Een Azure Synapse Analytics-werkruimte van de ene regio naar de andere verplaatsen
Dit artikel is een stapsgewijze handleiding die laat zien hoe u een Azure Synapse Analytics-werkruimte van de ene Azure-regio naar de andere verplaatst.
Notitie
De stappen in dit artikel verplaatsen de werkruimte niet daadwerkelijk. De stappen laten zien hoe u een nieuwe werkruimte in een nieuwe regio maakt met behulp van back-ups en artefacten van toegewezen SQL-pools van Azure Synapse Analytics vanuit de bronregio.
Vereisten
- Integreer de Azure Synapse-werkruimte van de bronregio met Azure DevOps of GitHub. Zie Broncodebeheer in Synapse Studio voor meer informatie.
- Zorg ervoor dat Azure PowerShell - en Azure CLI-modules zijn geïnstalleerd op de server waarop scripts worden uitgevoerd.
- Zorg ervoor dat alle afhankelijke services, zoals Azure Machine Learning, Azure Storage en Azure Private Link-hubs, opnieuw worden gemaakt in de doelregio of naar de doelregio worden verplaatst als de service ondersteuning biedt voor een regioverplaatsing.
- Verplaats Azure Storage naar een andere regio. Zie Een Azure Storage-account verplaatsen naar een andere regio voor meer informatie.
- Zorg ervoor dat de naam van de toegewezen SQL-pool en de naam van de Apache Spark-pool hetzelfde zijn in de bronregio en de werkruimte van de doelregio.
Scenario's voor het verplaatsen van een regio
- Nieuwe nalevingsvereisten: organisaties vereisen dat gegevens en services in dezelfde regio worden geplaatst als onderdeel van nieuwe nalevingsvereisten.
- Beschikbaarheid van een nieuwe Azure-regio: scenario's waarin een nieuwe Azure-regio beschikbaar is en er project- of bedrijfsvereisten zijn om de werkruimte en andere Azure-resources te verplaatsen naar de nieuw beschikbare Azure-regio.
- Verkeerde regio geselecteerd: de verkeerde regio is geselecteerd toen de Azure-resources werden gemaakt.
Stappen voor het verplaatsen van een Azure Synapse-werkruimte naar een andere regio
Het verplaatsen van een Azure Synapse-werkruimte van de ene regio naar een andere regio is een proces met meerdere stappen. Dit zijn de stappen op hoog niveau:
- Maak een nieuwe Azure Synapse-werkruimte in de doelregio, samen met een Spark-pool met dezelfde configuraties als die worden gebruikt in de werkruimte van de bronregio.
- Herstel de toegewezen SQL-pool naar de doelregio met behulp van herstelpunten of geo-back-ups.
- Maak alle vereiste aanmeldingen opnieuw op de nieuwe logische SQL Server.
- Maak serverloze SQL-pool- en Spark-pooldatabases en -objecten.
- Voeg een Azure DevOps-service-principal toe aan de Rol op rollen gebaseerd toegangsbeheer (RBAC) Synapse Artifact Publisher van Azure Synapse als u een Azure DevOps-releasepijplijn gebruikt om de artefacten te implementeren.
- Implementeer codeartefacten (SQL-scripts, notebooks), gekoppelde services, pijplijnen, gegevenssets, Spark-taakdefinities en referenties van Azure DevOps-releasepijplijnen naar de Azure Synapse-werkruimte.
- Voeg Microsoft Entra-gebruikers of -groepen toe aan Azure Synapse RBAC-rollen. Het verlenen van inzender voor Opslagblob-toegang tot door het systeem toegewezen beheerde identiteit (SA-MI) in Azure Storage en Azure Key Vault als u verificatie uitvoert met behulp van een beheerde identiteit.
- Verdeel opslagbloblezer- of Opslagblobbijdragerrollen aan vereiste Microsoft Entra-gebruikers op de standaard gekoppelde opslag of in het Opslagaccount waarop gegevens moeten worden opgevraagd met behulp van een serverloze SQL-pool.
- Zelf-hostende Integration Runtime (SHIR) opnieuw maken.
