Cloudeigen gegevenspatronen
Tip
Deze inhoud is een fragment uit het eBook, Cloud Native .NET Applications for Azure ontwerpen, beschikbaar op .NET Docs of als een gratis downloadbare PDF die offline kan worden gelezen.

Zoals we in dit boek hebben gezien, verandert een cloudeigen benadering de manier waarop u toepassingen ontwerpt, implementeert en beheert. Het verandert ook de manier waarop u gegevens beheert en opslaat.
Afbeelding 5-1 contrasteert de verschillen.
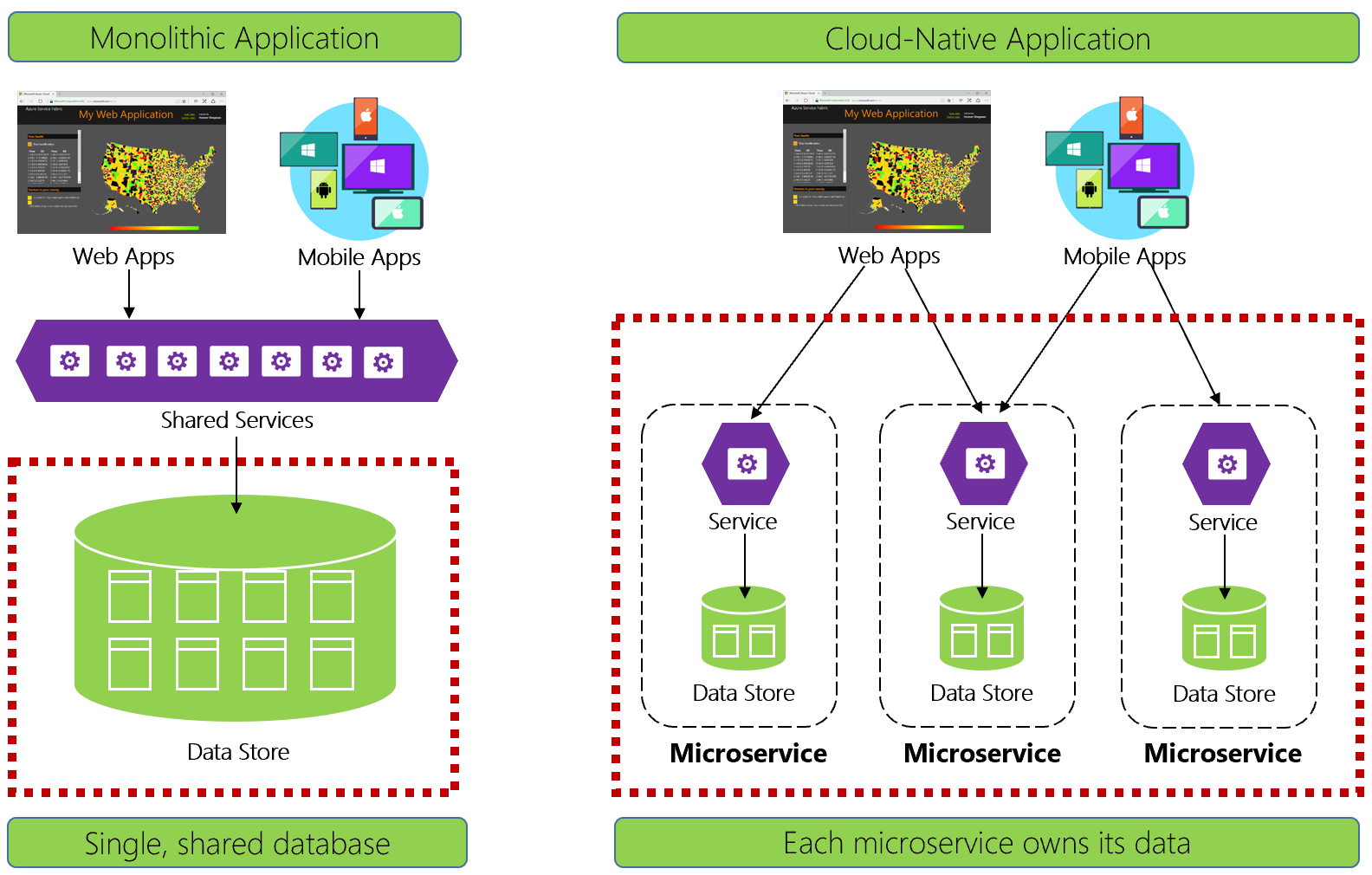
Afbeelding 5-1. Gegevensbeheer in cloudtoepassingen
Ervaren ontwikkelaars herkennen de architectuur aan de linkerkant van afbeelding 5-1. In deze monolithische toepassing delen bedrijfsserviceonderdelen samen in een gedeelde serviceslaag gegevens uit één relationele database.
Op veel manieren houdt één database gegevensbeheer eenvoudig. Het uitvoeren van query's op gegevens in meerdere tabellen is eenvoudig. Wijzigingen in gegevens worden samen bijgewerkt of ze worden allemaal teruggedraaid. ACID-transacties garanderen een sterke en onmiddellijke consistentie.
Ontwerpen voor cloudeigen, we hanteren een andere benadering. Aan de rechterkant van afbeelding 5-1 ziet u hoe de bedrijfsfunctionaliteit wordt gescheiden in kleine, onafhankelijke microservices. Elke microservice omvat een specifieke bedrijfsmogelijkheid en zijn eigen gegevens. De monolithische database is onderverdeeld in een gedistribueerd gegevensmodel met veel kleinere databases, die elk worden uitgelijnd met een microservice. Wanneer de rook leeg is, komen we uit met een ontwerp dat een database per microservice blootstelt.
Database-per-microservice, waarom?
Deze database per microservice biedt veel voordelen, met name voor systemen die snel moeten evolueren en grootschalige schaal moeten ondersteunen. Met dit model...
- Domeingegevens worden ingekapseld binnen de service
- Gegevensschema kan zich ontwikkelen zonder dat dit rechtstreeks van invloed is op andere services
- Elk gegevensarchief kan onafhankelijk worden geschaald
- Een fout in het gegevensarchief in de ene service heeft niet rechtstreeks invloed op andere services
Door gegevens te scheiden, kan elke microservice ook het gegevensarchieftype implementeren dat het beste is geoptimaliseerd voor de workload, opslagbehoeften en lees-/schrijfpatronen. Opties zijn onder andere relationele gegevensarchieven, documenten, sleutelwaarden en zelfs gegevensarchieven op basis van grafieken.
