Migreren van on-premises HDFS-archief naar Azure Storage met Azure Data Box
U kunt gegevens migreren vanuit een on-premises HDFS-archief van uw Hadoop-cluster naar Azure Storage (blobopslag of Data Lake Storage) met behulp van een Data Box-apparaat. U kunt kiezen uit Data Box Disk, een Data Box van 80 TB of een Data Box Heavy van 770 TB.
Dit artikel helpt u bij het voltooien van deze taken:
- Voorbereiden om uw gegevens te migreren
- Uw gegevens kopiëren naar een Data Box Disk-, Data Box- of Data Box Heavy-apparaat
- Het apparaat terugsturen naar Microsoft
- Toegangsmachtigingen toepassen op bestanden en mappen (alleen Data Lake Storage)
Vereisten
U hebt deze dingen nodig om de migratie te voltooien.
Een Azure Storage-account.
Een on-premises Hadoop-cluster dat uw brongegevens bevat.
-
Sluit uw Data Box of Data Box Heavy aan op een on-premises netwerk.
Als u klaar bent, gaan we beginnen.
Uw gegevens kopiëren naar een Data Box-apparaat
Als uw gegevens in één Data Box-apparaat passen, kopieert u de gegevens naar het Data Box-apparaat.
Als uw gegevens groter zijn dan de capaciteit van het Data Box-apparaat, gebruikt u de optionele procedure om de gegevens te splitsen over meerdere Data Box-apparaten en voert u deze stap uit.
Als u de gegevens uit uw on-premises HDFS-archief wilt kopiëren naar een Data Box-apparaat, stelt u een paar dingen in en gebruikt u vervolgens het hulpprogramma DistCp .
Volg deze stappen om gegevens te kopiëren via de REST API's van Blob/Object Storage naar uw Data Box-apparaat. De REST API-interface zorgt ervoor dat het apparaat wordt weergegeven als een HDFS-archief in uw cluster.
Voordat u de gegevens kopieert via REST, moet u de beveiligings- en verbindingsprimitief identificeren om verbinding te maken met de REST-interface op de Data Box of Data Box Heavy. Meld u aan bij de lokale webgebruikersinterface van Data Box en ga naar de pagina Verbinding maken en kopiëren . Zoek en selecteer REST op basis van de Azure-opslagaccounts voor uw apparaat, zoek en selecteer REST.
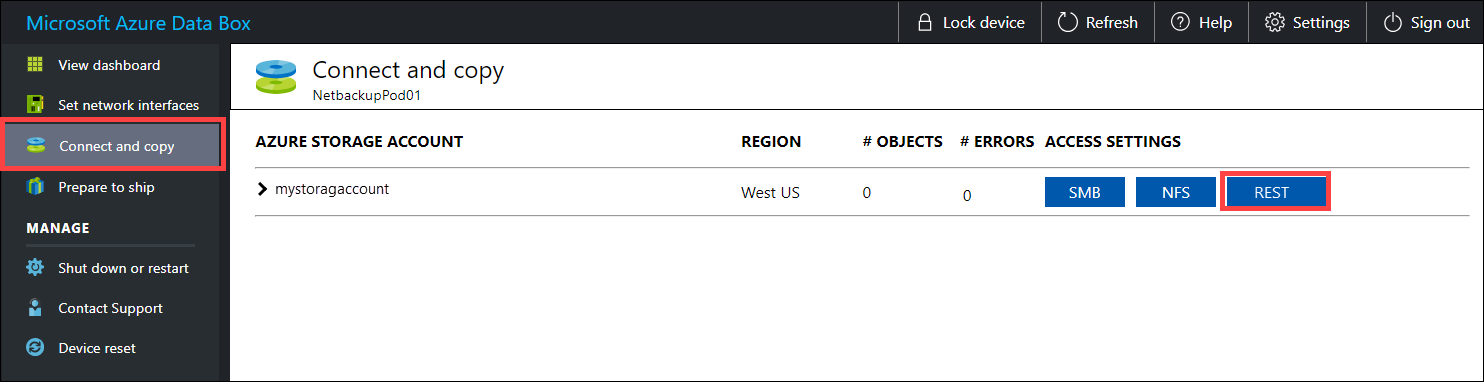
Kopieer in het dialoogvenster Opslagaccount van Access en het uploaden van gegevens het Blob-service-eindpunt en de sleutel van het opslagaccount. Laat vanaf het blob-service-eindpunt de
https://en de afsluitende slash weg.In dit geval is het eindpunt:
https://mystorageaccount.blob.mydataboxno.microsoftdatabox.com/. Het hostgedeelte van de URI die u gebruikt, is:mystorageaccount.blob.mydataboxno.microsoftdatabox.com. Zie voor een voorbeeld hoe u verbinding maakt met REST via http.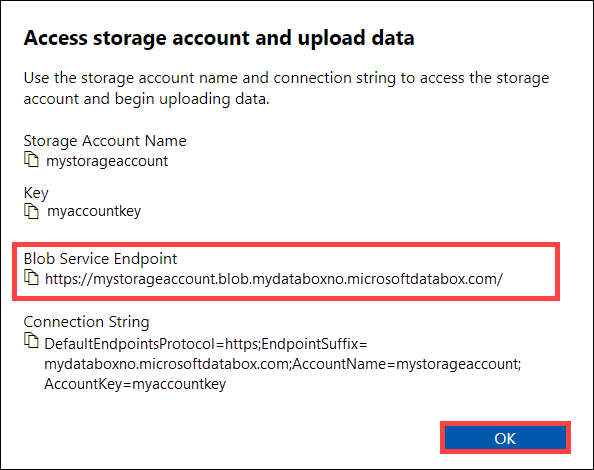
Voeg het eindpunt en het IP-adres van het Data Box- of Data Box Heavy-knooppunt toe aan
/etc/hostselk knooppunt.10.128.5.42 mystorageaccount.blob.mydataboxno.microsoftdatabox.comAls u een ander mechanisme voor DNS gebruikt, moet u ervoor zorgen dat het Data Box-eindpunt kan worden omgezet.