- Upload handmatig alle vereiste bibliotheken en JAR's in de Azure Synapse-doelwerkruimte.
- Maak alle beheerde privé-eindpunten als de werkruimte is geïmplementeerd in een beheerd virtueel netwerk.
- Test de nieuwe werkruimte in de doelregio en werk eventuele DNS-vermeldingen bij die verwijzen naar de werkruimte van de bronregio.
- Als er een privé-eindpuntverbinding is gemaakt in de bronwerkruimte, maakt u er een in de werkruimte van de doelregio.
- U kunt de werkruimte in de bronregio verwijderen nadat u deze grondig hebt getest en alle verbindingen naar de werkruimte van de doelregio hebt gerouteerd.
Voorbereiden
Stap 1: Een Azure Synapse-werkruimte maken in een doelregio
In deze sectie maakt u de Azure Synapse-werkruimte met behulp van Azure PowerShell, de Azure CLI en Azure Portal. U maakt een resourcegroep samen met een Azure Data Lake Storage Gen2-account dat wordt gebruikt als de standaardopslag voor de werkruimte als onderdeel van het PowerShell-script en het CLI-script. Als u het implementatieproces wilt automatiseren, roept u deze PowerShell- of CLI-scripts aan vanuit de DevOps-releasepijplijn.
Azure Portal
Als u een werkruimte wilt maken vanuit Azure Portal, volgt u de stappen in quickstart: Een Synapse-werkruimte maken.
Azure PowerShell
Met het volgende script worden de resourcegroep en de Azure Synapse-werkruimte gemaakt met behulp van de cmdlets New-AzResourceGroup en New-AzSynapseWorkspace.
Een brongroep maken
$storageAccountName= "<YourDefaultStorageAccountName>"
$resourceGroupName="<YourResourceGroupName>"
$regionName="<YourTargetRegionName>"
$containerName="<YourFileSystemName>" # This is the file system name
$workspaceName="<YourTargetRegionWorkspaceName>"
$sourceRegionWSName="<Your source region workspace name>"
$sourceRegionRGName="<YourSourceRegionResourceGroupName>"
$sqlUserName="<SQLUserName>"
$sqlPassword="<SQLStrongPassword>"
$sqlPoolName ="<YourTargetSQLPoolName>" #Both Source and target workspace SQL pool name will be same
$sparkPoolName ="<YourTargetWorkspaceSparkPoolName>"
$sparkVersion="2.4"
New-AzResourceGroup -Name $resourceGroupName -Location $regionName
Een Data Lake Storage Gen2-account maken
#If the Storage account is already created, then you can skip this step.
New-AzStorageAccount -ResourceGroupName $resourceGroupName `
-Name $storageAccountName `
-Location $regionName `
-SkuName Standard_LRS `
-Kind StorageV2 `
-EnableHierarchicalNamespace $true
Een Azure Synapse-werkruimte maken
$password = ConvertTo-SecureString $sqlPassword -AsPlainText -Force
$creds = New-Object System.Management.Automation.PSCredential ($sqlUserName, $password)
New-AzSynapseWorkspace -ResourceGroupName $resourceGroupName `
-Name $workspaceName -Location $regionName `
-DefaultDataLakeStorageAccountName $storageAccountName `
-DefaultDataLakeStorageFilesystem $containerName `
-SqlAdministratorLoginCredential $creds
Als u de werkruimte wilt maken met een beheerd virtueel netwerk, voegt u de extra parameter ManagedVirtualNetwork toe aan het script. Zie Managed Virtual Network Config voor meer informatie over de beschikbare opties.
#Creating a managed virtual network configuration
$config = New-AzSynapseManagedVirtualNetworkConfig -PreventDataExfiltration -AllowedAadTenantIdsForLinking ContosoTenantId
#Creating an Azure Synapse workspace
New-AzSynapseWorkspace -ResourceGroupName $resourceGroupName `
-Name $workspaceName -Location $regionName `
-DefaultDataLakeStorageAccountName $storageAccountName `
-DefaultDataLakeStorageFilesystem $containerName `
-SqlAdministratorLoginCredential $creds `
-ManagedVirtualNetwork $config
Azure-CLI
Met dit Azure CLI-script maakt u een resourcegroep, een Data Lake Storage Gen2-account en een bestandssysteem. Vervolgens wordt de Azure Synapse-werkruimte gemaakt.
