Hoge beschikbaarheid van SAP HANA-uitschaalsysteem in Red Hat Enterprise Linux
In dit artikel wordt beschreven hoe u een maximaal beschikbaar SAP HANA-systeem implementeert in een uitschaalconfiguratie. De configuratie maakt specifiek gebruik van HANA-systeemreplicatie (HSR) en Pacemaker op virtuele Azure Red Hat Enterprise Linux-machines (VM's). De gedeelde bestandssystemen in de gepresenteerde architectuur zijn gekoppeld aan NFS en worden geleverd door Azure NetApp Files of NFS-share in Azure Files.
In de voorbeeldconfiguraties en installatieopdrachten is 03 het HANA-exemplaar en de HANA-systeem-id HN1.
Vereisten
Sommige lezers kunnen profiteren van het raadplegen van diverse SAP-notities en -resources voordat ze verdergaan met de onderwerpen in dit artikel:
- SAP-notitie 1928533 omvat:
- Een lijst met Azure VM-grootten die worden ondersteund voor de implementatie van SAP-software.
- Belangrijke capaciteitsinformatie voor Azure VM-grootten.
- Ondersteunde SAP-software en combinaties van besturingssystemen en databases.
- De vereiste SAP-kernelversie voor Windows en Linux in Microsoft Azure.
- SAP-opmerking 2015553: bevat vereisten voor SAP-ondersteunde SAP-software-implementaties in Azure.
- SAP-opmerking [2002167]: heeft aanbevolen besturingssysteeminstellingen voor RHEL.
- SAP-opmerking 2009879: bevat SAP HANA-richtlijnen voor RHEL.
- SAP Note 3108302 heeft SAP HANA-richtlijnen voor Red Hat Enterprise Linux 9.x.
- SAP-opmerking 2178632: bevat gedetailleerde informatie over alle metrische bewakingsgegevens die zijn gerapporteerd voor SAP in Azure.
- SAP-opmerking 2191498: bevat de vereiste versie van de SAP-hostagent voor Linux in Azure.
- SAP-opmerking 2243692: bevat informatie over SAP-licenties op Linux in Azure.
- SAP-opmerking 1999351: bevat aanvullende informatie over probleemoplossing voor de uitgebreide azure-bewakingsextensie voor SAP.
- SAP-opmerking 1900823: bevat informatie over de opslagvereisten voor SAP HANA.
- SAP-communitywiki: bevat alle vereiste SAP-notities voor Linux.
- Azure Virtual Machines plannen en implementeren voor SAP op Linux.
- Azure Virtual Machines-implementatie voor SAP in Linux.
- DBMS-implementatie van Azure Virtual Machines voor SAP in Linux.
- SAP HANA-netwerkvereisten.
- Algemene RHEL-documentatie:
- Overzicht van invoegtoepassingen met hoge beschikbaarheid.
- Beheer van invoegtoepassingen met hoge beschikbaarheid.
- Naslaginformatie over invoegtoepassingen met hoge beschikbaarheid.
- Red Hat Enterprise Linux-netwerkhandleiding.
- Hoe kan ik sap HANA scale-out systeemreplicatie configureren in een Pacemaker-cluster met HANA-bestandssystemen op NFS-shares.
- Actief/actief (met lezen ingeschakeld): RHEL HA-oplossing voor SAP HANA uitschalen en systeemreplicatie.
- Azure-specifieke RHEL-documentatie:
- Documentatie voor Azure NetApp Files.
- NFS v4.1-volumes in Azure NetApp Files voor SAP HANA.
- Documentatie voor Azure Files
Overzicht
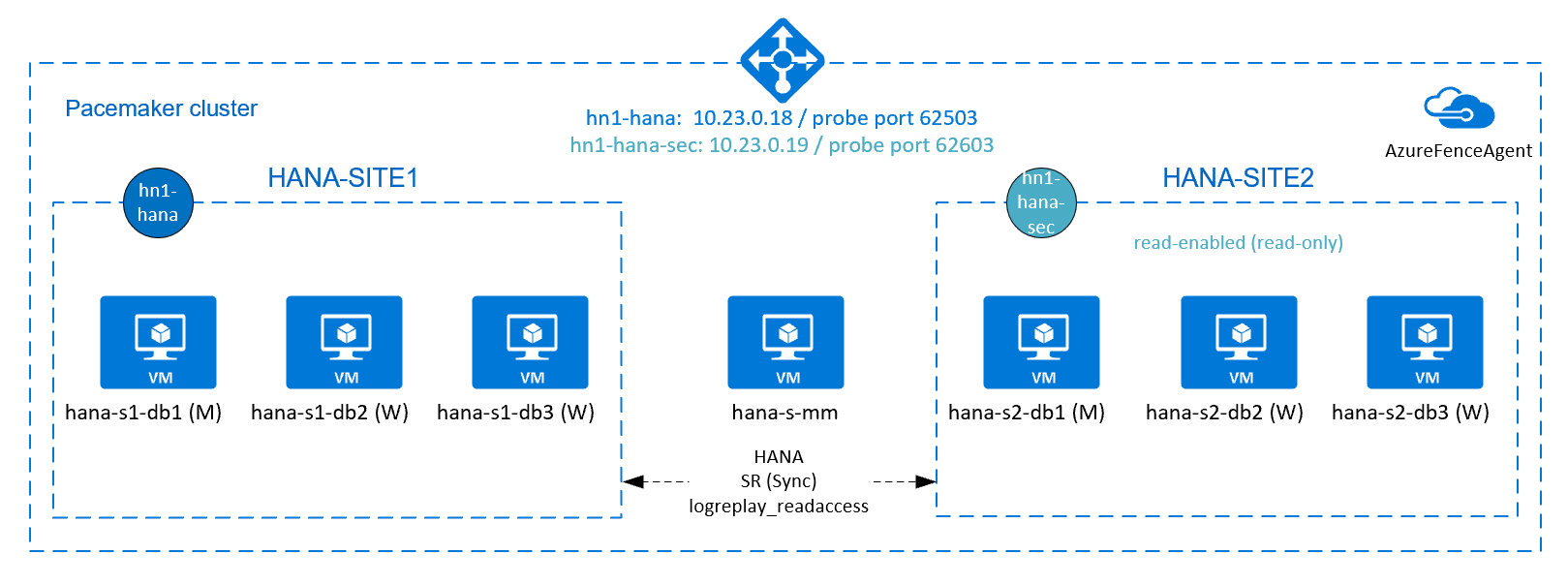
Als u hoge beschikbaarheid van HANA wilt bereiken voor HANA-uitschaalinstallaties, kunt u HANA-systeemreplicatie configureren en de oplossing beveiligen met een Pacemaker-cluster om automatische failover toe te staan. Wanneer een actief knooppunt mislukt, voert het cluster een failover uit van de HANA-resources naar de andere site.
In het volgende diagram bevinden zich drie HANA-knooppunten op elke site en een meerderheidsmakerknooppunt om een 'split-brain'-scenario te voorkomen. De instructies kunnen worden aangepast om meer VM's op te nemen als HANA DB-knooppunten.
Het gedeelde HANA-bestandssysteem /hana/shared in de gepresenteerde architectuur kan worden geleverd door Azure NetApp Files of NFS-share in Azure Files. Het gedeelde HANA-bestandssysteem is NFS gekoppeld op elk HANA-knooppunt in dezelfde HANA-systeemreplicatiesite. Bestandssystemen en /hana/log zijn lokale bestandssystemen /hana/data en worden niet gedeeld tussen de HANA DB-knooppunten. SAP HANA wordt geïnstalleerd in de niet-gedeelde modus.
Zie opslagconfiguraties voor SAP HANA Azure-VM's voor aanbevolen SAP HANA-opslagconfiguraties.
Belangrijk
Als u alle HANA-bestandssystemen implementeert in Azure NetApp Files, voor productiesystemen, waarbij de prestaties een sleutel zijn, raden we u aan om azure NetApp Files-toepassingsvolumegroep te evalueren en te gebruiken voor SAP HANA.

In het voorgaande diagram ziet u drie subnetten die worden weergegeven binnen één virtueel Azure-netwerk, volgens de aanbevelingen voor het SAP HANA-netwerk:
- Voor clientcommunicatie:
client10.23.0.0/24 - Voor interne communicatie tussen HANA-knooppunten:
inter10.23.1.128/26 - Voor HANA-systeemreplicatie:
hsr10.23.1.192/26
Omdat /hana/data en /hana/log worden geïmplementeerd op lokale schijven, is het niet nodig om afzonderlijke subnetkaarten en afzonderlijke virtuele netwerkkaarten te implementeren voor communicatie met de opslag.
Als u Azure NetApp Files gebruikt, worden de NFS-volumes voor /hana/shared, geïmplementeerd in een afzonderlijk subnet, gedelegeerd aan Azure NetApp Files: anf 10.23.1.0/26.
De infrastructuur instellen
In de volgende instructies wordt ervan uitgegaan dat u de resourcegroep, het virtuele Azure-netwerk met drie Azure-netwerksubnetten: clienten interhsr.
Virtuele Linux-machines implementeren via Azure Portal
Implementeer de Virtuele Azure-machines. Implementeer voor deze configuratie zeven virtuele machines:
- Drie virtuele machines die fungeren als HANA DB-knooppunten voor HANA-replicatiesite 1: hana-s1-db1, hana-s1-db2 en hana-s1-db3.
- Drie virtuele machines die fungeren als HANA DB-knooppunten voor HANA-replicatiesite 2: hana-s2-db1, hana-s2-db2 en hana-s2-db3.
- Een kleine virtuele machine die als meerderheidsmaker moet fungeren: hana-s-mm.
De VM's die als SAP DB HANA-knooppunten zijn geïmplementeerd, moeten worden gecertificeerd door SAP voor HANA, zoals gepubliceerd in de SAP HANA-hardwaremap. Wanneer u de HANA DB-knooppunten implementeert, moet u een versneld netwerk selecteren.
