Prestaties van bestandsshares optimaliseren bij het openen van grote mappen vanaf Linux-clients
Dit artikel bevat aanbevelingen voor het werken met mappen die grote aantallen bestanden bevatten. Het is meestal een goede gewoonte om het aantal bestanden in één map te verminderen door de bestanden over meerdere mappen te spreiden. Er zijn echter situaties waarin grote mappen niet kunnen worden vermeden. Houd rekening met de volgende suggesties bij het werken met grote mappen op Azure-bestandsshares die zijn gekoppeld op Linux-clients.
Van toepassing op
| Bestands sharetype | SMB | NFS |
|---|---|---|
| Standaardbestandsshares (GPv2), LRS/ZRS |
|
|
| Standaardbestandsshares (GPv2), GRS/GZRS |
|
|
| Premium bestandsshares (FileStorage), LRS/ZRS |
|
|
Aanbevolen koppelingsopties
De volgende koppelingsopties zijn specifiek voor opsomming en kunnen latentie verminderen bij het werken met grote mappen.
actimeo
actimeo Als u alle acregmin, acregmaxen acdirmindezelfde waarde opgeeft, wordt acdirmax ingesteld. Als actimeo dit niet is opgegeven, gebruikt de client de standaardwaarden voor elk van deze opties.
U wordt aangeraden tussen 30 en 60 seconden in te stellen actimeo bij het werken met grote mappen. Als u een waarde in dit bereik instelt, blijven de kenmerken langer geldig in de kenmerkcache van de client, zodat bewerkingen bestandskenmerken uit de cache kunnen ophalen in plaats van ze via de kabel op te halen. Dit kan de latentie verminderen in situaties waarin de kenmerken in de cache verlopen terwijl de bewerking nog steeds wordt uitgevoerd.
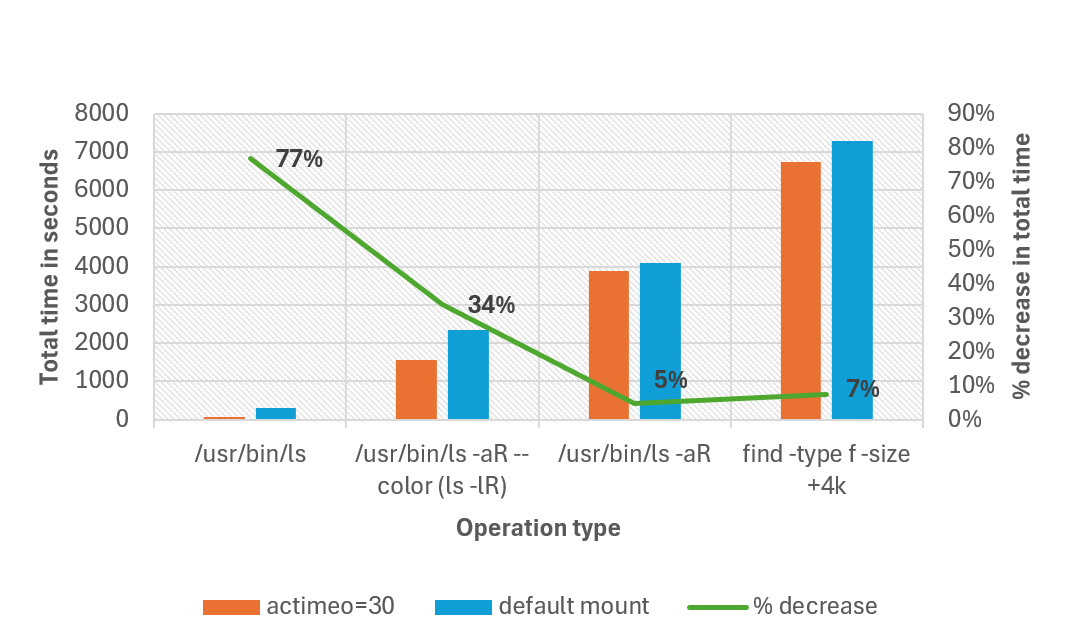
In de volgende grafiek wordt de totale tijd vergeleken die nodig is voor het voltooien van verschillende bewerkingen met standaardkoppeling en het instellen van een actimeo waarde van 30 voor een workload met 1 miljoen bestanden in één map. In onze testtijd is de totale voltooiingstijd voor sommige bewerkingen met maar liefst 77% verminderd. Alle bewerkingen werden uitgevoerd met niet-gealiaseerde ls.
nconnect
Nconnect is een koppelingsoptie aan de clientzijde voor NFS-bestandsshares waarmee u meerdere TCP-verbindingen tussen de client en de Azure Premium Files-service voor NFSv4.1 kunt gebruiken. We raden de optimale instelling aan nconnect=4 om de latentie te verminderen en de prestaties te verbeteren.
Nconnect kan met name handig zijn voor workloads die asynchrone of synchrone I/O van meerdere threads gebruiken.
Meer informatie.
Het aantal hash-buckets verhogen
De totale hoeveelheid RAM die aanwezig is op het systeem dat de inventarisatie uitvoert, beïnvloedt de interne werking van bestandssysteemprotocollen zoals NFS en SMB. Zelfs als gebruikers geen hoog geheugengebruik ondervinden, heeft de beschikbare hoeveelheid geheugen invloed op het aantal inode-hash-buckets dat het systeem heeft, wat invloed heeft op/verbetert de inventarisatieprestaties voor grote mappen. U kunt het aantal inode-hash-buckets wijzigen dat het systeem nodig heeft om de hashconflicten te verminderen die kunnen optreden tijdens grote inventarisatieworkloads.
Hiervoor moet u de instellingen voor de opstartconfiguratie wijzigen door een extra kernelopdracht op te geven die van kracht wordt tijdens het opstarten om het aantal inode-hash-buckets te verhogen. Volg deze stappen.
Bewerk het
/etc/default/grubbestand met behulp van een teksteditor.sudo vim /etc/default/grubVoeg de volgende tekst toe aan het bestand
/etc/default/grub. Met deze opdracht wordt 128 MB uitgezet als de grootte van de inode-hashtabel, waardoor het geheugenverbruik van het systeem met maximaal 128 MB wordt verhoogd.GRUB_CMDLINE_LINUX="ihash_entries=16777216"Als
GRUB_CMDLINE_LINUXdit al bestaat, voegtihash_entries=16777216u deze toe gescheiden door een spatie, zoals deze:GRUB_CMDLINE_LINUX="<previous commands> ihash_entries=16777216"Voer de volgende opdracht uit om de wijzigingen toe te passen:
sudo update-grub2Start het systeem opnieuw op:
sudo rebootAls u wilt controleren of de wijzigingen van kracht zijn, controleert u de cmdline-opdrachten van de kernel nadat het systeem opnieuw is opgestart:
cat /proc/cmdlineAls
ihash_entriesdit zichtbaar is, heeft het systeem de instelling toegepast en moeten de inventarisatieprestaties exponentieel worden verbeterd.U kunt ook de dmesg-uitvoer controleren om te zien of de kernel-cmdline is toegepast:
dmesg | grep "Inode-cache hash table" Inode-cache hash table entries: 16777216 (order: 15, 134217728 bytes, linear)
Opdrachten en bewerkingen
De manier waarop opdrachten en bewerkingen worden opgegeven, kan ook van invloed zijn op de prestaties. Het is een goed voorbeeld van het weergeven van alle bestanden in een grote map met behulp van de ls opdracht.
Notitie
Sommige bewerkingen, zoals recursief ls, finden du hebben zowel bestandsnamen als bestandskenmerken nodig, zodat ze directory-opsommingen (om de vermeldingen op te halen) combineren met een statistiek voor elke vermelding (om de kenmerken op te halen). We raden u aan om een hogere waarde voor actimeo te gebruiken op koppelpunten waar u dergelijke opdrachten waarschijnlijk uitvoert.
Niet-gealiaseerde ls gebruiken
In sommige Linux-distributies stelt de shell automatisch standaardopties in voor de ls opdracht, zoals ls --color=auto. Hierdoor wordt de werking ls van de kabel gewijzigd en worden er meer bewerkingen toegevoegd aan de ls uitvoering. Om prestatievermindering te voorkomen, raden we aan om niet-gealiaseerde ls te gebruiken. U kunt dit op drie manieren doen:
Verwijder de alias met behulp van de opdracht
unalias ls. Dit is slechts een tijdelijke oplossing voor de huidige sessie.Voor een permanente wijziging kunt u de
lsalias bewerken in het bestand vanbashrc/bash_aliasesde gebruiker. Bewerk~/.bashrcin Ubuntu om de alias voorlste verwijderen.In plaats van aanroepen
lskunt u bijvoorbeeld hetlsbinaire bestand/usr/bin/lsrechtstreeks aanroepen. Hiermee kunt u zonder opties die zich in de alias bevinden, gebruikenls. U kunt de locatie van het binaire bestand vinden door de opdrachtwhich lsuit te voeren.
Voorkomen dat ls de uitvoer sorteert
ls Wanneer u met andere opdrachten gebruikt, kunt u de prestaties verbeteren door te voorkomen dat ls de uitvoer wordt gesorteerd in situaties waarin u niet om de volgorde geeft die ls de bestanden retourneert. Het sorteren van de uitvoer zorgt voor aanzienlijke overhead.
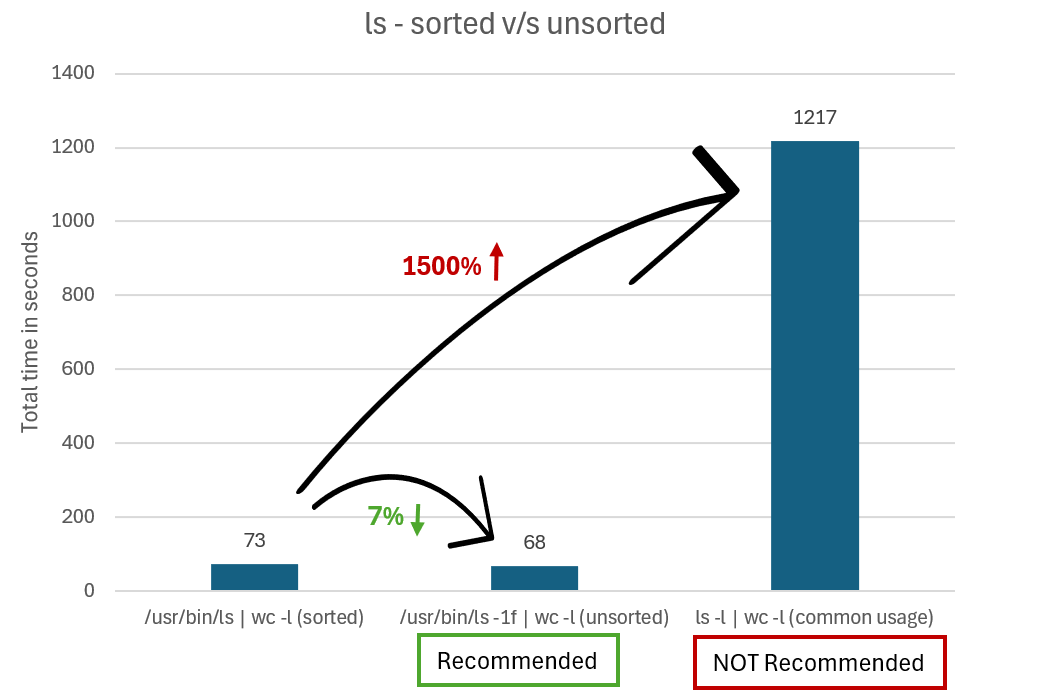
In plaats van het ls -l | wc -l totale aantal bestanden op te halen, kunt u de -f of -U opties ls gebruiken om te voorkomen dat de uitvoer wordt gesorteerd. Het verschil is dat -f ook verborgen bestanden worden weergegeven en -U niet.
