.NET voor Apache Spark gebruiken met Azure Synapse Analytics
.NET voor Apache Spark biedt gratis opensource- en platformoverschrijdende .NET-ondersteuning voor Spark.
Het biedt .NET-bindingen voor Spark, waarmee u toegang hebt tot Spark-API's via C# en F#. Met .NET voor Apache Spark kunt u ook door de gebruiker gedefinieerde functies schrijven en uitvoeren voor Spark die zijn geschreven in .NET. Met de .NET-API's voor Spark hebt u toegang tot alle aspecten van Spark DataFrames waarmee u uw gegevens kunt analyseren, waaronder Spark SQL, Delta Lake en Structured Streaming.
U kunt gegevens analyseren met .NET voor Apache Spark via Batch-taakdefinities of met interactieve Azure Synapse Analytics-notebooks. In dit artikel leert u hoe u .NET voor Apache Spark gebruikt met Azure Synapse met behulp van beide technieken.
Belangrijk
. NET voor Apache Spark is een opensource-project onder de .NET Foundation waarvoor momenteel de .NET 3.1-bibliotheek is vereist, die de status van de ondersteuning heeft bereikt. We willen gebruikers informeren over Azure Synapse Spark over het verwijderen van de .NET voor Apache Spark-bibliotheek in de Azure Synapse Runtime voor Apache Spark versie 3.3. Gebruikers kunnen het .NET-ondersteuningsbeleid raadplegen voor meer informatie over deze kwestie.
Als gevolg hiervan is het niet langer mogelijk voor gebruikers om Apache Spark-API's te gebruiken via C# en F#, of C#-code uit te voeren in notebooks binnen Synapse of via Apache Spark-taakdefinities in Synapse. Het is belangrijk te weten dat deze wijziging alleen van invloed is op Azure Synapse Runtime voor Apache Spark 3.3 en hoger.
We blijven .NET voor Apache Spark ondersteunen in alle vorige versies van de Azure Synapse Runtime op basis van hun levenscyclusfasen. We hebben echter geen plannen om .NET voor Apache Spark te ondersteunen in Azure Synapse Runtime voor Apache Spark 3.3 en toekomstige versies. We raden gebruikers aan met bestaande workloads die zijn geschreven in C# of F# te migreren naar Python of Scala. Gebruikers worden aangeraden deze informatie te noteren en dienovereenkomstig te plannen.
Batchtaken verzenden met behulp van de Spark-taakdefinitie
Ga naar de zelfstudie voor meer informatie over het gebruik van Azure Synapse Analytics om Apache Spark-taakdefinities te maken voor Synapse Spark-pools. Als u uw app niet hebt verpakt om te verzenden naar Azure Synapse, voert u de volgende stappen uit.
Configureer uw
dotnettoepassingsafhankelijkheden voor compatibiliteit met Synapse Spark. De vereiste .NET Spark-versie wordt vermeld in de Synapse Studio-interface onder de configuratie van uw Apache Spark-pool, onder de werkset Beheren.
Maak uw project als een .NET-consoletoepassing die een uitvoerbaar Ubuntu x86-bestand uitvoert.
<Project Sdk="Microsoft.NET.Sdk"> <PropertyGroup> <OutputType>Exe</OutputType> <TargetFramework>netcoreapp3.1</TargetFramework> </PropertyGroup> <ItemGroup> <PackageReference Include="Microsoft.Spark" Version="2.1.0" /> </ItemGroup> </Project>Voer de volgende opdrachten uit om uw app te publiceren. Zorg ervoor dat u mySparkApp vervangt door het pad naar uw app.
cd mySparkApp dotnet publish -c Release -f netcoreapp3.1 -r ubuntu.18.04-x64Zip de inhoud van de publicatiemap,
publish.zipbijvoorbeeld die is gemaakt als gevolg van stap 1. Alle assembly's moeten zich in de hoofdmap van het ZIP-bestand bevinden en er mag geen tussenliggende maplaag zijn. Dit betekent dat wanneer u uitpaktpublish.zip, alle assembly's worden geëxtraheerd in uw huidige werkmap.In Windows:
Maak met Windows PowerShell of PowerShell 7 een .zip op basis van de inhoud van uw publicatiemap.