Stel de shell-variabele
azjarsin op de locatie van dehadoop-azureenazure-storageJAR-bestanden. U vindt deze bestanden onder de installatiemap van Hadoop.Gebruik de volgende opdracht om te bepalen of deze bestanden bestaan:
ls -l $<hadoop_install_dir>/share/hadoop/tools/lib/ | grep azureVervang de<hadoop_install_dir>tijdelijke aanduiding door het pad naar de map waarin u Hadoop hebt geïnstalleerd. Zorg ervoor dat u volledig gekwalificeerde paden gebruikt.Voorbeelden:
azjars=$hadoop_install_dir/share/hadoop/tools/lib/hadoop-azure-2.6.0-cdh5.14.0.jarazjars=$azjars,$hadoop_install_dir/share/hadoop/tools/lib/microsoft-windowsazure-storage-sdk-0.6.0.jarMaak de opslagcontainer die u wilt gebruiken voor het kopiëren van gegevens. U moet ook een doelmap opgeven als onderdeel van deze opdracht. Dit kan op dit moment een dummy-doelmap zijn.
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -mkdir -p wasb://<container_name>@<blob_service_endpoint>/<destination_directory>Vervang de
<blob_service_endpoint>tijdelijke aanduiding door de naam van uw blobservice-eindpunt.Vervang de
<account_key>tijdelijke aanduiding door de toegangssleutel van uw account.Vervang de
<container-name>tijdelijke aanduiding door de naam van uw container.Vervang de
<destination_directory>tijdelijke aanduiding door de naam van de map waarnaar u de gegevens wilt kopiëren.
Voer een lijstopdracht uit om ervoor te zorgen dat uw container en map zijn gemaakt.
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -ls -R wasb://<container_name>@<blob_service_endpoint>/Vervang de
<blob_service_endpoint>tijdelijke aanduiding door de naam van uw blobservice-eindpunt.Vervang de
<account_key>tijdelijke aanduiding door de toegangssleutel van uw account.Vervang de
<container-name>tijdelijke aanduiding door de naam van uw container.
Kopieer gegevens van Hadoop HDFS naar Data Box Blob Storage naar de container die u eerder hebt gemaakt. Als de map waarnaar u kopieert niet wordt gevonden, wordt deze automatisch gemaakt met de opdracht.
hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -filters <exclusion_filelist_file> \ [-f filelist_file | /<source_directory> \ wasb://<container_name>@<blob_service_endpoint>/<destination_directory>Vervang de
<blob_service_endpoint>tijdelijke aanduiding door de naam van uw blobservice-eindpunt.Vervang de
<account_key>tijdelijke aanduiding door de toegangssleutel van uw account.Vervang de
<container-name>tijdelijke aanduiding door de naam van uw container.Vervang de
<exclusion_filelist_file>tijdelijke aanduiding door de naam van het bestand dat de lijst met bestandsuitsluitingen bevat.Vervang de
<source_directory>tijdelijke aanduiding door de naam van de map die de gegevens bevat die u wilt kopiëren.Vervang de
<destination_directory>tijdelijke aanduiding door de naam van de map waarnaar u de gegevens wilt kopiëren.
