Rag (Retrieval-augmented generation) biedt LLM-kennis
In dit artikel wordt beschreven hoe met het ophalen van uitgebreide generatie LLM's uw gegevensbronnen als kennis kunnen worden behandeld zonder dat ze hoeven te trainen.
LLM's hebben uitgebreide knowledge bases via training. Voor de meeste scenario's kunt u een LLM selecteren die is ontworpen voor uw vereisten, maar deze LLM's vereisen nog steeds aanvullende training om inzicht te krijgen in uw specifieke gegevens. Met het ophalen van uitgebreide generatie kunt u uw gegevens beschikbaar maken voor LLM's zonder deze eerst te trainen.
Hoe RAG werkt
Als u het ophalen van uitgebreide generatie wilt uitvoeren, maakt u insluitingen voor uw gegevens, samen met veelgestelde vragen over deze gegevens. U kunt dit direct doen of u kunt de insluitingen maken en opslaan met behulp van een vectordatabaseoplossing.
Wanneer een gebruiker een vraag stelt, gebruikt de LLM uw insluitingen om de vraag van de gebruiker te vergelijken met uw gegevens en de meest relevante context te vinden. Deze context en de vraag van de gebruiker gaan vervolgens in een prompt naar de LLM en de LLM geeft een antwoord op basis van uw gegevens.
Eenvoudig RAG-proces
Als u RAG wilt uitvoeren, moet u elke gegevensbron verwerken die u wilt gebruiken voor het ophalen. Het basisproces is als volgt:
- Grote gegevens segmenten in beheerbare stukken.
- Converteer de segmenten naar een doorzoekbare indeling.
- Sla de geconverteerde gegevens op een locatie op die efficiënte toegang mogelijk maakt. Daarnaast is het belangrijk om relevante metagegevens op te slaan voor bronvermeldingen of verwijzingen wanneer de LLM antwoorden levert.
- Voer uw geconverteerde gegevens in in prompts naar LLM's.
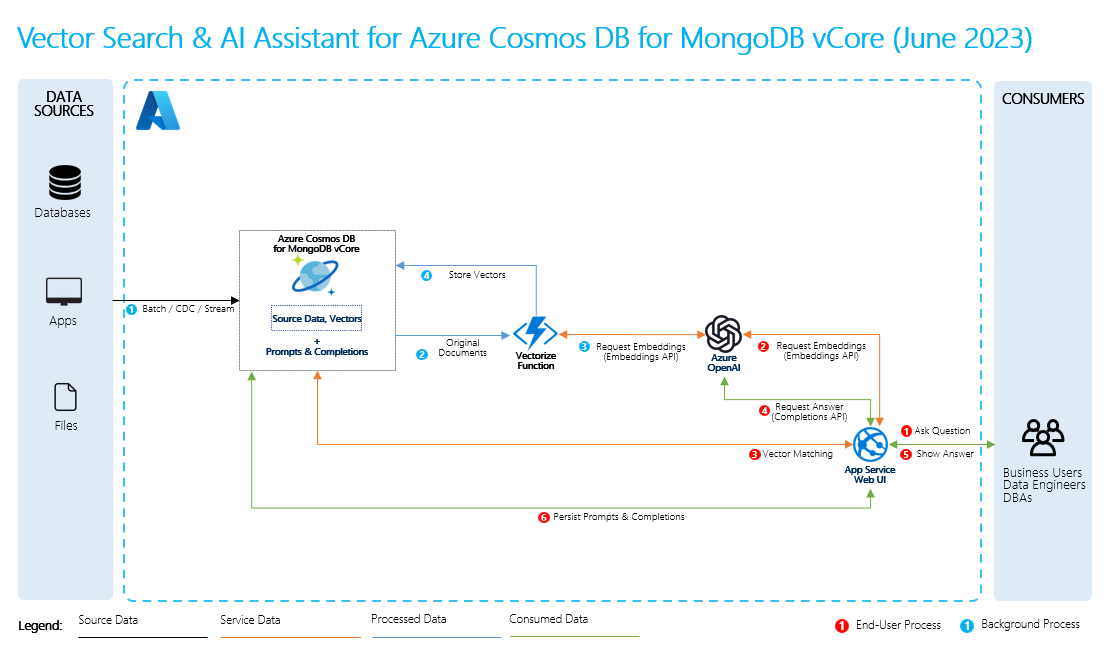
- Brongegevens: dit is waar uw gegevens bestaan. Dit kan een bestand/map op uw computer zijn, een bestand in cloudopslag, een Azure Machine Learning-gegevensasset, een Git-opslagplaats of een SQL-database.
- Gegevenssegmentering: de gegevens in uw bron moeten worden geconverteerd naar tekst zonder opmaak. Word-documenten of PDF-bestanden moeten bijvoorbeeld open worden gebarsten en geconverteerd naar tekst. De tekst wordt vervolgens in kleinere stukken gesegmenteerd.
- De tekst converteren naar vectoren: dit zijn insluitingen. Vectoren zijn numerieke representaties van concepten die zijn geconverteerd naar getalreeksen, waardoor computers de relaties tussen deze concepten eenvoudig kunnen begrijpen.
- Koppelingen tussen brongegevens en insluitingen: deze informatie wordt opgeslagen als metagegevens op de segmenten die u hebt gemaakt, die vervolgens worden gebruikt om de LLM's te helpen bronvermeldingen te genereren tijdens het genereren van antwoorden.