Hoe door de klant beheerde geplande failover (preview) werkt
Door de klant beheerde geplande failover kan nuttig zijn in scenario's zoals nood- en herstelplanning en -tests, proactief herstel van verwachte grootschalige rampen en niet-opslaggerelateerde storingen.
Tijdens het geplande failoverproces worden de primaire en secundaire regio's van uw opslagaccount gewisseld. De oorspronkelijke primaire regio wordt gedegradeerd en wordt de nieuwe secundaire terwijl de oorspronkelijke secundaire regio wordt gepromoveerd en de nieuwe primaire regio wordt. Het opslagaccount moet beschikbaar zijn in zowel de primaire als de secundaire regio's voordat een geplande failover kan worden gestart.
In dit artikel wordt beschreven wat er gebeurt tijdens een door de klant beheerde geplande failover en failback in elke fase van het proces. Als u wilt weten hoe een failover vanwege een onverwachte storing van het opslageindpunt werkt, raadpleegt u Hoe door de klant beheerde (niet-geplande) failover.
Belangrijk
Door de klant beheerde geplande failover is momenteel in PREVIEW en beperkt tot de volgende regio's:
- Frankrijk - centraal
- Frankrijk - zuid
- India - centraal
- India - west
- Azië - oost
- Azië - zuidoost
Zie Preview-functies instellen in het Azure-abonnement en AllowSoftFailover opgeven als de naam van de functie als u zich wilt aanmelden voor de preview. De providernaam voor deze preview-functie is Microsoft.Storage.
Raadpleeg de Aanvullende voorwaarden voor Microsoft Azure-previews voor juridische voorwaarden die van toepassing zijn op Azure-functies die in bèta of preview zijn of die anders nog niet algemeen beschikbaar zijn.
Belangrijk
Na een geplande failover kan de LST-waarde (Last Sync Time) van een opslagaccount verlopen zijn of als NULL worden gerapporteerd wanneer Azure Files-gegevens aanwezig zijn.
Systeemmomentopnamen worden periodiek gemaakt in de secundaire regio van een opslagaccount om consistente herstelpunten te onderhouden die worden gebruikt tijdens een failover en failback. Het initiëren van door de klant beheerde geplande failover zorgt ervoor dat de oorspronkelijke primaire regio de nieuwe secundaire regio wordt. In sommige gevallen zijn er geen systeemmomentopnamen beschikbaar op de nieuwe secundaire nadat de geplande failover is voltooid, waardoor de totale LST-waarde van het account verouderd wordt weergegeven of als wordt weergegeven Null.
Omdat gebruikersactiviteiten zoals het maken, wijzigen of verwijderen van objecten het maken van momentopnamen kunnen activeren, heeft elk account waarop deze activiteiten plaatsvinden na geplande failover geen extra aandacht nodig. Accounts zonder momentopnamen of gebruikersactiviteit kunnen echter een Null LST-waarde blijven weergeven totdat het maken van een systeemmomentopname wordt geactiveerd.
Voer zo nodig een van de volgende activiteiten uit voor elke share in een opslagaccount om het maken van momentopnamen te activeren. Na voltooiing moet uw account binnen 30 minuten een geldige LST-waarde weergeven.
- Koppel de share en open vervolgens een bestand om te lezen.
- Upload een test- of voorbeeldbestand naar de share.
Redundantiebeheer tijdens geplande failover en failback
Tip
Zie Azure Storage-redundantie voor definities van elk voor meer informatie over de verschillende redundantiestatussen tijdens het door de klant beheerde failover- en failbackproces.
Tijdens het geplande failoverproces worden de eindpunten van de opslagservice van de primaire regio alleen-lezen terwijl de resterende updates worden gerepliceerd naar de secundaire regio. Vervolgens worden alle DNS-vermeldingen (Domain Name Service) van het opslagservice-eindpunt overgeschakeld. De secundaire eindpunten van uw opslagaccount worden de nieuwe primaire eindpunten en de oorspronkelijke primaire eindpunten worden de nieuwe secundaire. Gegevensreplicatie binnen elke regio blijft ongewijzigd, ook al worden de primaire en secundaire regio's overgeschakeld.
Het geplande failbackproces is in feite hetzelfde als het geplande failoverproces, maar met één uitzondering. Tijdens geplande failback slaat Azure de oorspronkelijke redundantieconfiguratie van uw opslagaccount op en herstelt deze naar de oorspronkelijke status na failback. Als uw opslagaccount bijvoorbeeld oorspronkelijk is geconfigureerd als GZRS, wordt het opslagaccount GZRS na failback.
Notitie
In tegenstelling tot door de klant beheerde (niet-geplande) failover, moet de replicatie van de primaire naar de secundaire regio worden voltooid voordat de DNS-vermeldingen voor de eindpunten worden gewijzigd in de nieuwe secundaire. Daarom wordt gegevensverlies niet verwacht tijdens geplande failover of failback, zolang zowel de primaire als de secundaire regio's tijdens het proces beschikbaar zijn.
Een failover initiëren
Zie Een accountfailover initiëren voor meer informatie over het initiëren van een failover.
Het geplande failover- en failbackproces
In de volgende diagrammen ziet u wat er gebeurt tijdens een door de klant beheerde geplande failover en failback van een opslagaccount.
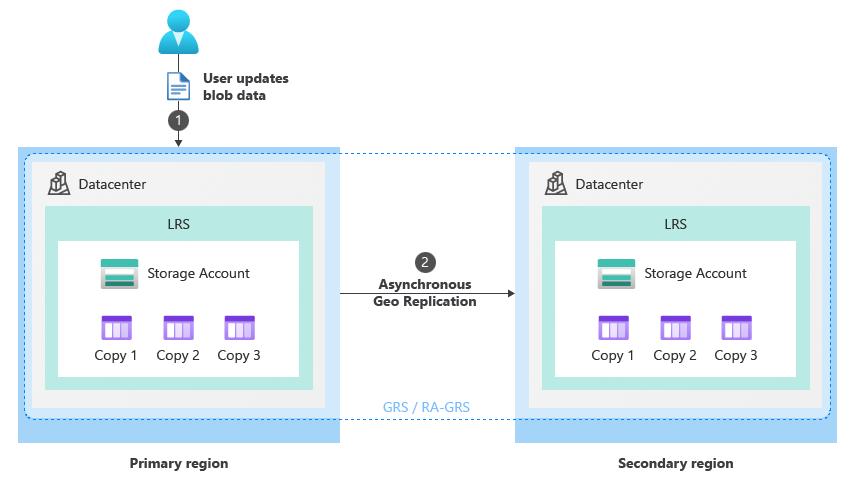
In normale omstandigheden schrijft een client gegevens naar een opslagaccount in de primaire regio via opslagservice-eindpunten (1). De gegevens worden vervolgens asynchroon gekopieerd van de primaire regio naar de secundaire regio (2). In de volgende afbeelding ziet u de normale status van een opslagaccount dat is geconfigureerd als GRS:

