Een index maken in Azure AI Search
In dit artikel leert u de stappen voor het definiëren van een schema voor een zoekindex en het pushen ervan naar een zoekservice. Als u een index maakt, worden de fysieke gegevensstructuren in uw zoekservice vastgelegd. Zodra de index bestaat, laadt u de index als een afzonderlijke taak.
Vereisten
Schrijfmachtigingen als inzender voor zoekservice of een beheerders-API-sleutel voor verificatie op basis van sleutels.
Inzicht in de gegevens die u wilt indexeren. Een zoekindex is gebaseerd op externe inhoud die u doorzoekbaar wilt maken. Doorzoekbare inhoud wordt opgeslagen als velden in een index. U moet een duidelijk beeld hebben van welke bronvelden u doorzoekbaar, ophaalbaar, filterbaar, facetable en sorteerbaar wilt maken in Azure AI Search. Zie de controlelijst voor schema's voor richtlijnen.
U moet ook een uniek veld hebben in brongegevens die kunnen worden gebruikt als documentsleutel (of id) in de index.
Een stabiele indexlocatie. Het verplaatsen van een bestaande index naar een andere zoekservice wordt niet standaard ondersteund. Ga opnieuw naar de toepassingsvereisten en zorg ervoor dat uw bestaande zoekservice (capaciteit en regio) voldoende is voor uw behoeften. Als u afhankelijk bent van Azure AI-services of Azure OpenAI, kiest u een regio die alle benodigde resources biedt.
Ten slotte hebben alle servicelagen indexlimieten voor het aantal objecten dat u kunt maken. Als u bijvoorbeeld experimenteert op de gratis laag, kunt u op elk gewenst moment slechts drie indexen hebben. Binnen de index zelf gelden limieten voor vectoren en indexlimieten voor het aantal eenvoudige en complexe velden.
Documentsleutels
Het maken van een zoekindex heeft twee vereisten: een index moet een unieke naam hebben voor de zoekservice en moet een documentsleutel hebben. Het booleaanse key kenmerk van een veld kan worden ingesteld op true om aan te geven welk veld de documentsleutel levert.
Een documentsleutel is de unieke id van een zoekdocument en een zoekdocument is een verzameling velden die iets volledig beschrijft. Als u bijvoorbeeld een filmset indexeert, bevat een zoekdocument de titel, het genre en de duur van één film. Filmnamen zijn uniek in deze gegevensset, dus u kunt de filmnaam gebruiken als documentsleutel.
In Azure AI Search is een documentsleutel een tekenreeks en moet deze afkomstig zijn van unieke waarden in de gegevensbron die de inhoud levert die moet worden geïndexeerd. In de regel genereert een zoekservice geen sleutelwaarden, maar in sommige scenario's (zoals de Indexeerfunctie voor Azure-tabellen) worden bestaande waarden gesyntheteerd om een unieke sleutel te maken voor de documenten die worden geïndexeerd. Een ander scenario is een-op-veel-indexering voor gesegmenteerde of gepartitioneerde gegevens. In dat geval worden documentsleutels voor elk segment gegenereerd.
Tijdens incrementele indexering, waarbij nieuwe en bijgewerkte inhoud wordt geïndexeerd, worden binnenkomende documenten met nieuwe sleutels toegevoegd, terwijl binnenkomende documenten met bestaande sleutels worden samengevoegd of overschreven, afhankelijk van of indexvelden null of ingevuld zijn.
Belangrijke punten over documentsleutels zijn onder andere:
- De maximale lengte van waarden in een sleutelveld is 1024 tekens.
- Precies één veld op het hoogste niveau in elke index moet worden gekozen als het sleutelveld en moet van het type
Edm.Stringzijn. - De standaardwaarde van het
keykenmerk is onwaar voor eenvoudige velden en null voor complexe velden.
Sleutelvelden kunnen worden gebruikt om documenten rechtstreeks op te zoeken en specifieke documenten bij te werken of te verwijderen. De waarden van sleutelvelden worden op een hoofdlettergevoelige manier verwerkt bij het opzoeken of indexeren van documenten. Zie GET Document (REST) en Index Documents (REST) voor meer informatie.
Controlelijst voor schema
Gebruik deze controlelijst om te helpen bij de ontwerpbeslissingen voor uw zoekindex.
Controleer naamconventies zodat index- en veldnamen voldoen aan de naamgevingsregels.
Raadpleeg ondersteunde gegevenstypen. Het gegevenstype heeft invloed op de manier waarop het veld wordt gebruikt. Numerieke inhoud kan bijvoorbeeld worden gefilterd, maar kan niet in volledige tekst worden doorzocht. Het meest voorkomende gegevenstype is
Edm.Stringvoor doorzoekbare tekst, die is getokeniseerd en opgevraagd met behulp van het zoekprogramma voor volledige tekst. Het meest voorkomende gegevenstype voor een vectorveld is,Edm.Singlemaar u kunt ook andere typen gebruiken.Een documentsleutel identificeren. Een documentsleutel is een indexvereiste. Het is één tekenreeksveld dat is ingevuld vanuit een brongegevensveld dat unieke waarden bevat. Als u bijvoorbeeld indexeert vanuit Blob Storage, wordt het opslagpad voor metagegevens vaak gebruikt als documentsleutel, omdat deze elke blob in de container een unieke id geeft.
Identificeer de velden in uw gegevensbron die doorzoekbare inhoud in de index bijdragen.
Doorzoekbare niet-ctorinhoud bevat korte of lange tekenreeksen die worden opgevraagd met behulp van de zoekprogramma voor volledige tekst. Als de inhoud is uitgebreid (kleine woordgroepen of grotere segmenten), experimenteert u met verschillende analyses om te zien hoe de tekst wordt getokeniseerd.
Doorzoekbare vectorinhoud kan afbeeldingen of tekst (in elke taal) zijn die bestaan als een wiskundige weergave. U kunt smalle gegevenstypen of vectorcompressie gebruiken om vectorvelden kleiner te maken.
Kenmerken die zijn ingesteld op velden, zoals
retrievableoffilterable, bepalen zowel zoekgedrag als de fysieke weergave van uw index in de zoekservice. Bepalen hoe velden moeten worden toegeschreven, is een iteratief proces voor veel ontwikkelaars. Als u iteraties wilt versnellen, begint u met voorbeeldgegevens, zodat u deze eenvoudig kunt verwijderen en opnieuw kunt opbouwen.Bepalen welke bronvelden kunnen worden gebruikt als filters. Numerieke inhoud en korte tekstvelden, met name velden met herhalende waarden, zijn goede keuzes. Wanneer u met filters werkt, moet u het volgende onthouden:
Filters kunnen worden gebruikt in vector- en niet-vectorquery's, maar het filter zelf wordt toegepast op door mensen leesbare (nietvector) velden in uw index.
Filterbare velden kunnen eventueel worden gebruikt in facetnavigatie.
Filterbare velden worden geretourneerd in willekeurige volgorde en ondergaan geen score voor relevantie, dus overweeg ze ook sorteerbaar te maken.
Geef voor vectorvelden een configuratie voor vectorzoekopdrachten op en de algoritmen die worden gebruikt voor het maken van navigatiepaden en het vullen van de insluitruimte. Zie Vectorvelden toevoegen voor meer informatie.
Vectorvelden hebben extra eigenschappen die niet-vectorvelden niet hebben, zoals welke algoritmen moeten worden gebruikt en vectorcompressie.
Vectorvelden laten kenmerken weg die niet nuttig zijn voor vectorgegevens, zoals sorteren, filteren en facet.
Voor niet-ctorvelden bepaalt u of u de standaardanalyse (
"analyzer": null) of een andere analyse wilt gebruiken. Analysefuncties worden gebruikt om tekstvelden te tokeniseren tijdens het indexeren en uitvoeren van query's.Voor meertalige tekenreeksen kunt u een taalanalyse overwegen.
Voor afbreekstreepjes of speciale tekens kunt u gespecialiseerde analyses overwegen. Een voorbeeld is een trefwoord dat de volledige inhoud van een veld als één token behandelt. Dit gedrag is handig voor gegevens zoals postcodes, id's en sommige productnamen. Zie Gedeeltelijke zoektermen en patronen met speciale tekens voor meer informatie.
Notitie
Zoekopdrachten in volledige tekst worden uitgevoerd voor termen die tijdens het indexeren worden tokeniseerd. Als uw query's de verwachte resultaten niet retourneren, test u op tokenisatie om te controleren of de tekenreeks die u zoekt, daadwerkelijk bestaat. U kunt verschillende analyses op tekenreeksen proberen om te zien hoe tokens worden geproduceerd voor verschillende analyses.
Velddefinities configureren
De verzameling velden definieert de structuur van een zoekdocument. Alle velden hebben een naam, gegevenstype en kenmerken.
Het instellen van een veld als doorzoekbaar, filterbaar, sorteerbaar of facetabel heeft een effect op de indexgrootte en queryprestaties. Stel deze kenmerken niet in voor velden waarnaar niet moet worden verwezen in query-expressies.
Als een veld niet is ingesteld op doorzoekbaar, filterbaar, sorteerbaar of facetabel, kan het veld niet worden verwezen in een query-expressie. Dit is wenselijk voor velden die niet worden gebruikt in query's, maar die wel nodig zijn in zoekresultaten.
De REST API's hebben standaardtoewijzing op basis van gegevenstypen, die ook worden gebruikt door de wizard Importeren in Azure Portal. De Azure-SDK's hebben geen standaardinstellingen, maar ze hebben veldsubklassen die eigenschappen en gedrag bevatten, zoals SearchableField voor tekenreeksen en SimpleField voor primitieven.
Standaardveldtoewijzingen voor de REST API's worden samengevat in de volgende tabel.
| Gegevenstype | Zoekbaar | Ophaalbaar | Filterbaar | Facetten mogelijk | Sorteerbaar | Opgeslagen |
|---|---|---|---|---|---|---|
Edm.String |
✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
Collection(Edm.String) |
✅ | ✅ | ✅ | ✅ | ❌ | ✅ |
Edm.Boolean |
❌ | ✅ | ✅ | ✅ | ✅ | ✅ |
Edm.Int32, , Edm.Int64Edm.Double |
❌ | ✅ | ✅ | ✅ | ✅ | ✅ |
Edm.DateTimeOffset |
❌ | ✅ | ✅ | ✅ | ✅ | ✅ |
Edm.GeographyPoint |
✅ | ✅ | ✅ | ❌ | ✅ | ✅ |
Edm.ComplexType |
✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
Collection(Edm.Single) en alle andere vectorveldtypen |
✅ | ✅ of ❌ | ❌ | ❌ | ❌ | ✅ |
Tekenreeksvelden kunnen ook worden gekoppeld aan analyses en synoniemenkaarten. Velden van het type Edm.String die filterbaar, sorteerbaar of facetabel zijn, kunnen maximaal 32 kilobytes lang zijn. Dit komt doordat waarden van dergelijke velden worden behandeld als één zoekterm en de maximale lengte van een term in Azure AI Search 32 kilobytes is. Als u meer tekst wilt opslaan dan dit in één tekenreeksveld, moet u expliciet filterbaar, sorteerbaar en facetabel false instellen op in uw indexdefinitie.
Vectorvelden moeten worden gekoppeld aan dimensies en vectorprofielen. De standaardinstelling voor ophalen is waar als u het vectorveld toevoegt met behulp van de wizard Importeren en vectoriseren in Azure Portal, anders is deze onwaar als u de REST API gebruikt.
Veldkenmerken worden beschreven in de volgende tabel.
| Kenmerk | Beschrijving |
|---|---|
| naam | Vereist. Hiermee stelt u de naam van het veld in, die uniek moet zijn binnen de veldenverzameling van het index- of bovenliggende veld. |
| type | Vereist. Hiermee stelt u het gegevenstype voor het veld in. Velden kunnen eenvoudig of complex zijn. Eenvoudige velden zijn primitieve typen, zoals Edm.String voor tekst of Edm.Int32 voor gehele getallen. Complexe velden kunnen subvelden bevatten die zichzelf eenvoudig of complex zijn. Hiermee kunt u objecten en matrices van objecten modelleren, waardoor u de meeste JSON-objectstructuren naar uw index kunt uploaden. Zie Ondersteunde gegevenstypen voor de volledige lijst met ondersteunde typen. |
| sleutel | Vereist. Stel dit kenmerk in op true om aan te geven dat de waarden van een veld de documenten in de index uniek identificeren. Zie Documentsleutels in dit artikel voor meer informatie. |
| retrievable | Hiermee wordt aangegeven of het veld kan worden geretourneerd in een zoekresultaat. Stel dit kenmerk in op false als u een veld wilt gebruiken als filter-, sorteer- of scoremechanisme, maar niet wilt dat het veld zichtbaar is voor de eindgebruiker. Dit kenmerk moet voor sleutelvelden zijn true en moet voor complexe velden zijn null . Dit kenmerk kan worden gewijzigd voor bestaande velden. Het instellen dat kan worden opgehaald, true veroorzaakt geen toename van de opslagvereisten voor indexen. De standaardwaarde is true voor eenvoudige velden en null voor complexe velden. |
| doorzoekbaar | Geeft aan of het veld doorzoekbaar is in volledige tekst en waarnaar kan worden verwezen in zoekquery's. Dit betekent dat het lexicale analyses ondergaat, zoals woordbreking tijdens het indexeren. Als u een doorzoekbaar veld instelt op een waarde zoals 'Zonnige dag', wordt het intern genormaliseerd in de afzonderlijke tokens 'zonnig' en 'dag'. Hiermee kunt u zoeken in volledige tekst naar deze termen. Velden van het type Edm.String of Collection(Edm.String) kunnen standaard worden doorzocht. Dit kenmerk moet zijn false voor eenvoudige velden van andere niet-getekende gegevenstypen en moet voor complexe velden zijn null . Een doorzoekbaar veld verbruikt extra ruimte in uw index omdat Azure AI Search de inhoud van deze velden verwerkt en ordent in hulpgegevensstructuren voor het uitvoeren van zoekopdrachten. Als u ruimte wilt besparen in uw index en u geen veld nodig hebt om te worden opgenomen in zoekopdrachten, stelt u doorzoekbaar in op false. Zie Hoe zoeken in volledige tekst werkt in Azure AI Search voor meer informatie. |
| filteren mogelijk | Hiermee wordt aangegeven of naar het veld moet worden verwezen in $filter query's. Filterbaar verschilt van doorzoekbaar in de manier waarop tekenreeksen worden verwerkt. Velden van het type Edm.String of Collection(Edm.String) die filterbaar zijn, ondergaan geen lexicale analyse, dus vergelijkingen zijn alleen voor exacte overeenkomsten. Als u bijvoorbeeld een dergelijk veld f instelt op 'Sunny day', $filter=f eq 'sunny' vindt u geen overeenkomsten, maar $filter=f eq 'Sunny day' wel. Dit kenmerk moet voor complexe velden zijn null . De standaardwaarde is true voor eenvoudige velden en null voor complexe velden. Als u de indexgrootte wilt verkleinen, stelt u dit kenmerk false in op velden waarop u niet wilt filteren. |
| sorteerbaar | Hiermee wordt aangegeven of naar het veld moet worden verwezen in $orderby expressies. Standaard sorteert Azure AI Search resultaten op score, maar in veel ervaringen willen gebruikers sorteren op velden in de documenten. Een eenvoudig veld kan alleen worden gesorteerd als het één waarde heeft (het heeft één waarde in het bereik van het bovenliggende document). Eenvoudige verzamelingsvelden kunnen niet worden gesorteerd, omdat ze meerdere waarden hebben. Eenvoudige subvelden van complexe verzamelingen zijn ook meerdere waarden en kunnen daarom niet worden gesorteerd. Dit is waar, of het nu een direct bovenliggend veld of een bovenliggend veld is, dat is de complexe verzameling. Complexe velden kunnen niet worden gesorteerd en het sorteerbare kenmerk moet voor dergelijke velden zijn null . De standaardinstelling voor sorteerbaar is true voor eenvoudige velden met één waarde, false voor eenvoudige velden met meerdere waarden en null voor complexe velden. |