Voor het meeste makerknooppunt kunt u een kleine VM implementeren, omdat deze VM geen SAP HANA-resources uitvoert. De meeste maker-VM's worden gebruikt in de clusterconfiguratie om een oneven aantal clusterknooppunten in een split-brain-scenario te bereiken. De meeste maker-VM's hebben slechts één virtuele netwerkinterface nodig in het
clientsubnet in dit voorbeeld.Lokale beheerde schijven implementeren voor
/hana/dataen/hana/log. De minimaal aanbevolen opslagconfiguratie voor/hana/dataen/hana/logwordt beschreven in opslagconfiguraties van SAP HANA Azure-VM's.Implementeer de primaire netwerkinterface voor elke VIRTUELE machine in het subnet van het
clientvirtuele netwerk. Wanneer de VM wordt geïmplementeerd via Azure Portal, wordt de naam van de netwerkinterface automatisch gegenereerd. In dit artikel verwijzen we naar de automatisch gegenereerde primaire netwerkinterfaces als hana-s1-db1-client, hana-s1-db2-client, hana-s1-db3-client, enzovoort. Deze netwerkinterfaces worden gekoppeld aan het subnet van hetclientvirtuele Azure-netwerk.Belangrijk
Zorg ervoor dat het besturingssysteem dat u selecteert SAP-gecertificeerd is voor SAP HANA op de specifieke VM-typen die u gebruikt. Zie voor een lijst met door SAP HANA gecertificeerde VM-typen en besturingssysteemreleases voor deze typen sap HANA-gecertificeerde IaaS-platforms. Zoom in op de details van het vermelde VM-type om de volledige lijst met door SAP HANA ondersteunde besturingssysteemreleases voor dat type op te halen.
Maak zes netwerkinterfaces, één voor elke virtuele HANA DB-machine, in het subnet van het
intervirtuele netwerk (in dit voorbeeld hana-s1-db1-inter, hana-s1-db2-inter, hana-s1-db3-inter, hana-s2-db1-inter, hana-s2-db2-inter en hana-s2-db3-inter).Maak zes netwerkinterfaces, één voor elke virtuele HANA DB-machine, in het subnet van het virtuele netwerk (in dit voorbeeld hana-s1-db1-hsr, hana-s1-db2-hsr, hana-s1-db3-hsr, hana-s2-db1-hsr, hana-s2-hsr en hana-s2-db3-hsr
hsr).Koppel de zojuist gemaakte virtuele netwerkinterfaces aan de bijbehorende virtuele machines:
- Ga naar de virtuele machine in Azure Portal.
- Selecteer Virtuele machines in het linkerdeelvenster. Filter op de naam van de virtuele machine (bijvoorbeeld hana-s1-db1) en selecteer vervolgens de virtuele machine.
- Selecteer In het deelvenster Overzicht de optie Stoppen om de toewijzing van de virtuele machine ongedaan te maken.
- Selecteer Netwerken en koppel vervolgens de netwerkinterface. Selecteer in de vervolgkeuzelijst Netwerkinterface koppelen de reeds gemaakte netwerkinterfaces voor de
interenhsrsubnetten. - Selecteer Opslaan.
- Herhaal stap b tot en met e voor de resterende virtuele machines (in ons voorbeeld hana-s1-db2, hana-s1-db3, hana-s2-db1, hana-s2-db2 en hana-s2-db3)
- Laat de virtuele machines voorlopig in de gestopte status staan.
Schakel versneld netwerken in voor de extra netwerkinterfaces voor de
interenhsrsubnetten door het volgende te doen:Open Azure Cloud Shell in Azure Portal.
Voer de volgende opdrachten uit om versneld netwerken in te schakelen voor de extra netwerkinterfaces die zijn gekoppeld aan de
interenhsrsubnetten.az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db1-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db2-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db3-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db1-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db2-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db3-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db1-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db2-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db3-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db1-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db2-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db3-hsr --accelerated-networking true
Start de virtuele HANA DB-machines.
Azure Load Balancer configureren
Tijdens de VM-configuratie hebt u de mogelijkheid om een load balancer te maken of te selecteren in de sectie Netwerken. Volg de onderstaande stappen om de standaard load balancer in te stellen voor het instellen van hoge beschikbaarheid van de HANA-database.
Notitie
- Voor uitschalen van HANA selecteert u de NIC voor het
clientsubnet bij het toevoegen van de virtuele machines in de back-endpool. - Met de volledige set opdrachten in Azure CLI en PowerShell worden de VM's met primaire NIC in de back-endpool toegevoegd.
Volg de stappen in Load Balancer maken om een standaard load balancer in te stellen voor een SAP-systeem met hoge beschikbaarheid met behulp van Azure Portal. Houd rekening met de volgende punten tijdens de installatie van de load balancer:
- Front-end-IP-configuratie: maak een front-end-IP-adres. Selecteer dezelfde virtuele netwerk- en subnetnaam als uw virtuele databasemachines.
- Back-endpool: maak een back-endpool en voeg database-VM's toe.
-
Regels voor inkomend verkeer: maak een taakverdelingsregel. Volg dezelfde stappen voor beide taakverdelingsregels.
- Front-end-IP-adres: Selecteer een front-end-IP-adres.
- Back-endpool: Selecteer een back-endpool.
- Poorten voor hoge beschikbaarheid: selecteer deze optie.
- Protocol: selecteer TCP.
-
Statustest: maak een statustest met de volgende details:
- Protocol: selecteer TCP.
- Poort: bijvoorbeeld 625<instance-no.>.
- Interval: Voer 5 in.
- Testdrempel: voer 2 in.
- Time-out voor inactiviteit (minuten): voer 30 in.
- Zwevend IP-adres inschakelen: selecteer deze optie.
Notitie
De configuratie-eigenschap numberOfProbesvan de statustest, ook wel bekend als drempelwaarde voor beschadigde status in de portal, wordt niet gerespecteerd. Als u het aantal geslaagde of mislukte opeenvolgende tests wilt bepalen, stelt u de eigenschap probeThreshold in op 2. Het is momenteel niet mogelijk om deze eigenschap in te stellen met behulp van Azure Portal, dus gebruik de Azure CLI of de PowerShell-opdracht.
Notitie
Wanneer u de standard load balancer gebruikt, moet u rekening houden met de volgende beperking. Wanneer u virtuele machines zonder openbare IP-adressen in de back-endpool van een interne load balancer plaatst, is er geen uitgaande internetverbinding. Als u routering naar openbare eindpunten wilt toestaan, moet u aanvullende configuratie uitvoeren. Zie Openbare eindpuntconnectiviteit voor virtuele machines met behulp van Azure Standard Load Balancer in scenario's met hoge beschikbaarheid van SAP voor meer informatie.
Belangrijk
Schakel TCP-tijdstempels niet in op Azure-VM's die achter Azure Load Balancer worden geplaatst. Als u TCP-tijdstempels inschakelt, mislukken de statustests. Stel de parameter in net.ipv4.tcp_timestamps op 0. Zie Statustests van Load Balancer en SAP-notitie 2382421 voor meer informatie.
NFS implementeren
Er zijn twee opties voor het implementeren van systeemeigen Azure NFS voor /hana/shared. U kunt NFS-volume implementeren op Azure NetApp Files of NFS-share in Azure Files. Azure-bestanden ondersteunen het NFSv4.1-protocol, NFS op Azure NetApp-bestanden ondersteunt zowel NFSv4.1 als NFSv3.
In de volgende secties worden de stappen beschreven voor het implementeren van NFS. U moet slechts één van de opties selecteren.
Tip
U hebt ervoor gekozen om te implementeren /hana/shared op NFS-share op Azure Files of NFS-volume in Azure NetApp Files.
De Azure NetApp Files-infrastructuur implementeren
Implementeer de Azure NetApp Files-volumes voor het /hana/shared bestandssysteem. U hebt een afzonderlijk /hana/shared volume nodig voor elke HANA-systeemreplicatiesite. Zie De Azure NetApp Files-infrastructuur instellen voor meer informatie.
In dit voorbeeld gebruikt u de volgende Azure NetApp Files-volumes:
- volume HN1-shared-s1 (nfs://10.23.1.7/ HN1-shared-s1)
- volume HN1-shared-s2 (nfs://10.23.1.7/ HN1-shared-s2)
De NFS implementeren in de Infrastructuur van Azure Files
Azure Files NFS-shares implementeren voor het /hana/shared bestandssysteem. U hebt een afzonderlijke /hana/shared Azure Files NFS-share nodig voor elke HANA-systeemreplicatiesite. Zie Een NFS-share maken voor meer informatie.