Een brongroep maken
az group create --name $resourceGroupName --location $regionName
Een Data Lake Storage Gen2-account maken
Met het volgende script maakt u een opslagaccount en container.
# Checking if name is not used only then creates it.
$StorageAccountNameAvailable=(az storage account check-name --name $storageAccountName --subscription $subscriptionId | ConvertFrom-Json).nameAvailable
if($StorageAccountNameAvailable)
{
Write-Host "Storage account Name is available to be used...creating storage account"
#Creating a Data Lake Storage Gen2 account
$storageAccountProvisionStatus=az storage account create `
--name $storageAccountName `
--resource-group $resourceGroupName `
--location $regionName `
--sku Standard_GRS `
--kind StorageV2 `
--enable-hierarchical-namespace $true
($storageAccountProvisionStatus| ConvertFrom-Json).provisioningState
}
else
{
Write-Host "Storage account Name is NOT available to be used...use another name -- exiting the script..."
EXIT
}
#Creating a container in a Data Lake Storage Gen2 account
$key=(az storage account keys list -g $resourceGroupName -n $storageAccountName|ConvertFrom-Json)[0].value
$fileShareStatus=(az storage share create --account-name $storageAccountName --name $containerName --account-key $key)
if(($fileShareStatus|ConvertFrom-Json).created -eq "True")
{
Write-Host f"Successfully created the fileshare - '$containerName'"
}
Een Azure Synapse-werkruimte maken
az synapse workspace create `
--name $workspaceName `
--resource-group $resourceGroupName `
--storage-account $storageAccountName `
--file-system $containerName `
--sql-admin-login-user $sqlUserName `
--sql-admin-login-password $sqlPassword `
--location $regionName
Als u een beheerd virtueel netwerk wilt inschakelen, neemt u de parameter --enable-managed-virtual-network op in het voorgaande script. Zie voor meer opties het beheerde virtuele netwerk van de werkruimte.
az synapse workspace create `
--name $workspaceName `
--resource-group $resourceGroupName `
--storage-account $storageAccountName `
--file-system $FileShareName `
--sql-admin-login-user $sqlUserName `
--sql-admin-login-password $sqlPassword `
--location $regionName `
--enable-managed-virtual-network true `
--allowed-tenant-ids "Contoso"
Stap 2: Een firewallregel voor een Azure Synapse-werkruimte maken
Nadat de werkruimte is gemaakt, voegt u de firewallregels voor de werkruimte toe. Beperk de IP-adressen tot een bepaald bereik. U kunt een firewall toevoegen vanuit Azure Portal of met behulp van PowerShell of de CLI.
Azure Portal
Selecteer de firewallopties en voeg het bereik van IP-adressen toe, zoals wordt weergegeven in de volgende schermopname.
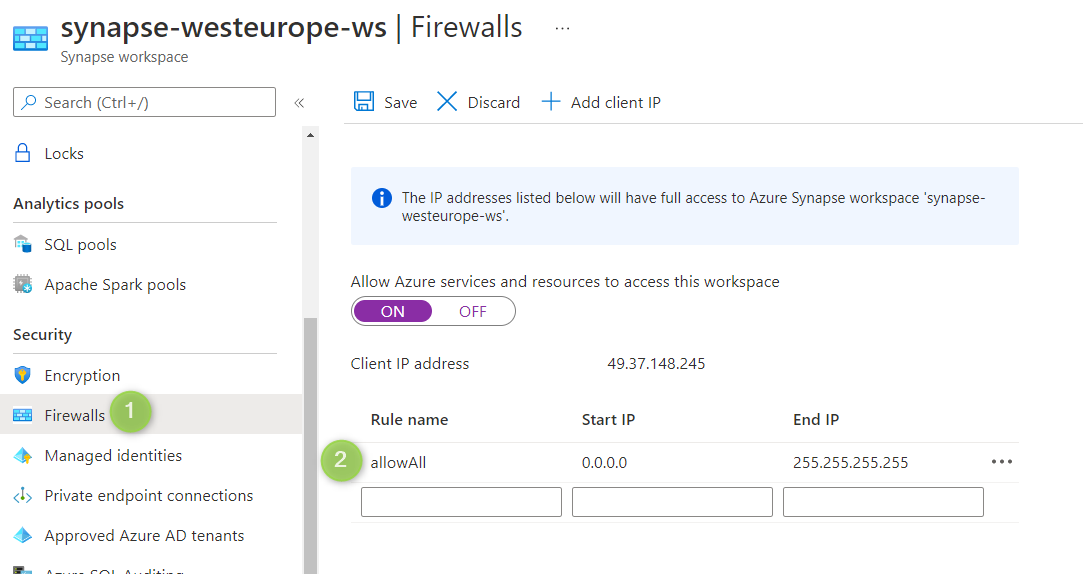
Azure PowerShell
Voer de volgende PowerShell-opdrachten uit om firewallregels toe te voegen door de begin- en eind-IP-adressen op te geven. Werk het IP-adresbereik bij op basis van uw vereisten.