| facetable | Hiermee wordt aangegeven of naar het veld moet worden verwezen in facetquery's. Meestal gebruikt in een presentatie van zoekresultaten met hit count per categorie (bijvoorbeeld zoeken naar digitale camera's en treffers per merk, per megapixel, prijs, enzovoort). Dit kenmerk moet voor complexe velden zijn null . Velden van het type Edm.GeographyPoint of Collection(Edm.GeographyPoint) kunnen niet worden ge facetbaar. De standaardwaarde is true voor alle andere eenvoudige velden. Als u de indexgrootte wilt verkleinen, stelt u dit kenmerk false in op velden waarop u geen facet wilt toepassen. |
| analyzer | Hiermee stelt u de lexical analyzer in voor het tokeniseren van tekenreeksen tijdens het indexeren en querybewerkingen. Geldige waarden voor deze eigenschap zijn taalanalyses, ingebouwde analyses en aangepaste analyse. De standaardwaarde is standard.lucene. Dit kenmerk kan alleen worden gebruikt met doorzoekbare tekenreeksvelden en kan niet samen met searchAnalyzer of indexAnalyzer worden ingesteld. Zodra de analyse is gekozen en het veld in de index is gemaakt, kan het niet worden gewijzigd voor het veld. Moet voor complexe velden zijnnull. |
| searchAnalyzer | Stel deze eigenschap samen met indexAnalyzer in om verschillende lexicale analysefuncties voor indexering en query's op te geven. Als u deze eigenschap gebruikt, stelt u analyzer in op null indexAnalyzer en zorgt u ervoor dat indexAnalyzer is ingesteld op een toegestane waarde. Geldige waarden voor deze eigenschap zijn ingebouwde analyses en aangepaste analyses. Dit kenmerk kan alleen worden gebruikt met doorzoekbare velden. De zoekanalyse kan worden bijgewerkt op een bestaand veld, omdat deze alleen wordt gebruikt tijdens het uitvoeren van query's. Moet voor complexe velden zijn null ]. |
| indexAnalyzer | Stel deze eigenschap samen met searchAnalyzer in om verschillende lexicale analysefuncties voor indexering en query's op te geven. Als u deze eigenschap gebruikt, stelt u analyzer in en null zorgt u ervoor dat searchAnalyzer is ingesteld op een toegestane waarde. Geldige waarden voor deze eigenschap zijn ingebouwde analyses en aangepaste analyses. Dit kenmerk kan alleen worden gebruikt met doorzoekbare velden. Zodra de indexanalyse is gekozen, kan deze niet meer worden gewijzigd voor het veld. Moet voor complexe velden zijn null . |
| synoniemmaps | Een lijst met de namen van synoniemen die aan dit veld moeten worden gekoppeld. Dit kenmerk kan alleen worden gebruikt met doorzoekbare velden. Op dit moment wordt slechts één synoniemenkaart per veld ondersteund. Als u een synoniemtoewijzing toewijst aan een veld, zorgt u ervoor dat querytermen die gericht zijn op dat veld tijdens query's worden uitgebreid met behulp van de regels in de synoniementoewijzing. Dit kenmerk kan worden gewijzigd voor bestaande velden. null Moet of een lege verzameling zijn voor complexe velden. |
| velden | Een lijst met subvelden als dit een veld van het type Edm.ComplexType of Collection(Edm.ComplexType). Moet leeg of leeg zijn null voor eenvoudige velden. Zie Complexe gegevenstypen modelleren in Azure AI Search voor meer informatie over hoe en wanneer subvelden moeten worden gebruikt. |
Een index maken
Wanneer u klaar bent om de index te maken, gebruikt u een zoekclient die de aanvraag kan verzenden. U kunt Azure Portal of REST API's gebruiken voor vroege ontwikkeling en proof-of-concept-tests, anders is het gebruikelijk om de Azure SDK's te gebruiken.
Plan tijdens de ontwikkeling regelmatig herbouwen. Omdat fysieke structuren in de service worden gemaakt, zijn het verwijderen en opnieuw maken van indexen nodig voor veel wijzigingen. U kunt overwegen om met een subset van uw gegevens te werken om herbouwen sneller te laten verlopen.
Indexontwerp via Azure Portal dwingt vereisten en schemaregels af voor specifieke gegevenstypen, zoals het ongedaan maken van de toewijzing van zoekmogelijkheden voor volledige tekst op numerieke velden.
Meld u aan bij het Azure-portaal.
Controleer of er ruimte is. Search-service zijn onderworpen aan het maximum aantal indexen, variërend per servicelaag. Zorg ervoor dat u ruimte hebt voor een tweede index.
Kies op de pagina Overzicht van de zoekservice een van de opties voor het maken van een zoekindex:
- Index toevoegen, een ingesloten editor voor het opgeven van een indexschema
- Wizards importeren
De wizard is een end-to-end werkstroom waarmee een indexeerfunctie, een gegevensbron en een voltooide index worden gemaakt. De gegevens worden ook geladen. Als dit meer is dan wat u wilt, gebruikt u in plaats daarvan Index toevoegen.
In de volgende schermopname ziet u waar index toevoegen, gegevens importeren en gegevens importeren en vectoriseren worden weergegeven op de opdrachtbalk.
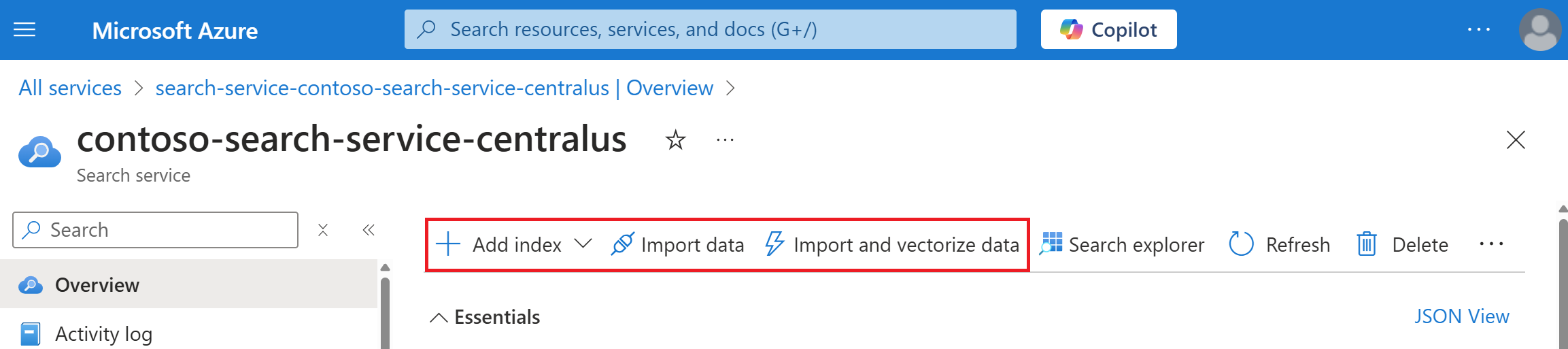
Nadat een index is gemaakt, kunt u deze opnieuw vinden op de pagina Indexen in het linkernavigatiedeelvenster.
Tip
Nadat u een index hebt gemaakt in Azure Portal, kunt u de JSON-weergave kopiëren en toevoegen aan uw toepassingscode.
Instellen corsOptions voor cross-origin-query's
Indexschema's bevatten een sectie voor het instellen corsOptions. JavaScript aan de clientzijde kan standaard geen API's aanroepen, omdat browsers alle cross-origin-aanvragen voorkomen. Als u cross-origin-query's naar uw index wilt toestaan, schakelt u CORS (Cross-Origin Resource Sharing) in door het kenmerk corsOptions in te stellen. Om veiligheidsredenen bieden alleen query-API's ondersteuning voor CORS.