In afbeelding 5-2 wordt het principe van polyglotpersistentie in een cloudeigen systeem gepresenteerd.
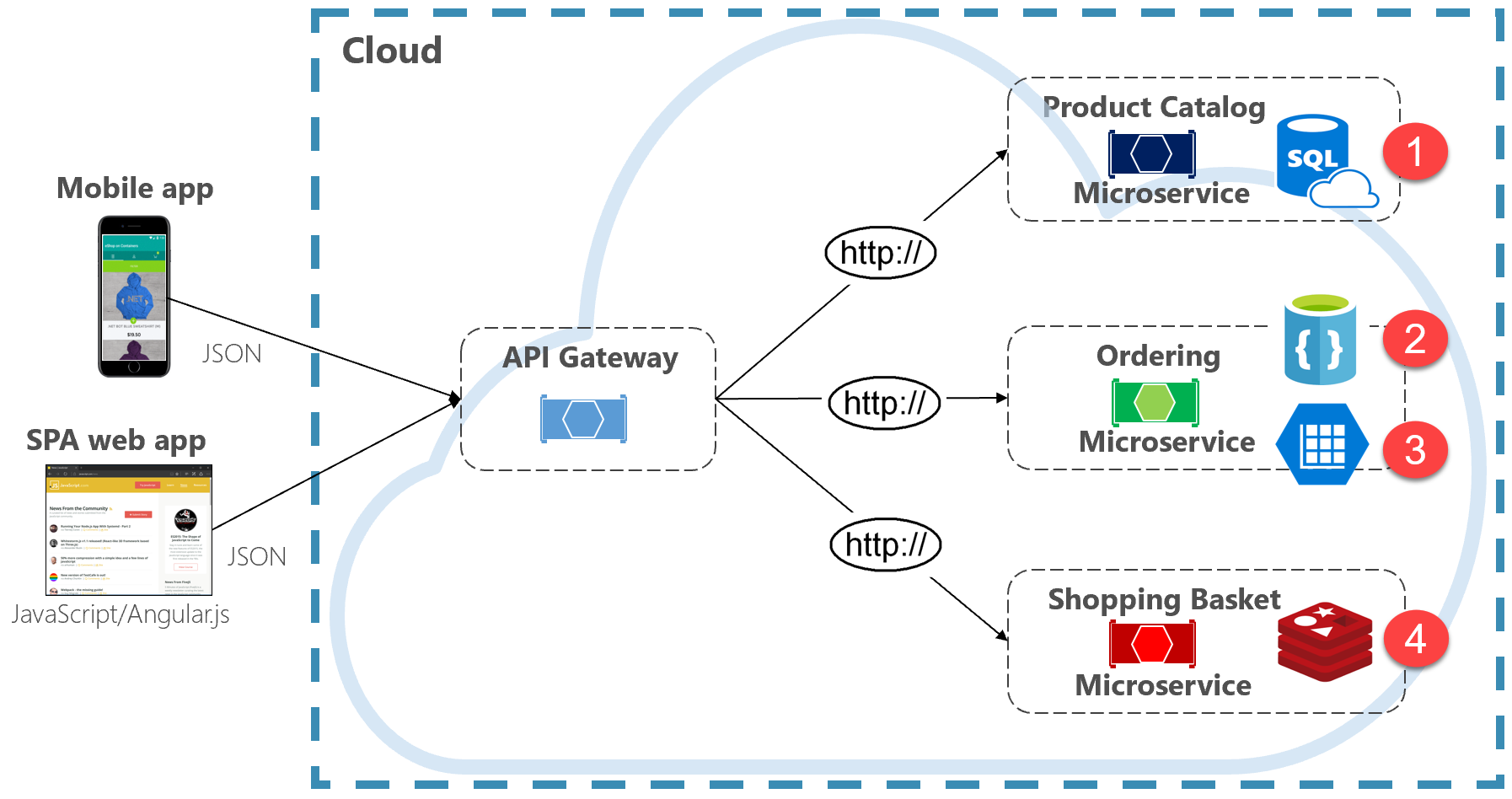
Afbeelding 5-2. Polyglot-gegevenspersistentie
In de vorige afbeelding ziet u hoe elke microservice een ander type gegevensarchief ondersteunt.
- De microservice van de productcatalogus gebruikt een relationele database voor de uitgebreide relationele structuur van de onderliggende gegevens.
- De microservice voor winkelwagens verbruikt een gedistribueerde cache die ondersteuning biedt voor het eenvoudige, sleutelwaardegegevensarchief.
- De bestellende microservice verbruikt zowel een NoSql-documentdatabase voor schrijfbewerkingen, samen met een sterk gedenormaliseerd sleutel-/waardearchief voor grote volumes leesbewerkingen.
Hoewel relationele databases relevant blijven voor microservices met complexe gegevens, hebben NoSQL-databases aanzienlijke populariteit gekregen. Ze bieden grootschalige en hoge beschikbaarheid. Met hun schemaloze aard kunnen ontwikkelaars weggaan van een architectuur van getypte gegevensklassen en ORM's die wijzigingen duur en tijdrovend maken. Verderop in dit hoofdstuk behandelen we NoSQL-databases.
Hoewel het inkapselen van gegevens in afzonderlijke microservices de flexibiliteit, prestaties en schaalbaarheid kan vergroten, biedt het ook veel uitdagingen. In de volgende sectie bespreken we deze uitdagingen, samen met patronen en procedures om ze te helpen overwinnen.
Query's voor meerdere services
Hoewel microservices onafhankelijk zijn en zich richten op specifieke functionele mogelijkheden, zoals voorraad, verzending of bestellen, vereisen ze vaak integratie met andere microservices. Vaak omvat de integratie één microservice die een query uitvoert op een andere microservice voor gegevens. In afbeelding 5-3 ziet u het scenario.
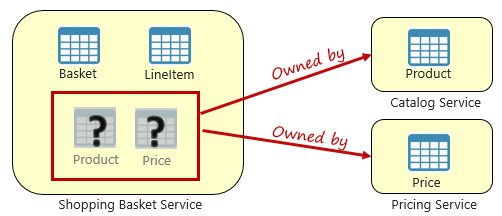
Afbeelding 5-3. Query's uitvoeren op microservices
In de voorgaande afbeelding zien we een microservice voor winkelwagens waarmee een item wordt toegevoegd aan de winkelwagen van een gebruiker. Hoewel het gegevensarchief voor deze microservice winkelwagen- en regelitemgegevens bevat, worden er geen product- of prijsgegevens bijgehouden. In plaats daarvan zijn deze gegevensitems eigendom van de catalogus en prijsmicroservices. Dit aspect vormt een probleem. Hoe kan de microservice voor winkelwagens een product toevoegen aan het winkelwagentje van de gebruiker wanneer deze geen product- of prijsgegevens in de database bevat?
Een optie die in hoofdstuk 4 wordt besproken, is een directe HTTP-aanroep van het winkelwagentje naar de catalogus en prijsmicroservices. In hoofdstuk 4 zeiden we echter dat synchrone HTTP-aanroepen microservices samen aanroepen, waardoor hun autonomie wordt verminderd en de architecturale voordelen afnemen.
We kunnen ook een aanvraagantwoordpatroon implementeren met afzonderlijke inkomende en uitgaande wachtrijen voor elke service. Dit patroon is echter ingewikkeld en vereist loodgieters om aanvraag- en antwoordberichten te correleren. Hoewel de microserviceaanroepen van de back-end worden losgekoppeld, moet de aanroepende service nog steeds synchroon wachten totdat de aanroep is voltooid. Netwerkcongestie, tijdelijke fouten of een overbelaste microservice en kunnen leiden tot langdurige en zelfs mislukte bewerkingen.
In plaats daarvan is een algemeen geaccepteerd patroon voor het verwijderen van afhankelijkheden tussen services het gerealiseerde weergavepatroon, weergegeven in afbeelding 5-4.
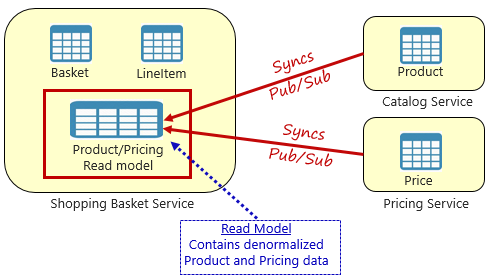
Afbeelding 5-4. Gerealiseerde weergave-patroon
Met dit patroon plaatst u een lokale gegevenstabel (ook wel een leesmodel genoemd) in de winkelmandservice. Deze tabel bevat een gedenormaliseerde kopie van de gegevens die nodig zijn van de product- en prijsmicroservices. Als u de gegevens rechtstreeks naar de winkelmand microservice kopieert, hoeft u geen dure crossservice-aanroepen meer te doen. Met de gegevens die lokaal zijn voor de service, verbetert u de reactietijd en betrouwbaarheid van de service. Bovendien maakt het gebruik van een eigen kopie van de gegevens de winkelwagenservice toleranter. Als de catalogusservice niet beschikbaar zou moeten zijn, zou deze niet rechtstreeks van invloed zijn op de winkelwagenservice. De winkelwagen kan blijven werken met de gegevens uit een eigen winkel.