$WorkspaceWeb = (Get-AzSynapseWorkspace -Name $workspaceName -ResourceGroupName $resourceGroup).ConnectivityEndpoints.Web
$WorkspaceDev = (Get-AzSynapseWorkspace -Name $workspaceName -ResourceGroupName $resourceGroup).ConnectivityEndpoints.Dev
# Adding firewall rules
$FirewallParams = @{
WorkspaceName = $workspaceName
Name = 'Allow Client IP'
ResourceGroupName = $resourceGroup
StartIpAddress = "0.0.0.0"
EndIpAddress = "255.255.255.255"
}
New-AzSynapseFirewallRule @FirewallParams
Voer het volgende script uit om de SQL-beheerinstellingen voor beheerde identiteiten van de werkruimte bij te werken:
Set-AzSynapseManagedIdentitySqlControlSetting -WorkspaceName $workspaceName -Enabled $true
Azure-CLI
az synapse workspace firewall-rule create --name allowAll --workspace-name $workspaceName `
--resource-group $resourceGroupName --start-ip-address 0.0.0.0 --end-ip-address 255.255.255.255
Voer het volgende script uit om de SQL-beheerinstellingen voor beheerde identiteiten van de werkruimte bij te werken:
az synapse workspace managed-identity grant-sql-access `
--workspace-name $workspaceName --resource-group $resourceGroupName
Stap 3: Een Apache Spark-pool maken
Maak de Spark-pool met dezelfde configuratie die wordt gebruikt in de werkruimte van de bronregio.
Azure Portal
U kunt ook de Spark-pool maken vanuit Synapse Studio door de stappen in quickstart te volgen: Een serverloze Apache Spark-pool maken met behulp van Synapse Studio.
Azure PowerShell
Met het volgende script maakt u een Spark-pool met twee werkrollen en één stuurprogrammaknooppunt, en een kleine clustergrootte met 4 kernen en 32 GB RAM. Werk de waarden bij zodat deze overeenkomen met de Spark-pool van uw bronregiowerkruimte.
#Creating a Spark pool with 3 nodes (2 worker + 1 driver) and a small cluster size with 4 cores and 32 GB RAM.
New-AzSynapseSparkPool `
-WorkspaceName $workspaceName `
-Name $sparkPoolName `
-NodeCount 3 `
-SparkVersion $sparkVersion `
-NodeSize Small
Azure-CLI
az synapse spark pool create --name $sparkPoolName --workspace-name $workspaceName --resource-group $resourceGroupName `
--spark-version $sparkVersion --node-count 3 --node-size small
Verplaatsen
Stap 4: Een toegewezen SQL-pool herstellen
Herstellen vanuit geografisch redundante back-ups
Zie Geo-restore a dedicated SQL pool in Azure Synapse Analytics (Een toegewezen SQL-pool herstellen in Azure Synapse Analytics) als u de toegewezen SQL-pools wilt herstellen vanuit geo-back-up met behulp van Azure Portal en PowerShell.
