Bibliotheken beheren voor Apache Spark-pools in Azure Synapse Analytics
Nadat u de Scala-, Java-, R-(preview)-pakketten of Python-pakketten hebt geïdentificeerd die u wilt gebruiken of bijwerken voor uw Spark-toepassing, kunt u deze installeren of verwijderen uit een Spark-pool. Bibliotheken op poolniveau zijn beschikbaar voor alle notebooks en taken die in de pool worden uitgevoerd.
Er zijn twee primaire manieren om een bibliotheek in een Spark-pool te installeren:
- Installeer een werkruimtebibliotheek die is geüpload als een werkruimtepakket.
- Als u Python-bibliotheken wilt bijwerken, geeft u een requirements.txt - of Conda environment.yml-omgevingsspecificatiebestand op om pakketten te installeren vanuit opslagplaatsen zoals PyPI of Conda-Forge. Zie de sectie Indelingen voor omgevingsspecificaties voor meer informatie.
Nadat de wijzigingen zijn opgeslagen, voert een Spark-taak de installatie uit en slaat de resulterende omgeving in de cache op voor later hergebruik. Zodra de taak is voltooid, gebruiken nieuwe Spark-taken of notebooksessies de bijgewerkte poolbibliotheken.
Belangrijk
- Als het pakket dat u installeert groot is of lang duurt voordat het is geïnstalleerd, wordt de opstarttijd van het Spark-exemplaar beïnvloed.
- Het wijzigen van de PySpark-, Python-, Scala/Java-, .NET-, R- of Spark-versie wordt niet ondersteund.
- Het installeren van pakketten vanuit externe opslagplaatsen zoals PyPI, Conda-Forge of de standaard Conda-kanalen wordt niet ondersteund in werkruimten met gegevensexfiltratiebeveiliging.
Pakketten beheren vanuit Synapse Studio of Azure Portal
Spark-poolbibliotheken kunnen worden beheerd vanuit Synapse Studio of Azure Portal.
Navigeer in Azure Portal naar uw Azure Synapse Analytics-werkruimte.
Selecteer in de sectie Analysegroepen het tabblad Apache Spark-pools en selecteer een Spark-pool in de lijst.
Selecteer de pakketten in de sectie Instellingen van de Spark-pool.
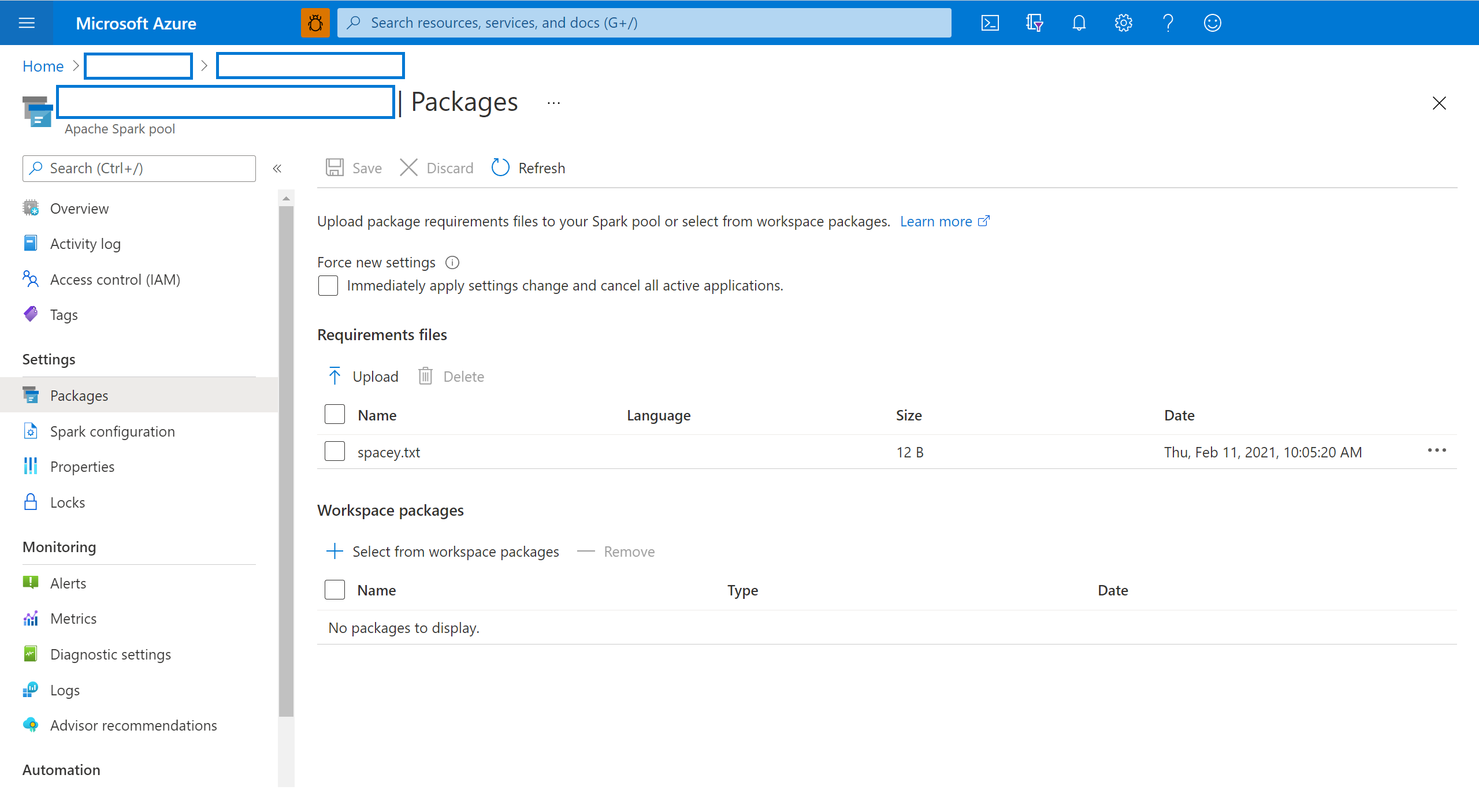
Upload voor Python-feedbibliotheken het omgevingsconfiguratiebestand met behulp van de bestandskiezer in de sectie Pakketten van de pagina.
U kunt ook extra werkruimtepakketten selecteren om Jar-, Wheel- of Tar.gz-bestanden aan uw pool toe te voegen.
U kunt afgeschafte pakketten ook verwijderen uit de sectie Werkruimtepakketten , waarna uw pool deze pakketten niet meer koppelt.
Nadat u de wijzigingen hebt opgeslagen, wordt een systeemtaak geactiveerd om de opgegeven bibliotheken te installeren en in de cache op te slaan. Dit proces helpt bij het verminderen van de totale opstarttijd van de sessie.
Nadat de taak is voltooid, halen alle nieuwe sessies de bijgewerkte poolbibliotheken op.


Belangrijk
Als u de optie nieuwe instellingen forceren selecteert, beëindigt u alle huidige sessies voor de geselecteerde Spark-pool. Zodra de sessies zijn beëindigd, moet u wachten totdat de pool opnieuw is opgestart.
Als deze instelling is uitgeschakeld, moet u wachten totdat de huidige Spark-sessie is beëindigd of handmatig stoppen. Nadat de sessie is beëindigd, moet u de pool opnieuw laten opstarten.
De installatievoortgang bijhouden
Een door het systeem gereserveerde Spark-taak wordt gestart telkens wanneer een pool wordt bijgewerkt met een nieuwe set bibliotheken. Met deze Apache Spark-taak kunt u de status van de bibliotheekinstallatie bewaken. Als de installatie mislukt vanwege bibliotheekconflicten of andere problemen, wordt de Spark-pool teruggezet naar de vorige of standaardstatus.
Daarnaast kunnen gebruikers de installatielogboeken inspecteren om afhankelijkheidsconflicten te identificeren of zien welke bibliotheken zijn geïnstalleerd tijdens de poolupdate.
Ga als volgt te werk om deze logboeken weer te geven:
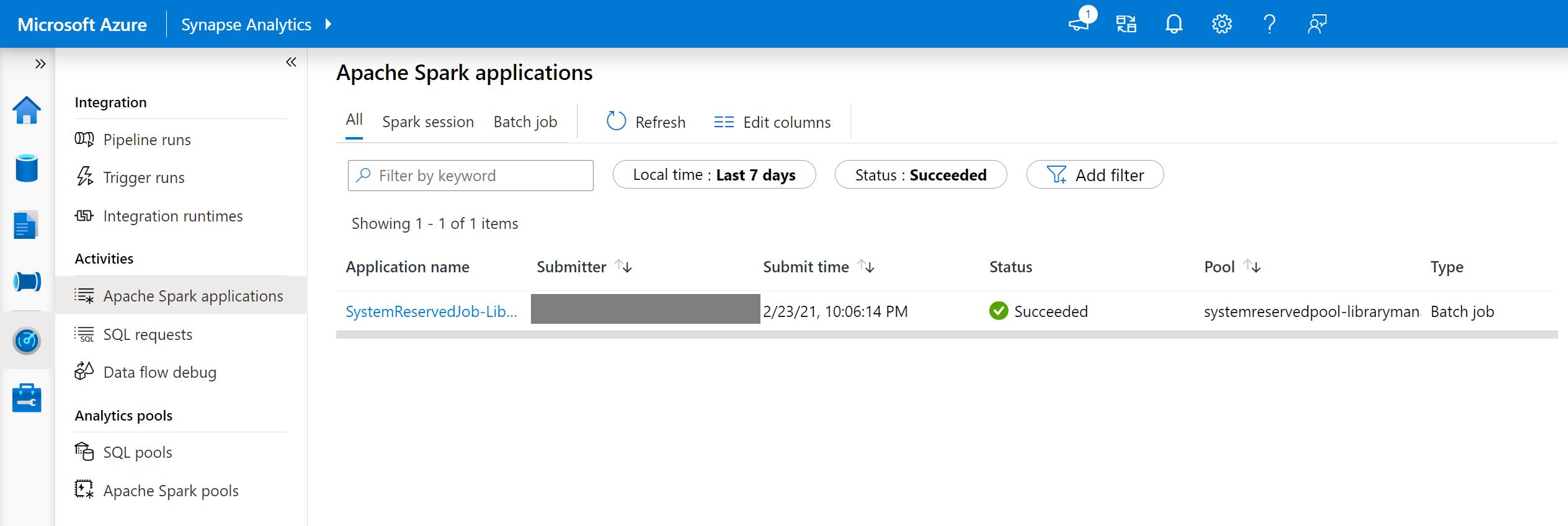
Navigeer in Synapse Studio naar de lijst met Spark-toepassingen op het tabblad Monitor .
Selecteer de Apache Spark-systeemtoepassingstaak die overeenkomt met uw poolupdate. Deze systeemtaken worden uitgevoerd onder de titel SystemReservedJob-LibraryManagement.
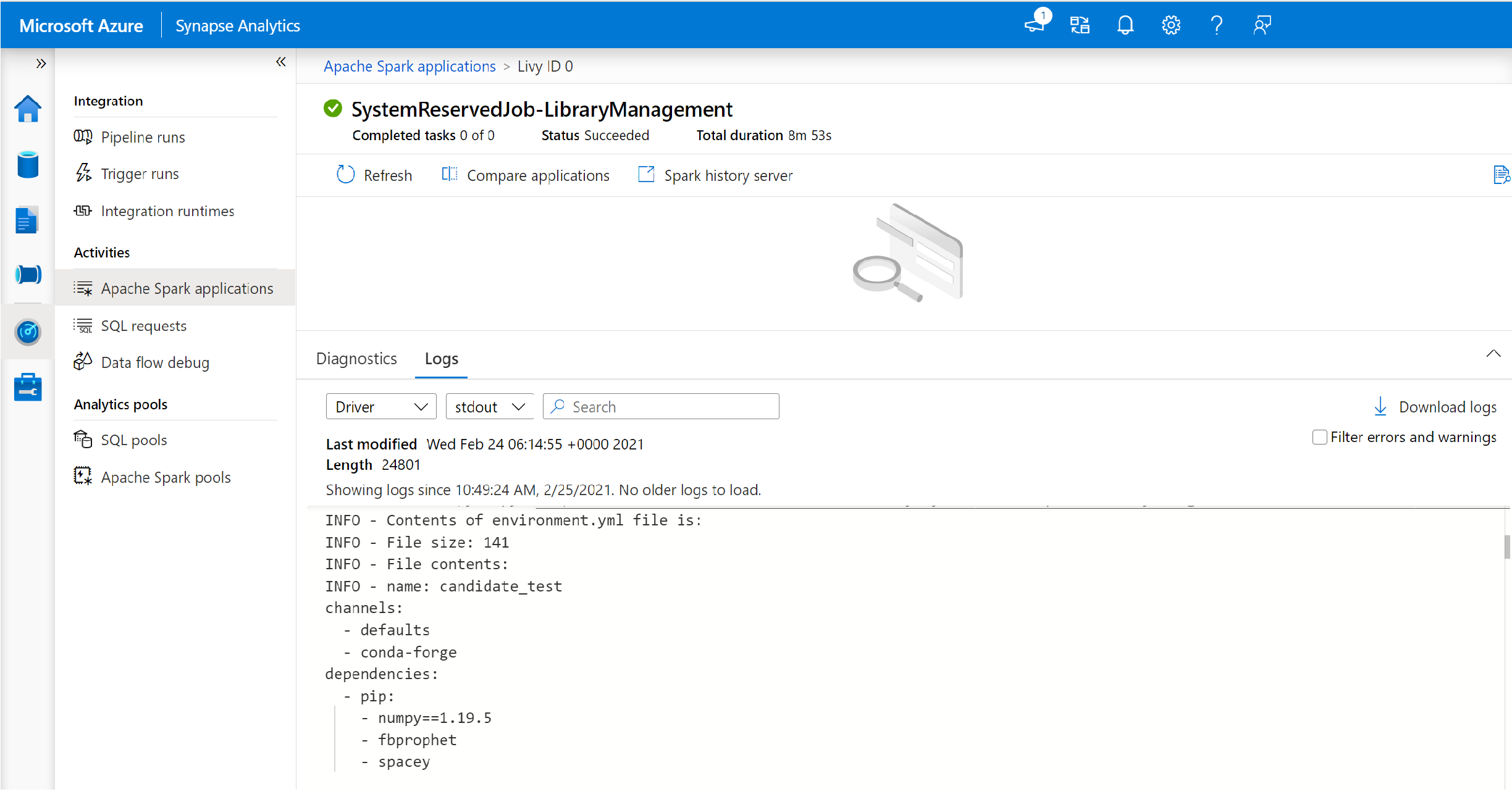
Schakel om de stuurprogramma- en stdout-logboeken weer te geven.
De resultaten bevatten de logboeken met betrekking tot de installatie van uw afhankelijkheden.


Indelingen voor omgevingsspecificatie
PIP-requirements.txt
Een requirements.txt-bestand (uitvoer van de pip freeze opdracht) kan worden gebruikt om de omgeving bij te werken. Wanneer een pool wordt bijgewerkt, worden de pakketten die in dit bestand worden vermeld, gedownload van PyPI. De volledige afhankelijkheden worden vervolgens in de cache opgeslagen en opgeslagen voor later hergebruik van de pool.
In het volgende codefragment ziet u de indeling voor het vereistenbestand. De naam van het PyPI-pakket wordt vermeld samen met een exacte versie. Dit bestand volgt de indeling die wordt beschreven in de referentiedocumentatie voor pip freeze .
In dit voorbeeld wordt een specifieke versie vastgemaakt.
absl-py==0.7.0
adal==1.2.1
alabaster==0.7.10
YML-indeling
Daarnaast kunt u een environment.yml-bestand opgeven om de poolomgeving bij te werken. De pakketten die in dit bestand worden vermeld, worden gedownload van de standaard Conda-kanalen, Conda-Forge en PyPI. U kunt andere kanalen opgeven of de standaardkanalen verwijderen met behulp van de configuratieopties.
In dit voorbeeld worden de kanalen en Conda/PyPI-afhankelijkheden opgegeven.
name: stats2
channels:
- defaults
dependencies:
- bokeh
- numpy
- pip:
- matplotlib
- koalas==1.7.0
Zie Een omgeving activeren voor meer informatie over het maken van een omgeving op basis van dit environment.yml-bestand.