Zelfstudie: Een aangepaste analyse voor telefoonnummers maken
In zoekoplossingen kunnen tekenreeksen met complexe patronen of speciale tekens een uitdaging zijn om mee te werken, omdat de standaardanalyse duidelijke delen van een patroon wegwerkt of verkeerd interpreteert, wat resulteert in een slechte zoekervaring wanneer gebruikers de verwachte informatie niet kunnen vinden. Telefoonnummers zijn een klassiek voorbeeld van tekenreeksen die moeilijk te analyseren zijn. Ze hebben verschillende indelingen en bevatten speciale tekens die de standaardanalyse negeert.
Met telefoonnummers als onderwerp bekijkt deze zelfstudie de problemen van gepatroonte gegevens en laat u zien dat probleem op te lossen met behulp van een aangepaste analyse. De hier beschreven benadering kan worden gebruikt voor telefoonnummers of aangepast voor velden met dezelfde kenmerken (met speciale tekens), zoals URL's, e-mailberichten, postcodes en datums.
In deze zelfstudie gebruikt u een REST-client en de REST API's van Azure AI Search voor het volgende:
- Het probleem begrijpen
- Een initiële aangepaste analyse ontwikkelen voor het verwerken van telefoonnummers
- De aangepaste analyse testen
- Herhalen op aangepast analyseontwerp om de resultaten verder te verbeteren
Vereisten
De volgende services en hulpprogramma's zijn vereist voor deze zelfstudie.
Visual Studio Code met een REST-client.
Azure AI Search. Maak of zoek een bestaande Azure AI Search-resource onder uw huidige abonnement. U kunt een gratis service voor deze quickstart gebruiken.
Bestanden downloaden
Broncode voor deze zelfstudie is het bestand custom-analyzer.rest in de GitHub-opslagplaats Azure-Samples/azure-search-rest.samples .
Een sleutel en URL kopiëren
Voor de REST-aanroepen in deze zelfstudie is een zoekservice-eindpunt en een beheer-API-sleutel vereist. U kunt deze waarden ophalen uit Azure Portal.
Meld u aan bij Azure Portal, navigeer naar de pagina Overzicht en kopieer de URL. Een eindpunt ziet er bijvoorbeeld uit als
https://mydemo.search.windows.net.Kopieer onder Instellingensleutels> een beheerderssleutel. Beheerderssleutels worden gebruikt om objecten toe te voegen, te wijzigen en te verwijderen. Er zijn twee uitwisselbare beheerderssleutels. Kopieer een van beide.
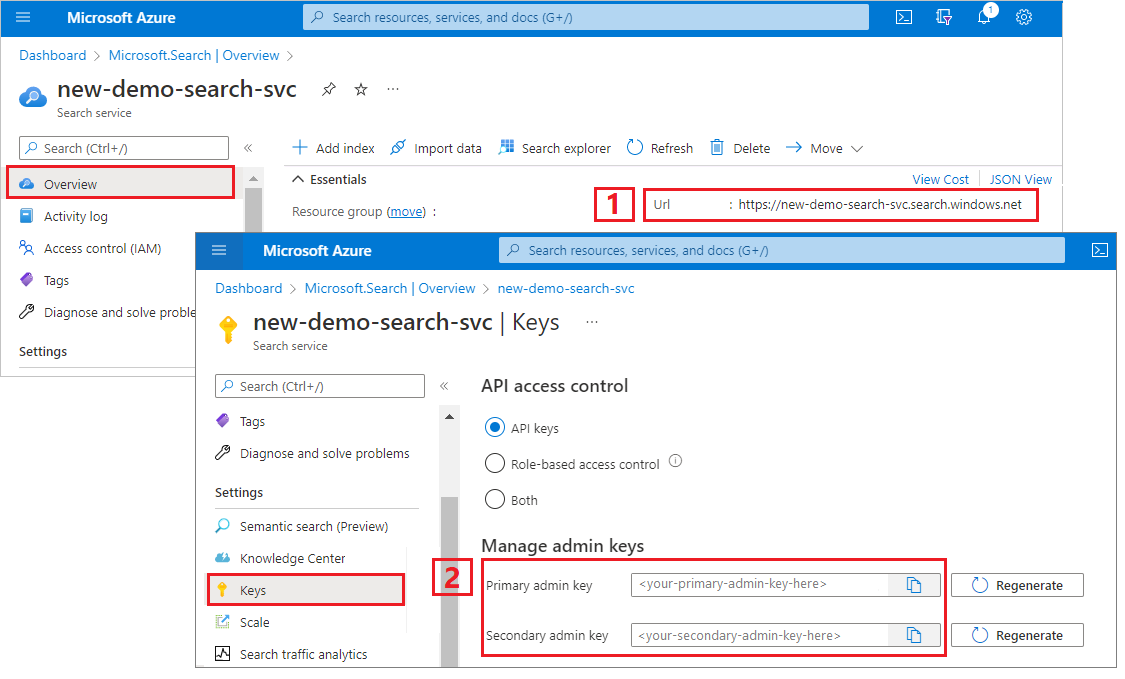
Een geldige API-sleutel brengt een vertrouwensrelatie tot stand, per aanvraag, tussen de toepassing die de aanvraag verzendt en de zoekservice die deze verwerkt.
Een initiële index maken
Open een nieuw tekstbestand in Visual Studio Code.
Stel variabelen in op het zoekeindpunt en de API-sleutel die u in de vorige stap hebt verzameld.
@baseUrl = PUT-YOUR-SEARCH-SERVICE-URL-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HERESla het bestand op met een
.restbestandsextensie.Plak in het volgende voorbeeld een kleine index met de naam
phone-numbers-indextwee velden:idenphone_number. We hebben nog geen analyse gedefinieerd, dus destandard.luceneanalyse wordt standaard gebruikt.### Create a new index POST {{baseUrl}}/indexes?api-version=2024-07-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "name": "phone-numbers-index", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "searchable": true, "filterable": false, "facetable": false, "sortable": true }, { "name": "phone_number", "type": "Edm.String", "sortable": false, "searchable": true, "filterable": false, "facetable": false } ] }Selecteer Verzoek verzenden. U moet een
HTTP/1.1 201 Createdantwoord hebben en de hoofdtekst van het antwoord moet de JSON-weergave van het indexschema bevatten.Laad gegevens in de index met documenten die verschillende notaties voor telefoonnummers bevatten. Dit zijn uw testgegevens.
### Load documents POST {{baseUrl}}/indexes/phone-numbers-index/docs/index?api-version=2024-07-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "value": [ { "@search.action": "upload", "id": "1", "phone_number": "425-555-0100" }, { "@search.action": "upload", "id": "2", "phone_number": "(321) 555-0199" }, { "@search.action": "upload", "id": "3", "phone_number": "+1 425-555-0100" }, { "@search.action": "upload", "id": "4", "phone_number": "+1 (321) 555-0199" }, { "@search.action": "upload", "id": "5", "phone_number": "4255550100" }, { "@search.action": "upload", "id": "6", "phone_number": "13215550199" }, { "@search.action": "upload", "id": "7", "phone_number": "425 555 0100" }, { "@search.action": "upload", "id": "8", "phone_number": "321.555.0199" } ] }Laten we een paar query's proberen die vergelijkbaar zijn met wat een gebruiker kan typen. Een gebruiker kan zoeken
(425) 555-0100in een willekeurig aantal indelingen en verwacht nog steeds dat resultaten worden geretourneerd. Begin door te zoeken(425) 555-0100:### Search for a phone number GET {{baseUrl}}/indexes/phone-numbers-index/docs/search?api-version=2024-07-01&search=(425) 555-0100 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}}De query retourneert drie van de vier verwachte resultaten, maar retourneert ook twee onverwachte resultaten:
{ "value": [ { "@search.score": 0.05634898, "phone_number": "+1 425-555-0100" }, { "@search.score": 0.05634898, "phone_number": "425 555 0100" }, { "@search.score": 0.05634898, "phone_number": "425-555-0100" }, { "@search.score": 0.020766128, "phone_number": "(321) 555-0199" }, { "@search.score": 0.020766128, "phone_number": "+1 (321) 555-0199" } ] }Laten we het opnieuw proberen zonder opmaak:
4255550100.### Search for a phone number GET {{baseUrl}}/indexes/phone-numbers-index/docs/search?api-version=2024-07-01&search=4255550100 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}}Deze query doet nog erger en retourneert slechts één van de vier juiste overeenkomsten.
{ "value": [ { "@search.score": 0.6015292, "phone_number": "4255550100" } ] }
U bent niet de enige die deze resultaten verwarrend vindt. In de volgende sectie gaan we dieper in op de reden waarom we deze resultaten krijgen.
Controleren hoe analysen werken
Om deze zoekresultaten te begrijpen, moeten we begrijpen wat de analyse doet. Van daaruit kunnen we de standaardanalyse testen met behulp van de Analyse-API, die een basis biedt voor het ontwerpen van een analyse die beter aan onze behoeften voldoet.
Een analyse maakt deel uit van de engine voor zoekopdrachten in volledige tekst en is verantwoordelijk voor het verwerken van tekst in queryreeksen en geïndexeerde documenten. Afhankelijk van het scenario manipuleren verschillende analyses tekst op verschillende manieren. Voor dit scenario gaan we een analyse maken die geschikt is voor telefoonnummers.
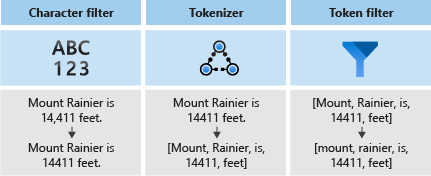
Analyses bestaan uit drie onderdelen:
- tekenfilters waarmee afzonderlijke tekens in de invoertekst worden verwijderd of vervangen.
- een tokenizer waarmee de invoertekst wordt opgesplitst in tokens, die sleutels worden in de zoekindex.
- tokenfilters waarmee de tokens worden gemanipuleerd die door de tokenizer worden geproduceerd.
In het volgende diagram ziet u hoe deze drie onderdelen samenwerken om een zin te tokeniseren:
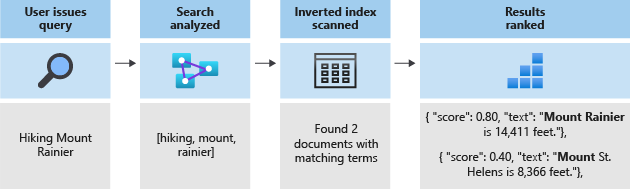
Deze tokens worden vervolgens opgeslagen in een omgekeerde index, waardoor snelle zoekopdrachten in volledige tekst mogelijk zijn. Met een omgekeerde index kunt u zoeken in volledige tekst toestaan door alle unieke termen die zijn geëxtraheerd tijdens de lexicale analyse, toe te wijzen aan de documenten waarin ze voorkomen. In het volgende diagram ziet u een voorbeeld:

Elke zoekopdracht komt neer op het zoeken naar de termen die in de omgekeerde index zijn opgeslagen. Wanneer een gebruiker een query opgeeft:
- Wordt de query geparseerd en worden de querytermen geanalyseerd.
- De omgekeerde index wordt vervolgens gescand op documenten die overeenkomende termen bevatten.
- Ten slotte worden de opgehaalde documenten gerangschikt op basis van het score-algoritme.
Als de querytermen niet overeenkomen met de termen in de omgekeerde index, worden de resultaten niet geretourneerd. Voor meer informatie over hoe query's werken, raadpleegt u dit artikel over zoeken in volledige tekst.
Notitie
Query's die uit onvolledige termen bestaan vormen een belangrijke uitzondering op deze regel. Met deze query's (query met voorvoegsel, jokerteken of die uit een reguliere-expressie bestaat) wordt het lexicale analyseproces omzeild, in tegenstelling tot query's die uit reguliere termen bestaan. Gedeeltelijke termen worden alleen in kleine letters omgezet voordat ze aan overeenkomende termen in de index worden gekoppeld. Als een analyse niet is geconfigureerd om deze typen query's te ondersteunen, ontvangt u vaak onverwachte resultaten omdat er geen overeenkomende termen in de index voorkomen.
Analyseanalyses testen met behulp van de Analyse-API
Azure AI Search biedt een Analyse-API waarmee u analyses kunt testen om te begrijpen hoe tekst wordt verwerkt.
De Analyze-API wordt aangeroepen met behulp van de volgende aanvraag:
POST {{baseUrl}}/indexes/phone-numbers-index/analyze?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"text": "(425) 555-0100",
"analyzer": "standard.lucene"
}
De API retourneert de tokens die zijn geëxtraheerd uit de tekst, met behulp van de analyse die u hebt opgegeven. De standaard Lucene Analyzer splitst het telefoonnummer in drie afzonderlijke tokens:
{
"tokens": [
{
"token": "425",
"startOffset": 1,
"endOffset": 4,
"position": 0
},
{
"token": "555",
"startOffset": 6,
"endOffset": 9,
"position": 1
},
{
"token": "0100",
"startOffset": 10,
"endOffset": 14,
"position": 2
}
]
}
Omgekeerd wordt het telefoonnummer 4255550100 waarvan de indeling geen enkel leesteken bevat, in één enkele token getokeniseerd.
{
"text": "4255550100",
"analyzer": "standard.lucene"
}
Respons:
{
"tokens": [
{
"token": "4255550100",
"startOffset": 0,
"endOffset": 10,
"position": 0
}
]
}
Houd er rekening mee dat zowel querytermen als de geïndexeerde documenten een analyse ondergaan. Als u even terugdenkt aan de zoekresultaten uit de vorige stap, wordt het u misschien duidelijk waarom die resultaten werden geretourneerd.
In de eerste query werden onverwachte telefoonnummers geretourneerd omdat een van hun tokens, 555overeenkomt met een van de termen die we hebben doorzocht. In de tweede query werd slechts één getal geretourneerd omdat het de enige record was die een tokenmatch 4255550100had.
Een aangepaste analyse bouwen
Nu we weten waarom deze resultaten werden geretourneerd, gaan we een aangepaste analyse bouwen om de tokeniseringslogica te verbeteren.
Ons doel is om intuïtieve zoekacties te kunnen uitvoeren op telefoonnummers, ongeacht welke indeling de query of geïndexeerde tekenreeks heeft. Om dit resultaat te bereiken, geven we een tekenfilter, een tokenizer en een tokenfilter op.
Tekenfilters
Tekenfilters worden gebruikt voor het verwerken van tekst voordat deze aan de tokenizer wordt doorgegeven. Tekenfilters worden vaak gebruikt om HTML-elementen uit te filteren of om speciale tekens te vervangen.
Bij telefoonnummers willen we witruimte en speciale tekens verwijderen omdat niet alle telefoonnummerindelingen dezelfde speciale tekens en spaties bevatten.
"charFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.MappingCharFilter",
"name": "phone_char_mapping",
"mappings": [
"-=>",
"(=>",
")=>",
"+=>",
".=>",
"\\u0020=>"
]
}
]
Het filter verwijdert -+(). en spaties uit de invoer.
| Invoer | Uitvoer |
|---|---|
(321) 555-0199 |
3215550199 |
321.555.0199 |
3215550199 |
Tokenizers
Met tokenizers wordt tekst opgesplitst in tokens en worden tegelijkertijd sommige tekens, zoals leestekens, verwijderd. Vaak is het doel van tokeniseren om een zin op te splitsen in afzonderlijke woorden.
Voor dit scenario gaan we een trefwoordtokenizer gebruiken, keyword_v2, omdat we het telefoonnummer willen vastleggen als één enkele term. Dit is overigens niet de enige manier om dit probleem op te lossen. Zie de sectie Andere manieren hieronder.
Bij het gebruik van trefwoordtokenizers is de invoertekst gelijk aan de uitvoertekst, maar dan in de vorm van één enkele term.
| Invoer | Uitvoer |
|---|---|
The dog swims. |
[The dog swims.] |
3215550199 |
[3215550199] |
Tokenfilters
Met tokenfilters worden de tokens die zijn gegenereerd door de tokenizer, uitgefilterd of gewijzigd. Tokenfilters worden vaak gebruikt om alle tekens in kleine letters om te zetten met behulp van kleine-lettertokenfilter. Een ander veelvoorkomend gebruik is het filteren van stopwoorden zoals the, andof is.
Voor dit scenario gaan we geen van deze filters gebruiken, maar gaan we een nGram-tokenfilter gebruiken om deelzoekopdrachten voor telefoonnummers mogelijk te maken.
"tokenFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.NGramTokenFilterV2",
"name": "custom_ngram_filter",
"minGram": 3,
"maxGram": 20
}
]
NGramTokenFilterV2
Met het tokenfilter nGram_v2 worden tokens gesplitst in n-grammen van een bepaalde grootte op basis van de parameters minGram en maxGram.
