Pakketten met sessiebereik beheren
Naast pakketten op groepsniveau kunt u ook bibliotheken met sessiebereik opgeven aan het begin van een notebooksessie. Met bibliotheken met sessiebereik kunt u Python-, JAR- en R-pakketten in een notebooksessie opgeven en gebruiken.
Wanneer u bibliotheken met sessiebereik gebruikt, is het belangrijk om rekening te houden met de volgende punten:
- Wanneer u bibliotheken met sessiebereik installeert, heeft alleen het huidige notitieblok toegang tot de opgegeven bibliotheken.
- Deze bibliotheken hebben geen invloed op andere sessies of taken met behulp van dezelfde Spark-pool.
- Deze bibliotheken worden geïnstalleerd boven op de basisbibliotheken op runtime- en poolniveau en hebben de hoogste prioriteit.
- Bibliotheken met sessiebereik blijven niet behouden tussen sessies.
Python-pakketten met sessiebereik
Python-pakketten met sessiebereik beheren via environment.yml-bestand
Python-pakketten met sessiebereik opgeven:
- Navigeer naar de geselecteerde Spark-pool en zorg ervoor dat u bibliotheken op sessieniveau hebt ingeschakeld. U kunt deze instelling inschakelen door naar het >tabblad Pakketten voor Apache Spark-pools>beheren te gaan.
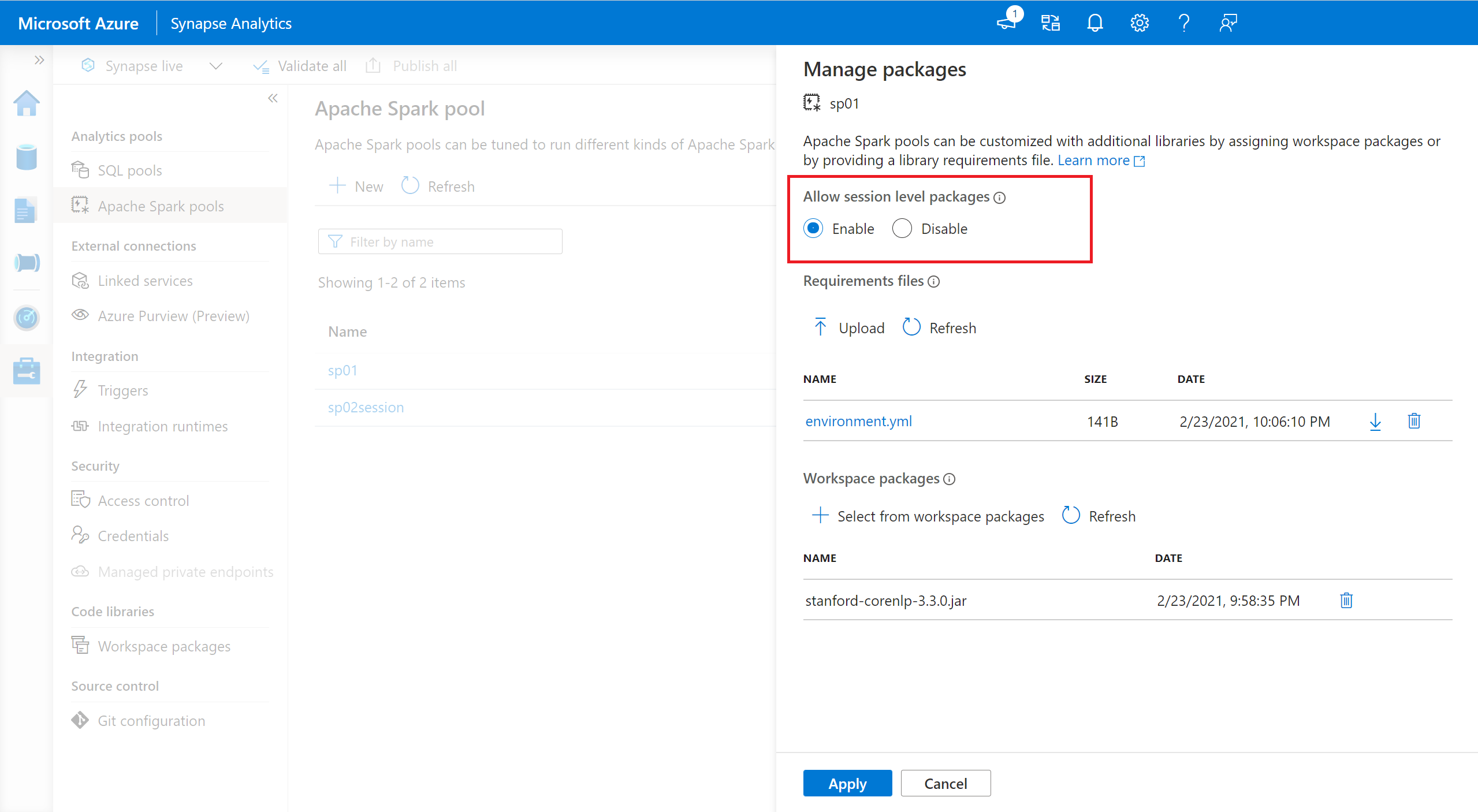
- Zodra de instelling van toepassing is, kunt u een notitieblok openen en sessiepakketten> configureren selecteren.

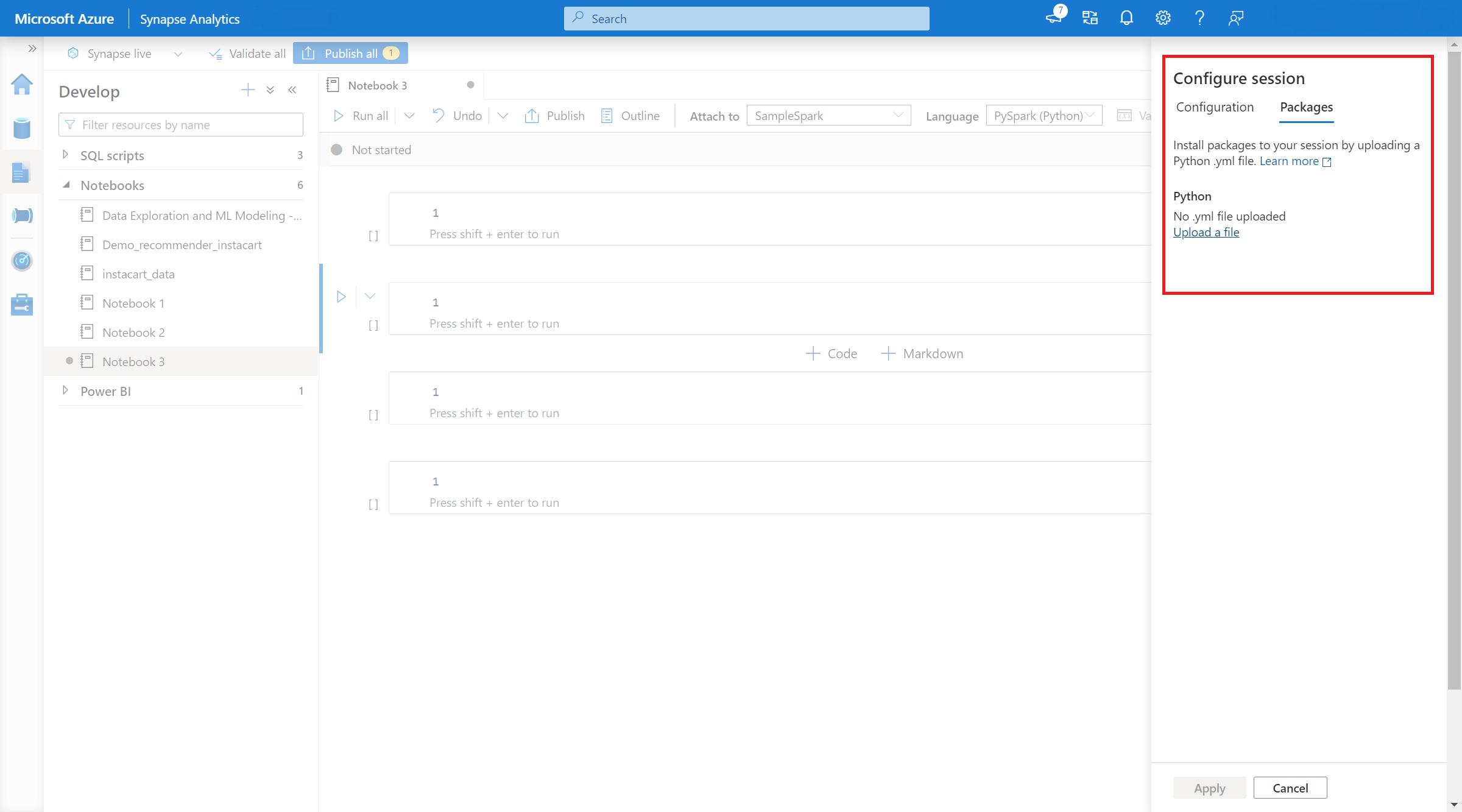
- Hier kunt u een Conda environment.yml-bestand uploaden om pakketten binnen een sessie te installeren of bij te werken. De opgegeven bibliotheken zijn aanwezig zodra de sessie is gestart. Deze bibliotheken zijn niet meer beschikbaar nadat de sessie is beëindigd.

Python-pakketten met sessiebereik beheren via %pip- en %conda-opdrachten
U kunt de populaire opdrachten %pip en %conda gebruiken om extra bibliotheken van derden of uw aangepaste bibliotheken te installeren tijdens uw Apache Spark-notebooksessie. In deze sectie gebruiken we %pip-opdrachten om verschillende veelvoorkomende scenario's te demonstreren.
Notitie
- U wordt aangeraden de opdrachten %pip en %conda in de eerste cel van uw notebook te plaatsen als u nieuwe bibliotheken wilt installeren. De Python-interpreter wordt opnieuw gestart nadat de bibliotheek op sessieniveau wordt beheerd om de wijzigingen effectief te maken.
- Deze opdrachten voor het beheren van Python-bibliotheken worden uitgeschakeld bij het uitvoeren van pijplijntaken. Als u een pakket in een pijplijn wilt installeren, moet u gebruikmaken van de mogelijkheden voor bibliotheekbeheer op groepsniveau.
- Python-bibliotheken met sessiebereik worden automatisch geïnstalleerd op zowel het stuurprogramma als de werkknooppunten.
- De volgende %conda-opdrachten worden niet ondersteund: maken, opschonen, vergelijken, activeren, deactiveren, uitvoeren, pakket.
- U kunt verwijzen naar %pip-opdrachten en %conda-opdrachten voor de volledige lijst met opdrachten.
Een pakket van derden installeren
U kunt eenvoudig een Python-bibliotheek installeren vanuit PyPI.
# Install vega_datasets
%pip install altair vega_datasets
Als u het installatieresultaat wilt controleren, kunt u de volgende code uitvoeren om vega_datasets te visualiseren
# Create a scatter plot
# Plot Miles per gallon against the horsepower across different region
import altair as alt
from vega_datasets import data
cars = data.cars()
alt.Chart(cars).mark_point().encode(
x='Horsepower',
y='Miles_per_Gallon',
color='Origin',
).interactive()
Een wielpakket installeren vanuit een opslagaccount
Als u bibliotheek wilt installeren vanuit opslag, moet u koppelen aan uw opslagaccount door de volgende opdrachten uit te voeren.
from notebookutils import mssparkutils
mssparkutils.fs.mount(
"abfss://<<file system>>@<<storage account>.dfs.core.windows.net",
"/<<path to wheel file>>",
{"linkedService":"<<storage name>>"}
)
En vervolgens kunt u de opdracht %pip installeren om het vereiste wielpakket te installeren
%pip install /<<path to wheel file>>/<<wheel package name>>.whl
Een andere versie van de ingebouwde bibliotheek installeren
U kunt de volgende opdracht gebruiken om te zien wat de ingebouwde versie van een bepaald pakket is. We gebruiken pandas als voorbeeld
%pip show pandas
Het resultaat is als het volgende logboek:
Name: pandas
Version: **1.2.3**
Summary: Powerful data structures for data analysis, time series, and statistics
Home-page: https://pandas.pydata.org
... ...
U kunt de volgende opdracht gebruiken om pandas over te schakelen naar een andere versie, bijvoorbeeld 1.2.4
%pip install pandas==1.2.4
Een bibliotheek met sessiebereik verwijderen
Als u een pakket wilt verwijderen dat op deze notebooksessie is geïnstalleerd, kunt u de volgende opdrachten raadplegen. U kunt de ingebouwde pakketten echter niet verwijderen.
%pip uninstall altair vega_datasets --yes
De opdracht %pip gebruiken om bibliotheken te installeren vanuit een requirement.txt-bestand
%pip install -r /<<path to requirement file>>/requirements.txt
Java- of Scala-pakketten met sessiebereik
Als u java- of Scala-pakketten met sessiebereik wilt opgeven, kunt u de %%configure volgende optie gebruiken:
%%configure -f
{
"conf": {
"spark.jars": "abfss://<<file system>>@<<storage account>.dfs.core.windows.net/<<path to JAR file>>",
}
}
Notitie
- U wordt aangeraden de %%-configuratie aan het begin van uw notebook uit te voeren. U kunt naar dit document verwijzen voor de volledige lijst met geldige parameters.
R-pakketten met sessiebereik (preview)
Azure Synapse Analytics-pools bevatten veel populaire R-bibliotheken. U kunt ook extra bibliotheken van derden installeren tijdens uw Apache Spark-notebooksessie.
Notitie
- Deze opdrachten voor het beheren van R-bibliotheken worden uitgeschakeld bij het uitvoeren van pijplijntaken. Als u een pakket in een pijplijn wilt installeren, moet u gebruikmaken van de mogelijkheden voor bibliotheekbeheer op groepsniveau.
- R-bibliotheken met sessiebereik worden automatisch geïnstalleerd op zowel het stuurprogramma als de werkknooppunten.
Een pakket installeren
U kunt eenvoudig een R-bibliotheek installeren vanuit CRAN.
# Install a package from CRAN
install.packages(c("nycflights13", "Lahman"))
U kunt CRAN-momentopnamen ook gebruiken als de opslagplaats om ervoor te zorgen dat u elke keer dezelfde pakketversie downloadt.
install.packages("highcharter", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
Devtools gebruiken om pakketten te installeren
De devtools bibliotheek vereenvoudigt de ontwikkeling van pakketten om veelvoorkomende taken te versnellen. Deze bibliotheek wordt geïnstalleerd in de standaard Azure Synapse Analytics-runtime.
U kunt een devtools specifieke versie van een bibliotheek opgeven die u wilt installeren. Deze bibliotheken worden op alle knooppunten in het cluster geïnstalleerd.
# Install a specific version.
install_version("caesar", version = "1.0.0")
Op dezelfde manier kunt u rechtstreeks vanuit GitHub een bibliotheek installeren.
# Install a GitHub library.
install_github("jtilly/matchingR")
Momenteel worden de volgende devtools functies ondersteund in Azure Synapse Analytics:
| Opdracht | Beschrijving |
|---|---|
| install_github() | Hiermee wordt een R-pakket vanuit GitHub geïnstalleerd |
| install_gitlab() | Een R-pakket installeren vanuit GitLab |
| install_bitbucket() | Hiermee wordt een R-pakket vanuit Bitbucket geïnstalleerd |
| install_url() | Hiermee wordt een R-pakket van een willekeurige URL geïnstalleerd |
| install_git() | Installaties vanuit een willekeurige Git-opslagplaats |
| install_local() | Wordt geïnstalleerd vanuit een lokaal bestand op schijf |
| install_version() | Installaties van een specifieke versie op CRAN |
Geïnstalleerde bibliotheken weergeven
U kunt een query uitvoeren op alle bibliotheken die in uw sessie zijn geïnstalleerd met behulp van de library opdracht.
library()
U kunt de packageVersion functie gebruiken om de versie van de bibliotheek te controleren:
packageVersion("caesar")
Een R-pakket verwijderen uit een sessie
U kunt de detach functie gebruiken om een bibliotheek uit de naamruimte te verwijderen. Deze bibliotheken blijven op schijf totdat ze opnieuw worden geladen.
# detach a library
detach("package: caesar")
Als u een pakket met sessiebereik uit een notebook wilt verwijderen, gebruikt u de remove.packages() opdracht. Deze bibliotheekwijziging heeft geen invloed op andere sessies in hetzelfde cluster. Gebruikers kunnen ingebouwde bibliotheken van de standaard Azure Synapse Analytics-runtime niet verwijderen of verwijderen.
remove.packages("caesar")
Notitie
U kunt kernpakketten zoals SparkR, SparklyR of R niet verwijderen.
R-bibliotheken met sessiebereik en SparkR
Er zijn notebookbibliotheken beschikbaar voor SparkR-werkrollen.
install.packages("stringr")
library(SparkR)
str_length_function <- function(x) {
library(stringr)
str_length(x)
}
docs <- c("Wow, I really like the new light sabers!",
"That book was excellent.",
"R is a fantastic language.",
"The service in this restaurant was miserable.",
"This is neither positive or negative.")
spark.lapply(docs, str_length_function)
R-bibliotheken met sessiebereik en SparklyR
Met spark_apply() in SparklyR kunt u elk R-pakket in Spark gebruiken. Standaard wordt in sparklyr::spark_apply() het argument pakketten ingesteld op FALSE. Hiermee kopieert u bibliotheken in de huidige libPaths naar de werkrollen, zodat u ze op werkrollen kunt importeren en gebruiken. U kunt bijvoorbeeld het volgende uitvoeren om een met caesar versleuteld bericht te genereren met sparklyr::spark_apply():
install.packages("caesar", repos = "https://cran.microsoft.com/snapshot/2021-07-16/")
spark_version <- "3.2"
config <- spark_config()
sc <- spark_connect(master = "yarn", version = spark_version, spark_home = "/opt/spark", config = config)
apply_cases <- function(x) {
library(caesar)
caesar("hello world")
}
sdf_len(sc, 5) %>%
spark_apply(apply_cases, packages=FALSE)
Volgende stappen
- De standaardbibliotheken weergeven: ondersteuning voor Apache Spark-versies
- De pakketten buiten de Synapse Studio-portal beheren: Pakketten beheren via Az-opdrachten en REST API's