Tekst en informatie extraheren uit afbeeldingen met behulp van AI-verrijking
Dankzij AI-verrijking biedt Azure AI Search u verschillende opties voor het maken en extraheren van doorzoekbare tekst uit afbeeldingen, waaronder:
- OCR voor optische tekenherkenning van tekst en cijfers
- Afbeeldingsanalyse waarin afbeeldingen worden beschreven via visuele functies
- Aangepaste vaardigheden voor het aanroepen van externe afbeeldingsverwerking die u wilt bieden
Met OCR kunt u tekst extraheren en uit foto's of afbeeldingen, zoals het woord STOP in een stopteken. Met behulp van afbeeldingsanalyse kunt u een tekstweergave van een afbeelding genereren, zoals paardenbloem voor een foto van een paardenbloem of de kleur geel. U kunt ook metagegevens over de afbeelding extraheren, zoals de grootte.
In dit artikel worden de basisprincipes van het werken met afbeeldingen beschreven en worden ook verschillende veelvoorkomende scenario's beschreven, zoals het werken met ingesloten afbeeldingen, aangepaste vaardigheden en het overlayen van visualisaties op oorspronkelijke afbeeldingen.
Als u met afbeeldingsinhoud in een vaardighedenset wilt werken, hebt u het volgende nodig:
- Bronbestanden met afbeeldingen
- Een zoekindexeerfunctie die is geconfigureerd voor afbeeldingsacties
- Een vaardighedenset met ingebouwde of aangepaste vaardigheden die OCR- of afbeeldingsanalyse aanroepen
- Een zoekindex met velden om de geanalyseerde tekstuitvoer te ontvangen, plus uitvoerveldtoewijzingen in de indexeerfunctie die koppeling tot stand brengen
U kunt eventueel projecties definiëren om door afbeeldingen geanalyseerde uitvoer te accepteren in een kennisarchief voor scenario's voor gegevensanalyse.
Bronbestanden instellen
Afbeeldingsverwerking is indexeerfunctiegestuurd, wat betekent dat de onbewerkte invoer in een ondersteunde gegevensbron moet staan.
- Afbeeldingsanalyse ondersteunt JPEG, PNG, GIF en BMP
- OCR ondersteunt JPEG, PNG, BMP en TIF
Afbeeldingen zijn zelfstandige binaire bestanden of ingesloten in documenten, zoals PDF-, RTF- of Microsoft-toepassingsbestanden. Er kunnen maximaal 1000 afbeeldingen worden geëxtraheerd uit een bepaald document. Als er meer dan 1000 afbeeldingen in een document staan, worden de eerste 1000 geëxtraheerd en wordt er een waarschuwing gegenereerd.
Azure Blob Storage is de meest gebruikte opslag voor afbeeldingsverwerking in Azure AI Search. Er zijn drie hoofdtaken met betrekking tot het ophalen van afbeeldingen uit een blobcontainer:
Toegang tot inhoud in de container inschakelen. Als u een volledige toegang gebruikt verbindingsreeks die een sleutel bevat, geeft de sleutel u toestemming voor de inhoud. U kunt ook verifiëren met behulp van Microsoft Entra ID of verbinding maken als een vertrouwde service.
Maak een gegevensbron van het type azureblob die verbinding maakt met de blobcontainer die uw bestanden opslaat.
Controleer de servicelaaglimieten om ervoor te zorgen dat uw brongegevens onder de maximale grootte en hoeveelheidslimieten vallen voor indexeerfuncties en verrijking.
Indexeerfuncties configureren voor afbeeldingsverwerking
Nadat de bronbestanden zijn ingesteld, schakelt u normalisatie van installatiekopieën in door de parameter in de configuratie van de imageAction indexeerfunctie in te stellen. Normalisatie van afbeeldingen helpt afbeeldingen uniformer te maken voor downstreamverwerking. Afbeeldingsnormalisatie omvat de volgende bewerkingen:
- Grote afbeeldingen worden aangepast tot een maximale hoogte en breedte om ze uniform te maken.
- Voor afbeeldingen met metagegevens die de afdrukstand aangeeft, wordt de draaiing van afbeeldingen aangepast voor verticaal laden.
