Gegevens analyseren met Apache Spark
In deze zelfstudie leert u hoe u verkennende gegevensanalyse uitvoert met behulp van Azure Open Datasets en Apache Spark. Vervolgens kunt u de resultaten visualiseren in een Synapse Studio notebook in Azure Synapse Analytics.
In het bijzonder analyseren we de gegevensset Taxi in New York City (NYC). De gegevens zijn beschikbaar via Azure Open Datasets. Deze subset van de gegevensset bevat informatie over gele taxiritten: informatie over elke rit, de begin- en eindtijd en locaties, de kosten en andere interessante kenmerken.
Voordat u begint
Maak een Apache Spark-pool door de stappen te volgen in zelfstudie Een Apache Spark-pool maken.
De gegevens downloaden en voorbereiden
Maak een notebook met behulp van de PySpark-kernel. Zie Een notebook maken voor instructies.
Notitie
Vanwege de PySpark-kernel hoeft u niet expliciet contexten te maken. De Spark-context wordt automatisch voor u gemaakt wanneer u de eerste codecel uitvoert.
In deze zelfstudie gebruiken we verschillende bibliotheken om de gegevensset te visualiseren. Importeer de volgende bibliotheken om deze analyse uit te voeren:
import matplotlib.pyplot as plt import seaborn as sns import pandas as pdOmdat de onbewerkte gegevens een Parquet-indeling hebben, kunt u de Spark-context gebruiken om het bestand rechtstreeks als een DataFrame in het geheugen op te halen. Maak een Spark DataFrame door de gegevens op te halen via de Open Datasets-API. Hier gebruiken we het Spark DataFrame-schema voor leeseigenschappen om de gegevenstypen en het schema af te leiden.
from azureml.opendatasets import NycTlcYellow from datetime import datetime from dateutil import parser end_date = parser.parse('2018-05-08 00:00:00') start_date = parser.parse('2018-05-01 00:00:00') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) df = spark.createDataFrame(nyc_tlc.to_pandas_dataframe())Nadat de gegevens zijn gelezen, willen we eerst filteren om de gegevensset op te schonen. We kunnen overbodige kolommen verwijderen en kolommen toevoegen waarmee belangrijke informatie wordt geëxtraheerd. Daarnaast filteren we afwijkingen in de gegevensset uit.
# Filter the dataset from pyspark.sql.functions import * filtered_df = df.select('vendorID', 'passengerCount', 'tripDistance','paymentType', 'fareAmount', 'tipAmount'\ , date_format('tpepPickupDateTime', 'hh').alias('hour_of_day')\ , dayofweek('tpepPickupDateTime').alias('day_of_week')\ , dayofmonth(col('tpepPickupDateTime')).alias('day_of_month'))\ .filter((df.passengerCount > 0)\ & (df.tipAmount >= 0)\ & (df.fareAmount >= 1) & (df.fareAmount <= 250)\ & (df.tripDistance > 0) & (df.tripDistance <= 200)) filtered_df.createOrReplaceTempView("taxi_dataset")
Gegevens analyseren
Als gegevensanalist beschikt u over een breed scala aan hulpprogramma's waarmee u inzichten uit de gegevens kunt extraheren. In dit deel van de zelfstudie doorlopen we enkele handige hulpprogramma's die beschikbaar zijn in Azure Synapse Analytics-notebooks. In deze analyse willen we de factoren begrijpen die hogere taxitips opleveren voor onze geselecteerde periode.
Apache Spark SQL Magic
Eerst voeren we verkennende gegevensanalyses uit door Apache Spark SQL en magic-opdrachten met de Azure Synapse notebook. Nadat we onze query hebben uitgevoerd, visualiseren we de resultaten met behulp van de ingebouwde chart options mogelijkheid.
Maak in uw notebook een nieuwe cel en kopieer de volgende code. Met behulp van deze query willen we begrijpen hoe de gemiddelde fooibedragen zijn gewijzigd gedurende de periode die we hebben geselecteerd. Deze query helpt ons ook bij het identificeren van andere nuttige inzichten, waaronder het minimum/maximum fooibedrag per dag en het gemiddelde tariefbedrag.
%%sql SELECT day_of_month , MIN(tipAmount) AS minTipAmount , MAX(tipAmount) AS maxTipAmount , AVG(tipAmount) AS avgTipAmount , AVG(fareAmount) as fareAmount FROM taxi_dataset GROUP BY day_of_month ORDER BY day_of_month ASCNadat de query is uitgevoerd, kunnen we de resultaten visualiseren door over te schakelen naar de grafiekweergave. In dit voorbeeld wordt een lijndiagram gemaakt door het
day_of_monthveld op te geven als de sleutel enavgTipAmountals de waarde. Nadat u de selecties hebt gemaakt, selecteert u Toepassen om de grafiek te vernieuwen.
Gegevens visualiseren
Naast de ingebouwde grafiekopties voor notebooks kunt u populaire opensource-bibliotheken gebruiken om uw eigen visualisaties te maken. In de volgende voorbeelden gebruiken we Seaborn en Matplotlib. Dit zijn veelgebruikte Python-bibliotheken voor gegevensvisualisatie.
Notitie
Standaard bevat elke Apache Spark-pool in Azure Synapse Analytics een set veelgebruikte en standaardbibliotheken. U kunt de volledige lijst met bibliotheken bekijken in de Azure Synapse runtime-documentatie. Als u bovendien code van derden of lokaal gebouwde code beschikbaar wilt maken voor uw toepassingen, kunt u een bibliotheek installeren op een van uw Spark-pools.
Om het ontwikkelen eenvoudiger en goedkoper te maken, gaan we de gegevensset downsamppleen. We gebruiken de ingebouwde apache Spark-samplingfunctie. Bovendien is voor zowel Seaborn als Matplotlib een Pandas DataFrame- of NumPy-matrix vereist. Als u een Pandas DataFrame wilt ophalen, gebruikt u de
toPandas()opdracht om het DataFrame te converteren.# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234) # The charting package needs a Pandas DataFrame or NumPy array to do the conversion sampled_taxi_pd_df = sampled_taxi_df.toPandas()We willen de distributie van tips in onze gegevensset begrijpen. We gebruiken Matplotlib om een histogram te maken met de verdeling van de hoeveelheid en het aantal fooien. Op basis van de verdeling kunnen we zien dat tips scheef zijn ten opzichte van bedragen die kleiner zijn dan of gelijk zijn aan $ 10.
# Look at a histogram of tips by count by using Matplotlib ax1 = sampled_taxi_pd_df['tipAmount'].plot(kind='hist', bins=25, facecolor='lightblue') ax1.set_title('Tip amount distribution') ax1.set_xlabel('Tip Amount ($)') ax1.set_ylabel('Counts') plt.suptitle('') plt.show()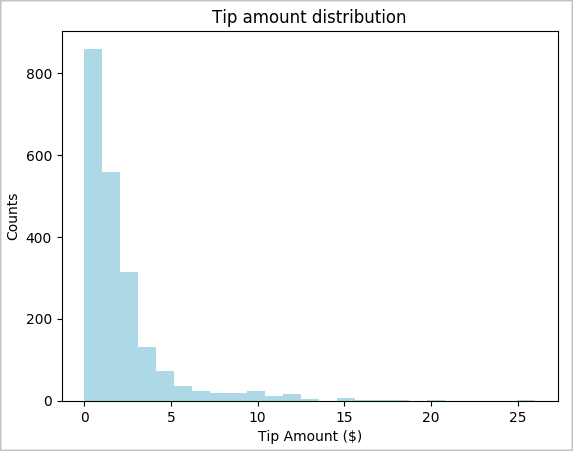
Vervolgens willen we de relatie begrijpen tussen de tips voor een bepaalde reis en de dag van de week. Gebruik Seaborn om een boxplot te maken met een overzicht van de trends voor elke dag van de week.
# View the distribution of tips by day of week using Seaborn ax = sns.boxplot(x="day_of_week", y="tipAmount",data=sampled_taxi_pd_df, showfliers = False) ax.set_title('Tip amount distribution per day') ax.set_xlabel('Day of Week') ax.set_ylabel('Tip Amount ($)') plt.show()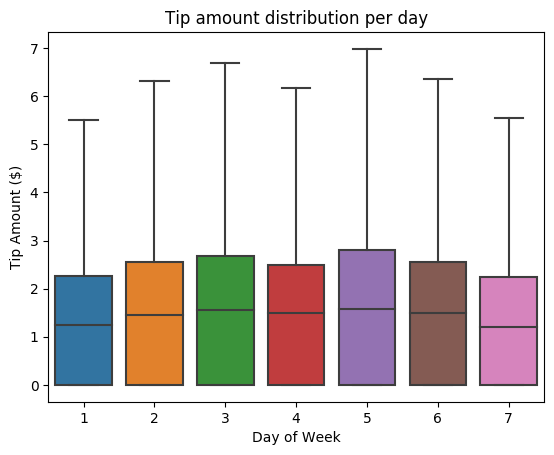
Een andere hypothese van ons kan zijn dat er een positieve relatie is tussen het aantal passagiers en het totale aantal taxitips. Als u deze relatie wilt controleren, voert u de volgende code uit om een boxplot te genereren die de distributie van tips voor elk aantal passagiers illustreert.
# How many passengers tipped by various amounts ax2 = sampled_taxi_pd_df.boxplot(column=['tipAmount'], by=['passengerCount']) ax2.set_title('Tip amount by Passenger count') ax2.set_xlabel('Passenger count') ax2.set_ylabel('Tip Amount ($)') ax2.set_ylim(0,30) plt.suptitle('') plt.show()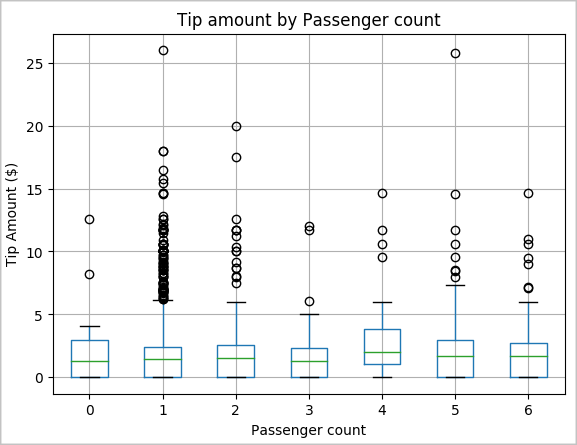
Ten slotte willen we de relatie tussen het tariefbedrag en het fooibedrag begrijpen. Op basis van de resultaten kunnen we zien dat er verschillende waarnemingen zijn waarbij mensen geen fooi geven. We zien echter ook een positieve relatie tussen het totale tarief en fooibedragen.
# Look at the relationship between fare and tip amounts ax = sampled_taxi_pd_df.plot(kind='scatter', x= 'fareAmount', y = 'tipAmount', c='blue', alpha = 0.10, s=2.5*(sampled_taxi_pd_df['passengerCount'])) ax.set_title('Tip amount by Fare amount') ax.set_xlabel('Fare Amount ($)') ax.set_ylabel('Tip Amount ($)') plt.axis([-2, 80, -2, 20]) plt.suptitle('') plt.show()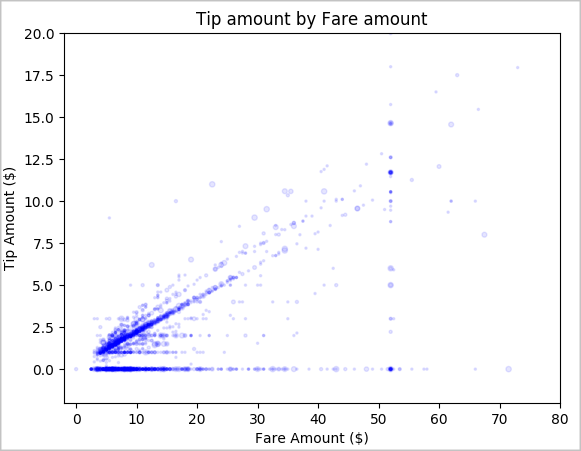
Het Spark-exemplaar afsluiten
Nadat u klaar bent met het uitvoeren van de toepassing, sluit u het notebook af om de resources vrij te geven. Sluit het tabblad of selecteer Sessie beëindigen in het statusvenster onderaan het notitieblok.
Zie ook
- Overzicht: Apache Spark in Azure Synapse Analytics
- Een machine learning-model bouwen met Apache SparkML