De vangst met deze methode is dat u nu dubbele gegevens in uw systeem hebt. Het strategisch dupliceren van gegevens in cloudeigen systemen is echter een gevestigde praktijk en wordt niet beschouwd als een antipatroon of slechte praktijken. Houd er rekening mee dat één en slechts één service eigenaar kan zijn van een gegevensset en er gezag over heeft. U moet de leesmodellen synchroniseren wanneer het recordsysteem wordt bijgewerkt. Synchronisatie wordt doorgaans geïmplementeerd via asynchrone berichten met een publicatie-/abonneerpatroon, zoals wordt weergegeven in afbeelding 5.4.
Gedistribueerde transacties
Hoewel het uitvoeren van query's op gegevens in microservices moeilijk is, is het implementeren van een transactie in verschillende microservices nog complexer. De inherente uitdaging voor het behouden van gegevensconsistentie tussen onafhankelijke gegevensbronnen in verschillende microservices kan niet worden onderschat. Het ontbreken van gedistribueerde transacties in cloudtoepassingen betekent dat u gedistribueerde transacties programmatisch moet beheren. U gaat van een wereld van onmiddellijke consistentie naar die van uiteindelijke consistentie.
In afbeelding 5-5 ziet u het probleem.
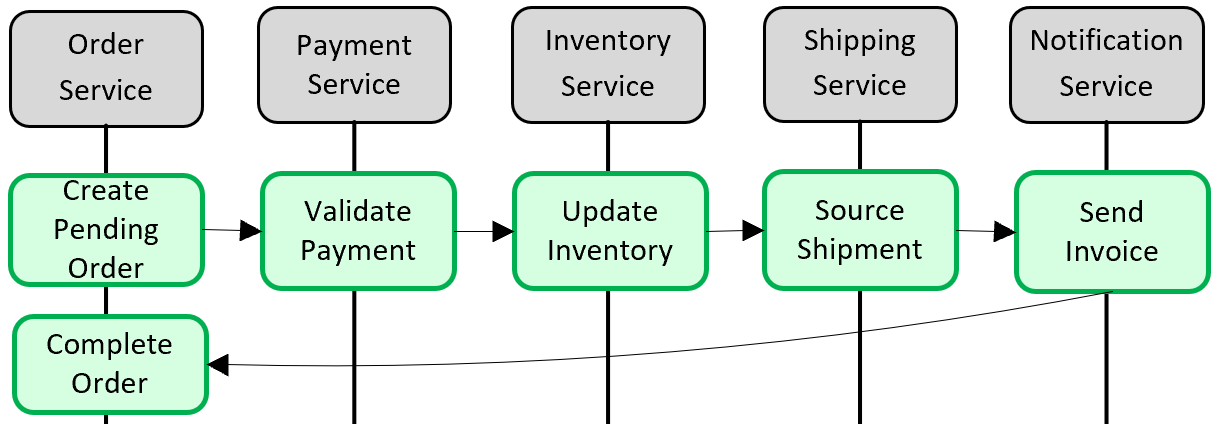
Afbeelding 5-5. Een transactie implementeren in microservices
In de voorgaande afbeelding nemen vijf onafhankelijke microservices deel aan een gedistribueerde transactie waarmee een order wordt gemaakt. Elke microservice onderhoudt een eigen gegevensarchief en implementeert een lokale transactie voor de opslag. Als u de order wilt maken, moet de lokale transactie voor elke afzonderlijke microservice slagen of moet alles de bewerking afbreken en terugdraaien. Hoewel ingebouwde transactionele ondersteuning beschikbaar is in elk van de microservices, is er geen ondersteuning voor een gedistribueerde transactie die alle vijf services omvat om gegevens consistent te houden.
In plaats daarvan moet u deze gedistribueerde transactie programmatisch samenstellen.
Een populair patroon voor het toevoegen van gedistribueerde transactionele ondersteuning is het Saga-patroon. Het wordt geïmplementeerd door lokale transacties programmatisch en opeenvolgend aan te roepen. Als een van de lokale transacties mislukt, wordt de bewerking door Saga afgebroken en wordt een set compenserende transacties aangeroepen. De compenserende transacties maken de wijzigingen ongedaan die zijn gemaakt door de voorgaande lokale transacties en herstellen van gegevensconsistentie. Afbeelding 5-6 toont een mislukte transactie met het Saga-patroon.
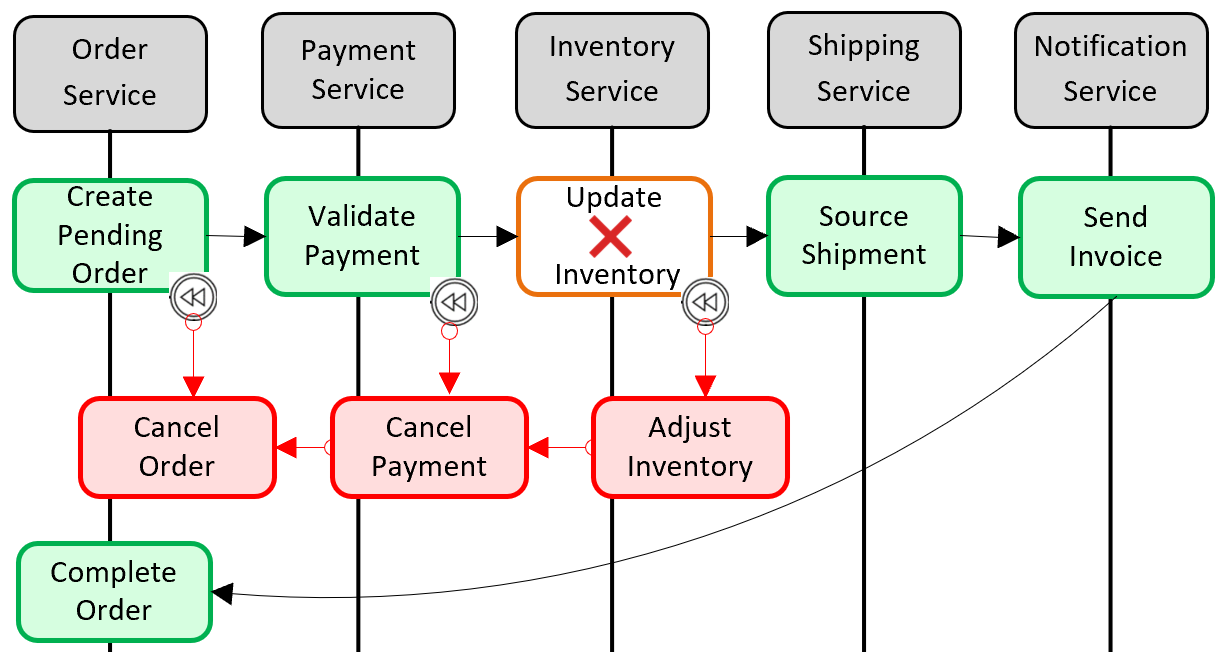
Afbeelding 5-6. Een transactie terugdraaien
In de vorige afbeelding is de bewerking Inventaris bijwerken mislukt in de microservice Inventaris. De Saga roept een reeks compenserende transacties (rood) aan om het aantal voorraad aan te passen, de betaling en de bestelling te annuleren en de gegevens voor elke microservice terug te sturen naar een consistente status.
Saga-patronen worden doorgaans gechoreografeerd als een reeks gerelateerde gebeurtenissen, of ingedeeld als een reeks gerelateerde opdrachten. In hoofdstuk 4 hebben we het serviceaggregatorpatroon besproken dat de basis vormt voor een georchekte saga-implementatie. We hebben ook eventing besproken, samen met Azure Service Bus en Azure Event Grid-onderwerpen die een basis vormen voor een gechoreografeerde saga-implementatie.
Gegevens met een hoog volume
Grote cloudtoepassingen bieden vaak ondersteuning voor gegevensvereisten met een hoog volume. In deze scenario's kunnen traditionele technieken voor gegevensopslag knelpunten veroorzaken. Voor complexe systemen die op grote schaal worden geïmplementeerd, kunnen CQRS (Command and Query Responsibility Segregation) en Event Sourcing de prestaties van toepassingen verbeteren.
CQRS
CQRS, is een architectuurpatroon dat kan helpen bij het maximaliseren van prestaties, schaalbaarheid en beveiliging. Het patroon scheidt bewerkingen die gegevens lezen van de bewerkingen die gegevens schrijven.
Voor normale scenario's worden hetzelfde entiteitsmodel en hetzelfde gegevensopslagplaatsobject gebruikt voor zowel lees- als schrijfbewerkingen.
Een groot gegevensscenario kan echter profiteren van afzonderlijke modellen en gegevenstabellen voor lees- en schrijfbewerkingen. Om de prestaties te verbeteren, kan de leesbewerking query's uitvoeren op een sterk gedenormaliseerde weergave van de gegevens om dure terugkerende tabeldeelnames en tabelvergrendelingen te voorkomen. De schrijfbewerking , ook wel een opdracht genoemd, wordt bijgewerkt op basis van een volledig genormaliseerde weergave van de gegevens die consistentie garanderen. Vervolgens moet u een mechanisme implementeren om beide weergaven gesynchroniseerd te houden. Wanneer de schrijftabel wordt gewijzigd, publiceert deze doorgaans een gebeurtenis die de wijziging naar de leestabel repliceert.
Afbeelding 5-7 toont een implementatie van het CQRS-patroon.
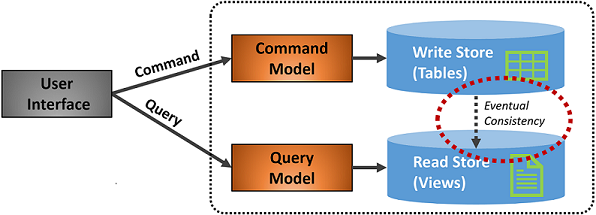
Afbeelding 5-7. CQRS-implementatie
In de vorige afbeelding worden afzonderlijke opdracht- en querymodellen geïmplementeerd. Elke schrijfbewerking voor gegevens wordt opgeslagen in het schrijfarchief en vervolgens doorgegeven aan het leesarchief. Let goed op hoe het gegevensdoorgifteproces werkt op basis van het principe van uiteindelijke consistentie. Het leesmodel synchroniseert uiteindelijk met het schrijfmodel, maar er is mogelijk enige vertraging in het proces. In de volgende sectie bespreken we uiteindelijke consistentie.
Met deze scheiding kunnen lees- en schrijfbewerkingen onafhankelijk worden geschaald. Leesbewerkingen maken gebruik van een schema dat is geoptimaliseerd voor query's, terwijl de schrijfbewerkingen een schema gebruiken dat is geoptimaliseerd voor updates. Leesquery's gaan ten opzichte van gedenormaliseerde gegevens, terwijl complexe bedrijfslogica kan worden toegepast op het schrijfmodel. Daarnaast kunt u een strakkere beveiliging opleggen voor schrijfbewerkingen dan voor schrijfbewerkingen die leesbewerkingen blootstellen.
Het implementeren van CQRS kan de prestaties van toepassingen voor cloudeigen services verbeteren. Het resulteert echter in een complexer ontwerp. Pas dit principe zorgvuldig en strategisch toe op deze secties van uw cloudeigen toepassing die hiervan profiteren. Zie het Microsoft-boek .NET Microservices: Architecture for Containerized .NET Applications voor meer informatie over CQRS.
Gebeurtenisbronnen
Een andere benadering voor het optimaliseren van scenario's voor gegevens met een hoog volume omvat gebeurtenisbronnen.
Een systeem slaat doorgaans de huidige status van een gegevensentiteit op. Als een gebruiker bijvoorbeeld het telefoonnummer wijzigt, wordt de klantrecord bijgewerkt met het nieuwe nummer. We weten altijd de huidige status van een gegevensentiteit, maar elke update overschrijft de vorige status.
In de meeste gevallen werkt dit model prima. In systemen met grote volumes kan de overhead van transactionele vergrendeling en frequente updatebewerkingen echter van invloed zijn op de prestaties van de database, reactiesnelheid en de schaalbaarheid beperken.
