Tolerantie van Azure-platform
Tip
Deze inhoud is een fragment uit het eBook, Cloud Native .NET Applications for Azure ontwerpen, beschikbaar op .NET Docs of als een gratis downloadbare PDF die offline kan worden gelezen.

Het bouwen van een betrouwbare toepassing in de cloud verschilt van traditionele on-premises toepassingsontwikkeling. Hoewel u historisch gezien hardware hebt gekocht om omhoog te schalen, schaalt u in een cloudomgeving uit. In plaats van fouten te voorkomen, is het doel hun effecten te minimaliseren en het systeem stabiel te houden.
Dat gezegd hebbende: betrouwbare cloudtoepassingen geven verschillende kenmerken weer:
- Ze zijn tolerant, herstellen probleemloos en blijven functioneren.
- Ze zijn maximaal beschikbaar (HA) en worden uitgevoerd zoals ontworpen in een gezonde status zonder significante downtime.
Inzicht in hoe deze kenmerken samenwerken , en hoe deze van invloed zijn op de kosten, is essentieel voor het bouwen van een betrouwbare cloudeigen toepassing. We gaan nu kijken naar manieren waarop u tolerantie en beschikbaarheid kunt bouwen in uw cloudeigen toepassingen die gebruikmaken van functies uit de Azure-cloud.
Ontwerpen met tolerantie
We hebben gezegd dat tolerantie ervoor zorgt dat uw toepassing reageert op fouten en nog steeds functioneel blijft. Het technisch document Tolerantie in Azure biedt richtlijnen voor het bereiken van tolerantie in het Azure-platform. Hier volgen enkele belangrijke aanbevelingen:
Hardwarefout. Bouw redundantie in de toepassing door onderdelen in verschillende foutdomeinen te implementeren. Zorg er bijvoorbeeld voor dat azure-VM's in verschillende rekken worden geplaatst met behulp van beschikbaarheidssets.
Datacenterfout. Bouw redundantie in de toepassing met foutisolatiezones in datacenters. Zorg er bijvoorbeeld voor dat azure-VM's in verschillende fout-geïsoleerde datacenters worden geplaatst met behulp van Azure Beschikbaarheidszones.
Regionale storing. Repliceer de gegevens en onderdelen in een andere regio, zodat toepassingen snel kunnen worden hersteld. Gebruik bijvoorbeeld Azure Site Recovery om Virtuele Azure-machines te repliceren naar een andere Azure-regio.
Zware belasting. Taakverdeling over exemplaren voor het afhandelen van pieken in gebruik. Plaats bijvoorbeeld twee of meer Azure-VM's achter een load balancer om verkeer naar alle VM's te distribueren.
Onopzettelijke gegevensverwijdering of beschadiging. Maak een back-up van gegevens, zodat deze kunnen worden hersteld als er sprake is van verwijdering of beschadiging. Gebruik bijvoorbeeld Azure Backup om periodiek een back-up te maken van uw Virtuele Azure-machines.
Ontwerpen met redundantie
Fouten variëren binnen het bereik van de impact. Een hardwarefout, zoals een mislukte schijf, kan van invloed zijn op één knooppunt in een cluster. Een mislukte netwerkswitch kan van invloed zijn op een volledig serverrek. Minder veelvoorkomende storingen, zoals stroomverlies, kunnen een heel datacenter verstoren. Zelden is een hele regio niet meer beschikbaar.
Redundantie is een manier om toepassingstolerantie te bieden. Het exacte redundantieniveau dat nodig is, is afhankelijk van uw bedrijfsvereisten en is van invloed op zowel de kosten als de complexiteit van uw systeem. Een implementatie met meerdere regio's is bijvoorbeeld duurder en complexer om te beheren dan een implementatie met één regio. U hebt operationele procedures nodig om failover en failback te beheren. De extra kosten en complexiteit zijn mogelijk gerechtvaardigd voor sommige bedrijfsscenario's, maar niet voor andere.
Als u redundantie wilt ontwerpen, moet u de kritieke paden in uw toepassing identificeren en vervolgens bepalen of er redundantie is op elk punt in het pad? Als een subsysteem moet mislukken, voert de toepassing een failover uit naar iets anders? Ten slotte hebt u een duidelijk inzicht nodig in deze functies die zijn ingebouwd in het Azure-cloudplatform dat u kunt gebruiken om te voldoen aan uw redundantievereisten. Hier volgen aanbevelingen voor het ontwerpen van redundantie:
Implementeer meerdere exemplaren van services. Als uw toepassing afhankelijk is van één exemplaar van een service, wordt er één storingspunt gemaakt. Het inrichten van meerdere exemplaren verbetert zowel tolerantie als schaalbaarheid. Wanneer u host in Azure Kubernetes Service, kunt u redundante exemplaren (replicasets) declaratief configureren in het Kubernetes-manifestbestand. De waarde voor het aantal replica's kan programmatisch worden beheerd, in de portal of via functies voor automatisch schalen.