"corsOptions": {
"allowedOrigins": [
"*"
],
"maxAgeInSeconds": 300
De volgende eigenschappen kunnen worden ingesteld voor CORS:
allowedOrigins (vereist): Dit is een lijst met oorsprongen die toegang hebben tot uw index. JavaScript-code die vanaf deze oorsprongen wordt geleverd, mag een query uitvoeren op uw index (ervan uitgaande dat de aanroeper een geldige sleutel biedt of machtigingen heeft). Elke oorsprong is meestal van de vorm
protocol://<fully-qualified-domain-name>:<port>, hoewel<port>deze vaak wordt weggelaten. Zie Cross-origin resource sharing (Wikipedia) voor meer informatie.Als u toegang tot alle origins wilt toestaan, neemt
*u deze op als één item in de matrix allowedOrigins . Dit is geen aanbevolen procedure voor productiezoekservices , maar dit is vaak handig voor ontwikkeling en foutopsporing.maxAgeInSeconds (optioneel): Browsers gebruiken deze waarde om de duur (in seconden) te bepalen voor het opslaan van CORS-preflight-antwoorden. Dit moet een niet-negatief geheel getal zijn. Een langere cacheperiode levert betere prestaties, maar het verlengt de hoeveelheid tijd die een CORS-beleid moet uitvoeren. Als deze waarde niet is ingesteld, wordt een standaardduur van vijf minuten gebruikt.
Toegestane updates voor bestaande indexen
Met Index maken worden de fysieke gegevensstructuren (bestanden en omgekeerde indexen) in uw zoekservice gemaakt. Zodra de index is gemaakt, is de mogelijkheid om wijzigingen door te voeren met behulp van Create of Update Index afhankelijk van of uw wijzigingen deze fysieke structuren ongeldig maken. De meeste veldkenmerken kunnen niet worden gewijzigd zodra het veld in uw index is gemaakt.
Als u het verloop in de toepassingscode wilt minimaliseren, kunt u een indexalias maken die fungeert als een stabiele verwijzing naar de zoekindex. In plaats van uw code bij te werken met indexnamen, kunt u een indexalias bijwerken zodat deze verwijst naar nieuwere indexversies.
Om het verloop in het ontwerpproces te minimaliseren, wordt in de volgende tabel beschreven welke elementen vast en flexibel zijn in het schema. Voor het wijzigen van een vast element moet een index opnieuw worden opgebouwd, terwijl flexibele elementen op elk gewenst moment kunnen worden gewijzigd zonder dat dit van invloed is op de fysieke implementatie. Zie Een index bijwerken of herbouwen voor meer informatie.
| Element | Kan worden bijgewerkt? |
|---|---|
| Naam | Nee |
| Sleutel | Nee |
| Veldnamen en -typen | Nee |
| Veldkenmerken (doorzoekbaar, filterbaar, facetable, sorteerbaar) | Nee |
| Veldkenmerk (ophaalbaar) | Ja |
| Opgeslagen (van toepassing op vectoren) | Nee |
| Analyzer | U kunt aangepaste analysefuncties toevoegen en wijzigen in de index. Met betrekking tot analysetoewijzingen voor tekenreeksvelden kunt u alleen wijzigen searchAnalyzer. Alle andere toewijzingen en wijzigingen vereisen een herbouw. |
| Scoreprofielen | Ja |
| Suggesties | Nee |
| cross-origin resource sharing (CORS) | Ja |
| Versleuteling | Ja |
| Synoniemenkaarten | Ja |
| Semantische configuratie | Ja |
Volgende stappen
Gebruik de volgende koppelingen voor meer informatie over gespecialiseerde functies die kunnen worden toegevoegd aan een index:
- Vectorvelden en vectorprofielen toevoegen
- Scoreprofielen toevoegen
- Semantische rangschikking toevoegen
- Suggesties toevoegen
- Synoniemenkaarten toevoegen
- Analyseanalyses toevoegen
- Versleuteling toevoegen
Gebruik deze koppelingen voor het laden of bijwerken van een index: