Technisch document over azure Synapse Analytics-beveiliging: Inleiding
Samenvatting: Azure Synapse Analytics is een onbeperkt analyseplatform van Microsoft dat zakelijke datawarehousing en big data-verwerking integreert in één beheerde omgeving zonder systeemintegratie. Azure Synapse biedt de end-to-end-hulpprogramma's voor uw analytische levenscyclus met:
- Pijplijnen voor gegevensintegratie.
- Apache Spark-pool voor verwerking van big data.
- Data Explorer voor logboek- en tijdreeksanalyse.
- Serverloze SQL-pool voor gegevensverkenning via Azure Data Lake.
- Toegewezen SQL-pool (voorheen SQL DW) voor datawarehousing voor ondernemingen.
- Uitgebreide integratie met Power BI, Azure Cosmos DB en Azure Machine Learning.
Azure Synapse-gegevensbeveiliging en -privacy zijn niet onderhandelbaar. Het doel van dit witboek is om een uitgebreid overzicht te bieden van Azure Synapse-beveiligingsfuncties, die op bedrijfsniveau en toonaangevende functies zijn. Het witboek bestaat uit een reeks artikelen die betrekking hebben op de volgende vijf beveiligingslagen:
- Gegevensbescherming
- Toegangsbeheer
- Verificatie
- Netwerkbeveiliging
- Bedreigingsbeveiliging
Dit witboek is gericht op alle belanghebbenden voor bedrijfsbeveiliging. Ze omvatten beveiligingsbeheerders, netwerkbeheer, Azure-beheerders, werkruimtebeheerders en databasebeheerders.
Schrijvers: Vengatesh Parasuraman, Fretz Nuson, Ron Dunn, Khendr'a Reid, John Hoang, Nithesh Krishnappa, Myppa Kovalenko, Brad Schacht, Pedro Martinez, Mark Pryce-Maher en Arshad Ali.
Technische revisoren: Nandita Valsan, Rony Thomas, Abhishek Narain, Daniel Daniël en Tammy Richter Jones.
Van toepassing op: Azure Synapse Analytics, toegewezen SQL-pool (voorheen SQL DW), serverloze SQL-pool en Apache Spark-pool.
Belangrijk
Dit witboek is niet van toepassing op Azure SQL Database, Azure SQL Managed Instance, Azure Machine Learning of Azure Databricks.
Inleiding
Frequente koppen over gegevensschendingen, malware-infecties en schadelijke code-injectie behoren tot een uitgebreide lijst met beveiligingsproblemen voor bedrijven die op zoek zijn naar modernisering van de cloud. Zakelijke klanten hebben een cloudprovider of serviceoplossing nodig die hun zorgen kan wegnemen, omdat ze het zich niet kunnen veroorloven om in de fout te gaan.
Enkele veelvoorkomende beveiligingsvragen zijn onder meer:
- Hoe kan ik bepalen wie welke gegevens kan zien?
- Wat zijn de opties voor het verifiëren van de identiteit van een gebruiker?
- Hoe worden mijn gegevens beveiligd?
- Welke netwerkbeveiligingstechnologie kan ik gebruiken om de integriteit, vertrouwelijkheid en toegang tot mijn netwerken en gegevens te beschermen?
- Wat zijn de hulpprogramma's die bedreigingen detecteren en mij op de hoogte stellen van bedreigingen?
Het doel van dit witboek is het geven van antwoorden op deze algemene beveiligingsvragen en vele andere.
Architectuur van onderdelen
Azure Synapse is een PaaS-analyseservice (Platform-as-a-Service) die meerdere onafhankelijke onderdelen samenbrengt, zoals toegewezen SQL-pools, serverloze SQL-pools, Apache Spark-pools en pijplijnen voor gegevensintegratie. Deze onderdelen zijn ontworpen om samen te werken om een naadloze analytische platformervaring te bieden.
Toegewezen SQL-pools zijn ingerichte clusters die enterprise datawarehousingmogelijkheden bieden voor SQL-workloads. Gegevens worden opgenomen in beheerde opslag, mogelijk gemaakt door Azure Storage. Dit is ook een PaaS-service. Compute is geïsoleerd van opslag, zodat klanten de rekenkracht onafhankelijk van hun gegevens kunnen schalen. Toegewezen SQL-pools bieden ook de mogelijkheid om rechtstreeks query's uit te voeren op gegevensbestanden via door de klant beheerde Azure Storage-accounts met behulp van externe tabellen.
Serverloze SQL-pools zijn clusters op aanvraag die een SQL-interface bieden voor het rechtstreeks opvragen en analyseren van gegevens via door de klant beheerde Azure Storage-accounts. Omdat ze serverloos zijn, is er geen beheerde opslag en worden de rekenknooppunten automatisch geschaald als reactie op de queryworkload.
Apache Spark in Azure Synapse is een van de implementaties van Microsoft van opensource Apache Spark in de cloud. Spark-exemplaren worden op aanvraag ingericht op basis van de metagegevensconfiguraties die zijn gedefinieerd in de Spark-pools. Elke gebruiker krijgt een eigen toegewezen Spark-exemplaar voor het uitvoeren van hun taken. De gegevensbestanden die door de Spark-exemplaren worden verwerkt, worden beheerd door de klant in hun eigen Azure Storage-accounts.
Pijplijnen zijn een logische groepering van activiteiten die gegevensverplaatsing en gegevenstransformatie op schaal uitvoeren. Gegevensstroom is een transformatieactiviteit in een pijplijn die is ontwikkeld met behulp van een gebruikersinterface met weinig code. Hiermee kunnen gegevenstransformaties op schaal worden uitgevoerd. Achter de schermen maken gegevensstromen gebruik van Apache Spark-clusters van Azure Synapse om automatisch gegenereerde code uit te voeren. Pijplijnen en gegevensstromen zijn alleen-rekenservices en er zijn geen beheerde opslag aan gekoppeld.
Pijplijnen gebruiken de Integration Runtime (IR) als de schaalbare rekeninfrastructuur voor het uitvoeren van gegevensverplaatsing en verzendingsactiviteiten. Activiteiten voor gegevensverplaatsing worden uitgevoerd op de IR, terwijl de verzendactiviteiten worden uitgevoerd op verschillende andere rekenprogramma's, waaronder Azure SQL Database, Azure HDInsight, Azure Databricks, Apache Spark-clusters van Azure Synapse en andere. Azure Synapse ondersteunt twee typen IR: Azure Integration Runtime en zelf-hostende Integration Runtime. De Azure IR biedt een volledig beheerde, schaalbare en on-demand rekeninfrastructuur. De zelf-hostende IR wordt geïnstalleerd en geconfigureerd door de klant in hun eigen netwerk, in on-premises machines of in virtuele Azure-cloudmachines.
Klanten kunnen ervoor kiezen om hun Synapse-werkruimte te koppelen aan een virtueel netwerk van een beheerde werkruimte. Wanneer deze zijn gekoppeld aan een virtueel netwerk van een beheerde werkruimte, worden Azure IR's en Apache Spark-clusters die worden gebruikt door pijplijnen, gegevensstromen en de Apache Spark-pools geïmplementeerd in het virtuele netwerk van de beheerde werkruimte. Deze installatie zorgt voor netwerkisolatie tussen de werkruimten voor pijplijnen en Apache Spark-workloads.
In het volgende diagram ziet u de verschillende onderdelen van Azure Synapse.
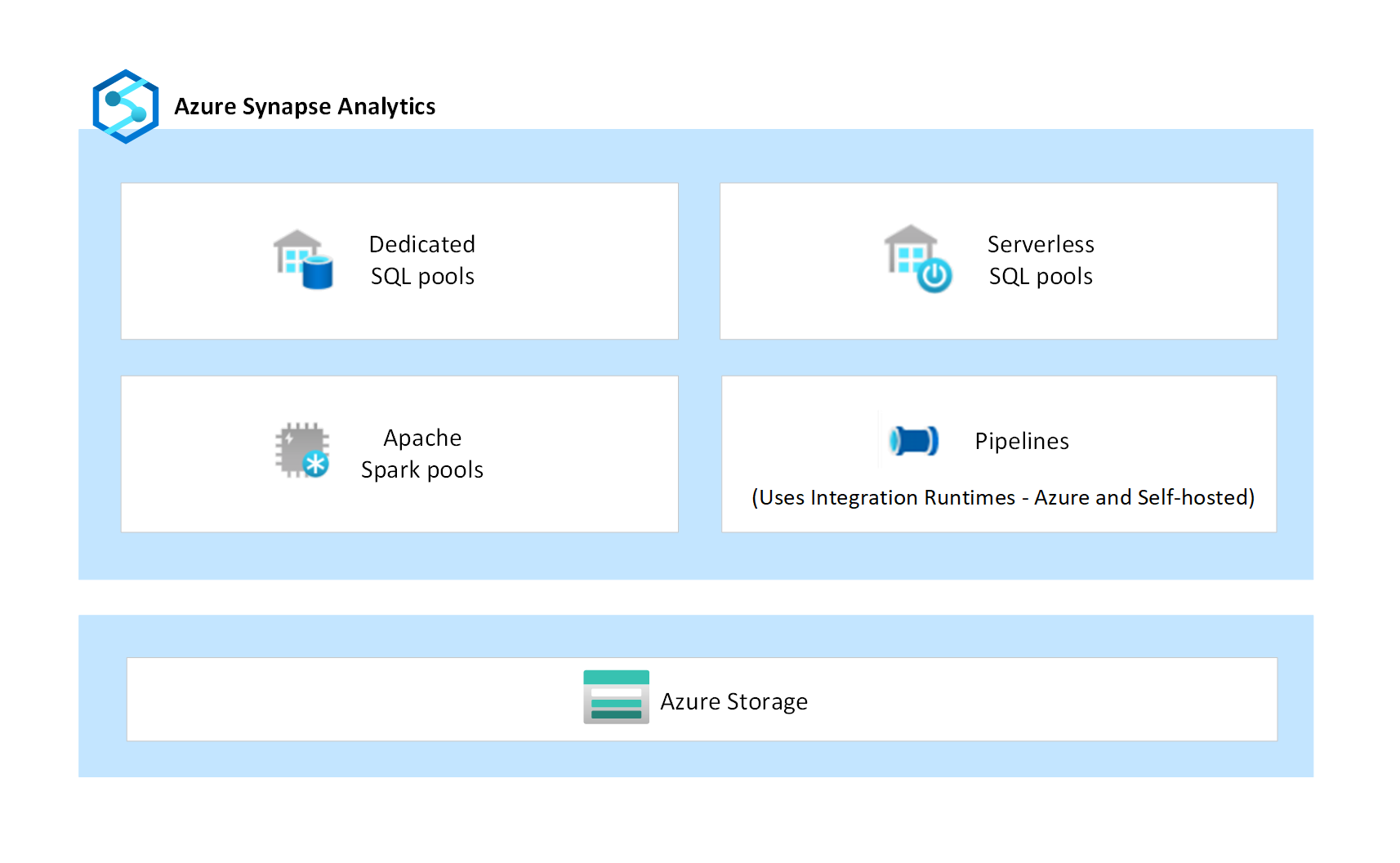
Isolatie van onderdelen
Elk afzonderlijk onderdeel van Azure Synapse dat in het diagram wordt weergegeven, biedt zijn eigen beveiligingsfuncties. Beveiligingsfuncties bieden gegevensbeveiliging, toegangsbeheer, verificatie, netwerkbeveiliging en bedreigingsbeveiliging voor het beveiligen van de berekening en de bijbehorende gegevens die worden verwerkt. Daarnaast biedt Azure Storage, een PaaS-service, extra beveiliging, die wordt ingesteld en beheerd door de klant in hun eigen opslagaccounts. Dit niveau van isolatielimieten voor onderdelen en minimaliseert de blootstelling als er een beveiligingsprobleem is op een van de onderdelen.
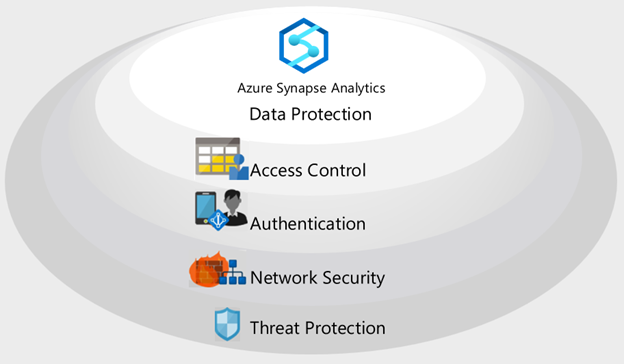
Beveiligingslagen
Azure Synapse implementeert een beveiligingsarchitectuur met meerdere lagen voor end-to-end-beveiliging van uw gegevens. Er zijn vijf lagen:
- Gegevensbescherming om gevoelige gegevens te identificeren en te classificeren, en data-at-rest en in beweging te versleutelen.
- Toegangsbeheer om het recht van een gebruiker te bepalen om met gegevens te communiceren.
- Verificatie om de identiteit van gebruikers en toepassingen te bewijzen.
- Netwerkbeveiliging om netwerkverkeer te isoleren met privé-eindpunten en virtuele particuliere netwerken.
- Beveiliging tegen bedreigingen om mogelijke beveiligingsrisico's te identificeren, zoals ongebruikelijke toegangslocaties, SQL-injectieaanvallen, verificatieaanvallen en meer.
Volgende stappen
In het volgende artikel in deze reeks technische documenten leert u meer over gegevensbescherming.