Sentiment analyseren met behulp van de ML.NET CLI
Meer informatie over het gebruik van ML.NET CLI om automatisch een ML.NET model en onderliggende C#-code te genereren. U geeft uw gegevensset en de machine learning-taak op die u wilt implementeren en de CLI gebruikt de AutoML-engine om broncode voor het genereren en implementeren van modellen te maken, evenals het classificatiemodel.
In deze zelfstudie voert u de volgende stappen uit:
- Uw gegevens voorbereiden voor de geselecteerde machine learning-taak
- Voer de opdracht
mlnet classificationuit vanuit de CLI - De metrische resultaten van de kwaliteit controleren
- Inzicht in de gegenereerde C#-code voor het gebruik van het model in uw toepassing
- Verken de gegenereerde C#-code die is gebruikt om het model te trainen
Notitie
Dit artikel verwijst naar het ML.NET CLI-hulpprogramma, dat momenteel in preview is en materiaal onderhevig is aan wijzigingen. Ga naar de pagina ML.NET voor meer informatie.
De ML.NET CLI maakt deel uit van ML.NET en het belangrijkste doel is om ML.NET voor .NET-ontwikkelaars te democratiseren bij het leren ML.NET, zodat u helemaal niets hoeft te coderen om aan de slag te gaan.
U kunt de ML.NET CLI uitvoeren op elke opdrachtprompt (Windows, Mac of Linux) om ML.NET modellen en broncode te genereren op basis van trainingsgegevenssets die u opgeeft.
Voorwaarden
- .NET 8 SDK versie of hoger
- (Optioneel) Visual Studio
- ML.NET CLI
U kunt de gegenereerde C#-codeprojecten uitvoeren vanuit Visual Studio of met dotnet run (.NET CLI).
Uw gegevens voorbereiden
We gaan een bestaande gegevensset gebruiken die wordt gebruikt voor een 'Sentimentanalyse'-scenario. Dit is een machine learning-taak voor binaire classificatie. U kunt uw eigen gegevensset op een vergelijkbare manier gebruiken en het model en de code worden voor u gegenereerd.
Download het UCI Sentiment Labeled Sentences dataset zip-bestand (zie bronvermeldingen in de volgende toelichting)en pak het uit in een map naar keuze.
Notitie
De gegevenssets in deze zelfstudie maken gebruik van een gegevensset uit de 'Van groep naar afzonderlijke labels met behulp van diepe functies', Kotzias et al.. KDD 2015 en gehost door de UCI Machine Learning Repository - Dua, D. en Karra Taniskidou, E. (2017). UCI Machine Learning Repository [http://archive.ics.uci.edu/ml]. Irvine, CA: University of California, School of Information and Computer Science.
Kopieer het
yelp_labelled.txtbestand naar een map die u eerder hebt gemaakt (zoals/cli-test).Open de opdrachtprompt van uw voorkeur en ga naar de map waarin u het gegevenssetbestand hebt gekopieerd. Bijvoorbeeld:
cd /cli-testMet behulp van een teksteditor zoals Visual Studio Code kunt u het
yelp_labelled.txtgegevenssetbestand openen en verkennen. U kunt zien dat de structuur het volgende is:Het bestand heeft geen header. U gebruikt de index van de kolom.
Er zijn slechts twee kolommen:
Tekst (kolomindex 0) Label (kolomindex 1) Wauw... Ik hield van deze plek. 1 De korst is niet goed. 0 Niet lekker en de textuur was gewoon vervelend. 0 ... NOG VEEL MEER TEKSTREGELS ... ... (1 of 0)...
Zorg ervoor dat u het gegevenssetbestand sluit vanuit de editor.
U bent nu klaar om de CLI te gaan gebruiken voor dit scenario 'Sentimentanalyse'.
Notitie
Na het voltooien van deze zelfstudie kunt u ook proberen met uw eigen gegevenssets zolang ze klaar zijn om te worden gebruikt voor een van de ML-taken die momenteel worden ondersteund door de ML.NET CLI Preview, die zijn 'Binaire classificatie', 'Classificatie', 'Regressie', en 'Aanbeveling'.
Voer de opdracht mlnet-classificatie uit
Voer de volgende ML.NET CLI-opdracht uit:
mlnet classification --dataset "yelp_labelled.txt" --label-col 1 --has-header false --train-time 10Met deze opdracht wordt de opdracht
mlnet classificationuitgevoerd:- voor de ML-taak van classificatie
- gebruikt het gegevenssetbestand
yelp_labelled.txtals trainings- en testgegevensset (intern gebruikt de CLI kruisvalidatie of splitst het in twee gegevenssets, één voor training en één voor testen) - waarbij de doelkolom die u wilt voorspellen (meestal label) de kolom is met index 1 (dat is de tweede kolom, omdat de index op nul is gebaseerd)
- gebruikt geen bestandskoptekst met kolomnamen omdat dit specifieke gegevenssetbestand geen koptekst heeft
- de gerichte verkenning-/trainingstijd voor het experiment is 10 seconden
Je ziet uitvoer van de CLI, op een soortgelijke manier als:
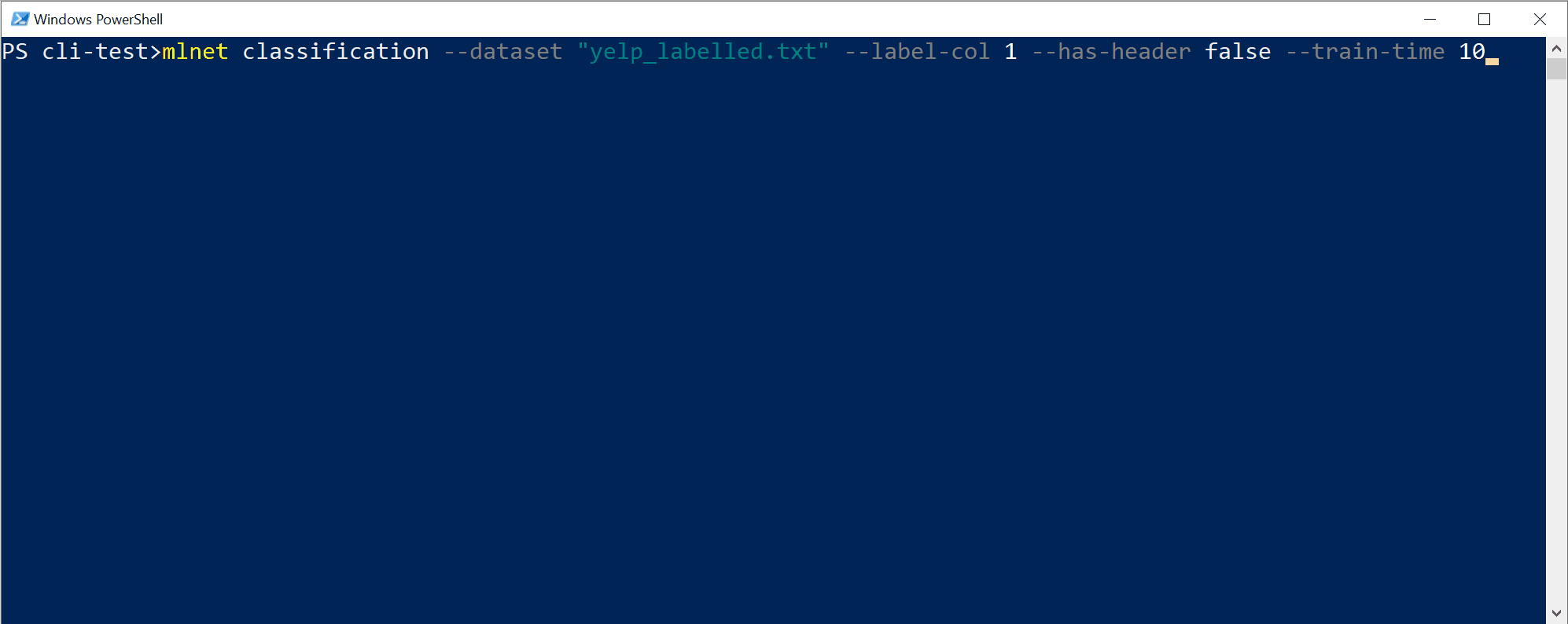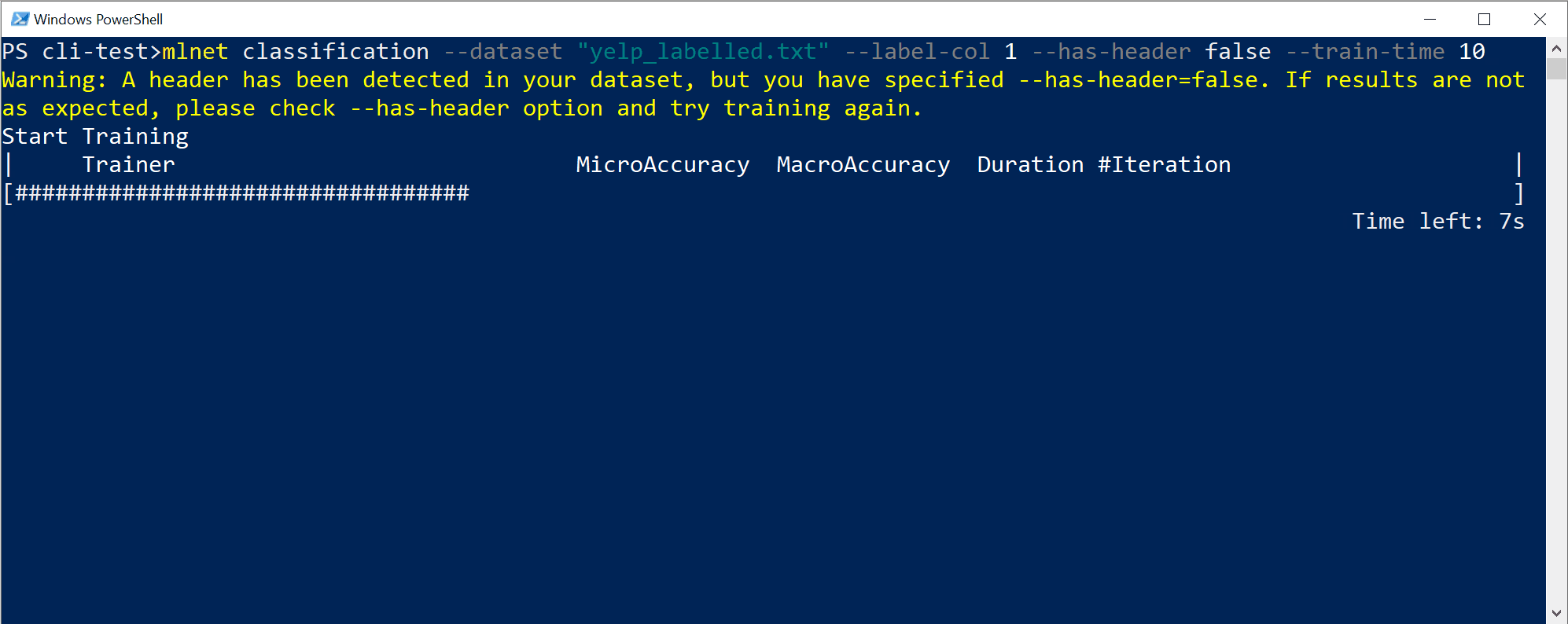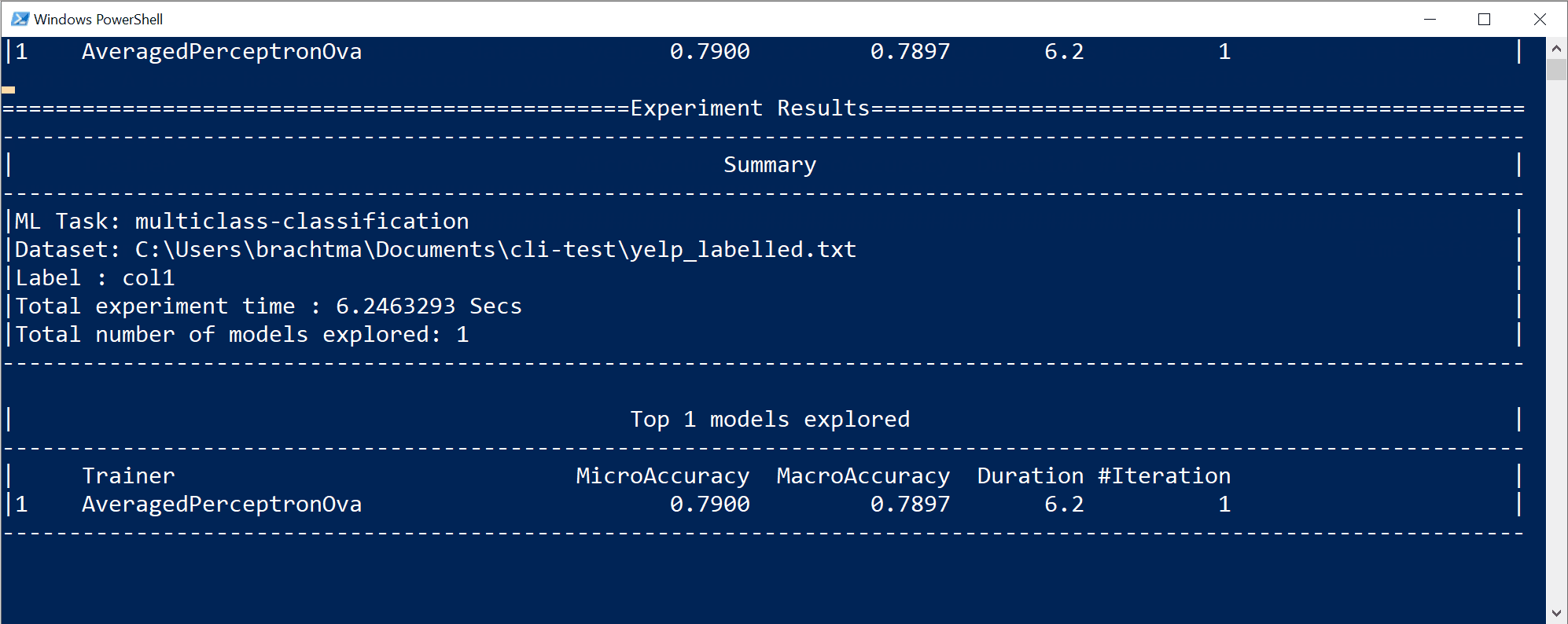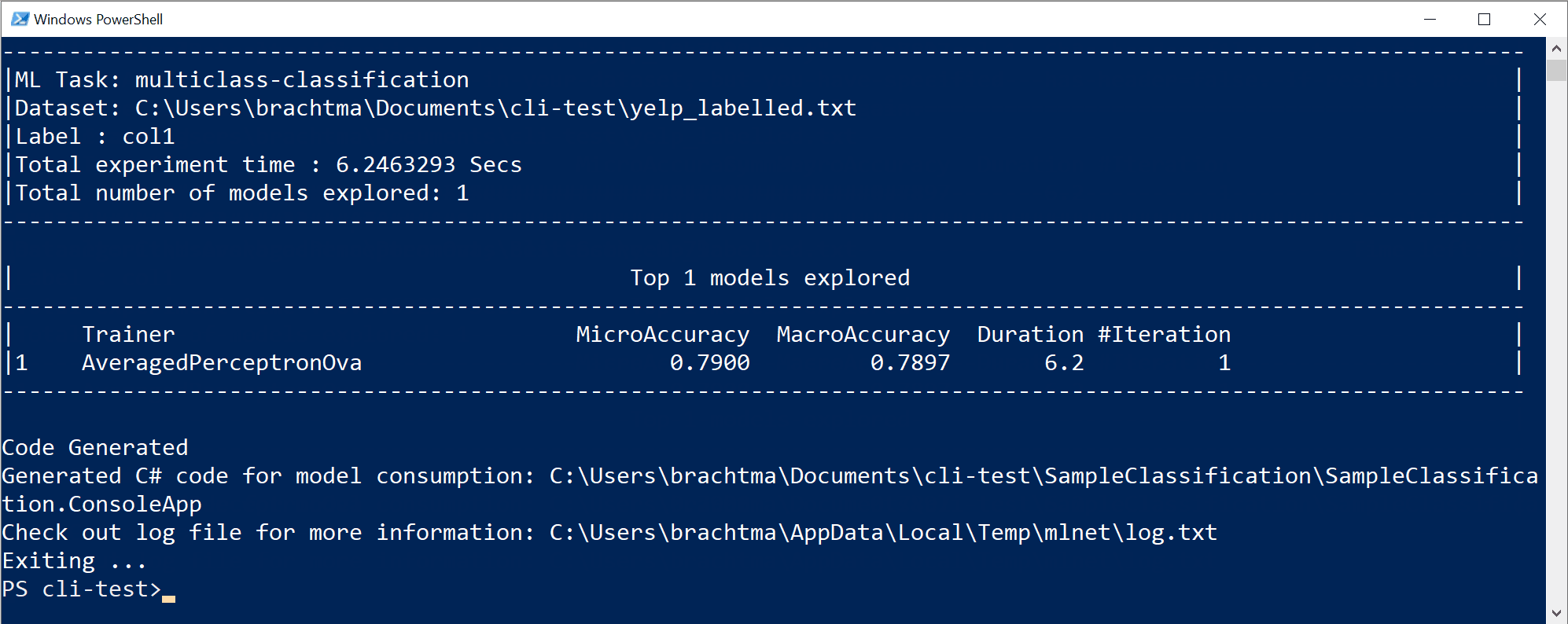
In dit specifieke geval, in slechts 10 seconden en met de kleine gegevensset, kon het CLI-hulpprogramma nogal wat iteraties uitvoeren, wat betekent dat het meerdere keren traint op basis van verschillende combinaties van algoritmen/configuratie met verschillende interne gegevenstransformaties en hyperparameters van het algoritme.
Ten slotte is het model 'beste kwaliteit' dat in 10 seconden is gevonden een model met behulp van een bepaalde trainer/algoritme met een specifieke configuratie. Afhankelijk van de verkenningstijd kan de opdracht een ander resultaat opleveren. De selectie is gebaseerd op de meerdere metrische gegevens die worden weergegeven, zoals
Accuracy.Inzicht in de metrische gegevens over de kwaliteit van het model
De eerste en eenvoudigste metrische waarde voor het evalueren van een binair classificatiemodel is de nauwkeurigheid, wat eenvoudig te begrijpen is. "Nauwkeurigheid is het aandeel van de juiste voorspellingen met een testgegevensset.". Hoe dichter bij 100% (1,00), hoe beter.
Er zijn echter gevallen waarin alleen meten met de metrische nauwkeurigheid niet genoeg is, met name wanneer het label (0 en 1 in dit geval) niet in balans is in de testgegevensset.
Zie voor aanvullende metrische gegevens en meer gedetailleerde informatie over de metrische gegevens zoals Nauwkeurigheid, AUC, AUCPR en F1-score die wordt gebruikt om de verschillende modellen te evalueren, Inzicht in ML.NET metrische gegevens.
Notitie
U kunt dezelfde dataset proberen en een paar minuten opgeven voor
--max-exploration-time(bijvoorbeeld drie minuten, dus u geeft 180 seconden op), zodat er een beter model voor u gevonden wordt met een andere configuratie van de trainingspijplijn voor deze dataset (die vrij klein is, namelijk 1000 rijen).Als u een model van hoge kwaliteit wilt vinden dat een productieklaar model is voor grotere gegevenssets, moet u experimenten uitvoeren met behulp van de CLI, waarbij u meestal veel meer verkenningstijd specificeert, afhankelijk van de omvang van de gegevensset. In veel gevallen is het zelfs mogelijk dat u meerdere uren verkenningstijd nodig hebt, met name als de gegevensset groot is voor rijen en kolommen.
De vorige opdrachtuitvoering heeft de volgende assets gegenereerd:
- Een geserialiseerd model .zip ("beste model") klaar voor gebruik.
- C#-code voor het uitvoeren/scoren van het gegenereerde model (om voorspellingen te doen in uw eindgebruikers-apps met dat model).
- C#-trainingscode die wordt gebruikt om dat model te genereren (leerdoeleinden).
- Een logbestand met alle iteraties waarin gedetailleerde informatie staat over elk algoritme dat is geprobeerd met de combinatie van hyperparameters en gegevenstransformaties.
De eerste twee assets (.ZIP bestandsmodel en C#-code om dat model uit te voeren) kunnen rechtstreeks worden gebruikt in uw eindgebruikers-apps (ASP.NET Core-web-app, services, desktop-app, enzovoort) om voorspellingen te doen met dat gegenereerde ML-model.
De derde asset, de trainingscode, laat zien wat ML.NET API-code is gebruikt door de CLI om het gegenereerde model te trainen, zodat u kunt onderzoeken welke specifieke trainer/algoritme en hyperparameters zijn geselecteerd door de CLI.
Deze opgesomde activa worden uitgelegd in de volgende stappen van de handleiding.
Verken de gegenereerde C#-code om het model uit te voeren om voorspellingen te doen
Open in Visual Studio de oplossing die is gegenereerd in de map met de naam
SampleClassificationin de oorspronkelijke doelmap (deze heeft de naam/cli-testin de zelfstudie). U zou een oplossing moeten zien die vergelijkbaar is met:
Notitie
In de zelfstudie wordt voorgesteld Visual Studio te gebruiken, maar u kunt ook de gegenereerde C#-code (twee projecten) verkennen met een teksteditor en de gegenereerde console-app uitvoeren met de
dotnet CLIop een macOS-, Linux- of Windows-computer.- De gegenereerde console-app bevat uitvoeringscode die u moet controleren en vervolgens gebruikt u meestal de scorecode (code waarmee het ML-model wordt uitgevoerd om voorspellingen te doen) door die eenvoudige code (slechts enkele regels) te verplaatsen naar uw eindgebruikerstoepassing waar u de voorspellingen wilt doen.
- Het gegenereerde mbconfig-bestand is een configuratiebestand dat kan worden gebruikt om uw model opnieuw te trainen, via de CLI of via Model Builder. Er zijn ook twee codebestanden aan gekoppeld en een zip-bestand.
- Het -bestand bevat de code voor het bouwen van de modelpijplijn met behulp van de ML.NET-API.
- Het verbruiksbestand bevat de code om het model te gebruiken.
- Het zip--bestand dat het gegenereerde model is van de CLI.
Open het SampleClassification.consumption.cs bestand in het bestand mbconfig. U ziet dat er invoer- en uitvoerklassen zijn. Dit zijn gegevensklassen, of POCO-klassen, die worden gebruikt voor het opslaan van gegevens. De klassen bevatten standaardcode die handig is als uw gegevensset tientallen of zelfs honderden kolommen bevat.
- De
ModelInput-klasse wordt gebruikt bij het lezen van gegevens uit de gegevensset. - De
ModelOutput-klasse wordt gebruikt om het voorspellingsresultaat (voorspellingsgegevens) op te halen.
- De
Open het Program.cs-bestand en verken de code. In slechts een paar regels kunt u het model uitvoeren en een voorbeeldvoorspelling maken.
static void Main(string[] args) { // Create single instance of sample data from first line of dataset for model input ModelInput sampleData = new ModelInput() { Col0 = @"Wow... Loved this place.", }; // Make a single prediction on the sample data and print results var predictionResult = SampleClassification.Predict(sampleData); Console.WriteLine("Using model to make single prediction -- Comparing actual Col1 with predicted Col1 from sample data...\n\n"); Console.WriteLine($"Col0: {sampleData.Col0}"); Console.WriteLine($"\n\nPredicted Col1 value {predictionResult.PredictedLabel} \nPredicted Col1 scores: [{String.Join(",", predictionResult.Score)}]\n\n"); Console.WriteLine("=============== End of process, hit any key to finish ==============="); Console.ReadKey(); }Met de eerste regels code maakt u een enkel steekproefgegeven. In dit geval zijn de enkele voorbeeldgegevens gebaseerd op de eerste rij van de gegevensset die moet worden gebruikt voor de voorspelling. U kunt ook uw eigen 'in code vastgelegde' gegevens maken door de code bij te werken:
ModelInput sampleData = new ModelInput() { Col0 = "The ML.NET CLI is great for getting started. Very cool!" };De volgende coderegel maakt gebruik van de
SampleClassification.Predict()methode op de opgegeven invoergegevens om een voorspelling te doen en de resultaten te retourneren (op basis van het ModelOutput.cs schema).Met de laatste regels code worden de eigenschappen van de voorbeeldgegevens (in dit geval de opmerking) en de sentimentvoorspelling en de bijbehorende scores voor positief gevoel (1) en negatief gevoel (2) afgedrukt.
Voer het project uit met behulp van de oorspronkelijke voorbeeldgegevens die zijn geladen vanuit de eerste rij van de gegevensset of door uw eigen aangepaste voorbeeldgegevens in code op te geven. U moet een voorspelling krijgen die vergelijkbaar is met:
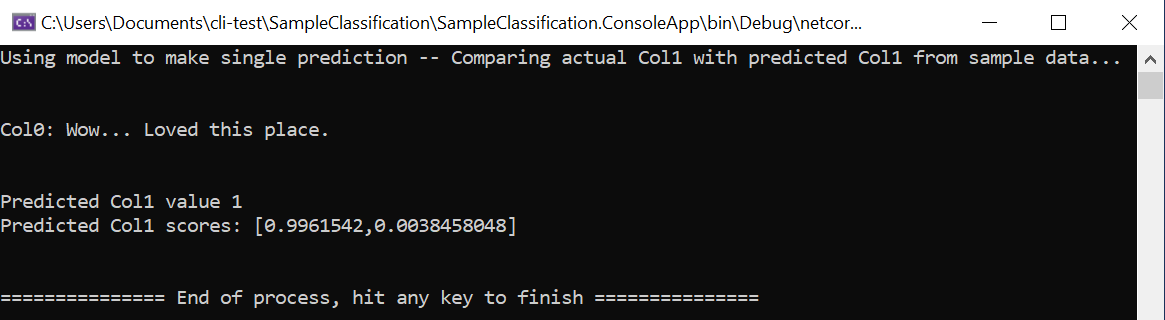
Probeer de in code vastgelegde voorbeeldgegevens te wijzigen in andere zinnen met verschillende sentimenten en kijk hoe het model positieve of negatieve sentiment voorspelt.
Uw eindgebruikerstoepassingen integreren met ML-modelvoorspellingen
U kunt vergelijkbare scorecode voor ML-modellen gebruiken om het model uit te voeren in uw eindgebruikerstoepassing en voorspellingen te doen.
U kunt die code bijvoorbeeld rechtstreeks verplaatsen naar een Windows-bureaubladtoepassing, zoals WPF- en WinForms en het model op dezelfde manier uitvoeren als in de console-app.
De manier waarop u deze regels code implementeert om een ML-model uit te voeren, moet echter worden geoptimaliseerd (dat wil gezegd: het model in de cache opslaan .zip bestand en eenmaal laden) en singleton-objecten hebben in plaats van ze op elke aanvraag te maken, met name als uw toepassing schaalbaar moet zijn, zoals een webtoepassing of gedistribueerde service, zoals wordt uitgelegd in de volgende sectie.
ML.NET-modellen uitvoeren in schaalbare ASP.NET Core-web-apps en -services (apps met meerdere threads)
Het maken van het modelobject (ITransformer geladen vanuit het .zip-bestand van een model) en het PredictionEngine-object moeten worden geoptimaliseerd, met name wanneer het wordt uitgevoerd op schaalbare web-apps en gedistribueerde services. In het eerste geval maakt het modelobject (ITransformer) de optimalisatie eenvoudig. Omdat het ITransformer object thread-safe is, kunt u het object in de cache opslaan als een singleton of statisch object, zodat u het model eenmaal laadt.
Voor het tweede object is het PredictionEngine-object niet zo eenvoudig omdat het PredictionEngine object niet thread-safe is, daarom kunt u dit object niet instantiëren als singleton- of statisch object in een ASP.NET Core-app. Dit thread-veilige en schaalbaarheidsprobleem wordt diep besproken in deze blogpost.
Het is echter veel eenvoudiger voor u dan wat in dat blogbericht wordt uitgelegd. We hebben voor u gewerkt aan een eenvoudigere aanpak en hebben een '.NET Integration Package' gemaakt die u eenvoudig kunt gebruiken in uw ASP.NET Core-apps en -services door deze te registreren in de toepassings-DI-services (Afhankelijkheidsinjectieservices) en deze vervolgens rechtstreeks vanuit uw code te gebruiken. Bekijk de volgende handleiding en het voorbeeld hiervoor:
- Zelfstudie: ML.NET-modellen uitvoeren op schaalbare ASP.NET Core-web-apps en WebAPIs-
- voorbeeld: Schaalbaar ML.NET model op ASP.NET Core WebAPI-
Verken de gegenereerde C#-code die is gebruikt om het model van de beste kwaliteit te trainen
Voor meer geavanceerde leerdoeleinden kunt u ook de gegenereerde C#-code verkennen die door het CLI-hulpprogramma is gebruikt om het gegenereerde model te trainen.
Die trainingsmodelcode wordt gegenereerd in het bestand met de naam SampleClassification.training.cs, zodat u die trainingscode kunt onderzoeken.
Belangrijker is dat u voor dit specifieke scenario (Sentimentanalysemodel) ook die gegenereerde trainingscode kunt vergelijken met de code die in de volgende zelfstudie wordt uitgelegd:
Het is interessant om het gekozen algoritme en de pijplijnconfiguratie in de zelfstudie te vergelijken met de code die is gegenereerd door het CLI-hulpprogramma. Afhankelijk van de tijd die u besteedt aan het herhalen en zoeken naar betere modellen, kan het gekozen algoritme verschillen, samen met de specifieke hyperparameters en pijplijnconfiguratie.
In deze zelfstudie hebt u het volgende geleerd:
- Uw gegevens voorbereiden voor de geselecteerde ML-taak (probleem om op te lossen)
- Voer de opdracht 'mlnet classification' uit in het CLI-hulpprogramma
- De metrische resultaten van de kwaliteit controleren
- Inzicht in de gegenereerde C#-code om het model uit te voeren (code die moet worden gebruikt in uw app voor eindgebruikers)
- Verken de gegenereerde C#-code die is gebruikt om het model van de beste kwaliteit te trainen (verdiendoeleinden)