Zelfstudie: Anomaliedetectie met Azure AI-services
In deze zelfstudie leert u hoe u uw gegevens eenvoudig kunt verrijken in Azure Synapse Analytics met Azure AI-services. U gebruikt Azure AI Anomaly Detector om afwijkingen te vinden. Een gebruiker in Azure Synapse kan eenvoudigweg een tabel selecteren om te verrijken met detectie van afwijkingen.
In deze zelfstudie komt het volgende aan bod:
- Stappen voor het ophalen van een Spark-tabelgegevensset die tijdreeksgegevens bevat.
- Gebruik van een wizard-ervaring in Azure Synapse om gegevens te verrijken met behulp van Anomaly Detector.
Als u geen Azure-abonnement hebt, maakt u een gratis account voordat u begint.
Vereisten
- Azure Synapse Analytics-werkruimte met een Azure Data Lake Storage Gen2-opslagaccount dat is geconfigureerd als de standaardopslag. U moet de bijdrager voor opslagblobgegevens zijn van het Data Lake Storage Gen2-bestandssysteem waarmee u werkt.
- Spark-pool in uw Azure Synapse Analytics-werkruimte. Zie Een Spark-pool maken in Azure Synapse voor meer informatie.
- Voltooiing van de stappen vóór configuratie in de zelfstudie Azure AI-services configureren in Azure Synapse .
Meld u aan bij het Azure Portal
Meld u aan bij het Azure-portaal.
Een Spark-tabel maken
Voor deze zelfstudie hebt u een Spark-tabel nodig.
Maak een PySpark-notebook en voer de volgende code uit.
from pyspark.sql.functions import lit
df = spark.createDataFrame([
("1972-01-01T00:00:00Z", 826.0),
("1972-02-01T00:00:00Z", 799.0),
("1972-03-01T00:00:00Z", 890.0),
("1972-04-01T00:00:00Z", 900.0),
("1972-05-01T00:00:00Z", 766.0),
("1972-06-01T00:00:00Z", 805.0),
("1972-07-01T00:00:00Z", 821.0),
("1972-08-01T00:00:00Z", 20000.0),
("1972-09-01T00:00:00Z", 883.0),
("1972-10-01T00:00:00Z", 898.0),
("1972-11-01T00:00:00Z", 957.0),
("1972-12-01T00:00:00Z", 924.0),
("1973-01-01T00:00:00Z", 881.0),
("1973-02-01T00:00:00Z", 837.0),
("1973-03-01T00:00:00Z", 9000.0)
], ["timestamp", "value"]).withColumn("group", lit("series1"))
df.write.mode("overwrite").saveAsTable("anomaly_detector_testing_data")
Een Apache Spark-tabel met de naam anomaly_detector_testing_data moet nu worden weergegeven in de standaard Apache Spark-database.
De wizard Azure AI-services openen
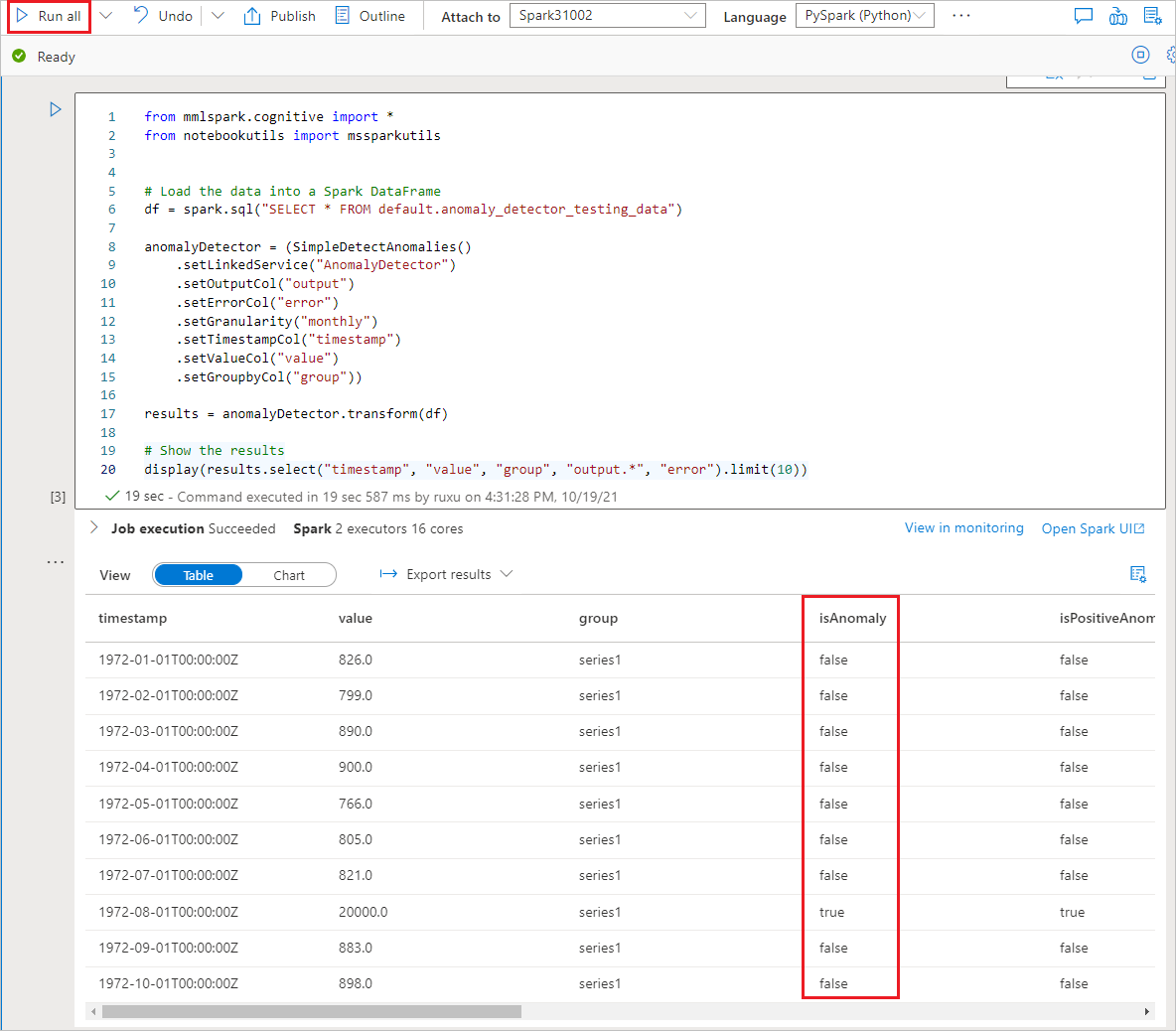
Klik met de rechtermuisknop op de Spark-tabel die u in de vorige stap hebt gemaakt. Selecteer Machine Learning>Predict met een model om de wizard te openen.
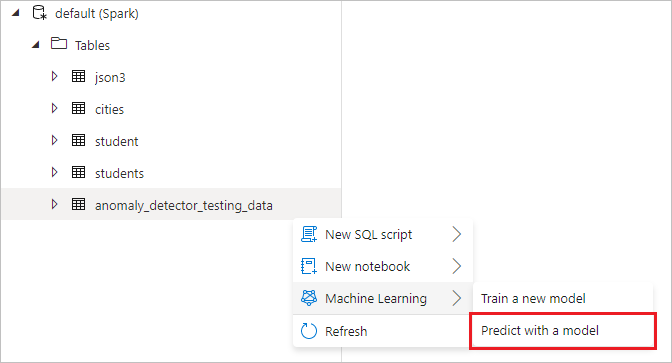
Er wordt een configuratievenster weergegeven en u wordt gevraagd een vooraf getraind model te selecteren. Selecteer Anomaly Detector.
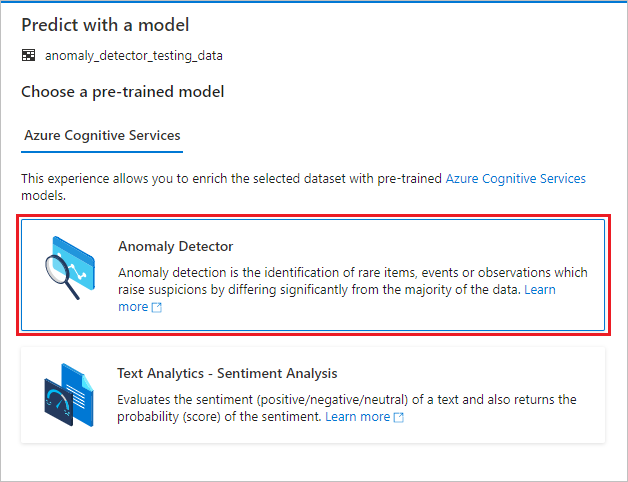
Anomaly Detector configureren
Geef de volgende details op om Anomaly Detector te configureren:
Gekoppelde Azure Cognitive Services-service: als onderdeel van de vereiste stappen hebt u een gekoppelde service gemaakt voor uw Azure AI-service. Selecteer deze hier.
Granulariteit: de snelheid waarmee uw gegevens worden bemonsterd. Kies maandelijks.
Tijdstempelkolom: de kolom die de tijd van de reeks aangeeft. Kies een tijdstempel (tekenreeks).
Kolom met tijdreekswaarden: de kolom die de waarde van de reeks aangeeft op het moment dat is opgegeven door de kolom Tijdstempel. Kies waarde (dubbel).
Groepeerkolom: De kolom die de reeks groepeert. Dat wil zeggen dat alle rijen met dezelfde waarde in deze kolom één tijdreeks moeten vormen. Kies groep (tekenreeks).
Wanneer u klaar bent, selecteert u Notitieblok openen. Hiermee wordt een notebook voor u gegenereerd met PySpark-code die gebruikmaakt van Azure AI-services om afwijkingen te detecteren.
Het notitieblok uitvoeren
Het notebook dat u zojuist hebt geopend, maakt gebruik van de SynapseML-bibliotheek om verbinding te maken met Azure AI-services. Met de gekoppelde Service van Azure AI-services die u hebt opgegeven, kunt u vanuit deze ervaring veilig verwijzen naar uw Azure AI-service zonder geheimen te onthullen.
U kunt nu alle cellen uitvoeren om anomaliedetectie uit te voeren. Selecteer Alles uitvoeren. Meer informatie over Anomaly Detector in Azure AI-services.