Een load balancer gebruiken. Taakverdeling verdeelt de aanvragen van uw toepassing naar gezonde service-exemplaren en verwijdert automatisch beschadigde exemplaren uit roulatie. Bij de implementatie in Kubernetes kan taakverdeling worden opgegeven in het Kubernetes-manifestbestand in de sectie Services.
Plan de implementatie van meerdere regio's. Als u uw toepassing in één regio implementeert en die regio niet meer beschikbaar is, is uw toepassing ook niet meer beschikbaar. Dit kan onaanvaardbaar zijn onder de voorwaarden van de serviceovereenkomsten van uw toepassing. In plaats daarvan kunt u overwegen uw toepassing en de bijbehorende services in meerdere regio's te implementeren. Een AKS-cluster (Azure Kubernetes Service) wordt bijvoorbeeld geïmplementeerd in één regio. Als u uw systeem wilt beschermen tegen een regionale fout, kunt u uw toepassing implementeren in meerdere AKS-clusters in verschillende regio's en de functie Gekoppelde regio's gebruiken om platformupdates te coördineren en prioriteit te geven aan herstelinspanningen.
Geo-replicatie inschakelen. Geo-replicatie voor services zoals Azure SQL Database en Cosmos DB maakt secundaire replica's van uw gegevens in meerdere regio's. Hoewel beide services automatisch gegevens binnen dezelfde regio repliceren, beschermt geo-replicatie u tegen een regionale storing door een failover naar een secundaire regio in te schakelen. Een andere best practice voor geo-replicatiecentra rond het opslaan van containerinstallatiekopieën. Als u een service in AKS wilt implementeren, moet u de installatiekopie opslaan en ophalen uit een opslagplaats. Azure Container Registry kan worden geïntegreerd met AKS en kan containerinstallatiekopieën veilig opslaan. Als u de prestaties en beschikbaarheid wilt verbeteren, kunt u overwegen om uw installatiekopieën te repliceren naar een register in elke regio waar u een AKS-cluster hebt. Elk AKS-cluster haalt vervolgens containerinstallatiekopieën op uit het lokale containerregister in de regio, zoals wordt weergegeven in afbeelding 6-4:
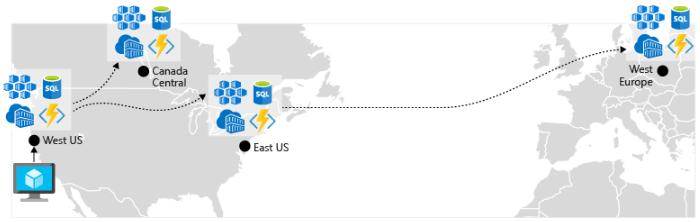
Afbeelding 6-4. Gerepliceerde resources in verschillende regio's
- Implementeer een load balancer voor DNS-verkeer.Azure Traffic Manager biedt hoge beschikbaarheid voor kritieke toepassingen door taakverdeling op DNS-niveau. Het kan verkeer routeren naar verschillende regio's op basis van geografie, reactietijd van het cluster en zelfs de status van het toepassingseindpunt. Zo kan Azure Traffic Manager klanten omleiden naar het dichtstbijzijnde AKS-cluster en het dichtstbijzijnde toepassingsexemplaren. Als u meerdere AKS-clusters in verschillende regio's hebt, gebruikt u Traffic Manager om te bepalen hoe verkeer stroomt naar de toepassingen die in elk cluster worden uitgevoerd. In afbeelding 6-5 ziet u dit scenario.
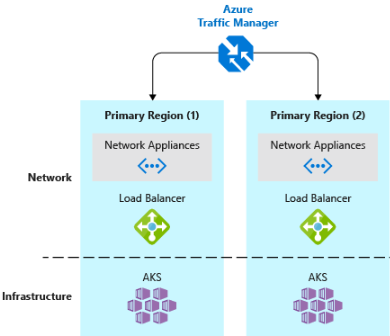
Afbeelding 6-5. AKS en Azure Traffic Manager
Ontwerpen voor schaalbaarheid
De cloud bloeit op schaalaanpassing. De mogelijkheid om systeemresources te vergroten/verlagen om de toenemende/afnemende systeembelasting aan te pakken, is een belangrijk tenet van de Azure-cloud. Maar om een toepassing effectief te schalen, hebt u inzicht nodig in de schaalfuncties van elke Azure-service die u in uw toepassing opneemt. Hier volgen aanbevelingen voor het effectief implementeren van schalen in uw systeem.
Ontwerp voor schalen. Een toepassing moet zijn ontworpen voor schalen. Om te beginnen moeten services staatloos zijn, zodat aanvragen naar elk exemplaar kunnen worden doorgestuurd. Als u stateless services hebt, betekent dit ook dat het toevoegen of verwijderen van een exemplaar geen negatieve gevolgen heeft voor huidige gebruikers.
Partitieworkloads. Als u domeinen uitsplitst in onafhankelijke, zelfstandige microservices, kan elke service onafhankelijk van anderen worden geschaald. Normaal gesproken hebben services verschillende schaalbaarheidsbehoeften en -vereisten. Met partitionering kunt u alleen schalen wat moet worden geschaald zonder de onnodige kosten voor het schalen van een hele toepassing.
Gun uitschalen. Cloudtoepassingen geven de voorkeur aan het uitschalen van resources in plaats van omhoog te schalen. Uitschalen (ook wel horizontaal schalen genoemd) omvat het toevoegen van meer serviceresources aan een bestaand systeem om aan een gewenst prestatieniveau te voldoen en te delen. Omhoog schalen (ook wel verticaal schalen genoemd) omvat het vervangen van bestaande resources door krachtigere hardware (meer schijf-, geheugen- en verwerkingskernen). Uitschalen kan automatisch worden aangeroepen met de functies voor automatisch schalen die beschikbaar zijn in sommige Azure-cloudresources. Door uit te schalen over meerdere resources wordt ook redundantie toegevoegd aan het algehele systeem. Ten slotte is het omhoog schalen van één resource doorgaans duurder dan het uitschalen van veel kleinere resources. In afbeelding 6-6 ziet u de twee benaderingen:
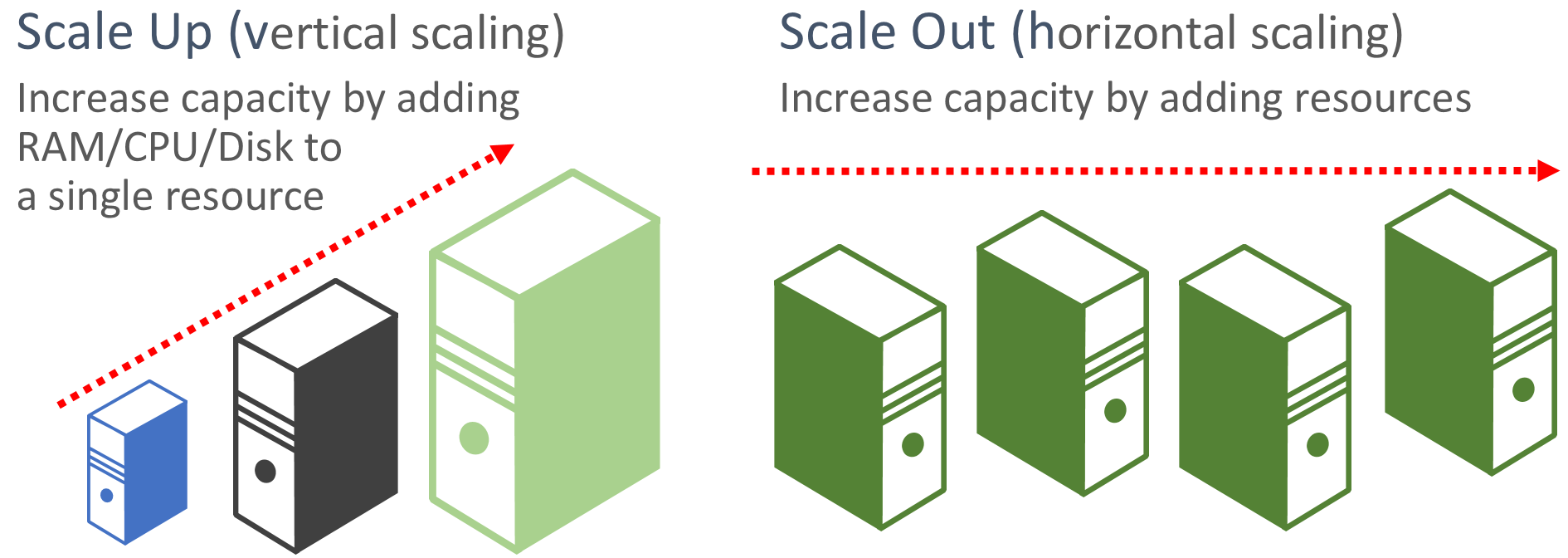
Afbeelding 6-6. Omhoog schalen versus uitschalen
Schaal proportioneel. Denk bij het schalen van een service na over resourcesets. Welke invloed zou het hebben op back-endgegevensarchieven, caches en afhankelijke services als u een specifieke service drastisch zou uitschalen? Sommige resources, zoals Cosmos DB, kunnen proportioneel worden uitgeschaald, terwijl veel andere niet. U wilt ervoor zorgen dat u een resource niet uitschaalt naar een punt waar andere gekoppelde resources worden uitgeput.