Het geplande failoverproces (GRS/RA-GRS)
Begin met het testen van herstel na noodgevallen door een failover van uw opslagaccount naar de secundaire regio te starten. In de volgende stappen wordt het failoverproces beschreven en in de volgende afbeelding ziet u een afbeelding:
- De oorspronkelijke primaire regio wordt alleen-lezen.
- Replicatie van alle gegevens van de primaire regio naar de secundaire regio is voltooid.
- DNS-vermeldingen voor opslagservice-eindpunten in de secundaire regio worden gepromoveerd en worden de nieuwe primaire eindpunten voor uw opslagaccount.
De failover duurt doorgaans ongeveer een uur.

Nadat de failover is voltooid, wordt de oorspronkelijke primaire regio de nieuwe secundaire (1) en wordt de oorspronkelijke secundaire regio de nieuwe primaire regio (2). De URI's voor de opslagservice-eindpunten voor blobs, tabellen, wachtrijen en bestanden blijven hetzelfde, maar hun DNS-vermeldingen worden gewijzigd zodat deze verwijzen naar de nieuwe primaire regio (3). Gebruikers kunnen doorgaan met het schrijven van gegevens naar het opslagaccount in de nieuwe primaire regio en de gegevens worden vervolgens asynchroon gekopieerd naar de nieuwe secundaire (4), zoals wordt weergegeven in de volgende afbeelding:

Voer tijdens de failoverstatus uw herstel na noodgevallen uit.
Het geplande failbackproces (GRS/RA-GRS)
Nadat het testen is voltooid, voert u een andere failover uit naar de failback naar de oorspronkelijke primaire regio. Tijdens het failoverproces, zoals wordt weergegeven in de volgende afbeelding:
- De oorspronkelijke primaire regio wordt alleen-lezen.
- Alle gegevens worden gerepliceerd van de huidige primaire regio naar de huidige secundaire regio.
- De DNS-vermeldingen voor de eindpunten van de opslagservice worden gewijzigd om terug te verwijzen naar de regio die de primaire was voordat de eerste failover werd uitgevoerd.
De failback duurt doorgaans ongeveer een uur.

Nadat de failback is voltooid, wordt het opslagaccount hersteld naar de oorspronkelijke redundantieconfiguratie. Gebruikers kunnen het schrijven van gegevens naar het opslagaccount in de oorspronkelijke primaire regio (1) hervatten terwijl de replicatie naar de oorspronkelijke secundaire (2) wordt voortgezet zoals vóór de failover: