Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In dit artikel wordt stapsgewijs uitgelegd hoe u SAP HANA Large Instances (HLIs) valideert, configureert en installeert in Azure (ook wel bekend als BareMetal Infrastructure).
Vereiste voorwaarden
Voordat u dit artikel leest, moet u vertrouwd raken met:
Zie ook:
- Azure-VM's verbinden met grote HANA-exemplaren
- Een virtueel netwerk verbinden met HANA Large Instances
Uw installatie plannen
De installatie van SAP HANA is uw verantwoordelijkheid. U kunt beginnen met het installeren van een nieuwe SAP HANA on Azure-server (Large Instances) nadat u de connectiviteit tussen uw virtuele Azure-netwerken en de HANA Large Instance-eenheid(en) tot stand hebt gebracht.
Opmerking
Per SAP-beleid moet de installatie van SAP HANA worden uitgevoerd door een persoon die het examen gecertificeerde SAP Technology Associate, sap HANA-installatiecertificeringsexamen of een SAP-gecertificeerde systeemintegrator (SI) is geslaagd.
Wanneer u van plan bent om HANA 2.0 te installeren, raadpleegt u de sap-ondersteuningsnotitie #2235581 - SAP HANA: ondersteunde besturingssystemen. Zorg ervoor dat het besturingssysteem wordt ondersteund met de SAP HANA-release die u installeert. Het ondersteunde besturingssysteem voor HANA 2.0 is meer beperkend dan het ondersteunde besturingssysteem voor HANA 1.0. Controleer of de release van het besturingssysteem waarin u geïnteresseerd bent, wordt ondersteund voor de specifieke HANA Large Instance. Gebruik deze lijst; selecteer de HLI om de details van de lijst met ondersteunde besturingssystemen voor die eenheid weer te geven.
Valideer het volgende voordat u begint met de HANA-installatie:
De HANA Large Instance-eenheid(en) valideren
Nadat u de HANA Large Instances van Microsoft hebt ontvangen, brengt u toegang tot en connectiviteit met deze exemplaren tot stand. Valideer vervolgens de volgende instellingen en pas deze indien nodig aan.
Controleer in Azure Portal of de exemplaren worden weergegeven met de juiste SKU's en het juiste besturingssysteem. Zie Azure HANA Large Instances-beheer via Azure Portal voor meer informatie.
Registreer het besturingssysteem van het exemplaar bij uw besturingssysteemprovider. Deze stap omvat het registreren van uw SUSE Linux-besturingssysteem in een exemplaar van het SUSE Subscription Management Tool (SMT) dat is geïmplementeerd in een VIRTUELE machine in Azure.
De grote instantie van HANA kan verbinding maken met dit SMT-exemplaar. (Zie SMT-server instellen voor SUSE Linux voor meer informatie. Als u een Red Hat-besturingssysteem gebruikt, moet het zijn geregistreerd bij Red Hat Subscription Manager waarmee u verbinding maakt. Zie de opmerkingen in What is SAP HANA on Azure (Large Instances)?voor meer informatie.
Deze stap is nodig voor het patchen van het besturingssysteem. Dit is uw verantwoordelijkheid. Zie de documentatie over het installeren en configureren van SMT voor SUSE.
Controleer op nieuwe patches en fixes van de specifieke release/versie van het besturingssysteem. Controleer of de HANA Large Instance de meest recente patches heeft. Soms zijn de nieuwste patches niet opgenomen, dus zorg ervoor dat u dit controleert.
Controleer de relevante SAP-opmerkingen voor het installeren en configureren van SAP HANA op de specifieke release/versie van het besturingssysteem. Microsoft configureert een HLI niet altijd volledig. Als u aanbevelingen of wijzigingen wijzigt in SAP-notities of -configuraties die afhankelijk zijn van afzonderlijke scenario's, kan dit onmogelijk zijn.
Lees daarom de SAP-opmerkingen met betrekking tot SAP HANA voor uw exacte Linux-release. Controleer ook de instellingen van de release/versie van het besturingssysteem en pas de configuratie-instellingen toe als u dat nog niet hebt gedaan.
Controleer met name de volgende parameters en pas deze uiteindelijk aan:
- net.core.rmem_max = 16777216
- net.core.wmem_max = 16777216
- net.core.rmem_default = 16777216
- net.core.wmem_default = 16777216
- net.core.optmem_max = 16777216
- net.ipv4.tcp_rmem = 65536 16777216 16777216
- net.ipv4.tcp_wmem = 65536 16777216 16777216
Vanaf SLES12 SP1 en Red Hat Enterprise Linux (RHEL) 7.2 moeten deze parameters worden ingesteld in een configuratiebestand in de map /etc/sysctl.d. Er moet bijvoorbeeld een configuratiebestand met de naam 91-NetApp-HANA.conf worden gemaakt. Voor oudere SLES- en RHEL-releases moeten deze parameters worden ingesteld in/etc/sysctl.conf.
Houd rekening met alle RHEL-releases die beginnen met RHEL 6.3:
- De parameter sunrpc.tcp_slot_table_entries = 128 moet worden ingesteld in/etc/modprobe.d/sunrpc-local.conf. Als het bestand niet bestaat, maakt u het eerst door de vermelding toe te voegen:
- opties sunrpc tcp_max_slot_table_entries=128
Controleer de systeemtijd van uw HANA Large Instance. De exemplaren worden ingezet met een systeemtijdzone. Deze tijdzone vertegenwoordigt de locatie van de Azure-regio waarin de HANA Large Instance-stempel zich bevindt. U kunt de systeemtijd of tijdzone wijzigen van de exemplaren waarvan u eigenaar bent.
Als u meer exemplaren in uw tenant bestelt, moet u de tijdzone van de nieuw geleverde exemplaren aanpassen. Microsoft heeft geen inzicht in de systeemtijdzone die u na de overdracht voor de exemplaren hebt ingesteld. Nieuw geïmplementeerde exemplaren worden mogelijk niet ingesteld in dezelfde tijdzone als degene waarnaar u hebt gewijzigd. Het is aan u om de tijdzone aan te passen van de instanties die, indien nodig, zijn overgedragen.
Controleer etc/hosts. Wanneer de blades worden overgedragen, hebben ze verschillende IP-adressen toegewezen voor verschillende doeleinden. Het is belangrijk om het bestand etc/hosts te controleren wanneer eenheden worden toegevoegd aan een bestaande tenant. Het bestand etc/hosts van de zojuist geïmplementeerde systemen wordt mogelijk niet correct onderhouden met de IP-adressen van systemen die eerder zijn geleverd. Zorg ervoor dat een nieuw geïmplementeerde instantie de namen kan oplossen van de eenheden die u eerder in uw tenant hebt geïmplementeerd.
Besturingssysteem
De wisselruimte van de geleverde installatiekopieën van het besturingssysteem is ingesteld op 2 GB volgens de SAP-ondersteuningsnotitie #1999997 - Veelgestelde vragen: SAP HANA-geheugen. Als u een andere instelling wilt, moet u deze zelf instellen.
SUSE Linux Enterprise Server 12 SP1 voor SAP-toepassingen is de distributie van Linux die is geïnstalleerd voor SAP HANA in Azure (Large Instances). Deze distributie biedt SAP-specifieke mogelijkheden, waaronder vooraf ingestelde parameters voor het effectief uitvoeren van SAP op SLES.
Zie voor verschillende nuttige bronnen met betrekking tot het implementeren van SAP HANA op SLES:
- Kennisbank/witboeken op de SUSE-website.
- SAP op SUSE op het SAP Community Network (SCN).
Deze resources omvatten informatie over het instellen van hoge beschikbaarheid, beveiliging die specifiek is voor SAP-bewerkingen en meer.
Hier volgen meer resources voor SAP op SUSE:
- SAP HANA op SUSE Linux site
- Best Practice voor SAP: Enqueue-replicatie – SAP NetWeaver op SUSE Linux Enterprise 12
- ClamSAP – SLES-virusbeveiliging voor SAP (inclusief SLES 12 voor SAP-toepassingen)
De volgende documenten zijn sap-ondersteuningsopmerkingen die van toepassing zijn op het implementeren van SAP HANA op SLES 12:
- Opmerking over SAP-ondersteuning #1944799 – SAP HANA-richtlijnen voor de installatie van het SLES-besturingssysteem
- Opmerking over SAP-ondersteuning #2205917 – aanbevolen besturingssysteeminstellingen voor SAP HANA DB voor SLES 12 voor SAP-toepassingen
- SAP-ondersteuningsnotitie #1984787 – SUSE Linux Enterprise Server 12: installatie-aanwijzingen
- SAP-ondersteuningsnotitie #171356 – SAP-software op Linux: algemene informatie
- Opmerking over SAP-ondersteuning #1391070 – Linux UUID-oplossingen
Red Hat Enterprise Linux voor SAP HANA is een andere aanbieding voor het uitvoeren van SAP HANA op grote instanties van HANA. Releases van RHEL 7.2 en 7.3 zijn beschikbaar en ondersteund. Zie de site SAP HANA op Red Hat voor meer informatie over SAP HANA op Red Hat Linux.
De volgende documenten zijn sap-ondersteuningsopmerkingen die van toepassing zijn op het implementeren van SAP HANA op Red Hat:
- SAP-ondersteuningsnotitie #2009879 - SAP HANA-richtlijnen voor het Red Hat Enterprise Linux-besturingssysteem (RHEL)
- Opmerking over SAP-ondersteuning #2292690 - SAP HANA DB: Aanbevolen besturingssysteeminstellingen voor RHEL 7
- Opmerking over SAP-ondersteuning #1391070 – Linux UUID-oplossingen
- Opmerking over SAP-ondersteuning #2228351 - Linux: SAP HANA Database SPS 11 revisie 110 (of hoger) op RHEL 6 of SLES 11
- Opmerking over SAP-ondersteuning #2397039 - Veelgestelde vragen: SAP op RHEL
- SAP-supportnotitie #2002167 - Red Hat Enterprise Linux 7.x: Installatie en upgrade
Tijdsynchronisatie
SAP-toepassingen die zijn gebouwd op de SAP NetWeaver-architectuur zijn gevoelig voor tijdverschillen voor de onderdelen van het SAP-systeem. SAP ABAP korte dumps met de fouttitel van ZDATE_LARGE_TIME_DIFF zijn waarschijnlijk met u bekend. Dat komt doordat deze korte dumps verschijnen wanneer de systeemtijd van verschillende servers of virtuele machines (VM's) te ver uit elkaar gaan.
Voor SAP HANA op Azure (grote instanties) is tijdsynchronisatie in Azure niet van toepassing op de rekeneenheden binnen de grote instanties. Het is ook niet van toepassing op het uitvoeren van SAP-toepassingen in systeemeigen Azure-VM's, omdat Azure ervoor zorgt dat de tijd van een systeem correct wordt gesynchroniseerd.
Als gevolg hiervan moet u een afzonderlijke tijdserver instellen. Deze server wordt gebruikt door SAP-toepassingsservers die worden uitgevoerd op Azure-VM's. Het wordt ook gebruikt door de SAP HANA-database-instanties die draaien op HANA Large Instances. De opslaginfrastructuur in Large Instance-configuraties is gesynchroniseerd met Network Time Protocol (NTP) servers.
Netwerken
Bij het ontwerpen van uw virtuele Azure-netwerken en het verbinden van deze virtuele netwerken met de HANA Large Instances, moet u de aanbevelingen volgen die worden beschreven in:
- Overzicht en architectuur van SAP HANA (Large Instance) in Azure
- Infrastructuur en connectiviteit van SAP HANA (Large Instances) in Azure
Hier volgen enkele details die het vermelden waard zijn over het netwerk van de afzonderlijke eenheden. Elke HANA Large Instance-eenheid wordt geleverd met twee of drie IP-adressen die zijn toegewezen aan twee of drie NIC-poorten (Network Interface Controller). Er worden drie IP-adressen gebruikt in HANA-uitschaalconfiguraties en het HANA-systeemreplicatiescenario. Een van de IP-adressen die zijn toegewezen aan de NIC van de eenheid is niet beschikbaar in de server-IP-adresgroep die wordt beschreven in het overzicht en de architectuur van SAP HANA (Large Instances) in Azure.
Zie HLI-ondersteunde scenario's voor meer informatie over Ethernet-details voor uw architectuur.
Opslag
De opslagindeling voor SAP HANA (Large Instances) wordt geconfigureerd door SAP HANA in Azure Service Management met behulp van de aanbevolen SAP-richtlijnen.
De ruwe grootten van de verschillende volumes met de verschillende HANA Large Instances-SKU's worden beschreven in het overzicht en de architectuur van SAP HANA (Large Instances) in Azure.
De naamconventies van de opslagvolumes worden vermeld in de volgende tabel:
| Opslaggebruik | Mountnaam | Volumenaam |
|---|---|---|
| HANA-gegevens | /hana/data/SID/mnt0000<m> | Opslag-IP:/hana_data_SID_mnt00001_tenant_vol |
| HANA-logboek | /hana/log/SID/mnt0000<m> | OPSLAG-IP:/hana_log_SID_mnt00001_tenant_vol |
| Back-up van HANA-logboek | /hana/log/backups | Opslag IP:/hana_log_backups_SID_mnt00001_tenant_vol |
| Gedeelde HANA | /hana/shared/SID | Opslag-IP:/hana_shared_SID_mnt00001_tenant_vol/gedeeld |
| usr/sap | /usr/sap/SID | Opslag-IP:/hana_shared_SID_mnt00001_tenant_vol/usr_sap |
SID is de systeem-id van het HANA-exemplaar.
Tenant is een interne inventarisatie van bewerkingen bij het implementeren van een tenant.
HANA usr/sap delen hetzelfde volume. De nomenclatuur van de koppelpunten bevat de systeem-id van de HANA-instanties en het koppelnummer. In opschaalimplementaties is er slechts één mount, zoals mnt00001. In uitschaalimplementaties ziet u zoveel mounts als u werkknooppunten en primaire knooppunten hebt.
In uitschaalomgevingen worden de gegevens-, logboek- en logboekback-upvolumes gedeeld en gekoppeld aan elk knooppunt in de uitschaalconfiguratie. Voor configuraties die meerdere SAP-exemplaren zijn, wordt een andere set volumes gemaakt en gekoppeld aan het grote HANA-exemplaar. Zie HLI-ondersteunde scenario's voor meer informatie over de opslagindeling voor uw scenario.
Grote HANA-exemplaren worden geleverd met ruime schijfruimte voor HANA/gegevens en een volume HANA/log/backup. We hebben de HANA/gegevens zo groot gemaakt omdat de opslagmomentopnamen hetzelfde schijfvolume gebruiken. Hoe meer opslagmomentopnamen u doet, hoe meer ruimte wordt verbruikt door momentopnamen in uw toegewezen opslagvolumes.
Het HANA-log-/backupvolume mag niet worden gebruikt als het volume voor databaseback-ups. Het is bedoeld om te worden gebruikt als het back-upvolume voor de HANA-transactielogboekback-ups. Zie sap HANA (large instances) hoge beschikbaarheid en herstel na noodgevallen in Azure voor meer informatie.
U kunt uw opslag verhogen door extra capaciteit aan te schaffen in stappen van 1 TB. Deze extra opslag kan als nieuwe volumes worden toegevoegd aan een HANA Large Instance.
Tijdens de onboarding met SAP HANA in Azure Service Management geeft u een gebruikers-id (UID) en groeps-id (GID) op voor de sidadm-gebruiker en sapsys-groep (bijvoorbeeld: 1000.500). Tijdens de installatie van het SAP HANA-systeem moet u dezelfde waarden gebruiken. Omdat u meerdere HANA-exemplaren op een eenheid wilt implementeren, krijgt u meerdere sets volumes (één set voor elk exemplaar). Dus tijdens de implementatie moet u het volgende definiëren:
- De SID van de verschillende HANA-exemplaren (sidadm is hiervan afgeleid).
- De geheugengrootten van de verschillende HANA-exemplaren. De geheugengrootte per instantie definieert de grootte van de volumes in elke afzonderlijke volumeset.
Op basis van aanbevelingen van de opslagprovider worden de volgende koppelingsopties geconfigureerd voor alle gekoppelde volumes (exclusief opstart-LUN):
- nfs rw, vers=4, hard, timeo=600, rsize=1048576, wsize=1048576, intr, noatime, lock 0 0
Deze koppelpunten zijn geconfigureerd in /etc/fstab, zoals wordt weergegeven in de volgende schermopnamen:

De uitvoer van de opdracht df -h op een S72m HANA Large Instance ziet er als volgt uit:
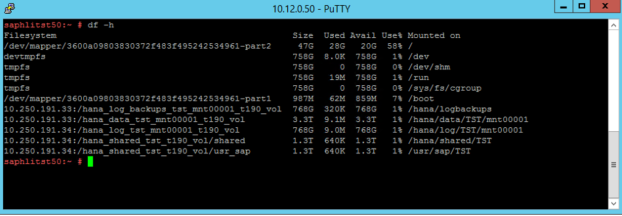
De opslagcontroller en knooppunten in de Large Instance-stempels worden gesynchroniseerd met NTP-servers. Het synchroniseren van sap HANA op Azure (grote exemplaren) en Azure-VM's op een NTP-server is belangrijk. Het elimineert aanzienlijke tijdsdrift tussen de infrastructuur en de rekeneenheden in Azure- of Large Instance-stempels.
Als u SAP HANA wilt optimaliseren voor de opslag die hieronder wordt gebruikt, stelt u de volgende SAP HANA-configuratieparameters in:
- max_parallel_io_requests 128
- async_read_submit op
- async_write_submit_active op
- async_write_submit_blocks alle
Voor SAP HANA 1.0-versies tot SPS12 kunnen deze parameters worden ingesteld tijdens de installatie van de SAP HANA-database, zoals beschreven in SAP-opmerking #2267798 - Configuratie van de SAP HANA-database.
U kunt de parameters ook configureren na de installatie van de SAP HANA-database met behulp van het hdbparam-framework.
De opslag die wordt gebruikt in HANA Large Instances heeft een beperking voor de bestandsgrootte. De groottebeperking is 16 TB per bestand. In tegenstelling tot beperkingen van de bestandsgrootte in de EXT3-bestandssystemen is HANA niet impliciet op de hoogte van de opslagbeperking die wordt afgedwongen door de HANA Large Instances-opslag. Als gevolg hiervan maakt HANA niet automatisch een nieuw gegevensbestand wanneer de bestandsgrootte van 16 TB is bereikt. Naarmate HANA het bestand groter probeert te maken dan 16 TB, rapporteert HANA fouten en loopt de indexserver vast aan het einde.
Belangrijk
Als u wilt voorkomen dat HANA gegevensbestanden probeert te laten groeien buiten de maximale bestandsgrootte van 16 TB van HANA Large Instance-opslag, stelt u de volgende parameters in het sap HANA-global.ini-configuratiebestand in:
Met SAP HANA 2.0 is het hdbparam-framework afgeschaft. De parameters moeten dus worden ingesteld met behulp van SQL-opdrachten. Zie SAP-opmerking #2399079: Verwijdering van hdbparam in HANA 2 voor meer informatie.
Raadpleeg ondersteunde HLI-scenario's voor meer informatie over de opslagindeling voor uw architectuur.
Volgende stappen
Doorloop de stappen voor het installeren van SAP HANA in Azure (Large Instances).