Vermijd affiniteit. Een best practice is ervoor te zorgen dat een knooppunt geen lokale affiniteit vereist, ook wel een plaksessie genoemd. Een aanvraag moet naar elk exemplaar kunnen worden gerouteerd. Als u de status wilt behouden, moet deze worden opgeslagen in een gedistribueerde cache, zoals Azure Redis-cache.
Profiteer van functies voor automatisch schalen van platformen. Gebruik waar mogelijk ingebouwde functies voor automatisch schalen in plaats van aangepaste of mechanismen van derden. Gebruik waar mogelijk geplande schaalregels om ervoor te zorgen dat resources beschikbaar zijn zonder opstartvertraging, maar voeg indien nodig reactief automatisch schalen toe aan de regels om onverwachte wijzigingen in de vraag aan te kunnen. Zie Richtlijnen voor automatisch schalen voor meer informatie.
Schaal agressief uit. Een laatste praktijk is om agressief uit te schalen, zodat u snel snelle pieken in het verkeer kunt tegenkomen zonder dat u zaken kwijtraakt. En schaal vervolgens voorzichtig in (dat wil gezegd overbodige instanties verwijderen) om het systeem stabiel te houden. Een eenvoudige manier om dit te implementeren, is het instellen van de afkoelperiode, de tijd die moet worden gewacht tussen schaalbewerkingen, tot vijf minuten voor het toevoegen van resources en maximaal 15 minuten voor het verwijderen van exemplaren.
Ingebouwde nieuwe poging in services
We hebben de aanbevolen procedure voor het implementeren van programmatische bewerkingen voor opnieuw proberen in een eerdere sectie aangemoedigd. Houd er rekening mee dat veel Azure-services en de bijbehorende client-SDK's ook mechanismen voor opnieuw proberen bevatten. De volgende lijst bevat een overzicht van functies voor opnieuw proberen in de vele Azure-services die in dit boek worden besproken:
Azure Cosmos DB. Met de DocumentClient-klasse van de client-API worden mislukte pogingen automatisch opnieuw geprobeerd. Het aantal nieuwe pogingen en de maximale wachttijd kan worden geconfigureerd. Uitzonderingen die worden gegenereerd door de client-API zijn aanvragen die het beleid voor opnieuw proberen of niet-tijdelijke fouten overschrijden.
Azure Redis Cache. De Redis StackExchange-client maakt gebruik van een verbindingsbeheerklasse die nieuwe pogingen voor mislukte pogingen bevat. Het aantal nieuwe pogingen, het specifieke beleid voor opnieuw proberen en de wachttijd zijn allemaal configureerbaar.
Azure Service Bus. De Service Bus-client maakt een RetryPolicy-klasse beschikbaar die kan worden geconfigureerd met een back-off-interval, het aantal nieuwe pogingen en TerminationTimeBuffer, waarmee wordt aangegeven hoe lang een bewerking kan duren. Het standaardbeleid is negen maximaal aantal nieuwe pogingen met een uitstelperiode van 30 seconden tussen pogingen.
Azure SQL-database. Ondersteuning voor opnieuw proberen wordt geboden bij het gebruik van de Entity Framework Core-bibliotheek .
Azure Storage. De opslagclientbibliotheek biedt ondersteuning voor bewerkingen voor opnieuw proberen. De strategieën verschillen per Azure-opslagtabel, -blobs en -wachtrijen. Daarnaast schakelen alternatieve nieuwe pogingen tussen de locaties van primaire en secundaire opslagservices wanneer de functie voor georedundantie is ingeschakeld.
Azure Event Hubs. De Event Hub-clientbibliotheek bevat een retryPolicy-eigenschap, die een configureerbare functie voor exponentieel uitstel bevat.