Tips voor betere prestaties in Azure AI Search
Dit artikel is een verzameling tips en aanbevolen procedures voor het stimuleren van query- en indexeringsprestaties voor trefwoordzoekopdrachten. Als u weet welke factoren waarschijnlijk van invloed zijn op de zoekprestaties, kunt u inefficiënties voorkomen en optimaal gebruikmaken van uw zoekservice. Enkele belangrijke factoren zijn:
- Indexsamenstelling (schema en grootte)
- Queryontwerp
- Servicecapaciteit (laag en het aantal replica's en partities)
Notitie
Bent u op zoek naar strategieën voor indexering met een hoog volume? Zie Grote gegevenssets indexeren in Azure AI Search.
Indexgrootte en schema
Query's worden sneller uitgevoerd op kleinere indexen. Dit is deels een functie waarbij minder velden moeten worden gescand, maar dit komt ook doordat het systeem inhoud opstuurt voor toekomstige query's. Na de eerste query blijft bepaalde inhoud in het geheugen waar deze efficiënter wordt doorzocht. Omdat de indexgrootte in de loop van de tijd toeneemt, kunt u het beste de indexsamenstelling, zowel schema als documenten, regelmatig opnieuw bekijken om te zoeken naar mogelijkheden voor inhoudsreductie. Als de index echter de juiste grootte heeft, is de enige kalibratie die u kunt maken de capaciteit te verhogen: door replica's toe te voegen of de servicelaag te upgraden. In de sectie 'Tip: Upgraden naar een Standard S2-laag' wordt de beslissing voor omhoog schalen versus uitschalen besproken.
Schemacomplexiteit kan ook nadelig zijn voor indexering en queryprestaties. Overmatige toeschrijving van velden in beperkingen en verwerkingsvereisten. Complexe typen duren langer om te indexeren en query's uit te voeren. In de volgende secties wordt elke voorwaarde verkend.
Tip: Selectief zijn in veldvermelding
Een veelvoorkomende fout die beheerders en ontwikkelaars maken bij het maken van een zoekindex, is het selecteren van alle beschikbare eigenschappen voor de velden, in plaats van alleen de eigenschappen te selecteren die nodig zijn. Als een veld bijvoorbeeld niet doorzoekbaar hoeft te zijn voor volledige tekst, slaat u dat veld over bij het instellen van het doorzoekbare kenmerk.
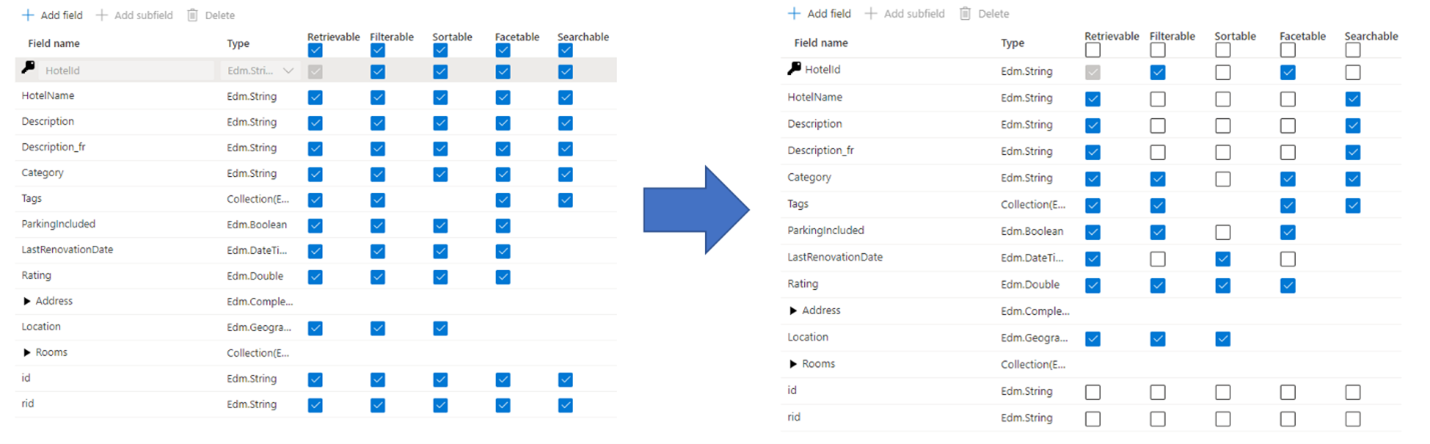
Ondersteuning voor filters, facetten en sorteren kan viervoudige opslagvereisten bieden. Als u suggesties toevoegt, neemt de opslagvereisten nog meer toe. Zie Kenmerken en indexgrootte voor een afbeelding van de impact van kenmerken op de opslag.