In dit voorbeeld zijn de volgende Azure Files NFS-shares gebruikt:
- delen hn1-shared-s1 (sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1)
- delen hn1-shared-s2 (sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2)
Configuratie en voorbereiding van het besturingssysteem
De instructies in de volgende secties worden voorafgegaan door een van de volgende afkortingen:
- [A]: Van toepassing op alle knooppunten
- [AH]: van toepassing op alle HANA DB-knooppunten
- [M]: Van toepassing op het knooppunt van de meerderheidsmaker
- [AH1]: Van toepassing op alle HANA DB-knooppunten op SITE 1
- [AH2]: Van toepassing op alle HANA DB-knooppunten op SITE 2
- [1]: Alleen van toepassing op HANA DB-knooppunt 1, SITE 1
- [2]: Alleen van toepassing op HANA DB-knooppunt 1, SITE 2
Configureer en bereid uw besturingssysteem als volgt voor:
[A] Onderhoud de hostbestanden op de virtuele machines. Vermeldingen opnemen voor alle subnetten. De volgende vermeldingen worden toegevoegd aan
/etc/hostsdit voorbeeld.# Client subnet 10.23.0.11 hana-s1-db1 10.23.0.12 hana-s1-db1 10.23.0.13 hana-s1-db2 10.23.0.14 hana-s2-db1 10.23.0.15 hana-s2-db2 10.23.0.16 hana-s2-db3 10.23.0.17 hana-s-mm # Internode subnet 10.23.1.138 hana-s1-db1-inter 10.23.1.139 hana-s1-db2-inter 10.23.1.140 hana-s1-db3-inter 10.23.1.141 hana-s2-db1-inter 10.23.1.142 hana-s2-db2-inter 10.23.1.143 hana-s2-db3-inter # HSR subnet 10.23.1.202 hana-s1-db1-hsr 10.23.1.203 hana-s1-db2-hsr 10.23.1.204 hana-s1-db3-hsr 10.23.1.205 hana-s2-db1-hsr 10.23.1.206 hana-s2-db2-hsr 10.23.1.207 hana-s2-db3-hsr[A] Maak configuratiebestand /etc/sysctl.d/ms-az.conf met Microsoft voor Azure-configuratie-instellingen.
vi /etc/sysctl.d/ms-az.conf # Add the following entries in the configuration file net.ipv6.conf.all.disable_ipv6 = 1 net.ipv4.tcp_max_syn_backlog = 16348 net.ipv4.conf.all.rp_filter = 0 sunrpc.tcp_slot_table_entries = 128 vm.swappiness=10Tip
Vermijd het instellen
net.ipv4.ip_local_port_rangeennet.ipv4.ip_local_reserved_portsexpliciet in desysctlconfiguratiebestanden, zodat de SAP-hostagent de poortbereiken kan beheren. Zie SAP-notitie 2382421 voor meer informatie.[A] Installeer het NFS-clientpakket.
yum install nfs-utils[AH] Red Hat voor HANA-configuratie.
Configureer RHEL, zoals beschreven in de Red Hat-klantportal en in de volgende SAP-notities:
- 2292690 - SAP HANA DB: Aanbevolen besturingssysteeminstellingen voor RHEL 7
- 2777782 - SAP HANA DB: Aanbevolen besturingssysteeminstellingen voor RHEL 8
- 2455582 - Linux: SAP-toepassingen uitvoeren die zijn gecompileerd met GCC 6.x
- 2593824 - Linux: SAP-toepassingen uitvoeren die zijn gecompileerd met GCC 7.x
- 2886607 - Linux: SAP-toepassingen uitvoeren die zijn gecompileerd met GCC 9.x
De bestandssystemen voorbereiden
De volgende secties bevatten stappen voor de voorbereiding van uw bestandssystemen. U hebt ervoor gekozen om /hana/shared te implementeren op NFS-share op Azure Files of NFS-volume in Azure NetApp Files.
Koppel de gedeelde bestandssystemen (Azure NetApp Files NFS)
In dit voorbeeld worden de gedeelde HANA-bestandssystemen geïmplementeerd in Azure NetApp Files en gekoppeld via NFSv4.1. Volg de stappen in deze sectie, alleen als u NFS gebruikt in Azure NetApp Files.
[AH] Bereid het besturingssysteem voor voor het uitvoeren van SAP HANA op NetApp Systems met NFS, zoals beschreven in SAP-opmerking 3024346 - Linux-kernelinstellingen voor NetApp NFS. Maak configuratiebestand /etc/sysctl.d/91-NetApp-HANA.conf voor de NetApp-configuratie-instellingen.
vi /etc/sysctl.d/91-NetApp-HANA.conf # Add the following entries in the configuration file net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 net.ipv4.tcp_rmem = 4096 131072 16777216 net.ipv4.tcp_wmem = 4096 16384 16777216 net.core.netdev_max_backlog = 300000 net.ipv4.tcp_slow_start_after_idle=0 net.ipv4.tcp_no_metrics_save = 1 net.ipv4.tcp_moderate_rcvbuf = 1 net.ipv4.tcp_window_scaling = 1 net.ipv4.tcp_sack = 1[AH] Pas de sunrpc-instellingen aan, zoals aanbevolen in SAP-opmerking 3024346 - Linux-kernelinstellingen voor NetApp NFS.
vi /etc/modprobe.d/sunrpc.conf # Insert the following line options sunrpc tcp_max_slot_table_entries=128[AH] Koppelpunten maken voor de HANA-databasevolumes.
mkdir -p /hana/shared[AH] Controleer de NFS-domeininstelling. Zorg ervoor dat het domein is geconfigureerd als het standaarddomein van Azure NetApp Files:
defaultv4iddomain.com. Zorg ervoor dat de toewijzing is ingesteld opnobody.
(Deze stap is alleen nodig als u Azure NetAppFiles NFS v4.1 gebruikt.)Belangrijk
Zorg ervoor dat u het NFS-domein instelt op
/etc/idmapd.confde VIRTUELE machine zodat dit overeenkomt met de standaarddomeinconfiguratie in Azure NetApp Files:defaultv4iddomain.com. Als de domeinconfiguratie op de NFS-client en de NFS-server niet overeenkomt, worden de machtigingen voor bestanden op Azure NetApp-volumes die zijn gekoppeld op de VM's weergegeven alsnobody.sudo cat /etc/idmapd.conf # Example [General] Domain = defaultv4iddomain.com [Mapping] Nobody-User = nobody Nobody-Group = nobody[AH] Controleer
nfs4_disable_idmapping. Deze moet worden ingesteld opY. Als u de mapstructuur wilt maken waarnfs4_disable_idmappingzich bevindt, voert u de koppelingsopdracht uit. U kunt de map niet handmatig maken onder /sys/modules, omdat toegang is gereserveerd voor de kernel of stuurprogramma's.
Deze stap is alleen nodig als u Azure NetAppFiles NFSv4.1 gebruikt.# Check nfs4_disable_idmapping cat /sys/module/nfs/parameters/nfs4_disable_idmapping # If you need to set nfs4_disable_idmapping to Y mkdir /mnt/tmp mount 10.9.0.4:/HN1-shared /mnt/tmp umount /mnt/tmp echo "Y" > /sys/module/nfs/parameters/nfs4_disable_idmapping # Make the configuration permanent echo "options nfs nfs4_disable_idmapping=Y" >> /etc/modprobe.d/nfs.confZie de Red Hat-klantportal voor meer informatie over het wijzigen van de
nfs4_disable_idmappingparameter.[AH1] Koppel de gedeelde Azure NetApp Files-volumes op de SITE1 HANA DB-VM's.
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.23.1.7:/HN1-shared-s1 /hana/shared[AH2] Koppel de gedeelde Azure NetApp Files-volumes op de SITE2 HANA DB-VM's.
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.23.1.7:/HN1-shared-s2 /hana/shared[AH] Controleer of de bijbehorende
/hana/shared/bestandssystemen zijn gekoppeld op alle HANA DB-VM's, met NFS-protocolversie NFSv4.sudo nfsstat -m # Verify that flag vers is set to 4.1 # Example from SITE 1, hana-s1-db1 /hana/shared from 10.23.1.7:/HN1-shared-s1 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.11,local_lock=none,addr=10.23.1.7 # Example from SITE 2, hana-s2-db1 /hana/shared from 10.23.1.7:/HN1-shared-s2 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.14,local_lock=none,addr=10.23.1.7
De gedeelde bestandssystemen koppelen (Azure Files NFS)
In dit voorbeeld worden de gedeelde HANA-bestandssystemen geïmplementeerd op NFS in Azure Files. Volg de stappen in deze sectie, alleen als u NFS in Azure Files gebruikt.
[AH] Koppelpunten maken voor de HANA-databasevolumes.
mkdir -p /hana/shared[AH1] Koppel de gedeelde Azure NetApp Files-volumes op de SITE1 HANA DB-VM's.
sudo vi /etc/fstab # Add the following entry sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 /hana/shared nfs nfsvers=4.1,sec=sys 0 0 # Mount all volumes sudo mount -a[AH2] Koppel de gedeelde Azure NetApp Files-volumes op de SITE2 HANA DB-VM's.
sudo vi /etc/fstab # Add the following entries sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 /hana/shared nfs nfsvers=4.1,sec=sys 0 0 # Mount the volume sudo mount -a[AH] Controleer of de bijbehorende
/hana/shared/bestandssystemen zijn gekoppeld op alle HANA DB-VM's met NFS-protocolversie NFSv4.1.sudo nfsstat -m # Example from SITE 1, hana-s1-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.19,local_lock=none,addr=10.23.0.35 # Example from SITE 2, hana-s2-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.22,local_lock=none,addr=10.23.0.35
De gegevens en lokale bestandssystemen in logboeken voorbereiden
In de gepresenteerde configuratie implementeert u bestandssystemen /hana/data en /hana/log op een beheerde schijf en koppelt u deze bestandssystemen lokaal aan elke HANA DB-VM. Voer de volgende stappen uit om de lokale gegevens en logboekvolumes op elke virtuele HANA DB-machine te maken.
Stel de schijfindeling in met LVM (Logical Volume Manager). In het volgende voorbeeld wordt ervan uitgegaan dat aan elke virtuele HANA-machine drie gegevensschijven zijn gekoppeld en dat deze schijven worden gebruikt om twee volumes te maken.
