. Proberen om elke mogelijke afstemming vast te leggen leidt tot veel regels en harmonisering die lang duurt.
Regels geleidelijk toevoegen en de resultaten bijhouden. Verwijder regels die het resultaat van de afstemming niet verbeteren.
Elke tabel ontdoen van dubbelingen, zodat elke klant in één rij wordt weergegeven.
Gebruik normalisatie om variaties te standaardiseren in de manier waarop gegevens zijn ingevoerd, zoals Straat versus Str versus Str. versus str.
Gebruik fuzzy overeenkomst strategisch om typefouten en fouten zoals bob@contoso.com en bob@contoso.cm te corrigeren. Fuzzy overeenkomsten kosten meer tijd dan exacte overeenkomsten. Controleer altijd of de extra tijd die u aan fuzzy overeenkomst besteedt, het extra overeenkomstpercentage waard is.
Beperk het bereik van overeenkomsten met exacte overeenkomst. Zorg ervoor dat elke regel met fuzzy-voorwaarden ten minste één exacte overeenkomstvoorwaarde heeft.
Gebruik overeenkomst niet voor kolommen met veelvuldig herhaalde gegevens. Zorg ervoor dat fuzzy overeenkomst-kolommen geen waarden bevatten die vaak worden herhaald, zoals de standaardwaarde 'Voornaam' in een formulier.
Prestaties van harmonisering
Elke regel heeft tijd nodig om uit te voeren. Patronen, zoals het vergelijken van elke tabel met elke andere tabel of het proberen vast te leggen van elke mogelijke recordovereenkomst, kunnen leiden tot lange verwerkingstijden voor de harmonisatie. Ook worden er dan weinig tot geen overeenkomsten meer geretourneerd via een abonnement dat elke tabel vergelijkt met een basistabel.
De beste aanpak is om te beginnen met een basisset aan regels waarvan u weet dat ze nodig zijn, zoals het vergelijken van elke tabel met uw primaire tabel. Uw primaire tabel moet de tabel zijn met de meest volledige en correcte gegevens. Deze tabel moet bovenaan worden geordend in de stap Harmonisatie van overeenkomstregels.
Voeg geleidelijk meerdere regels toe en kijk hoelang het duurt om de wijzigingen door te voeren en of uw resultaten verbeteren. Ga naar Instellingen>Systeem>Status en selecteer Overeenkomst om te zien hoelang ontdubbelen en afstemmen duurden voor elke harmonisatierun.
Bekijk de regelstatistieken op de pagina's Ontdubbelingsregels en Overeenkomstregels om te zien of het aantal Unieke records verandert. Als een nieuwe regel overeenkomt met bepaalde records en het unieke recordaantal niet verandert, dan identificeert een eerdere regel die overeenkomsten.
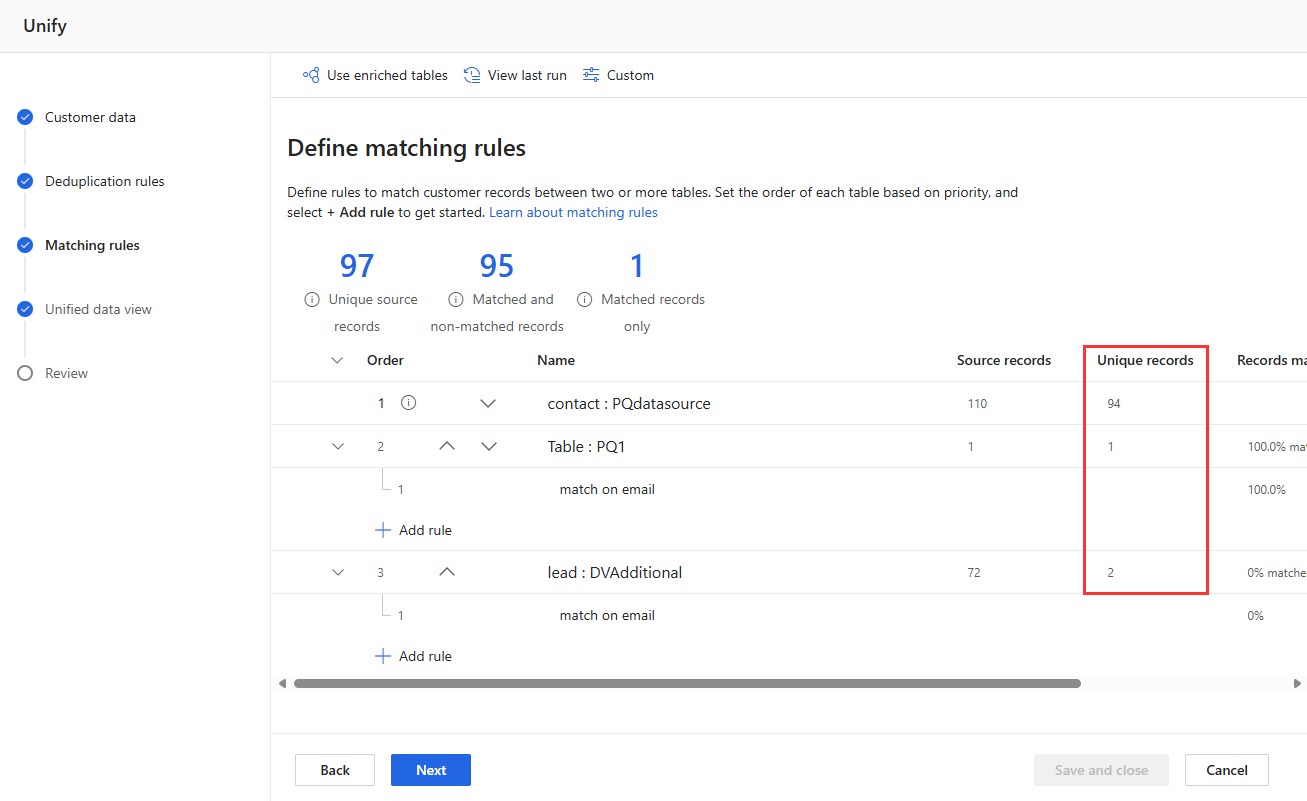
Klantgegevens
In de stap Klantgegevens:
Sluit kolommen uit die niet nodig zijn voor de overeenkomstregels of die u niet wilt opnemen in het uiteindelijke klantprofiel.
Bekijk de kolombeschrijvingen die zijn geselecteerd door intelligente toewijzing.
Niet alle kolommen hoeven te worden toegewezen. Door algemene kolommen, zoals e-mail- en adresvelden, toe te wijzen, kan Customer Insights downstream-processen vereenvoudigen. Kolommen met een unieke id of een doel voor uw bedrijf kunnen echter niet-toegewezen blijven.
Ontdubbeling
Gebruik ontdubbelingsregels om dubbele klantrecords in een tabel te verwijderen, zodat elke klant in één rij in elke tabel staat. Een goede regel identificeert een unieke klant.
In dit eenvoudige voorbeeld delen records 1, 2 en 3 een e-mailadres of telefoonnummer en vertegenwoordigen ze dezelfde persoon.
| Id | Meting | Telefoon | |
|---|---|---|---|
| 0 | Persoon 1 | (425) 555-1111 | AAA@A.com |
| 2 | Persoon 1 | (425) 555-1111 | BBB@B.com |
| 5 | Persoon 1 | (425) 555-2222 | BBB@B.com |
| 4 | Persoon 2 | (206) 555-9999 | Person2@contoso.com |
We willen niet alleen op naam matchen, omdat hierdoor verschillende mensen met dezelfde naam zouden worden gematcht.
Maak Regel 1 met Naam en Telefoonnummer, die overeenkomt met records 1 en 2.
Maak Regel 2 met Naam en E-mailadres, die overeenkomt met records 2 en 3.
De combinatie van Regel 1 en Regel 2 creëert een enkele afstemmingsgroep omdat ze record 2 delen.
U bepaalt het aantal regels en voorwaarden waarmee u uw klanten eenduidig identificeert. De exacte regels zijn afhankelijk van de gegevens waarover u beschikt, de kwaliteit van uw gegevens en hoe uitgebreid u het ontdubbelingsproces wilt laten zijn.
Normalisatie
Gebruik normalisatie om gegevens te standaardiseren voor betere afstemming. Normalisatie presteert goed bij grote gegevenssets.
De genormaliseerde gegevens worden alleen gebruikt voor vergelijkingsdoeleinden om klantgegevens beter op elkaar af te stemmen. De gegevens in de uiteindelijke geharmoniseerde klantprofieluitvoer worden hierdoor niet gewijzigd.