Aanpassingen van metagegevens worden vastgelegd in een complex type dat voor elke afbeelding is gemaakt. U kunt zich niet afmelden voor de normalisatievereiste voor afbeeldingen. Vaardigheden voor het herhalen van afbeeldingen, zoals OCR en afbeeldingsanalyse, verwachten genormaliseerde afbeeldingen.
Een indexeerfunctie maken of bijwerken om de configuratie-eigenschappen in te stellen:
{ "parameters": { "configuration": { "dataToExtract": "contentAndMetadata", "parsingMode": "default", "imageAction": "generateNormalizedImages" } } }Ingesteld
dataToExtractopcontentAndMetadata(vereist).Controleer of de
parsingModestandaardwaarde is ingesteld(vereist).Deze parameter bepaalt de granulariteit van zoekdocumenten die in de index zijn gemaakt. In de standaardmodus wordt een een-op-een-correspondentie ingesteld, zodat één blob in één zoekdocument resulteert. Als documenten groot zijn of als vaardigheden kleinere stukken tekst vereisen, kunt u de vaardigheid Tekst splitsen toevoegen die een document onderverdeelt voor verwerkingsdoeleinden. Maar voor zoekscenario's is één blob per document vereist als verrijking afbeeldingsverwerking omvat.
Instellen
imageActionom hetnormalized_imagesknooppunt in te schakelen in een verrijkingsstructuur (vereist):generateNormalizedImagesom een matrix van genormaliseerde afbeeldingen te genereren als onderdeel van het kraken van documenten.generateNormalizedImagePerPage(alleen van toepassing op PDF) om een matrix met genormaliseerde afbeeldingen te genereren waarbij elke pagina in het PDF-bestand wordt weergegeven op één uitvoerafbeelding. Voor niet-PDF-bestanden is het gedrag van deze parameter vergelijkbaar alsof u hebt ingesteldgenerateNormalizedImages. De instellinggenerateNormalizedImagePerPagekan er echter voor zorgen dat indexeringsbewerking minder goed presteert (met name voor grote documenten), omdat er verschillende afbeeldingen moeten worden gegenereerd.
U kunt desgewenst de breedte of hoogte van de gegenereerde genormaliseerde afbeeldingen aanpassen:
normalizedImageMaxWidthin pixels. De standaardwaarde is 2000. De maximumwaarde is 10.000.normalizedImageMaxHeightin pixels. De standaardwaarde is 2000. De maximumwaarde is 10.000.
De standaardwaarde van 2000 pixels voor de genormaliseerde afbeeldingen is gebaseerd op de maximale grootten die worden ondersteund door de OCR-vaardigheid en de vaardigheid afbeeldingsanalyse. De OCR-vaardigheid ondersteunt een maximale breedte en hoogte van 4.200 voor niet-Engelse talen en 10.000 voor Engels. Als u de maximale limieten verhoogt, kan de verwerking mislukken op grotere afbeeldingen, afhankelijk van de definitie van uw vaardighedenset en de taal van de documenten.
U kunt desgewenst criteria voor bestandstypen instellen als de werkbelasting is gericht op een specifiek bestandstype. De configuratie van de blobindexeerfunctie bevat instellingen voor het opnemen van bestanden en uitsluitingen. U kunt bestanden uitfilteren die u niet wilt.