Als u bijvoorbeeld het ls binaire bestand rechtstreeks aanroept in Ubuntu, voert u deze uit /usr/bin/ls -1f | wc -l of /usr/bin/ls -1U | wc -l.
In de volgende grafiek wordt de tijd vergeleken die nodig is om resultaten uit te voeren met behulp van niet-gealiaseerde, niet-gesorteerde ls versus gesorteerde lsresultaten.
Bestandskopie- en back-upbewerkingen
Wanneer u gegevens kopieert van een bestandsshare of een back-up maakt van bestandsshares naar een andere locatie, raden we u aan een momentopname van een share te gebruiken als de bron in plaats van de live-bestandsshare met actieve I/O. Back-uptoepassingen moeten opdrachten rechtstreeks op de momentopname uitvoeren. Zie Momentopnamen van shares gebruiken met Azure Files voor meer informatie.
Aanbevelingen op toepassingsniveau
Volg deze aanbevelingen bij het ontwikkelen van toepassingen die gebruikmaken van grote mappen.
Sla bestandskenmerken over. Als de toepassing alleen de bestandsnaam en niet bestandskenmerken nodig heeft, zoals bestandstype of de laatste wijzigingstijd, kunt u meerdere aanroepen naar systeemoproepen gebruiken, zoals
getdents64met een goede buffergrootte. Hierdoor worden de vermeldingen in de opgegeven map zonder het bestandstype weergegeven, waardoor de bewerking sneller wordt uitgevoerd door extra bewerkingen te voorkomen die niet nodig zijn.Interleave stat-aanroepen. Als de toepassing kenmerken en de bestandsnaam nodig heeft, raden we u aan om de aanroepen van stat samen te
getdents64schakelen in plaats van alle vermeldingen op te halen tot het einde van het bestand engetdents64vervolgens een statistiek uit te voeren op alle geretourneerde vermeldingen. Als u de stat-aanroepen interleaseert, wordt de client geïnstrueerd om zowel het bestand als de bijbehorende kenmerken tegelijk aan te vragen, waardoor het aantal aanroepen naar de server wordt verminderd. In combinatie met een hogeactimeowaarde kan dit de prestaties aanzienlijk verbeteren. Plaats bijvoorbeeld in plaats van[ getdents64, getdents64, ... , getdents64, statx (entry1), ... , statx(n) ]de statx-aanroepen na elkgetdents64van deze aanroepen:[ getdents64, (statx, statx, ... , statx), getdents64, (statx, statx, ... , statx), ... ].I/O-diepte vergroten. Indien mogelijk raden we u aan om te
nconnectconfigureren naar een niet-nulwaarde (groter dan 1) en de bewerking over meerdere threads te distribueren of om asynchrone I/O te gebruiken. Hierdoor kunnen bewerkingen die asynchroon kunnen zijn, profiteren van meerdere gelijktijdige verbindingen met de bestandsshare.Cache voor geforceerd gebruik. Als de toepassing een query uitvoert op de bestandskenmerken op een bestandsshare die slechts één client heeft gekoppeld, gebruikt u de aanroep van het statx-systeem met de
AT_STATX_DONT_SYNCvlag. Deze vlag zorgt ervoor dat de kenmerken in de cache worden opgehaald uit de cache zonder te synchroniseren met de server, waardoor er geen extra retouren van het netwerk worden gemaakt om de meest recente gegevens op te halen.