Exacte overeenkomst
Bepaal met precisie hoe dicht twee tekenreeksen bij elkaar moeten liggen om als overeenkomst te worden beschouwd. Voor de standaardprecisie-instelling is een exacte overeenkomst vereist. Elke andere waarde maakt fuzzy overeenkomst voor die voorwaarde mogelijk.
De precisie kan worden ingesteld op laag (30% overeenkomst), gemiddeld (60% overeenkomst) en hoog (80% overeenkomst). U kunt de precisie ook aanpassen en instellen in stappen van 1%.
Exacte overeenkomstvoorwaarden
Eerst worden de exacte overeenkomstvoorwaarden uitgevoerd om een kleinere set waarden voor fuzzy overeenkomsten te verkrijgen. Om effectief te zijn, moeten de exacte overeenkomstvoorwaarden in redelijke mate uniek zijn. Als al uw klanten bijvoorbeeld in hetzelfde land/dezelfde regio wonen, helpt een exacte overeenkomst op basis van land/regio niet om het bereik te beperken.
Kolommen zoals volledige naam, e-mailadres, telefoonnummer of adresvelden zijn vrij uniek en kunnen heel goed als exacte overeenkomst worden gebruikt.
Zorg ervoor dat de kolom die u gebruikt voor een exacte overeenkomstvoorwaarde geen waarden bevat die veelvuldig worden herhaald, zoals de standaardwaarde 'Voornaam' die door een formulier wordt vastgelegd. Met Customer Insights kunt u gegevenskolommen profileren om inzicht te krijgen in de meest voorkomende waarden. U kunt gegevensprofilering inschakelen voor Azure Data Lake-verbindingen (met behulp van Common Data Model of Delta-indeling) en Synapse. Het gegevensprofiel wordt uitgevoerd wanneer de gegevensbron de volgende keer wordt vernieuwd. Ga voor meer informatie naar Gegevensprofilering.
Fuzzy overeenkomst
Gebruik fuzzy overeenkomst om tekenreeksen te matchen die dicht bij elkaar liggen, maar niet exact zijn vanwege typefouten of andere kleine variaties. Gebruik fuzzy overeenkomst strategisch, omdat het langzamer is dan exacte matches. Zorg ervoor dat er in elke regel met fuzzy-voorwaarden minimaal één exacte overeenkomstvoorwaarde is.
Fuzzy overeenkomst is niet bedoeld om naamvarianten zoals Suzzie en Suzanne vast te leggen. Deze variaties worden beter vastgelegd met het normalisatiepatroon Type: Naam of de aangepaste Aliasovereenkomst waarbij klanten hun lijst met naamvariaties kunnen invoeren die ze als overeenkomsten willen beschouwen.
U kunt voorwaarden aan een regel toevoegen, zoals het matchen van FirstName en Telefoon. Voorwaarden binnen een bepaalde regel zijn "AND"-voorwaarden. Alle voorwaarden moeten overeenkomen, anders komen de rijen niet overeen. Afzonderlijke regels zijn 'OR'-voorwaarden. Als Regel 1 niet overeenkomt met de rijen, dan worden de rijen vergeleken met Regel 2.
Notitie
Alleen kolommen met het gegevenstype tekenreeks kunnen fuzzy overeenkomst gebruiken. Voor kolommen met andere gegevenstypen, zoals geheel getal, dubbel of datum/tijd, is het precisieveld alleen-lezen en ingesteld op de exacte overeenkomst.
Berekeningen bij fuzzy overeenkomst
Fuzzy overeenkomsten worden bepaald door de bewerkingsafstandsscore tussen twee tekenreeksen te berekenen. Als de score gelijk is aan of hoger is dan de precisiedrempelwaarde, worden de tekenreeksen als overeenstemmend beschouwd.
De bewerkingsafstand is het aantal bewerkingen dat nodig is om de ene tekenreeks om te zetten in een andere tekenreeks, door een teken toe te voegen, te verwijderen of te wijzigen.
De strings "robert2020@hotmail.com" en "robrt2020@hotmail.cm" hebben bijvoorbeeld een bewerkingsafstand van twee wanneer we de tekens e en o verwijderen. Om de bewerkingsafstand te berekenen gebruikt u deze formule: (Basisreekslengte – Bewerkafstand) / Basisreekslengte.
| Basistekenreeks | Vergelijkingstekenreeks | Score |
|---|---|---|
| robert2020@hotmail.com | robrt2020@hotmail.cm | (20 - 2)/20 = 0,9 |