[AH] Geef alle beschikbare schijven weer:
ls /dev/disk/azure/scsi1/lun*Voorbeelduitvoer:
/dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 /dev/disk/azure/scsi1/lun2[AH] Maak fysieke volumes voor alle schijven die u wilt gebruiken:
sudo pvcreate /dev/disk/azure/scsi1/lun0 sudo pvcreate /dev/disk/azure/scsi1/lun1 sudo pvcreate /dev/disk/azure/scsi1/lun2[AH] Maak een volumegroep voor de gegevensbestanden. Gebruik één volumegroep voor de logboekbestanden en een voor de gedeelde map van SAP HANA:
sudo vgcreate vg_hana_data_HN1 /dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 sudo vgcreate vg_hana_log_HN1 /dev/disk/azure/scsi1/lun2[AH] Maak de logische volumes. Er wordt een lineair volume gemaakt wanneer u zonder de
-ischakelaar gebruiktlvcreate. We raden u aan om een gestreept volume te maken voor betere I/O-prestaties. Lijn de stripegrootten uit op de waarden die worden beschreven in SAP HANA VM-opslagconfiguraties. Het-iargument moet het nummer zijn van de onderliggende fysieke volumes en het-Iargument is de streepgrootte. In dit artikel worden twee fysieke volumes gebruikt voor het gegevensvolume, dus het-ischakelargument is ingesteld op2. De stripegrootte voor het gegevensvolume is256 KiB. Er wordt één fysiek volume gebruikt voor het logboekvolume, dus u hoeft geen expliciete-iof-Ischakelopties te gebruiken voor de logboekvolumeopdrachten.Belangrijk
Gebruik de schakeloptie en stel deze
-iin op het aantal onderliggende fysieke volumes wanneer u meer dan één fysiek volume gebruikt voor elk gegevens- of logboekvolume. Gebruik de-Ischakeloptie om de stripegrootte op te geven wanneer u een gestreept volume maakt. Zie SAP HANA VM-opslagconfiguraties voor aanbevolen opslagconfiguraties, waaronder stripegrootten en het aantal schijven.sudo lvcreate -i 2 -I 256 -l 100%FREE -n hana_data vg_hana_data_HN1 sudo lvcreate -l 100%FREE -n hana_log vg_hana_log_HN1 sudo mkfs.xfs /dev/vg_hana_data_HN1/hana_data sudo mkfs.xfs /dev/vg_hana_log_HN1/hana_log[AH] Maak de koppelmappen en kopieer de UUID van alle logische volumes:
sudo mkdir -p /hana/data/HN1 sudo mkdir -p /hana/log/HN1 # Write down the ID of /dev/vg_hana_data_HN1/hana_data and /dev/vg_hana_log_HN1/hana_log sudo blkid[AH] Maak
fstabvermeldingen voor de logische volumes en koppel:sudo vi /etc/fstabVoeg de volgende regel in het
/etc/fstabbestand in:/dev/disk/by-uuid/UUID of /dev/mapper/vg_hana_data_HN1-hana_data /hana/data/HN1 xfs defaults,nofail 0 2 /dev/disk/by-uuid/UUID of /dev/mapper/vg_hana_log_HN1-hana_log /hana/log/HN1 xfs defaults,nofail 0 2Koppel de nieuwe volumes:
sudo mount -a
Installatie
In dit voorbeeld voor het implementeren van SAP HANA in een uitschaalconfiguratie met HSR op Azure-VM's gebruikt u HANA 2.0 SP4.
Voorbereiden op HANA-installatie
[AH] Voordat de HANA-installatie wordt uitgevoerd, stelt u het hoofdwachtwoord in. U kunt het hoofdwachtwoord uitschakelen nadat de installatie is voltooid. Voer de
rootopdrachtpasswduit om het wachtwoord in te stellen.[1,2] Wijzig de machtigingen voor
/hana/shared.chmod 775 /hana/shared[1] Controleer of u zich kunt aanmelden bij hana-s1-db2 en hana-s1-db3 via secure shell (SSH), zonder dat u om een wachtwoord wordt gevraagd. Als dat niet het geval is, wisselt
sshu sleutels uit, zoals beschreven in Verificatie op basis van sleutels.ssh root@hana-s1-db2 ssh root@hana-s1-db3[2] Controleer of u zich kunt aanmelden bij hana-s2-db2 en hana-s2-db3 via SSH, zonder dat u om een wachtwoord wordt gevraagd. Als dat niet het geval is, wisselt
sshu sleutels uit, zoals beschreven in Verificatie op basis van sleutels.ssh root@hana-s2-db2 ssh root@hana-s2-db3[AH] Installeer extra pakketten die vereist zijn voor HANA 2.0 SP4. Zie SAP Note 2593824 voor RHEL 7 voor meer informatie.
# If using RHEL 7 yum install libgcc_s1 libstdc++6 compat-sap-c++-7 libatomic1 # If using RHEL 8 yum install libatomic libtool-ltdl.x86_64[A] Schakel de firewall tijdelijk uit, zodat deze de HANA-installatie niet verstoort. U kunt deze opnieuw inschakelen nadat de HANA-installatie is voltooid.
# Execute as root systemctl stop firewalld systemctl disable firewalld
HANA-installatie op het eerste knooppunt op elke site
[1] Installeer SAP HANA door de instructies in de installatie- en updatehandleiding van SAP HANA 2.0 te volgen. In de volgende instructies ziet u de SAP HANA-installatie op het eerste knooppunt op SITE 1.
Start het
hdblcmprogramma vanafrootde HANA-installatiesoftwaremap. Gebruik deinternal_networkparameter en geef de adresruimte door voor het subnet, dat wordt gebruikt voor de interne communicatie tussen HANA-knooppunten../hdblcm --internal_network=10.23.1.128/26Voer bij de prompt de volgende waarden in:
- Voer voor Kies een actie 1 in (voor installatie).
- Voer 2, 3 in voor aanvullende onderdelen voor installatie.
- Druk voor het installatiepad op Enter (standaard ingesteld op /hana/gedeeld).
- Druk op Enter om de standaardwaarde te accepteren voor de lokale hostnaam.
- Als u hosts wilt toevoegen aan het systeem, voert u n in.
- Voer voor SAP HANA-systeem-id HN1 in.
- Voer bijvoorbeeld nummer [00] 03 in.
- Druk voor lokale hostwerkgroep [standaard] op Enter om de standaardwaarde te accepteren.
- Voer voor Systeemgebruik selecteren /Index invoeren [4]4 (voor aangepast) in.
- Voor Locatie van gegevensvolumes [/hana/data/HN1] drukt u op Enter om de standaardwaarde te accepteren.
- Voor locatie van logboekvolumes [/hana/log/HN1], drukt u op Enter om de standaardwaarde te accepteren.
- Als u maximale geheugentoewijzing wilt beperken? [n], voert u n in.
- Voor de naam van de certificaathost voor Host hana-s1-db1 [hana-s1-db1], drukt u op Enter om de standaardwaarde te accepteren.
- Voer het wachtwoord in voor SAP Host Agent User (sapadm).
- Voer het wachtwoord in om het wachtwoord van de SAP Host Agent-gebruiker (sapadm) te bevestigen.
- Voer voor het hn1adm-wachtwoord (hn1adm) het wachtwoord in.
- Druk op Enter om de standaardinstelling te accepteren voor de basismap van de systeembeheerder [/usr/sap/HN1/home].
- Druk voor systeembeheerdersaanmeldingsshell [/bin/sh] op Enter om de standaardwaarde te accepteren.
- Voor de gebruikers-id van de systeembeheerder [1001] drukt u op Enter om de standaardwaarde te accepteren.
- Druk voor Enter-id van gebruikersgroep (sapsys) [79] op Enter om de standaardwaarde te accepteren.
- Voer voor het wachtwoord van de systeemdatabasegebruiker (systeem) het wachtwoord van het systeem in.
- Voer het wachtwoord van het systeemdatabasegebruiker (systeem) in als u het wachtwoord van de systeemdatabase (systeemgebruiker) wilt bevestigen.
- Bij Systeem opnieuw opstarten nadat de computer opnieuw is opgestart? [n], voert u n in.
- Als u wilt doorgaan (y/n), valideert u de samenvatting en voert u y in als alles er goed uitziet.
[2] Herhaal de vorige stap om SAP HANA te installeren op het eerste knooppunt op SITE 2.
[1,2] Controleer global.ini.
Geef global.ini weer en zorg ervoor dat de configuratie voor de interne COMMUNICATIE tussen SAP HANA-knooppunten aanwezig is. Controleer de
communicationsectie. Deze moet de adresruimte voor hetintersubnet hebben enlisteninterfacemoet worden ingesteld op.internal. Controleer deinternal_hostname_resolutionsectie. Het moet de IP-adressen hebben voor de virtuele HANA-machines die deel uitmaken van hetintersubnet.sudo cat /usr/sap/HN1/SYS/global/hdb/custom/config/global.ini # Example from SITE1 [communication] internal_network = 10.23.1.128/26 listeninterface = .internal [internal_hostname_resolution] 10.23.1.138 = hana-s1-db1 10.23.1.139 = hana-s1-db2 10.23.1.140 = hana-s1-db3[1,2] Bereid global.ini voor op installatie in een niet-gedeelde omgeving, zoals beschreven in SAP-opmerking 2080991.
sudo vi /usr/sap/HN1/SYS/global/hdb/custom/config/global.ini [persistence] basepath_shared = no[1,2] Start SAP HANA opnieuw om de wijzigingen te activeren.
sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StopSystem sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StartSystem[1,2] Controleer of de clientinterface gebruikmaakt van de IP-adressen van het
clientsubnet voor communicatie.# Execute as hn1adm /usr/sap/HN1/HDB03/exe/hdbsql -u SYSTEM -p "password" -i 03 -d SYSTEMDB 'select * from SYS.M_HOST_INFORMATION'|grep net_publicname # Expected result - example from SITE 2 "hana-s2-db1","net_publicname","10.23.0.14"Zie SAP Note 2183363 - Configuratie van intern SAP HANA-netwerk voor informatie over het controleren van de configuratie.
[AH] Wijzig machtigingen voor de gegevens en logboekmappen om een HANA-installatiefout te voorkomen.
sudo chmod o+w -R /hana/data /hana/log[1] Installeer de secundaire HANA-knooppunten. De voorbeeldinstructies in deze stap zijn voor SITE 1.
Start het resident
hdblcmprogramma alsroot.cd /hana/shared/HN1/hdblcm ./hdblcmVoer bij de prompt de volgende waarden in:
- Voer voor Kies een actie 2 in (voor hosts toevoegen).
- Als u door komma's gescheiden hostnamen wilt toevoegen, voert u hana-s1-db2, hana-s1-db3 in.
- Voer 2, 3 in voor aanvullende onderdelen voor installatie.
- Druk voor Enter Root User Name [root] op Enter om de standaardwaarde te accepteren.
- Voor Rollen selecteren voor host 'hana-s1-db2' [1], selecteert u 1 (voor werkrol).
- Voor Enter Host Failover Group voor host 'hana-s1-db2' [standaard], drukt u op Enter om de standaardwaarde te accepteren.
- Voor Enter Storage Partition Number voor host 'hana-s1-db2' [<<automatisch>> toewijzen], drukt u op Enter om de standaardwaarde te accepteren.
- Druk voor Enter Worker Group voor host 'hana-s1-db2' [standaard] op Enter om de standaardwaarde te accepteren.
- Voor Rollen selecteren voor host 'hana-s1-db3' [1], selecteert u 1 (voor werkrol).
- Voor Enter Host Failover Group voor host 'hana-s1-db3' [standaard], drukt u op Enter om de standaardwaarde te accepteren.
- Voor Enter Storage Partition Number voor host 'hana-s1-db3' [<<automatisch>> toewijzen], drukt u op Enter om de standaardwaarde te accepteren.
- Druk voor Enter Worker Group voor host 'hana-s1-db3' [standaard] op Enter om de standaardwaarde te accepteren.
- Voer voor het hn1adm-wachtwoord (hn1adm) het wachtwoord in.
- Voer het wachtwoord in voor Het invoeren van het WACHTWOORD van de SAP Host Agent-gebruiker (sapadm).
- Voer het wachtwoord in om het wachtwoord van de SAP Host Agent-gebruiker (sapadm) te bevestigen.
- Voor de naam van de certificaathost voor Host hana-s1-db2 [hana-s1-db2], drukt u op Enter om de standaardwaarde te accepteren.
- Voor de naam van de certificaathost voor Host hana-s1-db3 [hana-s1-db3], drukt u op Enter om de standaardwaarde te accepteren.
- Als u wilt doorgaan (y/n), valideert u de samenvatting en voert u y in als alles er goed uitziet.
[2] Herhaal de vorige stap om de secundaire SAP HANA-knooppunten op SITE 2 te installeren.
SAP HANA 2.0-systeemreplicatie configureren
Met de volgende stappen kunt u systeemreplicatie instellen:
[1] Systeemreplicatie op SITE 1 configureren:
Maak een back-up van de databases als hn1adm:
hdbsql -d SYSTEMDB -u SYSTEM -p "passwd" -i 03 "BACKUP DATA USING FILE ('initialbackupSYS')" hdbsql -d HN1 -u SYSTEM -p "passwd" -i 03 "BACKUP DATA USING FILE ('initialbackupHN1')"Kopieer de PKI-systeembestanden naar de secundaire site:
scp /usr/sap/HN1/SYS/global/security/rsecssfs/data/SSFS_HN1.DAT hana-s2-db1:/usr/sap/HN1/SYS/global/security/rsecssfs/data/ scp /usr/sap/HN1/SYS/global/security/rsecssfs/key/SSFS_HN1.KEY hana-s2-db1:/usr/sap/HN1/SYS/global/security/rsecssfs/key/Maak de primaire site:
hdbnsutil -sr_enable --name=HANA_S1[2] Systeemreplicatie configureren op SITE 2:
Registreer de tweede site om de systeemreplicatie te starten. Voer de volgende opdracht uit als <hanasid>adm:
sapcontrol -nr 03 -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hana-s1-db1 --remoteInstance=03 --replicationMode=sync --name=HANA_S2 sapcontrol -nr 03 -function StartSystem[1] Controleer de replicatiestatus en wacht totdat alle databases zijn gesynchroniseerd.
sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py" # | Database | Host | Port | Service Name | Volume ID | Site ID | Site Name | Secondary | Secondary | Secondary | Secondary | Secondary | Replication | Replication | Replication | # | | | | | | | | Host | Port | Site ID | Site Name | Active Status | Mode | Status | Status Details | # | -------- | ------------- | ----- | ------------ | --------- | ------- | --------- | ------------- | --------- | --------- | --------- | ------------- | ----------- | ----------- | -------------- | # | HN1 | hana-s1-db3 | 30303 | indexserver | 5 | 1 | HANA_S1 | hana-s2-db3 | 30303 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | SYSTEMDB | hana-s1-db1 | 30301 | nameserver | 1 | 1 | HANA_S1 | hana-s2-db1 | 30301 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | HN1 | hana-s1-db1 | 30307 | xsengine | 2 | 1 | HANA_S1 | hana-s2-db1 | 30307 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | HN1 | hana-s1-db1 | 30303 | indexserver | 3 | 1 | HANA_S1 | hana-s2-db1 | 30303 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | HN1 | hana-s1-db2 | 30303 | indexserver | 4 | 1 | HANA_S1 | hana-s2-db2 | 30303 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # # status system replication site "2": ACTIVE # overall system replication status: ACTIVE # # Local System Replication State # # mode: PRIMARY # site id: 1 # site name: HANA_S1[1,2] Wijzig de HANA-configuratie zodat communicatie voor HANA-systeemreplicatie wordt omgeleid via de virtuele netwerkinterfaces van HANA-systeemreplicatie.
Stop HANA op beide sites.
sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StopSystem HDBBewerk global.ini om de hosttoewijzing toe te voegen voor HANA-systeemreplicatie. Gebruik de IP-adressen uit het
hsrsubnet.sudo vi /usr/sap/HN1/SYS/global/hdb/custom/config/global.ini #Add the section [system_replication_hostname_resolution] 10.23.1.202 = hana-s1-db1 10.23.1.203 = hana-s1-db2 10.23.1.204 = hana-s1-db3 10.23.1.205 = hana-s2-db1 10.23.1.206 = hana-s2-db2 10.23.1.207 = hana-s2-db3Start HANA op beide sites.
sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StartSystem HDB
Zie Hostnaamomzetting voor systeemreplicatie voor meer informatie.
[AH] Schakel de firewall opnieuw in en open de benodigde poorten.
Schakel de firewall opnieuw in.
# Execute as root systemctl start firewalld systemctl enable firewalldOpen de benodigde firewallpoorten. U moet de poorten voor uw HANA-exemplaarnummer aanpassen.
Belangrijk
Maak firewallregels om communicatie tussen HANA en clientverkeer toe te staan. De vereiste poorten worden vermeld op TCP/IP-poorten van alle SAP-producten. De volgende opdrachten zijn slechts een voorbeeld. In dit scenario gebruikt u systeemnummer 03.
# Execute as root sudo firewall-cmd --zone=public --add-port={30301,30303,30306,30307,30313,30315,30317,30340,30341,30342,1128,1129,40302,40301,40307,40303,40340,50313,50314,30310,30302}/tcp --permanent sudo firewall-cmd --zone=public --add-port={30301,30303,30306,30307,30313,30315,30317,30340,30341,30342,1128,1129,40302,40301,40307,40303,40340,50313,50314,30310,30302}/tcp
Een Pacemaker-cluster maken
Als u een eenvoudig Pacemaker-cluster wilt maken, volgt u de stappen in Het instellen van Pacemaker in Red Hat Enterprise Linux in Azure. Neem alle virtuele machines op, inclusief de meerderheidsmaker in het cluster.
Belangrijk
Stel niet in op quorum expected-votes 2. Dit is geen cluster met twee knooppunten. Zorg ervoor dat de clustereigenschap concurrent-fencing is ingeschakeld, zodat knooppuntafscheiding wordt gedeserialiseerd.
Bestandssysteembronnen maken
Voor het volgende deel van dit proces moet u bestandssysteembronnen maken. U doet dit als volgt:
[1,2] STOP SAP HANA op beide replicatiesites. Uitvoeren als <sid>adm.
sapcontrol -nr 03 -function StopSystem[AH] Ontkoppel het bestandssysteem
/hana/shared, dat tijdelijk is gekoppeld voor de installatie op alle HANA DB-VM's. Voordat u deze kunt ontkoppelen, moet u alle processen en sessies die gebruikmaken van het bestandssysteem stoppen.umount /hana/shared[1] Maak de bestandssysteemclusterbronnen voor
/hana/sharedde status Uitgeschakeld. U gebruikt--disabledomdat u de locatiebeperkingen moet definiëren voordat de koppelingen zijn ingeschakeld.
U hebt ervoor gekozen om /hana/shared te implementeren op NFS-share op Azure Files of NFS-volume in Azure NetApp Files.In dit voorbeeld wordt het bestandssysteem '/hana/shared' geïmplementeerd in Azure NetApp Files en gekoppeld via NFSv4.1. Volg de stappen in deze sectie, alleen als u NFS gebruikt in Azure NetApp Files.
# /hana/shared file system for site 1 pcs resource create fs_hana_shared_s1 --disabled ocf:heartbeat:Filesystem device=10.23.1.7:/HN1-shared-s1 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,timeo=600,rsize=262144,wsize=262144,proto=tcp,noatime,sec=sys,nfsvers=4.1,lock,_netdev' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # /hana/shared file system for site 2 pcs resource create fs_hana_shared_s2 --disabled ocf:heartbeat:Filesystem device=10.23.1.7:/HN1-shared-s1 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,timeo=600,rsize=262144,wsize=262144,proto=tcp,noatime,sec=sys,nfsvers=4.1,lock,_netdev' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # clone the /hana/shared file system resources for both site1 and site2 pcs resource clone fs_hana_shared_s1 meta clone-node-max=1 interleave=true pcs resource clone fs_hana_shared_s2 meta clone-node-max=1 interleave=true
Met de voorgestelde time-outwaarden kunnen de clusterresources bestand zijn tegen protocolspecifieke onderbreking, gerelateerd aan NFSv4.1-leasevernieuwingen in Azure NetApp Files. Zie NFS in NetApp Best practice voor meer informatie.
In dit voorbeeld wordt het bestandssysteem '/hana/shared' geïmplementeerd op NFS in Azure Files. Volg de stappen in deze sectie, alleen als u NFS in Azure Files gebruikt.
# /hana/shared file system for site 1 pcs resource create fs_hana_shared_s1 --disabled ocf:heartbeat:Filesystem device=sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,proto=tcp,noatime,nfsvers=4.1,lock' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # /hana/shared file system for site 2 pcs resource create fs_hana_shared_s2 --disabled ocf:heartbeat:Filesystem device=sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,proto=tcp,noatime,nfsvers=4.1,lock' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # clone the /hana/shared file system resources for both site1 and site2 pcs resource clone fs_hana_shared_s1 meta clone-node-max=1 interleave=true pcs resource clone fs_hana_shared_s2 meta clone-node-max=1 interleave=trueHet
OCF_CHECK_LEVEL=20kenmerk wordt toegevoegd aan de bewakingsbewerking, zodat bewakingsbewerkingen een lees-/schrijftest uitvoeren op het bestandssysteem. Zonder dit kenmerk controleert de bewakingsbewerking alleen of het bestandssysteem is gekoppeld. Dit kan een probleem zijn omdat wanneer de verbinding is verbroken, het bestandssysteem mogelijk gekoppeld blijft, ondanks dat het niet toegankelijk is.Het
on-fail=fencekenmerk wordt ook toegevoegd aan de bewakingsbewerking. Als met deze optie de monitorbewerking op een knooppunt mislukt, wordt dat knooppunt onmiddellijk omheining geplaatst. Zonder deze optie is het standaardgedrag om alle resources te stoppen die afhankelijk zijn van de mislukte resource, de mislukte resource opnieuw op te starten en vervolgens alle resources te starten die afhankelijk zijn van de mislukte resource. Dit gedrag kan niet alleen lang duren wanneer een SAP HANA-resource afhankelijk is van de mislukte resource, maar het kan ook helemaal mislukken. De SAP HANA-resource kan niet worden gestopt als de NFS-share met de binaire HANA-bestanden niet toegankelijk is.De time-outs in de bovenstaande configuraties moeten mogelijk worden aangepast aan de specifieke SAP-installatie.
[1] Configureer en verifieer de knooppuntkenmerken. Alle SAP HANA DB-knooppunten op replicatiesite 1 zijn toegewezen kenmerk
S1en alle SAP HANA DB-knooppunten op replicatiesite 2 zijn toegewezen kenmerkS2.# HANA replication site 1 pcs node attribute hana-s1-db1 NFS_SID_SITE=S1 pcs node attribute hana-s1-db2 NFS_SID_SITE=S1 pcs node attribute hana-s1-db3 NFS_SID_SITE=S1 # HANA replication site 2 pcs node attribute hana-s2-db1 NFS_SID_SITE=S2 pcs node attribute hana-s2-db2 NFS_SID_SITE=S2 pcs node attribute hana-s2-db3 NFS_SID_SITE=S2 # To verify the attribute assignment to nodes execute pcs node attribute[1] Configureer de beperkingen die bepalen waar de NFS-bestandssystemen worden gekoppeld en schakel de bestandssysteembronnen in.
# Configure the constraints pcs constraint location fs_hana_shared_s1-clone rule resource-discovery=never score=-INFINITY NFS_SID_SITE ne S1 pcs constraint location fs_hana_shared_s2-clone rule resource-discovery=never score=-INFINITY NFS_SID_SITE ne S2 # Enable the file system resources pcs resource enable fs_hana_shared_s1 pcs resource enable fs_hana_shared_s2Wanneer u de bestandssysteembronnen inschakelt, koppelt het cluster de
/hana/sharedbestandssystemen.[AH] Controleer of de Azure NetApp Files-volumes zijn gekoppeld onder
/hana/shared, op alle HANA DB-VM's op beide sites.Als u bijvoorbeeld Azure NetApp Files gebruikt:
sudo nfsstat -m # Verify that flag vers is set to 4.1 # Example from SITE 1, hana-s1-db1 /hana/shared from 10.23.1.7:/HN1-shared-s1 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.11,local_lock=none,addr=10.23.1.7 # Example from SITE 2, hana-s2-db1 /hana/shared from 10.23.1.7:/HN1-shared-s2 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.14,local_lock=none,addr=10.23.1.7Als u bijvoorbeeld Azure Files NFS gebruikt:
sudo nfsstat -m # Example from SITE 1, hana-s1-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.19,local_lock=none,addr=10.23.0.35 # Example from SITE 2, hana-s2-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.22,local_lock=none,addr=10.23.0.35
[1] Configureer en kloon de kenmerkbronnen en configureer de beperkingen als volgt:
# Configure the attribute resources pcs resource create hana_nfs_s1_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs_s1_active pcs resource create hana_nfs_s2_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs_s2_active # Clone the attribute resources pcs resource clone hana_nfs_s1_active meta clone-node-max=1 interleave=true pcs resource clone hana_nfs_s2_active meta clone-node-max=1 interleave=true # Configure the constraints, which will set the attribute values pcs constraint order fs_hana_shared_s1-clone then hana_nfs_s1_active-clone pcs constraint order fs_hana_shared_s2-clone then hana_nfs_s2_active-cloneTip
Als uw configuratie andere bestandssystemen dan /
hana/sharedbevat en deze bestandssystemen zijn gekoppeld aan NFS, neemt u desequential=falseoptie op. Deze optie zorgt ervoor dat er geen volgordeafhankelijkheden zijn tussen de bestandssystemen. Alle gekoppelde NFS-bestandssystemen moeten worden gestart vóór de bijbehorende kenmerkresource, maar ze hoeven niet te beginnen in volgorde ten opzichte van elkaar. Zie Hoe kan ik SAP HANA scale-out HSR configureren in een Pacemaker-cluster wanneer de HANA-bestandssystemen NFS-shares zijn.[1] Plaats Pacemaker in de onderhoudsmodus, ter voorbereiding op het maken van de HANA-clusterbronnen.
pcs property set maintenance-mode=true
SAP HANA-clusterbronnen maken
U bent nu klaar om de clusterresources te maken:
[A] Installeer de HANA scale-out resourceagent op alle clusterknooppunten, met inbegrip van de maker van de meerderheid.
yum install -y resource-agents-sap-hana-scaleoutNotitie
Zie Ondersteuningsbeleid voor RHEL HA-clusters - Beheer van SAP HANA in een cluster voor de minimaal ondersteunde versie van het pakket
resource-agents-sap-hana-scaleoutvoor uw besturingssysteem.[1,2] Configureer de HANA-systeemreplicatiehook op één HANA DB-knooppunt op elke systeemreplicatiesite. SAP HANA moet nog steeds offline zijn.
resource-agents-sap-hana-scaleoutversie 0.185.3-0 of hoger bevat zowel hooks SAPHanaSR als ChkSrv. Het is verplicht voor de juiste clusterbewerking om de SAPHanaSR-hook in te schakelen. We raden u ten zeerste aan om zowel SAPHanaSR- als ChkSrv Python-hooks te configureren.global.iniaanpassen.# add to global.ini [ha_dr_provider_SAPHanaSR] provider = SAPHanaSR path = /usr/share/SAPHanaSR-ScaleOut execution_order = 1 [ha_dr_provider_chksrv] provider = ChkSrv path = /usr/share/SAPHanaSR-ScaleOut execution_order = 2 action_on_lost = kill [trace] ha_dr_saphanasr = info ha_dr_chksrv = info
Als u de parameter
pathnaar de standaardlocatie/usr/share/SAPHanaSR-ScaleOutwijst, wordt de Python-hookcode automatisch bijgewerkt via besturingssysteemupdates. HANA gebruikt de hookcode-updates wanneer deze opnieuw wordt opgestart. Met een optioneel eigen pad, zoals/hana/shared/myHooks, kunt u besturingssysteemupdates loskoppelen van de hook-versie die door HANA wordt gebruikt.U kunt het gedrag van hook aanpassen met behulp van
ChkSrvdeaction_on_lostparameter. Geldige waarden zijn [ignorekill|stop| ].Zie De SAP HANA srConnectionChanged() hook inschakelen en de SAP HANA srConnectionChanged() hook inschakelen en de SAP HANA srServiceStateChanged() hook inschakelen voor hdbindexserver process failure action (optioneel).
[AH] Voor het cluster is sudoers-configuratie op het clusterknooppunt vereist voor <sid>adm. In dit voorbeeld bereikt u dit door een nieuw bestand te maken. Voer de opdrachten uit als
root.sudo visudo -f /etc/sudoers.d/20-saphana # Insert the following lines and then save Cmnd_Alias SOK = /usr/sbin/crm_attribute -n hana_hn1_glob_srHook -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL = /usr/sbin/crm_attribute -n hana_hn1_glob_srHook -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SRREBOOT = /usr/sbin/crm_attribute -n hana_hn1_gsh -v * -l reboot -t crm_config -s SAPHanaSR hn1adm ALL=(ALL) NOPASSWD: SOK, SFAIL, SRREBOOT Defaults!SOK, SFAIL, SRREBOOT !requiretty[1,2] START SAP HANA op beide replicatiesites. Uitvoeren als <sid>adm.
sapcontrol -nr 03 -function StartSystem[1] Controleer de hookinstallatie. Voer als <sid>adm uit op de actieve HANA-systeemreplicatiesite.
cdtrace awk '/ha_dr_SAPHanaSR.*crm_attribute/ \ { printf "%s %s %s %s\n",$2,$3,$5,$16 }' nameserver_* # Example entries # 2020-07-21 22:04:52.782774 ha_dr_SAPHanaSR SFAIL # 2020-07-21 22:04:53.117492 ha_dr_SAPHanaSR SFAIL # 2020-07-21 22:06:35.599324 ha_dr_SAPHanaSR SOK[1] Controleer de ChkSrv-hookinstallatie. Voer als <sid>adm uit op de actieve HANA-systeemreplicatiesite.
cdtrace tail -20 nameserver_chksrv.trc[1] Maak de HANA-clusterbronnen. Voer de volgende opdrachten uit als
root.Zorg ervoor dat het cluster zich al in de onderhoudsmodus bevindt.
Maak vervolgens de HANA-topologieresource.