De
-libjarsoptie wordt gebruikt om dehadoop-azure*.jaren de afhankelijkeazure-storage*.jarbestanden beschikbaar te maken voordistcp. Dit kan al gebeuren voor sommige clusters.In het volgende voorbeeld ziet u hoe de
distcpopdracht wordt gebruikt om gegevens te kopiëren.hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.mystorageaccount.blob.mydataboxno.microsoftdatabox.com=myaccountkey \ -filter ./exclusions.lst -f /tmp/copylist1 -m 4 \ /data/testfiles \ wasb://hdfscontainer@mystorageaccount.blob.mydataboxno.microsoftdatabox.com/dataDe kopieersnelheid verbeteren:
Probeer het aantal mappers te wijzigen. (Het standaardaantal mappers is 20. In het bovenstaande voorbeeld wordt gebruikgemaakt
mvan = 4 mappers.)Probeer
-D fs.azure.concurrentRequestCount.out=<thread_number>het. Vervang<thread_number>door het aantal threads per mapper. Het product van het aantal mappers en het aantal threads per mapper magm*<thread_number>niet groter zijn dan 32.Probeer meerdere
distcpparallel uit te voeren.Houd er rekening mee dat grote bestanden beter presteren dan kleine bestanden.
Als u bestanden hebt die groter zijn dan 200 GB, raden we u aan om de blokgrootte te wijzigen in 100 MB met de volgende parameters:
hadoop distcp \ -libjars $azjars \ -Dfs.azure.write.request.size= 104857600 \ -Dfs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -Dfs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -strategy dynamic \ -Dmapreduce.map.memory.mb=16384 \ -Dfs.azure.concurrentRequestCount.out=8 \ -Dmapreduce.map.java.opts=-Xmx8196m \ -m 4 \ -update \ /data/bigfile wasb://hadoop@mystorageaccount.blob.core.windows.net/bigfile
De Data Box verzenden naar Microsoft
Volg deze stappen om het Data Box-apparaat voor te bereiden en naar Microsoft te verzenden.
Bereid u eerst voor op verzending op uw Data Box of Data Box Heavy.
Nadat de voorbereiding van het apparaat is voltooid, downloadt u de BOM-bestanden. U gebruikt deze BOM- of manifestbestanden later om de gegevens te controleren die naar Azure zijn geüpload.
Sluit het apparaat af en verwijder de kabels.
Maak een afspraak met UPS om het pakket op te laten halen.
Zie Uw Data Box verzenden voor Data Box-apparaten.
Zie Uw Data Box Heavy verzenden voor Data Box Heavy-apparaten.
Nadat Microsoft uw apparaat heeft ontvangen, is het verbonden met het datacenternetwerk en worden de gegevens geüpload naar het opslagaccount dat u hebt opgegeven toen u de apparaatorder hebt geplaatst. Controleer op basis van de BOM-bestanden of al uw gegevens naar Azure zijn geüpload.
Toegangsmachtigingen toepassen op bestanden en mappen (alleen Data Lake Storage)
U hebt de gegevens al in uw Azure Storage-account. Nu past u toegangsmachtigingen toe op bestanden en mappen.
Notitie
Deze stap is alleen nodig als u Azure Data Lake Storage als uw gegevensarchief gebruikt. Als u alleen een Blob Storage-account gebruikt zonder hiërarchische naamruimte als uw gegevensarchief, kunt u deze sectie overslaan.
Een service-principal maken voor uw account met Azure Data Lake Storage
Wanneer u de stappen uitvoert in de sectie De toepassing toewijzen aan een rol van het artikel, moet u ervoor zorgen dat de rol Gegevensbijdrager voor opslagblob is toegewezen aan de service-principal.
Wanneer u de stappen uitvoert in de sectie Waarden ophalen voor aanmelding in het artikel, slaat u de toepassings-id en waarden van het clientgeheim op in een tekstbestand. Je hebt die binnenkort nodig.
Een lijst met gekopieerde bestanden genereren met hun machtigingen
Voer vanuit het on-premises Hadoop-cluster deze opdracht uit:
sudo -u hdfs ./copy-acls.sh -s /{hdfs_path} > ./filelist.json
Met deze opdracht wordt een lijst met gekopieerde bestanden met hun machtigingen gegenereerd.
Notitie
Afhankelijk van het aantal bestanden in de HDFS kan het lang duren voordat deze opdracht wordt uitgevoerd.
Een lijst met identiteiten genereren en deze toewijzen aan Microsoft Entra-identiteiten
Download het
copy-acls.pyscript. Zie de Helperscripts downloaden en stel uw Edge-knooppunt in om deze sectie van dit artikel uit te voeren.Voer deze opdracht uit om een lijst met unieke identiteiten te genereren.
./copy-acls.py -s ./filelist.json -i ./id_map.json -gMet dit script wordt een bestand gegenereerd
id_map.jsonmet de identiteiten die u moet toewijzen aan op ADD gebaseerde identiteiten.Open het bestand
id_map.jsonin een teksteditor.Werk voor elk JSON-object dat in het bestand wordt weergegeven, het
targetkenmerk van een Microsoft Entra user Principal Name (UPN) of ObjectId (OID) bij met de juiste toegewezen identiteit. Sla het bestand op nadat u klaar bent. U hebt dit bestand nodig in de volgende stap.
Machtigingen toepassen op gekopieerde bestanden en identiteitstoewijzingen toepassen
Voer deze opdracht uit om machtigingen toe te passen op de gegevens die u naar het Data Lake Storage-account hebt gekopieerd:
./copy-acls.py -s ./filelist.json -i ./id_map.json -A <storage-account-name> -C <container-name> --dest-spn-id <application-id> --dest-spn-secret <client-secret>
Vervang de tijdelijke plaatsaanduiding
<storage-account-name>door de naam van uw opslagaccount.Vervang de
<container-name>tijdelijke aanduiding door de naam van uw container.Vervang de
<application-id>tijdelijke aanduidingen door<client-secret>de toepassings-id en het clientgeheim dat u hebt verzameld toen u de service-principal maakte.
Bijlage: Gegevens splitsen over meerdere Data Box-apparaten
Voordat u uw gegevens naar een Data Box-apparaat verplaatst, moet u enkele helperscripts downloaden, ervoor zorgen dat uw gegevens zijn geordend om op een Data Box-apparaat te passen en overbodige bestanden uit te sluiten.
Helperscripts downloaden en uw Edge-knooppunt instellen om ze uit te voeren
Voer vanaf het edge- of hoofdknooppunt van uw on-premises Hadoop-cluster de volgende opdracht uit:
git clone https://github.com/jamesbak/databox-adls-loader.git cd databox-adls-loaderMet deze opdracht wordt de GitHub-opslagplaats gekloond die de helperscripts bevat.
Zorg ervoor dat het jq-pakket is geïnstalleerd op uw lokale computer.
sudo apt-get install jqInstalleer het Python-pakket Aanvragen .
pip install requestsStel uitvoermachtigingen in voor de vereiste scripts.
chmod +x *.py *.sh
Zorg ervoor dat uw gegevens zijn ingedeeld zodat ze op een Data Box-apparaat passen
Als de grootte van uw gegevens groter is dan één Data Box-apparaat, kunt u bestanden opsplitsen in groepen die u op meerdere Data Box-apparaten kunt opslaan.
Als uw gegevens niet groter zijn dan de grootte van een inge Data Box-apparaat, kunt u doorgaan naar de volgende sectie.
Voer met verhoogde machtigingen het
generate-file-listscript uit dat u hebt gedownload door de richtlijnen in de vorige sectie te volgen.Hier volgt een beschrijving van de opdrachtparameters:
sudo -u hdfs ./generate-file-list.py [-h] [-s DATABOX_SIZE] [-b FILELIST_BASENAME] [-f LOG_CONFIG] [-l LOG_FILE] [-v {DEBUG,INFO,WARNING,ERROR}] path where: positional arguments: path The base HDFS path to process. optional arguments: -h, --help show this help message and exit -s DATABOX_SIZE, --databox-size DATABOX_SIZE The size of each Data Box in bytes. -b FILELIST_BASENAME, --filelist-basename FILELIST_BASENAME The base name for the output filelists. Lists will be named basename1, basename2, ... . -f LOG_CONFIG, --log-config LOG_CONFIG The name of a configuration file for logging. -l LOG_FILE, --log-file LOG_FILE Name of file to have log output written to (default is stdout/stderr) -v {DEBUG,INFO,WARNING,ERROR}, --log-level {DEBUG,INFO,WARNING,ERROR} Level of log information to output. Default is 'INFO'.Kopieer de gegenereerde bestandslijsten naar HDFS zodat ze toegankelijk zijn voor de DistCp-taak .
hadoop fs -copyFromLocal {filelist_pattern} /[hdfs directory]
Onnodige bestanden uitsluiten
U moet sommige mappen uitsluiten van de DisCp-taak. Sluit bijvoorbeeld mappen uit die statusinformatie bevatten die het cluster actief houden.
Maak op het on-premises Hadoop-cluster waar u de DistCp-taak wilt initiëren een bestand met de lijst met mappen die u wilt uitsluiten.
Hier volgt een voorbeeld:
.*ranger/audit.*
.*/hbase/data/WALs.*
Volgende stappen
Meer informatie over hoe Data Lake Storage werkt met HDInsight-clusters. Zie Azure Data Lake Storage gebruiken met Azure HDInsight-clusters voor meer informatie.