Compress-Archive publish/* publish.zip -UpdateOp Linux:
Open een bash-shell en cd in de bin-map met alle gepubliceerde binaire bestanden en voer de volgende opdracht uit.
zip -r publish.zip
.NET voor Apache Spark in Azure Synapse Analytics-notebooks
Notebooks zijn een uitstekende optie voor het maken van prototypen van uw .NET voor Apache Spark-pijplijnen en -scenario's. U kunt snel en efficiënt aan de slag gaan met, begrijpen, filteren, weergeven en visualiseren van uw gegevens.
Data engineers, gegevenswetenschappers, bedrijfsanalisten en machine learning-engineers kunnen allemaal samenwerken via een gedeeld, interactief document. U ziet onmiddellijke resultaten van gegevensverkenning en kunt uw gegevens in hetzelfde notebook visualiseren.
.NET gebruiken voor Apache Spark-notebooks
Wanneer u een nieuw notebook maakt, kiest u een taalkernel die u uw bedrijfslogica wilt uitdrukken. Kernelondersteuning is beschikbaar voor verschillende talen, waaronder C#.
Als u .NET wilt gebruiken voor Apache Spark in uw Azure Synapse Analytics-notebook, selecteert u .NET Spark (C#) als uw kernel en koppelt u het notebook aan een bestaande serverloze Apache Spark-pool.
Het .NET Spark-notebook is gebaseerd op de interactieve .NET-ervaringen en biedt interactieve C#-ervaringen met de mogelijkheid om .NET voor Spark kant-en-klare te gebruiken met de Spark-sessievariabele spark die al vooraf is gedefinieerd.
NuGet-pakketten installeren in notebooks
U kunt NuGet-pakketten van uw keuze installeren in uw notebook met behulp van de #r nuget magic-opdracht vóór de naam van het NuGet-pakket. In het volgende diagram ziet u een voorbeeld:
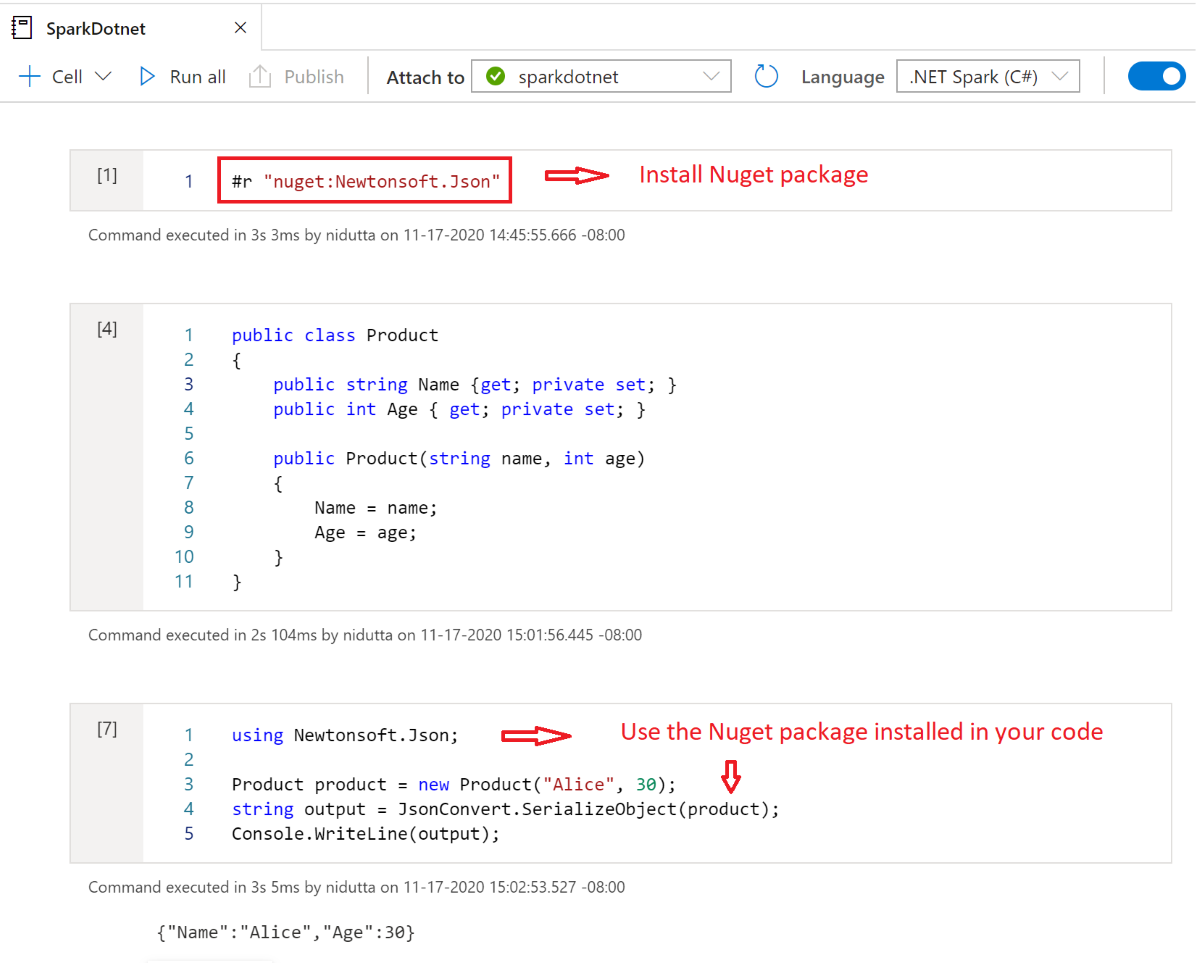
Zie de interactieve .NET-documentatie voor meer informatie over het werken met NuGet-pakketten in notebooks.
.NET voor Apache Spark C#-kernelfuncties
De volgende functies zijn beschikbaar wanneer u .NET voor Apache Spark gebruikt in het Azure Synapse Analytics-notebook:
- Declaratieve HTML: Uitvoer van uw cellen genereren met behulp van HTML-syntaxis, zoals kopteksten, lijsten met opsommingstekens en zelfs afbeeldingen weergeven.
- Eenvoudige C#-instructies (zoals toewijzingen, afdrukken naar console, het genereren van uitzonderingen, enzovoort).
- C#-codeblokken met meerdere regels (zoals if-instructies, foreach-lussen, klassedefinities enzovoort).
- Toegang tot de standaard C#-bibliotheek (zoals Systeem, LINQ, Enumerables, enzovoort).
- Ondersteuning voor C# 8.0-taalfuncties.
sparkals vooraf gedefinieerde variabele om u toegang te geven tot uw Apache Spark-sessie.- Ondersteuning voor het definiëren van door de gebruiker gedefinieerde .NET-functies die kunnen worden uitgevoerd in Apache Spark. We raden u aan UDF's te schrijven en aan te roepen in .NET voor Interactieve Apache Spark-omgevingen voor informatie over het gebruik van UDF's in .NET voor Interactieve Apache Spark-ervaringen.
- Ondersteuning voor het visualiseren van uitvoer van uw Spark-taken met behulp van verschillende grafieken (zoals lijn, staaf of histogram) en indelingen (zoals één, overlappend enzovoort) met behulp van de
XPlot.Plotlybibliotheek. - Mogelijkheid om NuGet-pakketten op te nemen in uw C#-notebook.
Problemen oplossen
DotNetRunner: null / Futures timeout in Synapse Spark-taakdefinitie uitvoeren
Synapse Spark-taakdefinities voor Spark-pools met Spark 2.4 vereisen Microsoft.Spark 1.0.0. Wis uw bin mappen en obj publiceer het project met 1.0.0.
OutOfMemoryError: java heap-ruimte op org.apache.spark
Dotnet Spark 1.0.0 maakt gebruik van een andere architectuur voor foutopsporing dan 1.1.1+. U moet 1.0.0 gebruiken voor uw gepubliceerde versie en 1.1.1+, voor lokale foutopsporing.