Voor de telefoonanalyse stellen we minGram in op 3 omdat dit de kortste subtekenreeks is waarnaar gebruikers verwacht worden te zoeken.
maxGram is ingesteld op 20 om ervoor te zorgen dat alle telefoonnummers, zelfs met toestelnummers, in één n-gram passen.
Het vervelend neveneffect van n-grammen is dat er enkele fout-positieven worden geretourneerd. Dit wordt in een latere stap opgelost door een afzonderlijke analyse uit te bouwen voor zoekopdrachten die geen n-gram tokenfilter bevatten.
| Invoer | Uitvoer |
|---|---|
[12345] |
[123, 1234, 12345, 234, 2345, 345] |
[3215550199] |
[321, 3215, 32155, 321555, 3215550, 32155501, 321555019, 3215550199, 215, 2155, 21555, 215550, ... ] |
Analyzer
Nu we over tekenfilters, tokenizers en tokenfilters beschikken kunnen we beginnen met het definiëren van onze analyse.
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer",
"tokenizer": "keyword_v2",
"tokenFilters": [
"custom_ngram_filter"
],
"charFilters": [
"phone_char_mapping"
]
}
]
Vanuit de Analyse-API, op basis van de volgende invoer, worden uitvoer van de aangepaste analyse weergegeven in de volgende tabel.
| Invoer | Uitvoer |
|---|---|
12345 |
[123, 1234, 12345, 234, 2345, 345] |
(321) 555-0199 |
[321, 3215, 32155, 321555, 3215550, 32155501, 321555019, 3215550199, 215, 2155, 21555, 215550, ... ] |
Alle tokens in de uitvoerkolom bestaan in de index. Als onze query een van deze termen bevat, wordt het telefoonnummer geretourneerd.
Herbouwen met behulp van de nieuwe analyse
Verwijder de huidige index:
### Delete the index DELETE {{baseUrl}}/indexes/phone-numbers-index?api-version=2024-07-01 HTTP/1.1 api-key: {{apiKey}}Maak de index opnieuw met behulp van de nieuwe analyse. Met dit indexschema wordt een aangepaste analysedefinitie en een aangepaste analysetoewijzing toegevoegd aan het telefoonnummerveld.
### Create a new index POST {{baseUrl}}/indexes?api-version=2024-07-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "name": "phone-numbers-index-2", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "searchable": true, "filterable": false, "facetable": false, "sortable": true }, { "name": "phone_number", "type": "Edm.String", "sortable": false, "searchable": true, "filterable": false, "facetable": false, "analyzer": "phone_analyzer" } ], "analyzers": [ { "@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer", "name": "phone_analyzer", "tokenizer": "keyword_v2", "tokenFilters": [ "custom_ngram_filter" ], "charFilters": [ "phone_char_mapping" ] } ], "charFilters": [ { "@odata.type": "#Microsoft.Azure.Search.MappingCharFilter", "name": "phone_char_mapping", "mappings": [ "-=>", "(=>", ")=>", "+=>", ".=>", "\\u0020=>" ] } ], "tokenFilters": [ { "@odata.type": "#Microsoft.Azure.Search.NGramTokenFilterV2", "name": "custom_ngram_filter", "minGram": 3, "maxGram": 20 } ] }
De aangepaste analyse testen
Nadat u de index opnieuw hebt gemaakt, kunt u nu de analyse testen met behulp van de volgende aanvraag:
POST {{baseUrl}}/indexes/tutorial-first-analyzer/analyze?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"text": "+1 (321) 555-0199",
"analyzer": "phone_analyzer"
}
U ziet nu de verzameling tokens die het gevolg zijn van het telefoonnummer:
{
"tokens": [
{
"token": "132",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
{
"token": "1321",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
{
"token": "13215",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
...
...
...
]
}
De aangepaste analyse aanpassen om fout-positieven te verwerken
Nadat u met de aangepaste analyse een aantal voorbeelden hebt gemaakt op basis van de index, zult u zien dat het aantal relevante overeenkomsten is toegenomen en dat alle overeenkomende telefoonnummers nu worden geretourneerd. Het n-gram-tokenfilter produceert echter ook een aantal fout-positieven. Dit is een veelvoorkomend neveneffect van een n-gram-tokenfilter.
Ter voorkoming van fout-positieven, gaan we een afzonderlijke analyse voor het uitvoeren van query's maken. Deze analyse is identiek aan de vorige analyse, behalve dat het de custom_ngram_filter.
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer_search",
"tokenizer": "custom_tokenizer_phone",
"tokenFilters": [],
"charFilters": [
"phone_char_mapping"
]
}
In de indexdefinitie geven we vervolgens zowel een indexAnalyzer als een searchAnalyzerop.
{
"name": "phone_number",
"type": "Edm.String",
"sortable": false,
"searchable": true,
"filterable": false,
"facetable": false,
"indexAnalyzer": "phone_analyzer",
"searchAnalyzer": "phone_analyzer_search"
}
Nadat u deze wijziging hebt aangebracht, bent u klaar. Dit zijn de volgende stappen:
Verwijder de index.
Maak de index opnieuw na het toevoegen van de nieuwe aangepaste analyse (
phone_analyzer-search) en wijs die analyse toe aan de eigenschap vansearchAnalyzerhetphone-numberveld.Laad de gegevens opnieuw.
Test de query's opnieuw om te controleren of de zoekopdracht werkt zoals verwacht. Als u het voorbeeldbestand gebruikt, maakt u met deze stap de derde index met de naam
phone-number-index-3.
Andere manieren
De analyse die in de vorige sectie wordt beschreven, is ontworpen om de flexibiliteit voor zoeken te maximaliseren. Dit gaat echter ten koste gaan van de mogelijkheid om veel, mogelijk onbelangrijke termen in de index te kunnen opslaan.
In het volgende voorbeeld ziet u een alternatieve analyse die efficiënter is in tokenisatie, maar nadelen heeft.
Uitgaande van een invoer van 14255550100, kan de analyse het telefoonnummer niet logisch segmenten. Het landnummer kan bijvoorbeeld niet worden gescheiden, 1van het netnummer. 425 Deze discrepantie zou ertoe leiden dat het telefoonnummer niet wordt geretourneerd als een gebruiker geen landcode in de zoekopdracht heeft opgenomen.
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer_shingles",
"tokenizer": "custom_tokenizer_phone",
"tokenFilters": [
"custom_shingle_filter"
]
}
],
"tokenizers": [
{
"@odata.type": "#Microsoft.Azure.Search.StandardTokenizerV2",
"name": "custom_tokenizer_phone",
"maxTokenLength": 4
}
],
"tokenFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.ShingleTokenFilter",
"name": "custom_shingle_filter",
"minShingleSize": 2,
"maxShingleSize": 6,
"tokenSeparator": ""
}
]
In het volgende voorbeeld ziet u dat het telefoonnummer is gesplitst in de segmenten waarnaar u normaal gesproken zou verwachten dat een gebruiker zoekt.
| Invoer | Uitvoer |
|---|---|
(321) 555-0199 |
[321, 555, 0199, 321555, 5550199, 3215550199] |
Afhankelijk van uw vereisten kan dit een efficiëntere benadering van het probleem zijn.
Opgedane kennis
In deze zelfstudie werd het proces voor het maken en testen van een aangepaste analyse getoond. U hebt een index gemaakt, gegevens geïndexeerd en vervolgens een query uitgevoerd op basis van de index om te zien welke zoekresultaten werden geretourneerd. Van daaruit hebt u de Analyse-API gebruikt om het lexicale analyseproces in actie te zien.
Hoewel de analyse die in deze zelfstudie is gedefinieerd, een eenvoudige oplossing biedt voor het zoeken naar telefoonnummers, kan hetzelfde proces worden gebruikt om een aangepaste analyse te maken voor elk scenario dat vergelijkbare kenmerken deelt.
Resources opschonen
Wanneer u in uw eigen abonnement werkt, is het een goed idee om aan het einde van een project de resources te verwijderen die u niet meer nodig hebt. Resources die actief blijven, kunnen u geld kosten. U kunt resources afzonderlijk verwijderen, maar u kunt ook de resourcegroep verwijderen als u de volledige resourceset wilt verwijderen.
U kunt resources vinden en beheren in Azure Portal met behulp van de koppeling Alle resources of resourcegroepen in het linkernavigatiedeelvenster.
Volgende stappen
Nu u bekend bent met het maken van een aangepaste analyse, gaan we kijken naar de verschillende filters, tokenizers en analyses die u tot uw beschikking hebt om een rijke zoekervaring te creëren.