Herstellen met behulp van herstelpunten uit de toegewezen SQL-pool van de bronregiowerkruimte
Herstel de toegewezen SQL-pool naar de werkruimte van de doelregio met behulp van het herstelpunt van de toegewezen SQL-pool van de bronregiowerkruimte. U kunt Azure Portal, Synapse Studio of PowerShell gebruiken om te herstellen vanaf herstelpunten. Als de bronregio niet toegankelijk is, kunt u deze optie niet herstellen.
Synapse Studio
Vanuit Synapse Studio kunt u de toegewezen SQL-pool herstellen vanuit elke werkruimte in het abonnement met behulp van herstelpunten. Terwijl u de toegewezen SQL-pool maakt, selecteert u onder Aanvullende instellingen het herstelpunt en selecteert u de werkruimte, zoals wordt weergegeven in de volgende schermopname. Als u een door de gebruiker gedefinieerd herstelpunt hebt gemaakt, gebruikt u dit om de SQL-pool te herstellen. Anders kunt u het meest recente automatische herstelpunt selecteren.
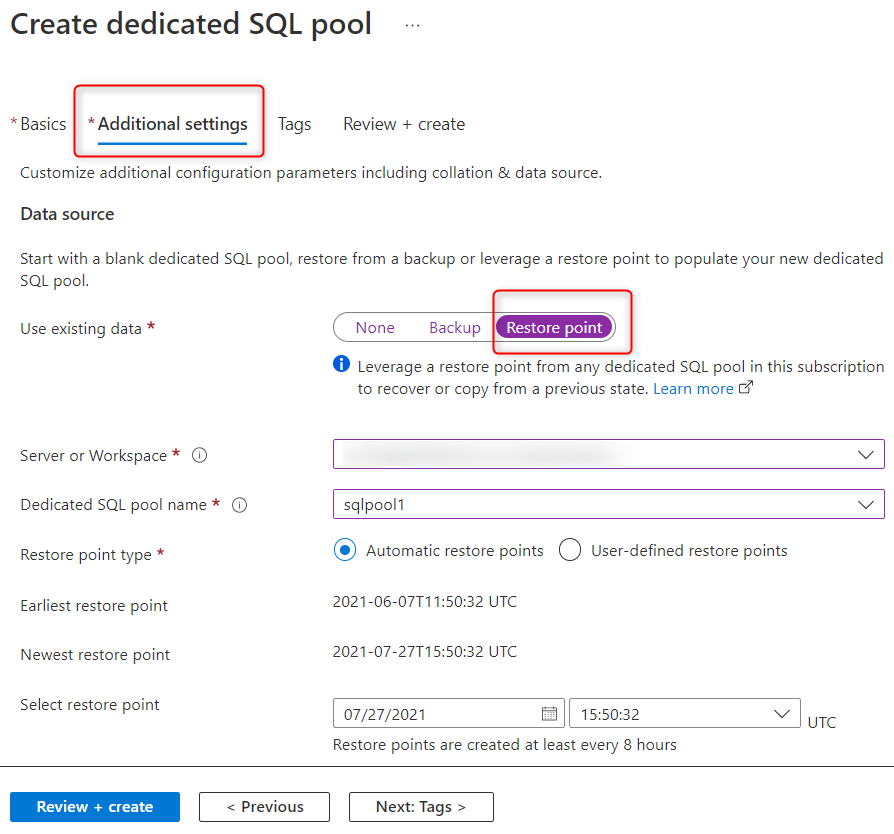
Azure PowerShell
Voer het volgende PowerShell-script uit om de werkruimte te herstellen. Dit script maakt gebruik van het meest recente herstelpunt van de toegewezen SQL-bronwerkruimtegroep om de SQL-pool in de doelwerkruimte te herstellen. Voordat u het script uitvoert, moet u het prestatieniveau van DW100c bijwerken naar de vereiste waarde.
Belangrijk
De naam van de toegewezen SQL-pool moet hetzelfde zijn voor beide werkruimten.
Haal de herstelpunten op:
$restorePoint=Get-AzSynapseSqlPoolRestorePoint -WorkspaceName $sourceRegionWSName -Name $sqlPoolName|Sort-Object -Property RestorePointCreationDate -Descending `
| SELECT RestorePointCreationDate -ExpandProperty RestorePointCreationDate -First 1
Transformeer de resource-id van de Azure Synapse SQL-pool naar de SQL-database-id, omdat de opdracht momenteel alleen de SQL-database-id accepteert.
Bijvoorbeeld: /subscriptions/<SubscriptionId>/resourceGroups/<ResourceGroupName>/providers/Microsoft.Sql/servers/<WorkspaceName>/databases/<DatabaseName>
$pool = Get-AzSynapseSqlPool -ResourceGroupName $sourceRegionRGName -WorkspaceName $sourceRegionWSName -Name $sqlPoolName
$databaseId = $pool.Id `
-replace "Microsoft.Synapse", "Microsoft.Sql" `
-replace "workspaces", "servers" `
-replace "sqlPools", "databases"
$restoredPool = Restore-AzSynapseSqlPool -FromRestorePoint `
-RestorePoint $restorePoint `
-TargetSqlPoolName $sqlPoolName `
-ResourceGroupName $resourceGroupName `
-WorkspaceName $workspaceName `
-ResourceId $databaseId `
-PerformanceLevel DW100c -AsJob
Hieronder wordt de status van de herstelbewerking bijgehouden:
Get-Job | Where-Object Command -In ("Restore-AzSynapseSqlPool") | `
Select-Object Id,Command,JobStateInfo,PSBeginTime,PSEndTime,PSJobTypeName,Error |Format-Table
Nadat de toegewezen SQL-pool is hersteld, maakt u alle SQL-aanmeldingen in Azure Synapse. Als u alle aanmeldingen wilt maken, volgt u de stappen in Aanmelden maken.
Stap 5: Een serverloze SQL-pool, Spark-pooldatabase en -objecten maken
U kunt geen back-ups maken van serverloze SQL-pooldatabases en Spark-pools. Als mogelijke tijdelijke oplossing kunt u het volgende doen:
- Maak notebooks en SQL-scripts, die de code hebben om alle vereiste Spark-pools, serverloze SQL-pooldatabases, tabellen, rollen en gebruikers opnieuw te maken met alle roltoewijzingen. Controleer deze artefacten naar Azure DevOps of GitHub.
- Als de naam van het opslagaccount is gewijzigd, controleert u of de codeartefacten verwijzen naar de juiste naam van het opslagaccount.
- Maak pijplijnen die deze codeartefacten in een specifieke volgorde aanroepen. Wanneer deze pijplijnen worden uitgevoerd in de werkruimte van de doelregio, worden de Spark SQL-databases, serverloze SQL-pooldatabases, externe gegevensbronnen, weergaven, rollen en gebruikers en machtigingen gemaakt in de werkruimte van de doelregio.
- Wanneer u de werkruimte van de bronregio integreert met Azure DevOps, maken deze codeartefacten deel uit van de opslagplaats. Later kunt u deze codeartefacten implementeren in de werkruimte van de doelregio met behulp van de DevOps Release-pijplijn, zoals vermeld in stap 6.
- Activeer deze pijplijnen handmatig in de werkruimte van de doelregio.
Stap 6: Artefacten en pijplijnen implementeren met behulp van CI/CD
Als u wilt weten hoe u een Azure Synapse-werkruimte integreert met Azure DevOps of GitHub en hoe u de artefacten implementeert in een werkruimte van een doelregio, volgt u de stappen in Ci/CD (Continue integratie en continue levering) voor een Azure Synapse-werkruimte.
Nadat de werkruimte is geïntegreerd met Azure DevOps, vindt u een vertakking met de naam workspace_publish. Deze vertakking bevat de werkruimtesjabloon die definities bevat voor de artefacten zoals Notebooks, SQL-scripts, Gegevenssets, Gekoppelde Services, Pijplijnen, Triggers en Spark-taakdefinitie.
In deze schermopname van de Azure DevOps-opslagplaats ziet u de werkruimtesjabloonbestanden voor de artefacten en andere onderdelen.
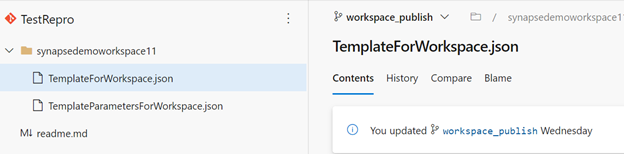
U kunt de werkruimtesjabloon gebruiken om artefacten en pijplijnen in een werkruimte te implementeren met behulp van de Azure DevOps-releasepijplijn.
Als de werkruimte niet is geïntegreerd met GitHub of Azure DevOps, moet u handmatig aangepaste PowerShell- of Azure CLI-scripts maken of schrijven om alle artefacten, pijplijnen, gekoppelde services, referenties, triggers en Spark-definities in de werkruimte van de doelregio te implementeren.
Notitie
Voor dit proces moet u de pijplijnen en codeartefacten bijwerken om eventuele wijzigingen in Spark- en serverloze SQL-pools, -objecten en -rollen in de werkruimten van de bronregio op te nemen.
Stap 7: Een gedeelde integratieruntime maken
Als u een SHIR wilt maken, volgt u de stappen in Een zelf-hostende Integration Runtime maken en configureren.
Stap 8: Een Azure-rol toewijzen aan beheerde identiteit
Wijs Storage Blob Contributor toegang toe aan de beheerde identiteit van de nieuwe werkruimte in het standaard gekoppelde Data Lake Storage Gen2-account. Wijs ook toegang toe aan andere opslagaccounts waarbij SA-MI wordt gebruikt voor verificatie. Wijs microsoft Entra-gebruikers en -groepen toe Storage Blob Contributor of Storage Blob Reader open ze voor alle vereiste opslagaccounts.
Azure Portal
Volg de stappen in Machtigingen verlenen aan de beheerde identiteit van de werkruimte om de rol Inzender voor opslagblobgegevens toe te wijzen aan de beheerde identiteit van de werkruimte.
Azure PowerShell
Wijs de rol Inzender voor opslagblobgegevens toe aan de beheerde identiteit van de werkruimte.
Inzender voor opslagblobgegevens toevoegen aan de beheerde identiteit van de werkruimte in het opslagaccount. De uitvoering van New-AzRoleAssignment fouten bij het bericht Exception of type 'Microsoft.Rest.Azure.CloudException' was thrown. , maar de vereiste machtigingen voor het opslagaccount worden gemaakt.
$workSpaceIdentityObjectID= (Get-AzSynapseWorkspace -ResourceGroupName $resourceGroupName -Name $workspaceName).Identity.PrincipalId
$scope = "/subscriptions/$($subscriptionId)/resourceGroups/$($resourceGroupName)/providers/Microsoft.Storage/storageAccounts/$($storageAccountName)"
$roleAssignedforManagedIdentity=New-AzRoleAssignment -ObjectId $workSpaceIdentityObjectID `
-RoleDefinitionName "Storage Blob Data Contributor" `
-Scope $scope -ErrorAction SilentlyContinue
Azure-CLI
Haal de rolnaam, resource-id en principal-id op voor de beheerde identiteit van de werkruimte en voeg vervolgens de Azure-rol Inzender voor opslagblobgegevens toe aan de SA-MI.
# Getting Role name
$roleName =az role definition list --query "[?contains(roleName, 'Storage Blob Data Contributor')].{roleName:roleName}" --output tsv
#Getting resource id for storage account
$scope= (az storage account show --name $storageAccountName|ConvertFrom-Json).id
#Getting principal ID for workspace managed identity
$workSpaceIdentityObjectID=(az synapse workspace show --name $workspaceName --resource-group $resourceGroupName|ConvertFrom-Json).Identity.PrincipalId
# Adding Storage Blob Data Contributor Azure role to SA-MI
az role assignment create --assignee $workSpaceIdentityObjectID `
--role $roleName `
--scope $scope
Stap 9: Azure Synapse RBAC-rollen toewijzen
Voeg alle gebruikers toe die toegang nodig hebben tot de doelwerkruimte met afzonderlijke rollen en machtigingen. Met het volgende PowerShell- en CLI-script wordt een Microsoft Entra-gebruiker toegevoegd aan de rol Synapse-beheerder in de werkruimte van de doelregio.
Zie Azure Synapse RBAC-rollen om alle azure Synapse RBAC-rollen op te halen.
Synapse Studio
Als u Azure Synapse RBAC-toewijzingen wilt toevoegen of verwijderen uit Synapse Studio, volgt u de stappen in Azure Synapse RBAC-roltoewijzingen beheren in Synapse Studio.
Azure PowerShell
Met het volgende PowerShell-script wordt de roltoewijzing Synapse-beheerder toegevoegd aan een Microsoft Entra-gebruiker of -groep. U kunt -RoleDefinitionId gebruiken in plaats van -RoleDefinitionName met de volgende opdracht om de gebruikers toe te voegen aan de werkruimte:
New-AzSynapseRoleAssignment `
-WorkspaceName $workspaceName `
-RoleDefinitionName "Synapse Administrator" `
-ObjectId aaaaaaaa-0000-1111-2222-bbbbbbbbbbbb
Get-AzSynapseRoleAssignment -WorkspaceName $workspaceName
Voer Get-AzSynapseRoleAssignment de opdracht uit om de ObjectIds en RoleIds op te halen in de werkruimte van de bronregio. Wijs dezelfde Azure Synapse RBAC-rollen toe aan de Microsoft Entra-gebruikers of -groepen in de werkruimte van de doelregio.
In plaats van als parameter te gebruiken -ObjectId , kunt u ook het -SignInNamee-mailadres of de user principal name van de gebruiker opgeven. Zie de Azure Synapse RBAC - PowerShell-cmdlet voor meer informatie over de beschikbare opties.
Azure-CLI
Haal de object-id van de gebruiker op en wijs de vereiste Azure Synapse RBAC-machtigingen toe aan de Microsoft Entra-gebruiker. U kunt het e-mailadres van de gebruiker (username@contoso.com) voor de --assignee parameter opgeven.
az synapse role assignment create `
--workspace-name $workspaceName `
--role "Synapse Administrator" --assignee adasdasdd42-0000-000-xxx-xxxxxxx
az synapse role assignment create `
--workspace-name $workspaceName `
--role "Synapse Contributor" --assignee "user1@contoso.com"
Zie Azure Synapse RBAC - CLI voor meer informatie over beschikbare opties.
Stap 10: Werkruimtepakketten uploaden
Upload alle vereiste werkruimtepakketten naar de nieuwe werkruimte. Als u het proces voor het uploaden van de werkruimtepakketten wilt automatiseren, raadpleegt u de clientbibliotheek van Microsoft Azure Synapse Analytics Artifacts.
Stap 11: Machtigingen
Als u het toegangsbeheer voor de Azure Synapse-werkruimte van de doelregio wilt instellen, volgt u de stappen in Het instellen van toegangsbeheer voor uw Azure Synapse-werkruimte.
Stap 12: beheerde privé-eindpunten maken
Als u de beheerde privé-eindpunten opnieuw wilt maken vanuit de werkruimte van de bronregio in uw doelregiowerkruimte, raadpleegt u Een beheerd privé-eindpunt maken voor uw gegevensbron.
Verwijderen
Als u de werkruimte van de doelregio wilt verwijderen, verwijdert u de werkruimte van de doelregio. Hiervoor gaat u naar de resourcegroep vanuit uw dashboard in de portal en selecteert u de werkruimte en selecteert u Verwijderen boven aan de pagina Resourcegroep.
Opschonen
Als u de wijzigingen wilt doorvoeren en de verplaatsing van de werkruimte wilt voltooien, verwijdert u de werkruimte van de bronregio nadat u de werkruimte in de doelregio hebt getest. Hiervoor gaat u naar de resourcegroep met de werkruimte van de bronregio in uw dashboard in de portal en selecteert u de werkruimte en selecteert u Verwijderen boven aan de pagina Resourcegroep.
Volgende stappen
- Meer informatie over door Azure Synapse beheerde virtuele netwerken.
- Meer informatie over door Azure Synapse beheerde privé-eindpunten.
- Meer informatie over het maken van verbinding met werkruimteresources vanuit een beperkt netwerk.