Samengevat zijn de gevolgen van overtoewijzing onder andere:
Degradatie van de indexeringsprestaties vanwege het extra werk dat nodig is om de inhoud in het veld te verwerken en sla deze vervolgens op in de omgekeerde index van de zoekopdracht (stel het kenmerk Doorzoekbaar alleen in voor velden die doorzoekbare inhoud bevatten).
Hiermee maakt u een groter oppervlak dat door elke query moet worden bedekt. Alle velden die als doorzoekbaar zijn gemarkeerd, worden gescand in een zoekopdracht in volledige tekst.
Verhoogt de operationele kosten vanwege extra opslagruimte. Filteren en sorteren vereist extra ruimte voor het opslaan van oorspronkelijke (niet-geanalyseerde) tekenreeksen. Vermijd het instellen van filterbaar of sorteerbaar voor velden die deze niet nodig hebben.
In veel gevallen beperkt het gebruik van toeschrijving de mogelijkheden van het veld. Als een veld bijvoorbeeld facetabel, filterbaar en doorzoekbaar is, kunt u slechts 16 kB tekst in een veld opslaan, terwijl een doorzoekbaar veld maximaal 16 MB aan tekst kan bevatten.
Notitie
Alleen onnodige toeschrijving moet worden vermeden. Filters en facetten zijn vaak essentieel voor de zoekervaring en in gevallen waarin filters worden gebruikt, hebt u vaak sorteren nodig, zodat u de resultaten kunt ordenen (filters op zichzelf retourneren in een niet-geordende set).
Tip: Overweeg alternatieven voor complexe typen
Complexe gegevenstypen zijn handig wanneer gegevens een gecompliceerde geneste structuur hebben, zoals de bovenliggende en onderliggende elementen in JSON-documenten. Het nadeel van complexe typen is de extra opslagvereisten en aanvullende resources die nodig zijn om de inhoud te indexeren, in vergelijking met niet-complexe gegevenstypen.
In sommige gevallen kunt u deze afwegingen voorkomen door een complexe gegevensstructuur toe te wijden aan een eenvoudiger veldtype, zoals een verzameling. U kunt ook kiezen voor het platmaken van een veldhiërarchie in afzonderlijke velden op hoofdniveau.

Queryontwerp
Querysamenstelling en complexiteit zijn een van de belangrijkste factoren voor prestaties en queryoptimalisatie kan de prestaties drastisch verbeteren. Denk bij het ontwerpen van query's na over de volgende punten:
Aantal doorzoekbare velden. Elk extra doorzoekbaar veld resulteert in meer werk voor de zoekservice. U kunt de velden die tijdens de query worden doorzocht beperken met behulp van de parameter searchFields. U kunt het beste alleen de velden opgeven die u belangrijk vindt om de prestaties te verbeteren.
Hoeveelheid gegevens die wordt geretourneerd. Door een grote hoeveelheid inhoud op te halen, kunnen query's langzamer worden. Wanneer u een query structureert, moet u ervoor zorgen dat alleen de velden worden geretourneerd die u nodig hebt om de resultatenpagina weer te geven. Haal vervolgens de resterende velden op met behulp van de Opzoek-API zodra een gebruiker een overeenkomst selecteert.
Gebruik van gedeeltelijke zoektermen. Gedeeltelijke zoektermen, zoals zoeken naar voorvoegsels, fuzzy zoekopdrachten en reguliere zoekacties voor expressies, zijn rekenkundig duurder dan gewone trefwoordzoekopdrachten, omdat ze volledige indexscans nodig hebben om resultaten te produceren.
Aantal facetten. Voor het toevoegen van facetten aan query's zijn aggregaties voor elke query vereist. Voor het aanvragen van een hoger 'aantal' facetten is ook extra werk van de service vereist. In het algemeen voegt u alleen de facetten toe die u in uw app wilt weergeven en vermijdt u het aanvragen van een groot aantal facetten, tenzij dat nodig is.
Hoge waarden voor overslaan. Als u parameter
$skipinstelt op een hoge waarde (bijvoorbeeld enkele duizenden), verhoogt u de zoeklatentie omdat de engine een groter aantal documenten voor elke aanvraag opvraagt en rangschikt. Vanwege prestatieredenen is het raadzaam om hoge$skip-waarden te voorkomen en in plaats daarvan andere technieken te gebruiken, zoals filteren, om grote aantallen documenten op te halen.Beperk velden van hoge kardinaliteit. Een veld met hoge kardinaliteit verwijst naar een facetabel of filterbaar veld met een aanzienlijk aantal unieke waarden en verbruikt als gevolg hiervan aanzienlijke resources bij het berekenen van resultaten. Als u bijvoorbeeld een veld Product-id of Beschrijving instelt als facetbaar en filterbaar, wordt het aantal kardinaliteiten meegeteld omdat de meeste waarden van het document naar het document uniek zijn.
Tip: Zoekfuncties gebruiken in plaats daarvan filtercriteria overbelasten
Als een query gebruikmaakt van steeds complexer filtercriteria, zullen de prestaties van de zoekquery afnemen. Bekijk het volgende voorbeeld dat het gebruik van filters laat zien om resultaten te knippen op basis van een gebruikersidentiteit:
$filter= userid eq 123 or userid eq 234 or userid eq 345 or userid eq 456 or userid eq 567
In dit geval worden de filterexpressies gebruikt om te controleren of één veld in elk document gelijk is aan een van de vele mogelijke waarden van een gebruikersidentiteit. U zult dit patroon waarschijnlijk vinden in toepassingen die beveiligingsbeperkingen implementeren (het controleren van een veld met een of meer principal-id's op basis van een lijst met principal-id's die de gebruiker aangeeft die de query uitgeven).
Een efficiëntere manier om filters uit te voeren die een groot aantal waarden bevatten, is door functie te gebruikensearch.in, zoals wordt weergegeven in dit voorbeeld:
search.in(userid, '123,234,345,456,567', ',')
Tip: Partities toevoegen voor trage afzonderlijke query's
Wanneer de queryprestaties in het algemeen vertragen, wordt het probleem vaak opgelost door meer replica's toe te voegen. Maar wat gebeurt er als het probleem een enkele query is die te lang duurt om te voltooien? In dit scenario helpt het toevoegen van replica's niet, maar meer partities kunnen wel. Een partitie splitst gegevens over extra rekenresources. Twee partities splitsen gegevens in de helft, een derde partitie splitst deze in derden, enzovoort.
Een positief neveneffect van het toevoegen van partities is dat tragere query's soms sneller presteren vanwege parallelle computing. We hebben parallellisatie genoteerd voor query's met lage selectiviteit, zoals query's die overeenkomen met veel documenten of facetten die tellingen bieden voor een groot aantal documenten. Omdat een aanzienlijke berekening vereist is om de relevantie van de documenten te beoordelen of om het aantal documenten te tellen, helpt het toevoegen van extra partities om query's sneller te voltooien.
Als u partities wilt toevoegen, gebruikt u Azure Portal, PowerShell, Azure CLI of een beheer-SDK.
Servicecapaciteit
Een service wordt overbelast wanneer query's te lang duren of wanneer de service aanvragen gaat verwijderen. Als dit gebeurt, kunt u het probleem oplossen door de service te upgraden of door capaciteit toe te voegen.
De laag van uw zoekservice en het aantal replica's/partities hebben ook een grote invloed op de prestaties. Elke geleidelijk hogere laag biedt snellere CPU's en meer geheugen, die beide een positieve invloed hebben op de prestaties.
Tip: Een nieuwe zoekservice voor hoge capaciteit maken
Basis- en standaardservices die zijn gemaakt in ondersteunde regio's na 3 april 2024, hebben meer opslag per partitie dan oudere services. Voordat u een upgrade uitvoert naar een hogere laag en een hoger factureerbare tarief, gaat u opnieuw naar de servicelimieten voor de laag om te zien of dezelfde laag voor een nieuwere service u de benodigde opslag biedt.
Tip: Upgraden naar een Standard S2-laag
De Standard S1-zoeklaag is vaak waar klanten beginnen. Een algemeen patroon voor S1-services is dat indexen na verloop van tijd toenemen, waarvoor meer partities nodig zijn. Meer partities leiden tot tragere reactietijden, zodat er meer replica's worden toegevoegd om de querybelasting te verwerken. Zoals u zich kunt voorstellen, zijn de kosten voor het uitvoeren van een S1-service nu verder gegaan dan de eerste configuratie.
Op dit moment is een belangrijke vraag of het nuttig zou zijn om over te stappen op een hogere laag, in tegenstelling tot het geleidelijk verhogen van het aantal partities of replica's van de huidige service.
Bekijk de volgende topologie als een voorbeeld van een service die is genomen op toenemende capaciteitsniveaus:
- Standard S1-laag
- Indexgrootte: 190 GB
- Aantal partities: 8 (op S1 is de partitiegrootte 25 GB per partitie)
- Aantal replica's: 2
- Totaal aantal zoekeenheden: 16 (8 partities x 2 replica's)
- Hypothetische verkoopprijs: ~ $ 4.000 USD / maand (ervan uitgegaan dat 250 USD x 16 zoekeenheden)
Stel dat de servicebeheerder nog steeds hogere latentiepercentages ziet en overweegt een andere replica toe te voegen. Hierdoor wordt het aantal replica's gewijzigd van 2 naar 3 en wordt het aantal zoekeenheden gewijzigd in 24 en een resulterende prijs van $ 6.000 USD/maand.
Als de beheerder er echter voor kiest om over te stappen op een Standard S2-laag, ziet de topologie er als volgt uit:
- Standard S2-laag
- Indexgrootte: 190 GB
- Aantal partities: 2 (op S2 is de partitiegrootte 100 GB per partitie)
- Aantal replica's: 2
- Totaal aantal zoekeenheden: 4 (2 partities x 2 replica's)
- Hypothetische verkoopprijs: ~$ 4.000 USD / maand (1.000 USD x 4 zoekeenheden)
Zoals dit hypothetische scenario illustreert, kunt u configuraties hebben op lagere lagen die resulteren in vergelijkbare kosten alsof u in de eerste plaats voor een hogere laag hebt gekozen. Hogere lagen worden echter geleverd met Premium Storage, waardoor indexering sneller verloopt. Hogere lagen hebben ook veel meer rekenkracht, evenals extra geheugen. Voor dezelfde kosten kunt u een krachtigere infrastructuur hebben als back-up van dezelfde index.
Een belangrijk voordeel van extra geheugen is dat meer van de index in de cache kan worden opgeslagen, wat resulteert in een lagere zoeklatentie en een groter aantal query's per seconde. Met deze extra kracht hoeft de beheerder mogelijk niet eens het aantal replica's te verhogen en mogelijk minder te betalen dan door in de S1-service te blijven.
Tip: Overweeg alternatieven voor reguliere expressiequery's
Reguliere expressiequery's of regex kunnen bijzonder duur zijn. Hoewel ze erg nuttig kunnen zijn voor geavanceerde zoekopdrachten, kan de uitvoering veel verwerkingskracht vereisen, vooral als de reguliere expressie ingewikkeld is of als u door een grote hoeveelheid gegevens zoekt. Al deze factoren dragen bij aan een hoge zoeklatentie. Probeer de reguliere expressie te vereenvoudigen of de complexe query op te splitsen in kleinere, beter beheerbare query's.
Volgende stappen
Bekijk deze andere artikelen met betrekking tot serviceprestaties: