Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Tip
Deze inhoud is een fragment uit het eBook, .NET Microservices Architecture for Containerized .NET Applications, beschikbaar op .NET Docs of als een gratis downloadbare PDF die offline kan worden gelezen.

Zoals eerder vermeld, moet u fouten afhandelen die mogelijk een variabele tijd in beslag nemen om van te herstellen, zoals kan gebeuren wanneer u verbinding probeert te maken met een externe service of resource. Het afhandelen van dit type fout kan de stabiliteit en tolerantie van een toepassing verbeteren.
In een gedistribueerde omgeving kunnen aanroepen naar externe resources en services mislukken vanwege tijdelijke fouten, zoals trage netwerkverbindingen en time-outs, of als resources langzaam reageren of tijdelijk niet beschikbaar zijn. Deze fouten corrigeren zichzelf doorgaans na korte tijd en een robuuste cloudtoepassing moet worden voorbereid om ze te verwerken met behulp van een strategie zoals het patroon 'Opnieuw proberen'.
Er kunnen echter ook situaties zijn waarin fouten worden veroorzaakt door onverwachte gebeurtenissen die veel langer kunnen duren voordat ze zijn opgelost. Deze fouten kunnen in ernst variëren, van een gedeeltelijke verbroken verbinding tot het volledig uitvallen van een service. In deze situaties kan het zinloos zijn voor een toepassing om voortdurend een bewerking opnieuw uit te voeren die waarschijnlijk niet lukt.
In plaats daarvan moet de toepassing worden gecodeerd om te accepteren dat de bewerking is mislukt en de fout dienovereenkomstig af te handelen.
Het gebruik van http-nieuwe pogingen kan leiden tot een DoS-aanval (Denial of Service) binnen uw eigen software. Als een microservice mislukt of langzaam wordt uitgevoerd, kunnen meerdere clients mislukte aanvragen herhaaldelijk opnieuw proberen. Hierdoor ontstaat een gevaarlijk risico dat exponentieel toenemend verkeer gericht is op de mislukte service.
Daarom hebt u een soort verdedigingsbarrière nodig, zodat overmatige aanvragen stoppen wanneer het niet de moeite waard is om te blijven proberen. Die verdedigingsbarrière is precies de circuitonderbreker.
Het circuitonderbrekerpatroon heeft een ander doel dan het patroon Opnieuw proberen. Met het patroon 'Opnieuw proberen' kan een toepassing een bewerking opnieuw proberen in de verwachting dat de bewerking uiteindelijk zal slagen. Het circuitonderbrekerpatroon voorkomt dat een toepassing een bewerking uitvoert die waarschijnlijk mislukt. Een toepassing kan deze twee patronen combineren. De logica voor opnieuw proberen moet echter gevoelig zijn voor een uitzondering die wordt geretourneerd door de circuitonderbreker en moet pogingen voor opnieuw proberen afbreken als de circuitonderbreker aangeeft dat een fout niet tijdelijk is.
Circuitonderbrekerpatroon implementeren met IHttpClientFactory en Polly
Net als bij het implementeren van nieuwe pogingen, is de aanbevolen aanpak voor circuitonderbrekers om te profiteren van bewezen .NET-bibliotheken zoals Polly en de systeemeigen integratie met IHttpClientFactory.
Het toevoegen van een circuitonderbrekerbeleid aan uw IHttpClientFactory uitgaande middleware-pijplijn is net zo eenvoudig als het toevoegen van één incrementeel stukje code aan wat u al hebt wanneer u deze gebruikt IHttpClientFactory.
De enige toevoeging hier aan de code die wordt gebruikt voor nieuwe pogingen voor HTTP-aanroepen, is de code waarin u het circuitonderbrekerbeleid toevoegt aan de lijst met beleidsregels die u wilt gebruiken, zoals wordt weergegeven in de volgende incrementele code.
// Program.cs
var retryPolicy = GetRetryPolicy();
var circuitBreakerPolicy = GetCircuitBreakerPolicy();
builder.Services.AddHttpClient<IBasketService, BasketService>()
.SetHandlerLifetime(TimeSpan.FromMinutes(5)) // Sample: default lifetime is 2 minutes
.AddHttpMessageHandler<HttpClientAuthorizationDelegatingHandler>()
.AddPolicyHandler(retryPolicy)
.AddPolicyHandler(circuitBreakerPolicy);
De AddPolicyHandler() methode voegt beleidsregels toe aan de HttpClient objecten die u gaat gebruiken. In dit geval wordt een Polly-beleid toegevoegd voor een circuitonderbreker.
Om een meer modulaire benadering te hebben, wordt het circuitonderbrekerbeleid gedefinieerd in een afzonderlijke methode met de naam GetCircuitBreakerPolicy(), zoals wordt weergegeven in de volgende code:
// also in Program.cs
static IAsyncPolicy<HttpResponseMessage> GetCircuitBreakerPolicy()
{
return HttpPolicyExtensions
.HandleTransientHttpError()
.CircuitBreakerAsync(5, TimeSpan.FromSeconds(30));
}
In het bovenstaande codevoorbeeld wordt het circuitonderbrekerbeleid geconfigureerd, zodat het circuit wordt onderbroken of geopend wanneer er vijf opeenvolgende fouten zijn opgetreden bij het opnieuw proberen van de HTTP-aanvragen. Als dat gebeurt, wordt het circuit 30 seconden verbroken: in die periode worden aanroepen onmiddellijk mislukt door de circuitonderbreker in plaats van daadwerkelijk te worden geplaatst. Het beleid interpreteert automatisch relevante uitzonderingen en HTTP-statuscodes als fouten.
Circuitonderbrekers moeten ook worden gebruikt om aanvragen om te leiden naar een terugvalinfrastructuur als u problemen hebt met een bepaalde resource die is geïmplementeerd in een andere omgeving dan de clienttoepassing of -service die de HTTP-aanroep uitvoert. Als er een storing optreedt in het datacenter dat alleen van invloed is op uw back-endmicroservices, maar niet op uw clienttoepassingen, kunnen de clienttoepassingen omleiden naar de terugvalservices. Polly plant een nieuw beleid om dit failoverbeleidsscenario te automatiseren.
Al deze functies zijn voor gevallen waarin u de failover vanuit de .NET-code beheert, in plaats van dat deze automatisch voor u wordt beheerd door Azure, met locatietransparantie.
Als u HttpClient gebruikt, hoeft u hier niets nieuws toe te voegen, omdat de code hetzelfde is als bij gebruik HttpClient met IHttpClientFactory, zoals wordt weergegeven in de vorige secties.
Http-nieuwe pogingen en circuitonderbrekers testen in eShopOnContainers
Wanneer u de eShopOnContainers-oplossing in een Docker-host start, moet deze meerdere containers starten. Sommige containers zijn langzamer om te starten en te initialiseren, zoals de SQL Server-container. Dit geldt met name wanneer u de eShopOnContainers-toepassing voor het eerst in Docker implementeert, omdat deze de installatiekopieën en de database moet instellen. Het feit dat sommige containers langzamer beginnen dan andere containers kunnen ertoe leiden dat de rest van de services in eerste instantie HTTP-uitzonderingen genereert, zelfs als u afhankelijkheden tussen containers op docker-compose-niveau instelt, zoals wordt uitgelegd in de vorige secties. Deze docker-compose-afhankelijkheden tussen containers bevinden zich alleen op procesniveau. Het invoerpuntproces van de container kan worden gestart, maar SQL Server is mogelijk niet gereed voor query's. Het resultaat kan een trapsgewijs aantal fouten zijn en de toepassing kan een uitzondering krijgen bij het gebruik van die specifieke container.
Mogelijk ziet u dit type fout bij het opstarten wanneer de toepassing in de cloud wordt geïmplementeerd. In dat geval verplaatsen orchestrators containers mogelijk van het ene knooppunt of de VM naar het andere (dat wil gezegd, nieuwe exemplaren starten) bij het verdelen van het aantal containers op de knooppunten van het cluster.
De manier waarop 'eShopOnContainers' deze problemen oplost bij het starten van alle containers, is met behulp van het patroon Opnieuw proberen dat eerder is geïllustreerd.
De circuitonderbreker testen in eShopOnContainers
Er zijn een aantal manieren waarop u het circuit kunt onderbreken/openen en testen met eShopOnContainers.
Een optie is om het toegestane aantal nieuwe pogingen te verlagen naar 1 in het circuitonderbrekerbeleid en de hele oplossing opnieuw te implementeren in Docker. Met één nieuwe poging is er een goede kans dat een HTTP-aanvraag mislukt tijdens de implementatie, de circuitonderbreker wordt geopend en u een fout krijgt.
Een andere optie is om aangepaste middleware te gebruiken die is geïmplementeerd in de Basket-microservice . Wanneer deze middleware is ingeschakeld, worden alle HTTP-aanvragen onderschept en statuscode 500 geretourneerd. U kunt de middleware inschakelen door een GET-aanvraag naar de mislukte URI te verzenden, zoals de volgende:
GET http://localhost:5103/failing
Deze aanvraag retourneert de huidige status van de middleware. Als de middleware is ingeschakeld, retourneert de aanvraag statuscode 500. Als de middleware is uitgeschakeld, is er geen antwoord.GET http://localhost:5103/failing?enable
Met deze aanvraag wordt de middleware ingeschakeld.GET http://localhost:5103/failing?disable
Met deze aanvraag wordt de middleware uitgeschakeld.
Zodra de toepassing wordt uitgevoerd, kunt u bijvoorbeeld de middleware inschakelen door een aanvraag in te dienen met behulp van de volgende URI in elke browser. Houd er rekening mee dat de bestellende microservice gebruikmaakt van poort 5103.
http://localhost:5103/failing?enable
Vervolgens kunt u de status controleren met behulp van de URI http://localhost:5103/failing, zoals weergegeven in afbeelding 8-5.
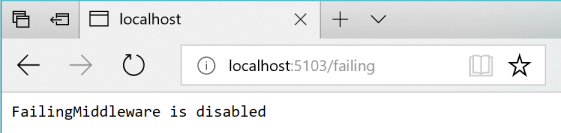
Afbeelding 8-5. Controleren van de status van de ASP.NET middleware : in dit geval uitgeschakeld.
Op dit moment reageert de Basket-microservice met statuscode 500 wanneer u deze aanroept.
Zodra de middleware wordt uitgevoerd, kunt u proberen een bestelling te maken vanuit de MVC-webtoepassing. Omdat de aanvragen mislukken, wordt het circuit geopend.
In het volgende voorbeeld ziet u dat de MVC-webtoepassing een catch-blok heeft in de logica voor het plaatsen van een order. Als de code een uitzondering voor een open circuit onderschept, wordt de gebruiker een vriendelijk bericht weergegeven waarin staat dat ze moeten wachten.
public class CartController : Controller
{
//…
public async Task<IActionResult> Index()
{
try
{
var user = _appUserParser.Parse(HttpContext.User);
//Http requests using the Typed Client (Service Agent)
var vm = await _basketSvc.GetBasket(user);
return View(vm);
}
catch (BrokenCircuitException)
{
// Catches error when Basket.api is in circuit-opened mode
HandleBrokenCircuitException();
}
return View();
}
private void HandleBrokenCircuitException()
{
TempData["BasketInoperativeMsg"] = "Basket Service is inoperative, please try later on. (Business message due to Circuit-Breaker)";
}
}
Hier volgt een overzicht. Het beleid voor opnieuw proberen probeert meerdere keren de HTTP-aanvraag te maken en http-fouten op te halen. Wanneer het aantal nieuwe pogingen het maximumaantal bereikt dat is ingesteld voor het circuitonderbrekerbeleid (in dit geval 5), genereert de toepassing een BrokenCircuitException. Het resultaat is een vriendelijk bericht, zoals wordt weergegeven in afbeelding 8-6.
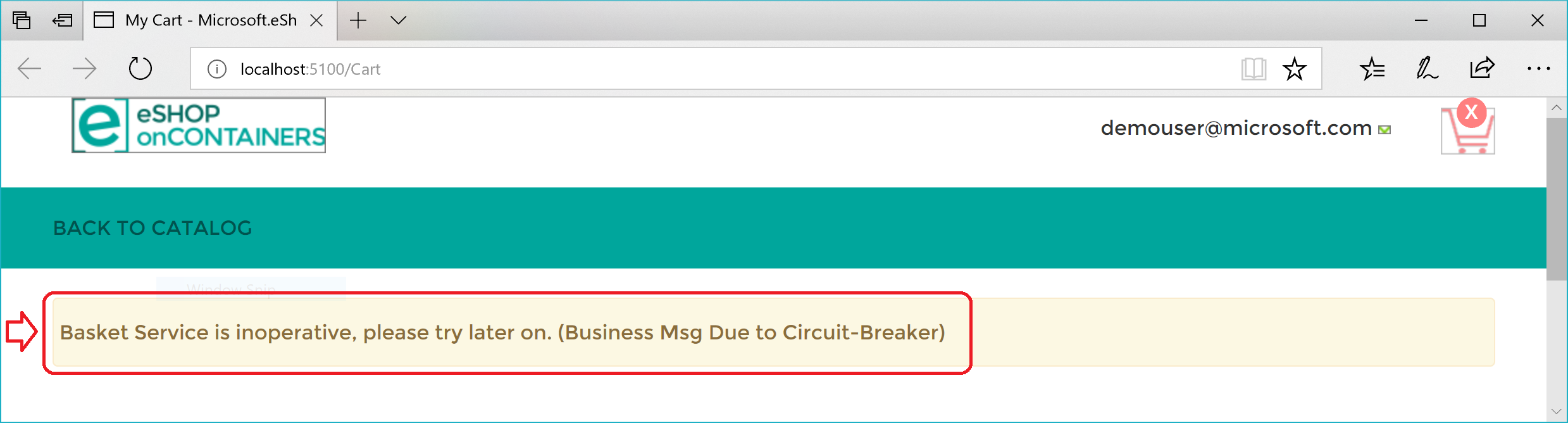
Afbeelding 8-6. Circuitonderbreker retourneert een fout in de gebruikersinterface
U kunt verschillende logica implementeren voor het openen/verbreken van het circuit. U kunt ook een HTTP-aanvraag proberen op basis van een andere back-end microservice als er een terugvalcentrum of een redundant back-endsysteem is.
Ten slotte is er nog een mogelijkheid om het CircuitBreakerPolicy circuit te gebruiken Isolate (waardoor het circuit open en vasthoudt) en Reset (waardoor het opnieuw wordt gesloten). Deze kunnen worden gebruikt om een HTTP-eindpunt voor het hulpprogramma te bouwen dat isoleren en opnieuw instellen rechtstreeks op het beleid aanroept. Een dergelijk HTTP-eindpunt kan ook worden gebruikt, geschikt beveiligd, in productie voor het tijdelijk isoleren van een downstreamsysteem, bijvoorbeeld wanneer u het wilt upgraden. Of het circuit kan handmatig worden gebruikt om een downstreamsysteem te beveiligen dat u vermoedt dat deze fouten veroorzaakt.
Aanvullende bronnen
- Patroon Circuitonderbreker
https://learn.microsoft.com/azure/architecture/patterns/circuit-breaker
Met ons samenwerken op GitHub
De bron voor deze inhoud vindt u op GitHub, waar u ook problemen en pull-aanvragen kunt maken en controleren. Bekijk onze gids voor inzenders voor meer informatie.