Verbinding maken met Azure Data Explorer met behulp van Apache Spark voor Azure Synapse Analytics
In dit artikel wordt beschreven hoe u toegang krijgt tot Azure Data Explorer-databases vanuit Synapse Studio met Apache Spark voor Azure Synapse Analytics.
Vereisten
- Maak een Azure Data Explorer-cluster en -database.
- Een bestaande Azure Synapse Analytics-werkruimte hebben of een nieuwe werkruimte maken door de stappen in quickstart te volgen: Een Azure Synapse-werkruimte maken.
- Een bestaande Apache Spark-pool hebben of een nieuwe pool maken door de stappen in quickstart te volgen: Een Apache Spark-pool maken met behulp van Azure Portal.
- Maak een Microsoft Entra-app door een Microsoft Entra-toepassing in te richten.
- Verdeel uw Microsoft Entra-app toegang tot uw database door de stappen in Databasemachtigingen voor Azure Data Explorer beheren te volgen.
Ga naar Synapse Studio
Selecteer Synapse Studio starten vanuit een Azure Synapse-werkruimte. Selecteer op de startpagina van Synapse Studio de optie Gegevens. U wordt nu naar Data Object Explorer geleid.
Een Azure Data Explorer-database verbinden met een Azure Synapse-werkruimte
Het verbinden van een Azure Data Explorer-database met een werkruimte wordt uitgevoerd via een gekoppelde service. Met een gekoppelde Azure Data Explorer-service kunt u gegevens bekijken en verkennen, lezen en schrijven vanuit Apache Spark voor Azure Synapse. U kunt ook integratietaken in een pijplijn uitvoeren.
Voer de volgende stappen uit vanuit Data Object Explorer om een rechtstreekse verbinding met een Azure Data Explorer-cluster te maken:
Selecteer het pictogram + bij de optie Gegevens.
Selecteer Verbinding maken om verbinding te maken met externe gegevens.
Selecteer Azure Data Explorer (Kusto).
Selecteer Continue.
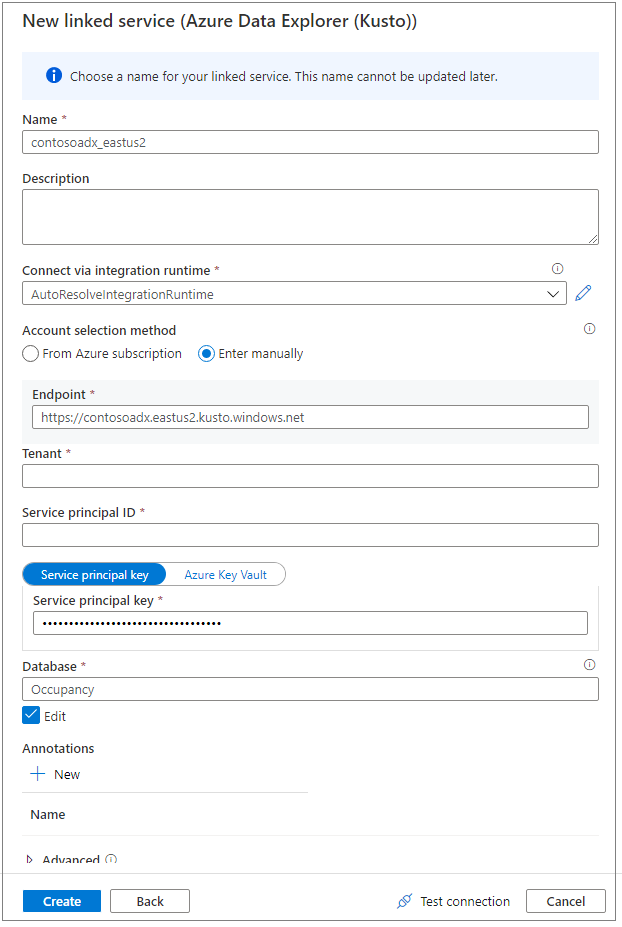
Gebruik een beschrijvende naam voor de gekoppelde service. De naam wordt weergegeven in Data Object Explorer en wordt tijdens Azure Synapse-uitvoeringen gebruikt om verbinding te maken met de database.
Selecteer het Azure Data Explorer-cluster in uw abonnement of voer de URI in.
Voer de id en de sleutel van de service-principal in. Zorg ervoor dat deze service-principal toegang heeft tot de database voor leesbewerkingen en toegang tot de ingestor voor het opnemen van gegevens.
Voer de naam van de Azure Data Explorer-database in.
Selecteer Verbinding testen om te controleren of u over de juiste machtigingen beschikt.
Selecteer Maken.
Notitie
(Optioneel) Verbinding testen valideert geen schrijftoegang. Zorg ervoor dat uw service-principal-id schrijftoegang heeft tot de Azure Data Explorer-database.
Azure Data Explorer-clusters en -databases worden weergegeven op het tabblad Gekoppeld onder de sectie Azure Data Explorer.
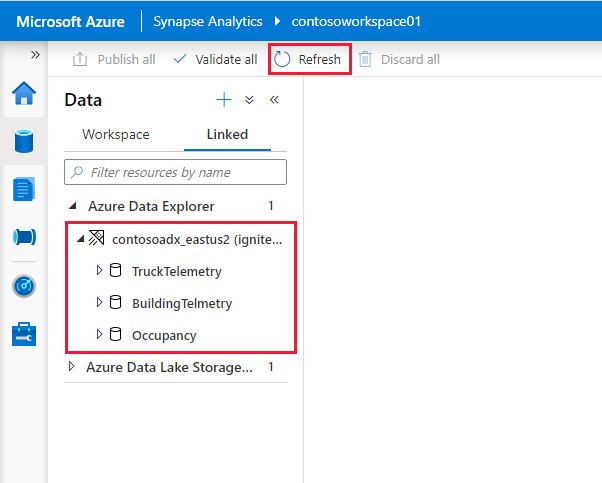
Voordat u de gekoppelde service vanuit een notebook kunt gebruiken, moet deze worden gepubliceerd naar de werkruimte. Klik op Publiceren op de werkbalk, controleer de wijzigingen die in behandeling zijn en klik op OK.
Notitie
In de huidige release worden de databaseobjecten ingevuld op basis van uw Microsoft Entra-accountmachtigingen voor de Azure Data Explorer-databases. Wanneer u de Apache Spark-notebooks of -integratietaken uitvoert, wordt de referentie in de koppelingsservice gebruikt (bijvoorbeeld service-principal).
Snel communiceren via met code gegenereerde acties
Wanneer u met de rechtermuisknop op een database of tabel klikt, wordt er een lijst met voorbeelden van Spark-notebooks weergegeven. Selecteer een optie om gegevens te lezen, schrijven of streamen naar Azure Data Explorer.

Hier volgt een voorbeeld van het lezen van gegevens. Koppel het notebook aan uw Spark-pool en voer de cel uit.

Notitie
Bij de eerste uitvoering kan het langer dan drie minuten duren om de Spark-sessie te initiëren. Volgende uitvoeringen zullen veel sneller gaan.
Beperkingen
De Azure Data Explorer-connector wordt momenteel niet ondersteund in virtuele netwerken die door Azure Synapse worden beheerd.