Gebeurtenisbronnen hebben een andere benadering voor het vastleggen van gegevens. Elke bewerking die van invloed is op gegevens, wordt bewaard in een gebeurtenisarchief. In plaats van de status van een gegevensrecord bij te werken, voegen we elke wijziging toe aan een opeenvolgende lijst met eerdere gebeurtenissen, vergelijkbaar met het grootboek van een accountant. Event Store wordt het recordsysteem voor de gegevens. Het wordt gebruikt om verschillende gerealiseerde weergaven door te geven binnen de gebonden context van een microservice. In afbeelding 5.8 ziet u het patroon.
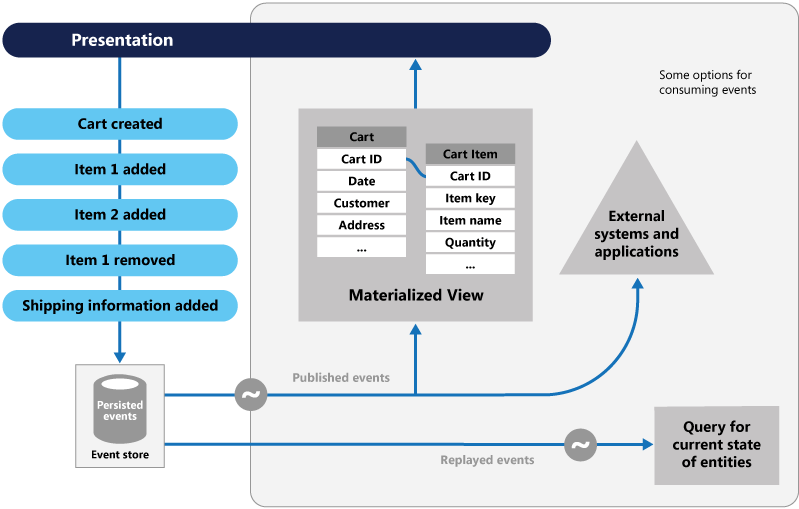
Afbeelding 5-8. Gebeurtenisbronnen
In de vorige afbeelding ziet u hoe elke vermelding (in blauw) voor het winkelwagentje van een gebruiker wordt toegevoegd aan een onderliggende gebeurtenisopslag. In de aangrenzende gerealiseerde weergave projecteert het systeem de huidige status door alle gebeurtenissen die aan elke winkelwagen zijn gekoppeld, opnieuw af te spelen. Deze weergave, of het leesmodel, wordt vervolgens weer weergegeven in de gebruikersinterface. Gebeurtenissen kunnen ook worden geïntegreerd met externe systemen en toepassingen of worden opgevraagd om de huidige status van een entiteit te bepalen. Met deze aanpak houdt u de geschiedenis bij. U weet niet alleen de huidige status van een entiteit, maar ook hoe u deze status hebt bereikt.
Met behulp van mechanische gegevens vereenvoudigt gebeurtenisbronnen het schrijfmodel. Er zijn geen updates of verwijderingen. Als u elke gegevensinvoer toevoegt als een onveranderbare gebeurtenis, worden conflicten, vergrendelingen en gelijktijdigheidsconflicten met betrekking tot relationele databases geminimaliseerd. Door leesmodellen te bouwen met het gerealiseerde weergavepatroon, kunt u de weergave loskoppelen van het schrijfmodel en het beste gegevensarchief kiezen om de behoeften van de gebruikersinterface van uw toepassing te optimaliseren.
Voor dit patroon kunt u een gegevensarchief overwegen dat rechtstreeks ondersteuning biedt voor gebeurtenisbronnen. Azure Cosmos DB, MongoDB, Cassandra, CouchDB en RavenDB zijn goede kandidaten.
Net als bij alle patronen en technologieën moet u strategisch en indien nodig implementeren. Hoewel gebeurtenisbronnen betere prestaties en schaalbaarheid kunnen bieden, gaat dit ten koste van complexiteit en een leercurve.