Als u een RHEL 7.x-cluster bouwt, gebruikt u de volgende opdrachten:pcs resource create SAPHanaTopology_HN1_HDB03 SAPHanaTopologyScaleOut \ SID=HN1 InstanceNumber=03 \ op start timeout=600 op stop timeout=300 op monitor interval=10 timeout=600 pcs resource clone SAPHanaTopology_HN1_HDB03 meta clone-node-max=1 interleave=trueAls u een RHEL >= 8.x-cluster bouwt, gebruikt u de volgende opdrachten:
pcs resource create SAPHanaTopology_HN1_HDB03 SAPHanaTopology \ SID=HN1 InstanceNumber=03 meta clone-node-max=1 interleave=true \ op methods interval=0s timeout=5 \ op start timeout=600 op stop timeout=300 op monitor interval=10 timeout=600 pcs resource clone SAPHanaTopology_HN1_HDB03 meta clone-node-max=1 interleave=trueMaak de HANA-exemplaarresource.
Notitie
Dit artikel bevat verwijzingen naar een term die microsoft niet meer gebruikt. Zodra de term uit de software wordt verwijderd, verwijderen we deze uit dit artikel.
Als u een RHEL 7.x-cluster bouwt, gebruikt u de volgende opdrachten:
pcs resource create SAPHana_HN1_HDB03 SAPHanaController \ SID=HN1 InstanceNumber=03 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=false \ op start interval=0 timeout=3600 op stop interval=0 timeout=3600 op promote interval=0 timeout=3600 \ op monitor interval=60 role="Master" timeout=700 op monitor interval=61 role="Slave" timeout=700 pcs resource master msl_SAPHana_HN1_HDB03 SAPHana_HN1_HDB03 \ meta master-max="1" clone-node-max=1 interleave=trueAls u een RHEL >= 8.x-cluster bouwt, gebruikt u de volgende opdrachten:
pcs resource create SAPHana_HN1_HDB03 SAPHanaController \ SID=HN1 InstanceNumber=03 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=false \ op demote interval=0s timeout=320 op methods interval=0s timeout=5 \ op start interval=0 timeout=3600 op stop interval=0 timeout=3600 op promote interval=0 timeout=3600 \ op monitor interval=60 role="Master" timeout=700 op monitor interval=61 role="Slave" timeout=700 pcs resource promotable SAPHana_HN1_HDB03 \ meta master-max="1" clone-node-max=1 interleave=trueBelangrijk
Het is een goed idee om in te stellen
AUTOMATED_REGISTERfalseop , terwijl u failovertests uitvoert, om te voorkomen dat een mislukt primair exemplaar automatisch wordt geregistreerd als secundair. Na het testen, als best practice, ingesteldAUTOMATED_REGISTERoptrue, zodat na overname de systeemreplicatie automatisch kan worden hervat.Maak het virtuele IP-adres en de bijbehorende resources.
pcs resource create vip_HN1_03 ocf:heartbeat:IPaddr2 ip=10.23.0.18 op monitor interval="10s" timeout="20s" sudo pcs resource create nc_HN1_03 azure-lb port=62503 sudo pcs resource group add g_ip_HN1_03 nc_HN1_03 vip_HN1_03Maak de clusterbeperkingen.
Als u een RHEL 7.x-cluster bouwt, gebruikt u de volgende opdrachten:
#Start HANA topology, before the HANA instance pcs constraint order SAPHanaTopology_HN1_HDB03-clone then msl_SAPHana_HN1_HDB03 pcs constraint colocation add g_ip_HN1_03 with master msl_SAPHana_HN1_HDB03 4000 #HANA resources are only allowed to run on a node, if the node's NFS file systems are mounted. The constraint also avoids the majority maker node pcs constraint location SAPHanaTopology_HN1_HDB03-clone rule resource-discovery=never score=-INFINITY hana_nfs_s1_active ne true and hana_nfs_s2_active ne trueAls u een RHEL >= 8.x-cluster bouwt, gebruikt u de volgende opdrachten:
#Start HANA topology, before the HANA instance pcs constraint order SAPHanaTopology_HN1_HDB03-clone then SAPHana_HN1_HDB03-clone pcs constraint colocation add g_ip_HN1_03 with master SAPHana_HN1_HDB03-clone 4000 #HANA resources are only allowed to run on a node, if the node's NFS file systems are mounted. The constraint also avoids the majority maker node pcs constraint location SAPHanaTopology_HN1_HDB03-clone rule resource-discovery=never score=-INFINITY hana_nfs_s1_active ne true and hana_nfs_s2_active ne true
[1] Plaats het cluster buiten de onderhoudsmodus. Zorg ervoor dat de clusterstatus is
oken dat alle resources zijn gestart.sudo pcs property set maintenance-mode=false #If there are failed cluster resources, you may need to run the next command pcs resource cleanupNotitie
De time-outs in de voorgaande configuratie zijn slechts voorbeelden en moeten mogelijk worden aangepast aan de specifieke HANA-installatie. U moet bijvoorbeeld de time-out voor de start verhogen als het langer duurt om de SAP HANA-database te starten.
Active/read-enabled systeemreplicatie van HANA configureren
Vanaf SAP HANA 2.0 SPS 01 staat SAP configuraties met actief/gelezen functionaliteit toe voor sap HANA-systeemreplicatie. Met deze mogelijkheid kunt u de secundaire systemen van SAP HANA-systeemreplicatie actief gebruiken voor leesintensieve workloads. Ter ondersteuning van een dergelijke installatie in een cluster hebt u een tweede virtueel IP-adres nodig, waarmee clients toegang hebben tot de secundaire SAP HANA-database met leesfunctionaliteit. Om ervoor te zorgen dat de secundaire replicatiesite nog steeds toegankelijk is nadat een overname is uitgevoerd, moet het cluster het virtuele IP-adres verplaatsen met de secundaire van de SAP HANA-resource.
In deze sectie worden de aanvullende stappen beschreven die u moet uitvoeren voor het beheren van dit type systeemreplicatie in een Red Hat-cluster met hoge beschikbaarheid, met een tweede virtueel IP-adres.
Voordat u verdergaat, moet u ervoor zorgen dat u een Red Hat-cluster met hoge beschikbaarheid volledig hebt geconfigureerd, waarbij u een SAP HANA-database beheert, zoals eerder in dit artikel is beschreven.
Aanvullende installatie in Azure Load Balancer voor installatie met actief/gelezen functionaliteit
Als u wilt doorgaan met het inrichten van uw tweede virtuele IP-adres, moet u Ervoor zorgen dat u Azure Load Balancer hebt geconfigureerd zoals beschreven in Azure Load Balancer configureren.
Volg voor de standard load balancer deze aanvullende stappen voor dezelfde load balancer die u in de vorige sectie hebt gemaakt.
Maak een tweede front-end-IP-adresgroep:
- Open de load balancer, selecteer front-end-IP-adresgroep en selecteer Toevoegen.
- Voer de naam in van de tweede front-end-IP-adresgroep (bijvoorbeeld hana-secondaryIP).
- Stel de toewijzing in op Statisch en voer het IP-adres in (bijvoorbeeld 10.23.0.19).
- Selecteer OK.
- Nadat de nieuwe front-end-IP-adresgroep is gemaakt, noteert u het IP-adres van de groep.
Maak vervolgens een statustest:
- Open de load balancer, selecteer statustests en selecteer Toevoegen.
- Voer de naam in van de nieuwe statustest (bijvoorbeeld hana-secondaryhp).
- Selecteer TCP als protocol en poort 62603. Houd de intervalwaarde ingesteld op 5 en de drempelwaarde voor beschadigde status is ingesteld op 2.
- Selecteer OK.
Maak vervolgens de taakverdelingsregels:
- Open de load balancer, selecteer taakverdelingsregels en selecteer Toevoegen.
- Voer de naam in van de nieuwe load balancer-regel (bijvoorbeeld hana-secondarylb).
- Selecteer het front-end-IP-adres, de back-endpool en de statustest die u eerder hebt gemaakt (bijvoorbeeld hana-secondaryIP, hana-backend en hana-secondaryhp).
- Selecteer HA-poorten.
- Zorg ervoor dat u Zwevend IP-adres inschakelt.
- Selecteer OK.
Active/read-enabled systeemreplicatie van HANA configureren
De stappen voor het configureren van HANA-systeemreplicatie worden beschreven in de sectie SAP HANA 2.0-systeemreplicatie configureren. Als u een secundair scenario met leesbewerkingen implementeert, voert u tijdens het configureren van systeemreplicatie op het tweede knooppunt de volgende opdracht uit als hanasidadm:
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hana-s1-db1 --remoteInstance=03 --replicationMode=sync --name=HANA_S2 --operationMode=logreplay_readaccess
Een secundaire virtuele IP-adresresource toevoegen voor een installatie met actief/gelezen functionaliteit
U kunt het tweede virtuele IP-adres en de aanvullende beperkingen configureren met de volgende opdrachten. Als het secundaire exemplaar offline is, wordt het secundaire virtuele IP-adres overgeschakeld naar de primaire.
pcs property set maintenance-mode=true
pcs resource create secvip_HN1_03 ocf:heartbeat:IPaddr2 ip="10.23.0.19"
pcs resource create secnc_HN1_03 ocf:heartbeat:azure-lb port=62603
pcs resource group add g_secip_HN1_03 secnc_HN1_03 secvip_HN1_03
# RHEL 8.x:
pcs constraint location g_ip_HN1_03 rule score=500 role=master hana_hn1_roles eq "master1:master:worker:master" and hana_hn1_clone_state eq PROMOTED
pcs constraint location g_secip_HN1_03 rule score=50 hana_hn1_roles eq 'master1:master:worker:master'
pcs constraint order promote SAPHana_HN1_HDB03-clone then start g_ip_HN1_03
pcs constraint order start g_ip_HN1_03 then start g_secip_HN1_03
pcs constraint colocation add g_secip_HN1_03 with Slave SAPHana_HN1_HDB03-clone 5
# RHEL 7.x:
pcs constraint location g_ip_HN1_03 rule score=500 role=master hana_hn1_roles eq "master1:master:worker:master" and hana_hn1_clone_state eq PROMOTED
pcs constraint location g_secip_HN1_03 rule score=50 hana_hn1_roles eq 'master1:master:worker:master'
pcs constraint order promote msl_SAPHana_HN1_HDB03 then start g_ip_HN1_03
pcs constraint order start g_ip_HN1_03 then start g_secip_HN1_03
pcs constraint colocation add g_secip_HN1_03 with Slave msl_SAPHana_HN1_HDB03 5
pcs property set maintenance-mode=false
Zorg ervoor dat de clusterstatus is oken dat alle resources zijn gestart. Het tweede virtuele IP-adres wordt uitgevoerd op de secundaire site, samen met de secundaire SAP HANA-resource.
# Example output from crm_mon
#Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#
#Active resources:
#
#rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm
#Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1]
# Started: [ hana--s1-db1 hana-s1-db2 hana-s1-db3 ]
#Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2]
# Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active]
# Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ]
#Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active]
# Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03]
# Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03]
# Masters: [ hana-s1-db1 ]
# Slaves: [ hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Resource Group: g_ip_HN1_03
# nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s1-db1
# vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s1-db1
#Resource Group: g_secip_HN1_03
# secnc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s2-db1
# secvip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s2-db1
In de volgende sectie vindt u de typische set failovertests die moeten worden uitgevoerd.
Wanneer u een HANA-cluster test dat is geconfigureerd met een secundaire met leesfunctionaliteit, moet u rekening houden met het volgende gedrag van het tweede virtuele IP-adres:
Wanneer de clusterresource SAPHana_HN1_HDB03 naar de secundaire site (S2) wordt verplaatst, wordt het tweede virtuele IP-adres verplaatst naar de andere site, hana-s1-db1. Als u hebt geconfigureerd
AUTOMATED_REGISTER="false"en HANA-systeemreplicatie niet automatisch wordt geregistreerd, wordt het tweede virtuele IP-adres uitgevoerd op hana-s2-db1.Wanneer u de server vastloopt, worden de tweede virtuele IP-resources (secvip_HN1_03) en de Azure Load Balancer-poortresource (secnc_HN1_03) uitgevoerd op de primaire server, naast de primaire virtuele IP-resources. Terwijl de secundaire server offline is, maken de toepassingen die zijn verbonden met de HANA-database met leesfunctionaliteit verbinding met de primaire HANA-database. Dit gedrag is verwacht. Hiermee kunnen toepassingen die zijn verbonden met de HANA-database met leesfunctionaliteit werken terwijl een secundaire server niet beschikbaar is.
Tijdens failover en terugval kunnen de bestaande verbindingen voor toepassingen die gebruikmaken van het tweede virtuele IP-adres, worden onderbroken om verbinding te maken met de HANA-database.
SAP HANA-failover testen
Voordat u een test start, controleert u de replicatiestatus van het cluster en sap HANA-systeem.
Controleer of er geen mislukte clusteracties zijn.
#Verify that there are no failed cluster actions pcs status # Example #Stack: corosync #Current DC: hana-s-mm (version 1.1.19-8.el7_6.5-c3c624ea3d) - partition with quorum #Last updated: Thu Sep 24 06:00:20 2020 #Last change: Thu Sep 24 05:59:17 2020 by root via crm_attribute on hana-s1-db1 # #7 nodes configured #45 resources configured # #Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # #Active resources: # #rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm #Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1] # Started: [ hana--s1-db1 hana-s1-db2 hana-s1-db3 ] #Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] #Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03] # Masters: [ hana-s1-db1 ] # Slaves: [ hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Resource Group: g_ip_HN1_03 # nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s1-db1 # vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s1-db1Controleer of sap HANA-systeemreplicatie gesynchroniseerd is.
# Verify HANA HSR is in sync sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py" #| Database | Host | Port | Service Name | Volume ID | Site ID | Site Name | Secondary | Secondary| Secondary | Secondary | Secondary | Replication | Replication | Replication | #| | | | | | | | Host | Port | Site ID | Site Name | Active Status | Mode | Status | Status Details | #| -------- | ----------- | ----- | ------------ | --------- | ------- | --------- | ------------- | -------- | --------- | --------- | ------------- | ----------- | ----------- | -------------- | #| HN1 | hana-s1-db3 | 30303 | indexserver | 5 | 2 | HANA_S1 | hana-s2-db3 | 30303 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| HN1 | hana-s1-db2 | 30303 | indexserver | 4 | 2 | HANA_S1 | hana-s2-db2 | 30303 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| SYSTEMDB | hana-s1-db1 | 30301 | nameserver | 1 | 2 | HANA_S1 | hana-s2-db1 | 30301 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| HN1 | hana-s1-db1 | 30307 | xsengine | 2 | 2 | HANA_S1 | hana-s2-db1 | 30307 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| HN1 | hana-s1-db1 | 30303 | indexserver | 3 | 2 | HANA_S1 | hana-s2-db1 | 30303 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #status system replication site "1": ACTIVE #overall system replication status: ACTIVE #Local System Replication State #~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ #mode: PRIMARY #site id: 1 #site name: HANA_S1
Controleer de clusterconfiguratie voor een foutscenario wanneer een knooppunt geen toegang meer heeft tot de NFS-share (
/hana/shared).De SAP HANA-resourceagents zijn afhankelijk van binaire bestanden, opgeslagen op
/hana/shared, om bewerkingen uit te voeren tijdens de failover./hana/sharedBestandssysteem wordt gekoppeld via NFS in de gepresenteerde configuratie. Een test die kan worden uitgevoerd, is het maken van een tijdelijke firewallregel om de toegang tot het/hana/sharedgekoppelde NFS-bestandssysteem op een van de vm's van de primaire site te blokkeren. Met deze methode wordt gevalideerd dat er een failover van het cluster wordt uitgevoerd als de toegang tot/hana/sharedde actieve systeemreplicatiesite verloren gaat.Verwacht resultaat: wanneer u de toegang tot het
/hana/sharedgekoppelde NFS-bestandssysteem op een van de primaire site-VM's blokkeert, mislukt de bewakingsbewerking die lees-/schrijfbewerking uitvoert op het bestandssysteem, omdat het geen toegang heeft tot het bestandssysteem en HANA-resourcefailover activeert. Hetzelfde resultaat wordt verwacht wanneer uw HANA-knooppunt geen toegang meer heeft tot de NFS-share.U kunt de status van de clusterbronnen controleren door deze uit te voeren
crm_monofpcs status. Resourcestatus voordat u de test start:# Output of crm_mon #7 nodes configured #45 resources configured #Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # #Active resources: #rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm # Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03] # Masters: [ hana-s1-db1 ] # Slaves: [ hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Resource Group: g_ip_HN1_03 # nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s1-db1 # vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s1-db1Fout simuleren voor
/hana/shared:- Als u NFS op ANF gebruikt, bevestigt u eerst het IP-adres voor het
/hana/sharedANF-volume op de primaire site. U kunt dat doen door uit te voerendf -kh|grep /hana/shared. - Als u NFS in Azure Files gebruikt, moet u eerst het IP-adres van het privé-eindpunt voor uw opslagaccount bepalen.
Stel vervolgens een tijdelijke firewallregel in om de toegang tot het IP-adres van het
/hana/sharedNFS-bestandssysteem te blokkeren door de volgende opdracht uit te voeren op een van de primaire HANA-systeemreplicatiesite-VM's.In dit voorbeeld is de opdracht uitgevoerd op hana-s1-db1 voor ANF-volume
/hana/shared.iptables -A INPUT -s 10.23.1.7 -j DROP; iptables -A OUTPUT -d 10.23.1.7 -j DROPDe HANA-VM waartoe de toegang is verloren, moet opnieuw worden
/hana/sharedopgestart of gestopt, afhankelijk van de clusterconfiguratie. De clusterresources worden gemigreerd naar de andere HANA-systeemreplicatiesite.Als het cluster niet is gestart op de VM die opnieuw is opgestart, start u het cluster door het volgende uit te voeren:
# Start the cluster pcs cluster startWanneer het cluster wordt gestart, wordt het bestandssysteem
/hana/sharedautomatisch gekoppeld. Als u insteltAUTOMATED_REGISTER="false", moet u SAP HANA-systeemreplicatie configureren op de secundaire site. In dit geval kunt u deze opdrachten uitvoeren om SAP HANA opnieuw te configureren als secundair.# Execute on the secondary su - hn1adm # Make sure HANA is not running on the secondary site. If it is started, stop HANA sapcontrol -nr 03 -function StopWait 600 10 # Register the HANA secondary site hdbnsutil -sr_register --name=HANA_S1 --remoteHost=hana-s2-db1 --remoteInstance=03 --replicationMode=sync # Switch back to root and clean up failed resources pcs resource cleanup SAPHana_HN1_HDB03De status van de resources na de test:
# Output of crm_mon #7 nodes configured #45 resources configured #Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Active resources: #rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm # Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03] # Masters: [ hana-s2-db1 ] # Slaves: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db2 hana-s2-db3 ] # Resource Group: g_ip_HN1_03 # nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s2-db1 # vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s2-db1- Als u NFS op ANF gebruikt, bevestigt u eerst het IP-adres voor het
Het is een goed idee om de CONFIGURATIE van het SAP HANA-cluster grondig te testen door ook de tests uit te voeren die worden beschreven in HA voor SAP HANA op Azure-VM's op RHEL.
Volgende stappen
- Azure Virtual Machines plannen en implementeren voor SAP
- Azure Virtual Machines-implementatie voor SAP
- DBMS-implementatie van Azure Virtual Machines voor SAP
- NFS v4.1-volumes in Azure NetApp Files voor SAP HANA
- Zie Hoge beschikbaarheid van SAP HANA op Virtuele Azure-machines voor meer informatie over hoge beschikbaarheid en plan voor herstel na noodgevallen van SAP HANA op Azure-VM's.