{ "parameters" : { "configuration" : { "indexedFileNameExtensions" : ".pdf, .docx", "excludedFileNameExtensions" : ".png, .jpeg" } } }
Over genormaliseerde afbeeldingen
Wanneer imageAction dit is ingesteld op een andere waarde dan geen, bevat het nieuwe normalized_images veld een matrix met afbeeldingen. Elke afbeelding is een complex type met de volgende leden:
| Lid van installatiekopieën | Beschrijving |
|---|---|
| gegevens | Met BASE64 gecodeerde tekenreeks van de genormaliseerde afbeelding in JPEG-indeling. |
| width | Breedte van de genormaliseerde afbeelding in pixels. |
| height | Hoogte van de genormaliseerde afbeelding in pixels. |
| originalWidth | De oorspronkelijke breedte van de afbeelding vóór normalisatie. |
| originalHeight | De oorspronkelijke hoogte van de afbeelding vóór normalisatie. |
| rotatieFromOriginal | Draaiing met de klok mee in graden die plaatsvonden om de genormaliseerde afbeelding te maken. Een waarde tussen 0 graden en 360 graden. In deze stap worden de metagegevens gelezen van de afbeelding die wordt gegenereerd door een camera of scanner. Meestal een veelvoud van 90 graden. |
| contentOffset | Het tekenverschil in het inhoudsveld waaruit de afbeelding is geëxtraheerd. Dit veld is alleen van toepassing op bestanden met ingesloten afbeeldingen. De contentOffset voor afbeeldingen die zijn geëxtraheerd uit PDF-documenten, bevindt zich altijd aan het einde van de tekst op de pagina waaruit deze in het document is geëxtraheerd. Dit betekent dat afbeeldingen na alle tekst op die pagina worden weergegeven, ongeacht de oorspronkelijke locatie van de afbeelding op de pagina. |
| pageNumber | Als de afbeelding is geëxtraheerd of weergegeven uit een PDF, bevat dit veld het paginanummer in het PDF-bestand dat is geëxtraheerd of weergegeven vanaf 1. Als de afbeelding niet afkomstig is van een PDF,is dit veld 0. |
Voorbeeldwaarde van normalized_images:
[
{
"data": "BASE64 ENCODED STRING OF A JPEG IMAGE",
"width": 500,
"height": 300,
"originalWidth": 5000,
"originalHeight": 3000,
"rotationFromOriginal": 90,
"contentOffset": 500,
"pageNumber": 2
}
]
Vaardighedensets definiëren voor afbeeldingsverwerking
Deze sectie vormt een aanvulling op de artikelen over vaardigheidsverwijzingen door context te bieden voor het werken met vaardigheidsinvoer, uitvoer en patronen, zoals ze betrekking hebben op afbeeldingsverwerking.
Een vaardighedenset maken of bijwerken om vaardigheden toe te voegen.
Voeg sjablonen toe voor OCR en Afbeeldingsanalyse vanuit Azure Portal of kopieer de definities uit de referentiedocumentatie voor vaardigheden. Voeg deze in de vaardighedenmatrix van uw vaardighedensetdefinitie in.
Neem indien nodig een sleutel voor meerdere services op in de eigenschap Azure AI-services van de vaardighedenset. Azure AI Search roept aan naar een factureerbare Azure AI-servicesresource voor OCR en afbeeldingsanalyse voor transacties die de gratis limiet overschrijden (20 per indexeerfunctie per dag). Azure AI-services moeten zich in dezelfde regio bevinden als uw zoekservice.
Als oorspronkelijke afbeeldingen zijn ingesloten in PDF- of toepassingsbestanden zoals PPTX of DOCX, moet u een vaardigheid tekst samenvoegen toevoegen als u de afbeeldingsuitvoer en tekstuitvoer wilt samenvoegen. Het werken met ingesloten afbeeldingen wordt verder besproken in dit artikel.
Zodra het basisframework van uw vaardighedenset is gemaakt en Azure AI-services zijn geconfigureerd, kunt u zich richten op elke afzonderlijke afbeeldingsvaardigheid, invoer en broncontext definiëren en uitvoer toewijzen aan velden in een index of kennisarchief.
Notitie
Zie REST-zelfstudie: REST en AI gebruiken om doorzoekbare inhoud van Azure-blobs te genereren voor een voorbeeld van een set vaardigheden die afbeeldingsverwerking combineert met downstream natuurlijke taalverwerking. Het laat zien hoe u de uitvoer van vaardigheidsafbeeldingen invoert in entiteitsherkenning en sleuteltermextractie.
Invoer voor afbeeldingsverwerking
Zoals vermeld, worden afbeeldingen geëxtraheerd tijdens het kraken van documenten en vervolgens genormaliseerd als een voorbereidende stap. De genormaliseerde afbeeldingen zijn de invoer voor elke vaardigheid voor het verwerken van afbeeldingen en worden altijd op twee manieren weergegeven in een verrijkte documentstructuur:
/document/normalized_images/*is bedoeld voor documenten die geheel worden verwerkt./document/normalized_images/*/pagesis bedoeld voor documenten die worden verwerkt in segmenten (pagina's).
Of u nu OCR en afbeeldingsanalyse in hetzelfde gebruikt, invoer heeft vrijwel dezelfde constructie:
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
},
{
"@odata.type": "#Microsoft.Skills.Vision.ImageAnalysisSkill",
"context": "/document/normalized_images/*",
"visualFeatures": [ "tags", "description" ],
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
}
Uitvoer toewijzen aan zoekvelden
In een vaardighedenset is uitvoer van afbeeldingenanalyse en OCR-vaardigheid altijd tekst. Uitvoertekst wordt weergegeven als knooppunten in een interne verrijkte documentstructuur en elk knooppunt moet worden toegewezen aan velden in een zoekindex of aan projecties in een kennisarchief om de inhoud beschikbaar te maken in uw app.
Bekijk in de vaardighedenset de
outputssectie van elke vaardigheid om te bepalen welke knooppunten aanwezig zijn in het verrijkte document:{ "@odata.type": "#Microsoft.Skills.Vision.OcrSkill", "context": "/document/normalized_images/*", "detectOrientation": true, "inputs": [ ], "outputs": [ { "name": "text", "targetName": "text" }, { "name": "layoutText", "targetName": "layoutText" } ] }Maak of werk een zoekindex bij om velden toe te voegen om de uitvoer van vaardigheden te accepteren.
In het volgende voorbeeld van de veldenverzameling is inhoud blobinhoud . Metadata_storage_name bevat de naam van het bestand (ingesteld op
retrievablewaar). Metadata_storage_path is het unieke pad van de blob en de standaarddocumentsleutel. Merged_content is uitvoer van Tekst samenvoegen (handig wanneer afbeeldingen zijn ingesloten).Tekst en layoutText zijn OCR-vaardigheidsuitvoer en moeten een tekenreeksverzameling zijn om alle door OCR gegenereerde uitvoer voor het hele document vast te leggen.
"fields": [ { "name": "content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_name", "type": "Edm.String", "filterable": true, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_path", "type": "Edm.String", "filterable": false, "key": true, "retrievable": true, "searchable": false, "sortable": false }, { "name": "merged_content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "text", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true }, { "name": "layoutText", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true } ],Werk de indexeerfunctie bij om de uitvoer van vaardighedensets (knooppunten in een verrijkingsstructuur) toe te wijzen aan indexvelden.
Verrijkte documenten zijn intern. Als u de knooppunten in een verrijkte documentstructuur wilt externaliseren, stelt u een toewijzing van uitvoervelden in waarmee wordt opgegeven welk indexveld knooppuntinhoud ontvangt. Verrijkte gegevens worden door uw app geopend via een indexveld. In het volgende voorbeeld ziet u een tekstknooppunt (OCR-uitvoer) in een verrijkt document dat is toegewezen aan een tekstveld in een zoekindex.
"outputFieldMappings": [ { "sourceFieldName": "/document/normalized_images/*/text", "targetFieldName": "text" }, { "sourceFieldName": "/document/normalized_images/*/layoutText", "targetFieldName": "layoutText" } ]Voer de indexeerfunctie uit om brondocument ophalen, afbeeldingsverwerking en indexering aan te roepen.
Resultaten controleren
Voer een query uit op de index om de resultaten van afbeeldingsverwerking te controleren. Gebruik Search Explorer als zoekclient of een hulpprogramma waarmee HTTP-aanvragen worden verzonden. De volgende query selecteert velden die de uitvoer van afbeeldingsverwerking bevatten.
POST /indexes/[index name]/docs/search?api-version=[api-version]
{
"search": "*",
"select": "metadata_storage_name, text, layoutText, imageCaption, imageTags"
}
OCR herkent tekst in afbeeldingsbestanden. Dit betekent dat OCR-velden (tekst en layoutText) leeg zijn als brondocumenten pure tekst of pure afbeeldingen zijn. Op dezelfde manier zijn afbeeldingsanalysevelden (imageCaption en imageTags) leeg als brondocumentinvoer strikt tekst is. De uitvoering van de indexeerfunctie verzendt waarschuwingen als de invoer van afbeeldingen leeg is. Dergelijke waarschuwingen worden verwacht wanneer knooppunten niet worden ingevuld in het verrijkte document. Zoals u zich herinnert, kunt u met blobindexering bestandstypen opnemen of uitsluiten als u wilt werken met inhoudstypen in isolatie. U kunt deze instellingen gebruiken om ruis te verminderen tijdens uitvoeringen van de indexeerfunctie.
Een alternatieve query voor het controleren van resultaten kan de inhoud en merged_content velden bevatten. U ziet dat deze velden inhoud bevatten voor een blobbestand, zelfs de velden waar geen afbeeldingsverwerking is uitgevoerd.
Over uitvoer van vaardigheden
Uitvoer van vaardigheden zijn onder andere text (OCR), layoutText (OCR), merged_content( captions afbeeldingsanalyse), tags (afbeeldingsanalyse):
textslaat door OCR gegenereerde uitvoer op. Dit knooppunt moet worden toegewezen aan het veld van het typeCollection(Edm.String). Er is ééntextveld per zoekdocument dat bestaat uit door komma's gescheiden tekenreeksen voor documenten die meerdere afbeeldingen bevatten. In de volgende afbeelding ziet u OCR-uitvoer voor drie documenten. Ten eerste is een document met een bestand zonder afbeeldingen. Ten tweede is een document (afbeeldingsbestand) met één woord, Microsoft. Ten derde is een document met meerdere afbeeldingen, sommige zonder tekst ("",)."value": [ { "@search.score": 1, "metadata_storage_name": "facts-about-microsoft.html", "text": [] }, { "@search.score": 1, "metadata_storage_name": "guthrie.jpg", "text": [ "Microsoft" ] }, { "@search.score": 1, "metadata_storage_name": "Azure AI services and Content Intelligence.pptx", "text": [ "", "Microsoft", "", "", "", "Azure AI Search and Augmentation Combining Microsoft Azure AI services and Azure Search" ] } ]layoutTextslaat door OCR gegenereerde informatie op over tekstlocatie op de pagina, zoals wordt beschreven in begrenzingsvakken en coördinaten van de genormaliseerde afbeelding. Dit knooppunt moet worden toegewezen aan het veld van het typeCollection(Edm.String). Er is éénlayoutTextveld per zoekdocument dat bestaat uit door komma's gescheiden tekenreeksen.merged_contentslaat de uitvoer van een vaardigheid Tekst samenvoegen op en het moet een groot veld van het typeEdm.Stringzijn dat onbewerkte tekst uit het brondocument bevat, met ingeslotentextin plaats van een afbeelding. Als bestanden alleen tekst zijn, hebben OCR en afbeeldingsanalyse niets te doen enmerged_contentis hetzelfde alscontent(een blobeigenschap die de inhoud van de blob bevat).imageCaptionlegt een beschrijving van een afbeelding vast als afzonderlijke tags en een langere tekstbeschrijving.imageTagsslaat tags over een afbeelding op als een verzameling trefwoorden, één verzameling voor alle afbeeldingen in het brondocument.
De volgende schermafbeelding is een afbeelding van een PDF met tekst en ingesloten afbeeldingen. Document kraken heeft drie ingesloten afbeeldingen gedetecteerd: zwerm van zeegullen, kaart, adelaar. Andere tekst in het voorbeeld (inclusief titels, koppen en hoofdtekst) is geëxtraheerd als tekst en uitgesloten van afbeeldingsverwerking.
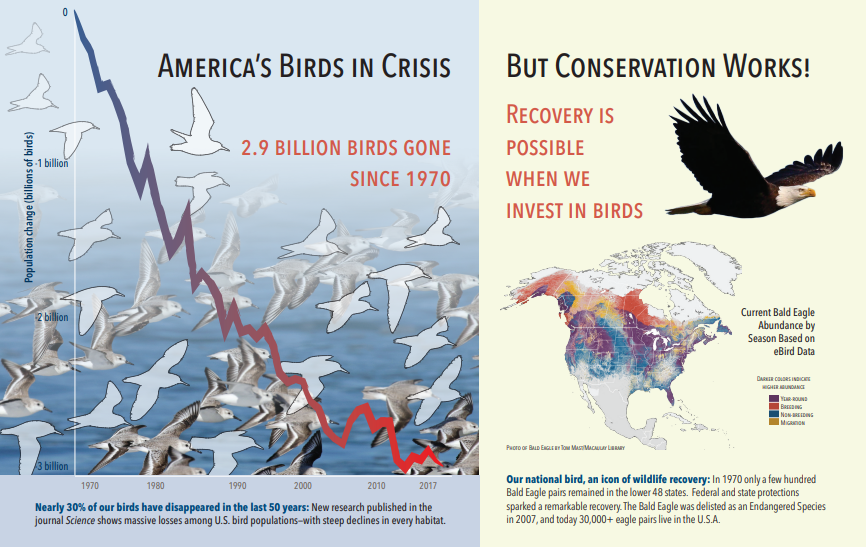
Uitvoer van afbeeldingsanalyse wordt geïllustreerd in de volgende JSON (zoekresultaat). Met de vaardigheidsdefinitie kunt u opgeven welke visuele functies van belang zijn. In dit voorbeeld zijn tags en beschrijvingen geproduceerd, maar er zijn meer uitvoer waaruit u kunt kiezen.
imageCaptionuitvoer is een matrix met beschrijvingen, één per afbeelding, aangeduid doortagséén woord en langere woordgroepen die de afbeelding beschrijven. Let op de tags die bestaan uit een zwerm van zeegullen zwemmen in het water of een close-up van een vogel.imageTagsuitvoer is een matrix met enkele tags, die worden vermeld in de volgorde van het maken. U ziet dat tags worden herhaald. Er is geen aggregatie of groepering.
"imageCaption": [
"{\"tags\":[\"bird\",\"outdoor\",\"water\",\"flock\",\"many\",\"lot\",\"bunch\",\"group\",\"several\",\"gathered\",\"pond\",\"lake\",\"different\",\"family\",\"flying\",\"standing\",\"little\",\"air\",\"beach\",\"swimming\",\"large\",\"dog\",\"landing\",\"jumping\",\"playing\"],\"captions\":[{\"text\":\"a flock of seagulls are swimming in the water\",\"confidence\":0.70419257326275686}]}",
"{\"tags\":[\"map\"],\"captions\":[{\"text\":\"map\",\"confidence\":0.99942880868911743}]}",
"{\"tags\":[\"animal\",\"bird\",\"raptor\",\"eagle\",\"sitting\",\"table\"],\"captions\":[{\"text\":\"a close up of a bird\",\"confidence\":0.89643581933539462}]}",
. . .
"imageTags": [
"bird",
"outdoor",
"water",
"flock",
"animal",
"bunch",
"group",
"several",
"drink",
"gathered",
"pond",
"different",
"family",
"same",
"map",
"text",
"animal",
"bird",
"bird of prey",
"eagle"
. . .
Scenario: Ingesloten afbeeldingen in PDF-bestanden
Wanneer de afbeeldingen die u wilt verwerken, zijn ingesloten in andere bestanden, zoals PDF of DOCX, worden met de verrijkingspijplijn alleen de afbeeldingen geëxtraheerd en vervolgens doorgegeven aan OCR of afbeeldingsanalyse voor verwerking. Afbeeldingextractie vindt plaats tijdens de fase van het kraken van documenten en zodra de afbeeldingen zijn gescheiden, blijven ze gescheiden, tenzij u de verwerkte uitvoer expliciet samenvoegt in de brontekst.
Tekst samenvoegen wordt gebruikt om de uitvoer van de afbeeldingsverwerking weer in het document te plaatsen. Hoewel Tekst samenvoegen geen harde vereiste is, wordt deze vaak aangeroepen, zodat afbeeldingsuitvoer (OCR-tekst, OCR layoutText, afbeeldingstags, bijschriften van afbeeldingen) opnieuw kan worden geïntroduceerd in het document. Afhankelijk van de vaardigheid vervangt de afbeeldingsuitvoer een ingesloten binaire afbeelding door een in-place tekstequivalent. Uitvoer van afbeeldingsanalyse kan worden samengevoegd op de locatie van de afbeelding. OCR-uitvoer wordt altijd weergegeven aan het einde van elke pagina.
De volgende werkstroom bevat een overzicht van het proces van afbeeldingextractie, analyse, samenvoegen en het uitbreiden van de pijplijn om verwerkte uitvoer van afbeeldingen te pushen naar andere op tekst gebaseerde vaardigheden, zoals Entiteitsherkenning of Tekstomzetting.
Nadat de indexeerfunctie verbinding heeft gemaakt met de gegevensbron, worden brondocumenten geladen en gekraakt, afbeeldingen en tekst geëxtraheerd en wordt elk inhoudstype in de wachtrij voor verwerking weergegeven. Er wordt een verrijkt document gemaakt dat alleen bestaat uit een hoofdknooppunt (document).
Afbeeldingen in de wachtrij worden genormaliseerd en doorgegeven aan verrijkte documenten als een document-/normalized_images-knooppunt .
Afbeeldingsverrijkingen worden uitgevoerd met behulp van
"/document/normalized_images"invoer.Afbeeldingsuitvoer wordt doorgegeven aan de verrijkte documentstructuur, waarbij elke uitvoer als een afzonderlijk knooppunt wordt uitgevoerd. De uitvoer verschilt per vaardigheid (tekst en layoutText voor OCR; tags en bijschriften voor afbeeldingsanalyse).
Optioneel maar aanbevolen als u wilt dat zoekdocumenten zowel tekst als tekst van oorsprong van afbeeldingen bevatten, wordt tekst samenvoegen uitgevoerd, waarbij de tekstweergave van deze afbeeldingen wordt gecombineerd met de onbewerkte tekst die uit het bestand is geëxtraheerd. Tekstsegmenten worden samengevoegd tot één grote tekenreeks, waarbij de tekst eerst in de tekenreeks wordt ingevoegd en vervolgens de OCR-tekstuitvoer of afbeeldingslabels en bijschriften.
De uitvoer van Tekst samenvoegen is nu de definitieve tekst die moet worden geanalyseerd op eventuele downstreamvaardigheden die tekstverwerking uitvoeren. Als uw vaardighedenset bijvoorbeeld zowel OCR als Entiteitsherkenning bevat, moet de invoer voor Entiteitsherkenning zijn
"document/merged_text"(de targetName van de vaardigheid Tekst samenvoegen).Nadat alle vaardigheden zijn uitgevoerd, is het verrijkte document voltooid. In de laatste stap verwijzen indexeerfuncties naar uitvoerveldtoewijzingen om verrijkte inhoud naar afzonderlijke velden in de zoekindex te verzenden.
In de volgende voorbeeldvaardighedenset wordt een merged_text veld gemaakt met de oorspronkelijke tekst van uw document met ingesloten OCRed-tekst in plaats van ingesloten afbeeldingen. Het bevat ook een entiteitsherkenningsvaardigheden die als invoer wordt gebruikt merged_text .
Hoofdtekstsyntaxis van aanvraag
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"description": "Extract text (plain and structured) from image.",
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text", "source": "/document/content"
},
{
"name": "itemsToInsert", "source": "/document/normalized_images/*/text"
},
{
"name":"offsets", "source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText", "targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"context": "/document",
"categories": [ "Person"],
"defaultLanguageCode": "en",
"minimumPrecision": 0.5,
"inputs": [
{
"name": "text", "source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons", "targetName": "people"
}
]
}
]
}
Nu u een merged_text veld hebt, kunt u dit toewijzen als doorzoekbaar veld in de definitie van de indexeerfunctie. Alle inhoud van uw bestanden, inclusief de tekst van de afbeeldingen, kan worden doorzocht.
Scenario: Begrenzingsvakken visualiseren
Een ander veelvoorkomend scenario is het visualiseren van informatie over de indeling van zoekresultaten. U kunt bijvoorbeeld markeren waar een stuk tekst in een afbeelding is gevonden als onderdeel van uw zoekresultaten.
Omdat de OCR-stap wordt uitgevoerd op de genormaliseerde afbeeldingen, bevinden de lay-outcoördinaten zich in de genormaliseerde afbeeldingsruimte, maar als u de oorspronkelijke afbeelding wilt weergeven, converteert u coördinatenpunten in de indeling naar het oorspronkelijke coördinatensysteem voor afbeeldingen.
Het volgende algoritme illustreert het patroon:
/// <summary>
/// Converts a point in the normalized coordinate space to the original coordinate space.
/// This method assumes the rotation angles are multiples of 90 degrees.
/// </summary>
public static Point GetOriginalCoordinates(Point normalized,
int originalWidth,
int originalHeight,
int width,
int height,
double rotationFromOriginal)
{
Point original = new Point();
double angle = rotationFromOriginal % 360;
if (angle == 0 )
{
original.X = normalized.X;
original.Y = normalized.Y;
} else if (angle == 90)
{
original.X = normalized.Y;
original.Y = (width - normalized.X);
} else if (angle == 180)
{
original.X = (width - normalized.X);
original.Y = (height - normalized.Y);
} else if (angle == 270)
{
original.X = height - normalized.Y;
original.Y = normalized.X;
}
double scalingFactor = (angle % 180 == 0) ? originalHeight / height : originalHeight / width;
original.X = (int) (original.X * scalingFactor);
original.Y = (int)(original.Y * scalingFactor);
return original;
}
Scenario: Vaardigheden voor aangepaste afbeeldingen
Afbeeldingen kunnen ook worden doorgegeven aan en geretourneerd door aangepaste vaardigheden. Een vaardighedenset base64 codeert de afbeelding die wordt doorgegeven aan de aangepaste vaardigheid. Als u de afbeelding in de aangepaste vaardigheid wilt gebruiken, stelt u "/document/normalized_images/*/data" deze in als invoer voor de aangepaste vaardigheid. In uw aangepaste vaardigheidscode codeert u de tekenreeks met base64 voordat u deze converteert naar een afbeelding. Als u een afbeelding wilt terugsturen naar de vaardighedenset, codeert u de afbeelding met base64 voordat u deze terugkeert naar de vaardighedenset.
De afbeelding wordt geretourneerd als een object met de volgende eigenschappen.
{
"$type": "file",
"data": "base64String"
}
De opslagplaats met Voorbeelden van Azure Search Python heeft een volledig voorbeeld geïmplementeerd in Python van een aangepaste vaardigheid waarmee afbeeldingen worden verrijkt.
Afbeeldingen doorgeven aan aangepaste vaardigheden
Voor scenario's waarin u een aangepaste vaardigheid nodig hebt om aan afbeeldingen te werken, kunt u afbeeldingen doorgeven aan de aangepaste vaardigheid en tekst of afbeeldingen laten retourneren. De volgende vaardighedenset is afkomstig uit een voorbeeld.
De volgende vaardighedenset gebruikt de genormaliseerde afbeelding (verkregen tijdens het kraken van documenten) en voert segmenten van de afbeelding uit.
Voorbeeldvaardighedenset
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "ImageSkill",
"description": "Segment Images",
"context": "/document/normalized_images/*",
"uri": "https://your.custom.skill.url",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 100,
"degreeOfParallelism": 1,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "slices",
"targetName": "slices"
}
],
"httpHeaders": {}
}
]
}
Voorbeeld van aangepaste vaardigheid
De aangepaste vaardigheid zelf is extern voor de vaardighedenset. In dit geval is het Python-code die eerst door de batch met aanvraagrecords in de aangepaste vaardigheidsindeling loopt en vervolgens de met Base64 gecodeerde tekenreeks converteert naar een afbeelding.
# deserialize the request, for each item in the batch
for value in values:
data = value['data']
base64String = data["image"]["data"]
base64Bytes = base64String.encode('utf-8')
inputBytes = base64.b64decode(base64Bytes)
# Use numpy to convert the string to an image
jpg_as_np = np.frombuffer(inputBytes, dtype=np.uint8)
# you now have an image to work with
Als u een afbeelding wilt retourneren, retourneert u een met base64 gecodeerde tekenreeks binnen een JSON-object met een eigenschap van het $type bestand.
def base64EncodeImage(image):
is_success, im_buf_arr = cv2.imencode(".jpg", image)
byte_im = im_buf_arr.tobytes()
base64Bytes = base64.b64encode(byte_im)
base64String = base64Bytes.decode('utf-8')
return base64String
base64String = base64EncodeImage(jpg_as_np)
result = {
"$type": "file",
"data": base64String
}