Gegevenssoevereine per microservice
Tip
Deze inhoud is een fragment uit het eBook, .NET Microservices Architecture for Containerized .NET Applications, beschikbaar op .NET Docs of als een gratis downloadbare PDF die offline kan worden gelezen.

Een belangrijke regel voor microservicesarchitectuur is dat elke microservice eigenaar moet zijn van domeingegevens en logica. Net zoals een volledige toepassing eigenaar is van de logica en gegevens, moet elke microservice dus eigenaar zijn van de logica en gegevens in een autonome levenscyclus, met onafhankelijke implementatie per microservice.
Dit betekent dat het conceptuele model van het domein verschilt tussen subsystemen of microservices. Overweeg bedrijfstoepassingen, waarbij CRM-toepassingen (Customer Relationship Management), transactionele aankoopsubsystemen en subsystemen voor klantondersteuning elke aanroep van unieke kenmerken en gegevens van de klantentiteit, en waar elk een andere gebonden context (BC) gebruikt.
Dit principe is vergelijkbaar in domeingestuurd ontwerp (DDD), waarbij elk gebonden context of autonome subsysteem of service eigenaar moet zijn van het domeinmodel (gegevens plus logica en gedrag). Elke DDD Gebonden context correleert met één zakelijke microservice (een of meerdere services). Dit punt over het patroon Gebonden context wordt uitgevouwen in de volgende sectie.
Aan de andere kant is de traditionele benadering (monolithische gegevens) die in veel toepassingen wordt gebruikt, het hebben van één gecentraliseerde database of slechts een paar databases. Dit is vaak een genormaliseerde SQL-database die wordt gebruikt voor de hele toepassing en alle bijbehorende interne subsystemen, zoals wordt weergegeven in afbeelding 4-7.
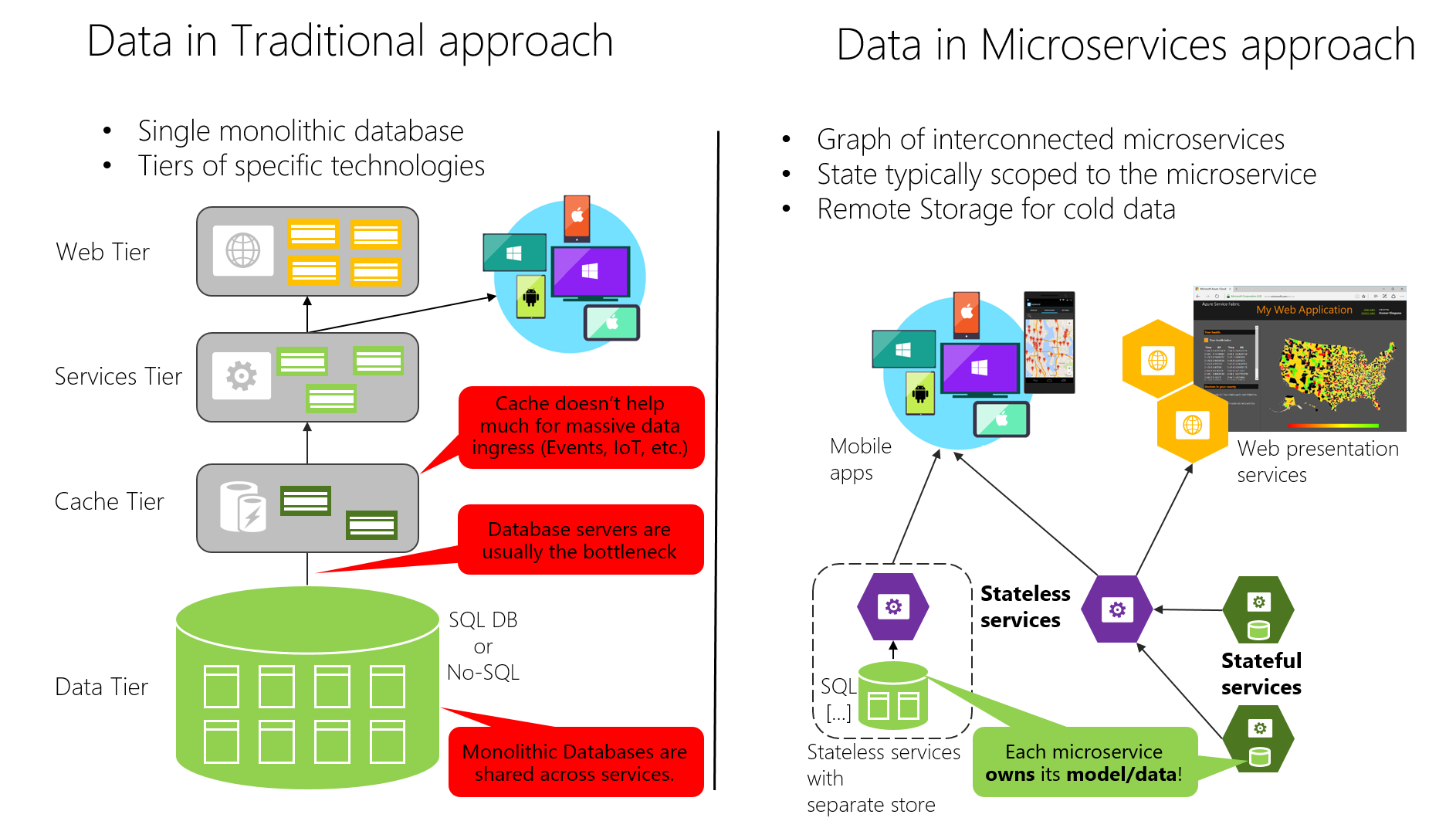
Afbeelding 4-7. Vergelijking van gegevenssoevereine gegevens: monolithische database versus microservices
In de traditionele benadering is er één database die wordt gedeeld in alle services, meestal in een gelaagde architectuur. In de microservicesbenadering is elke microservice eigenaar van het model/de gegevens. De gecentraliseerde databasebenadering ziet er in eerste instantie eenvoudiger uit en lijkt het hergebruik van entiteiten in verschillende subsystemen mogelijk te maken om alles consistent te maken. Maar de realiteit is dat u eindigt met enorme tabellen die veel verschillende subsystemen dienen en die kenmerken en kolommen bevatten die in de meeste gevallen niet nodig zijn. Het is alsof u dezelfde fysieke kaart probeert te gebruiken voor het wandelen van een korte route, het maken van een dag-lange autoreis en het leren van geografie.
Een monolithische toepassing met doorgaans één relationele database heeft twee belangrijke voordelen: ACID-transacties en de SQL-taal, die beide werken in alle tabellen en gegevens die betrekking hebben op uw toepassing. Deze benadering biedt een manier om eenvoudig een query te schrijven waarin gegevens uit meerdere tabellen worden gecombineerd.
Gegevenstoegang wordt echter veel ingewikkelder wanneer u overstapt op een microservicesarchitectuur. Zelfs wanneer u ACID-transacties binnen een microservice of gebonden context gebruikt, is het van cruciaal belang om te overwegen dat de gegevens die eigendom zijn van elke microservice privé zijn voor die microservice en alleen synchroon moeten worden geopend via de API-eindpunten (REST, gRPC, SOAP, enzovoort) of asynchroon via berichten (AMQP of vergelijkbaar).
Het inkapselen van de gegevens zorgt ervoor dat de microservices losjes worden gekoppeld en onafhankelijk van elkaar kunnen worden ontwikkeld. Als meerdere services toegang hadden tot dezelfde gegevens, zouden schema-updates gecoördineerde updates voor alle services vereisen. Dit zou de autonomie van de microservicelevenscyclus verbreken. Maar gedistribueerde gegevensstructuren betekenen dat u geen enkele ACID-transactie kunt maken voor microservices. Dit betekent op zijn beurt dat u uiteindelijke consistentie moet gebruiken wanneer een bedrijfsproces meerdere microservices omvat. Dit is veel moeilijker te implementeren dan eenvoudige SQL-joins, omdat u geen integriteitsbeperkingen kunt maken of gedistribueerde transacties tussen afzonderlijke databases kunt gebruiken, zoals later wordt uitgelegd. Op dezelfde manier zijn veel andere relationele databasefuncties niet beschikbaar voor meerdere microservices.
Nog verder gaan, verschillende microservices gebruiken vaak verschillende soorten databases. Moderne toepassingen slaan diverse soorten gegevens op en verwerken en een relationele database is niet altijd de beste keuze. Voor sommige gebruiksscenario's kan een NoSQL-database, zoals Azure CosmosDB of MongoDB, een handiger gegevensmodel hebben en betere prestaties en schaalbaarheid bieden dan een SQL-database zoals SQL Server of Azure SQL Database. In andere gevallen is een relationele database nog steeds de beste benadering. Daarom gebruiken microservicestoepassingen vaak een combinatie van SQL- en NoSQL-databases, ook wel de polyglot persistence-benadering genoemd.
Een gepartitioneerde, polyglot-permanente architectuur voor gegevensopslag heeft veel voordelen. Deze omvatten losjes gekoppelde services en betere prestaties, schaalbaarheid, kosten en beheerbaarheid. Het kan echter enkele problemen met gedistribueerd gegevensbeheer introduceren, zoals verderop in dit hoofdstuk wordt uitgelegd in 'Grenzen van domeinmodel identificeren'.
De relatie tussen microservices en het patroon Gebonden context
Het concept van microservice is afgeleid van het BC-patroon (Bounded Context) in domeingestuurd ontwerp (DDD). DDD behandelt grote modellen door ze op te delen in meerdere PC's en expliciet over hun grenzen te zijn. Elke BC moet een eigen model en database hebben; op dezelfde manier is elke microservice eigenaar van de gerelateerde gegevens. Bovendien heeft elke BC meestal een eigen alomtegenwoordige taal om communicatie tussen softwareontwikkelaars en domeinexperts te helpen.
Deze termen (voornamelijk domeinentiteiten) in de alomtegenwoordige taal kunnen verschillende namen hebben in verschillende contexten, zelfs als verschillende domeinentiteiten dezelfde identiteit delen (dat wil gezegd de unieke id die wordt gebruikt om de entiteit uit de opslag te lezen). In een gebruikersprofiel gebonden context kan de entiteit Gebruikersdomein bijvoorbeeld identiteit delen met de entiteit Koper-domein in de volgorde gebonden context.
Een microservice is daarom net als een gebonden context, maar geeft ook aan dat het een gedistribueerde service is. Het is gebouwd als een afzonderlijk proces voor elke gebonden context en moet gebruikmaken van de gedistribueerde protocollen die eerder zijn genoteerd, zoals HTTP/HTTPS, WebSockets of AMQP. Het patroon Gebonden context geeft echter niet op of de gebonden context een gedistribueerde service is of dat het gewoon een logische grens (zoals een algemeen subsysteem) is binnen een monolithische implementatietoepassing.
Het is belangrijk om te benadrukken dat het definiëren van een service voor elke gebonden context een goede plek is om te beginnen. Maar u hoeft uw ontwerp hiervoor niet te beperken. Soms moet u een gebonden context of zakelijke microservice ontwerpen die bestaat uit verschillende fysieke services. Maar uiteindelijk zijn zowel patronen - Gebonden context als microservice - nauw verwant.
DDD profiteert van microservices door echte grenzen te verkrijgen in de vorm van gedistribueerde microservices. Maar ideeën zoals het niet delen van het model tussen microservices zijn wat u ook wilt in een gebonden context.
Aanvullende bronnen
Chris Richardson. Patroon: Database per service
https://microservices.io/patterns/data/database-per-service.htmlMartin Fowler. BoundedContext
https://martinfowler.com/bliki/BoundedContext.htmlMartin Fowler. PolyglotPersistence
https://martinfowler.com/bliki/PolyglotPersistence.htmlAlberto Brandolini. Strategisch domeingestuurd ontwerp met contexttoewijzing
https://www.infoq.com/articles/ddd-contextmapping