Hoge beschikbaarheid instellen in SUSE met behulp van het fencing-apparaat
In dit artikel doorlopen we de stappen voor het instellen van hoge beschikbaarheid (HA) in HANA Large Instances op het SUSE-besturingssysteem met behulp van het fencing-apparaat.
Notitie
Deze handleiding is afgeleid van het testen van de installatie in de Microsoft HANA Large Instances-omgeving. Het Microsoft Service Management-team voor grote HANA-exemplaren biedt geen ondersteuning voor het besturingssysteem. Neem contact op met SUSE voor probleemoplossing of verduidelijking van de laag van het besturingssysteem.
Het Microsoft Service Management-team heeft het schermscherm wel ingesteld en volledig ondersteund. Het kan helpen bij het oplossen van problemen met schermen van apparaten.
Vereisten
Als u hoge beschikbaarheid wilt instellen met behulp van SUSE-clustering, moet u het volgende doen:
- Grote HANA-exemplaren inrichten.
- Installeer en registreer het besturingssysteem met de nieuwste patches.
- Verbind HANA Large Instance-servers met de SMT-server om patches en pakketten op te halen.
- Network Time Protocol (NTP-tijdserver) instellen.
- Lees en begrijp de nieuwste SUSE-documentatie over het instellen van hoge beschikbaarheid.
Details van de installatie
In deze handleiding wordt de volgende installatie gebruikt:
- Besturingssysteem: SLES 12 SP1 voor SAP
- HANA Large Instances: 2xS192 (vier sockets, 2 TB)
- HANA-versie: HANA 2.0 SP1
- Servernamen: sapprdhdb95 (node1) en sapprdhdb96 (node2)
- Fencing-apparaat: op iSCSI gebaseerd
- NTP op een van de HANA Large Instance-knooppunten
Wanneer u HANA Large Instances instelt met HANA-systeemreplicatie, kunt u het Microsoft Service Management-team vragen om het schermapparaat in te stellen. Doe dit op het moment van inrichten.
Als u een bestaande klant bent met HANA Large Instances al ingericht, kunt u het schermapparaat nog steeds instellen. Geef de volgende informatie op aan het Microsoft Service Management-team in het serviceaanvraagformulier (SRF). U kunt de SRF ophalen via de Technical Account Manager of uw Microsoft-contactpersoon voor onboarding van grote HANA-exemplaren.
- Servernaam en server-IP-adres (bijvoorbeeld myhanaserver1 en 10.35.0.1)
- Locatie (bijvoorbeeld US - oost)
- Klantnaam (bijvoorbeeld Microsoft)
- HANA-systeem-id (SID) (bijvoorbeeld H11)
Nadat het fencing-apparaat is geconfigureerd, geeft het Microsoft Service Management-team u de SBD-naam en het IP-adres van de iSCSI-opslag. U kunt deze informatie gebruiken om de installatie van de schermen te configureren.
Volg de stappen in de volgende secties om hoge beschikbaarheid in te stellen met behulp van het hekapparaat.
Het SBD-apparaat identificeren
Notitie
Deze sectie is alleen van toepassing op bestaande klanten. Als u een nieuwe klant bent, geeft het Microsoft Service Management-team u de naam van het SBD-apparaat, dus sla deze sectie over.
Wijzig /etc/iscsi/initiatorname.isci in:
iqn.1996-04.de.suse:01:<Tenant><Location><SID><NodeNumber>Microsoft Service Management biedt deze tekenreeks. Wijzig het bestand op beide knooppunten. Het knooppuntnummer verschilt echter op elk knooppunt.
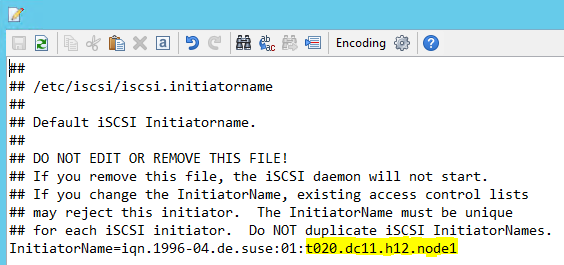
Wijzig /etc/iscsi/iscsid.conf door en
node.startup = automaticin te stellennode.session.timeo.replacement_timeout=5. Wijzig het bestand op beide knooppunten.Voer de volgende detectieopdracht uit op beide knooppunten.
iscsiadm -m discovery -t st -p <IP address provided by Service Management>:3260De resultaten tonen vier sessies.
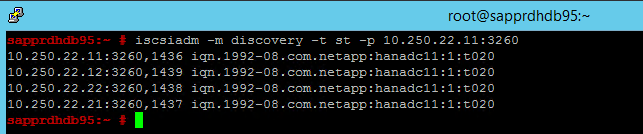
Voer de volgende opdracht uit op beide knooppunten om u aan te melden bij het iSCSI-apparaat.
iscsiadm -m node -lDe resultaten tonen vier sessies.

Gebruik de volgende opdracht om het script rescan-scsi-bus.sh opnieuw scannen uit te voeren. Dit script toont de nieuwe schijven die voor u zijn gemaakt. Voer deze uit op beide knooppunten.
rescan-scsi-bus.shDe resultaten moeten een LUN-getal weergeven dat groter is dan nul (bijvoorbeeld: 1, 2, enzovoort).
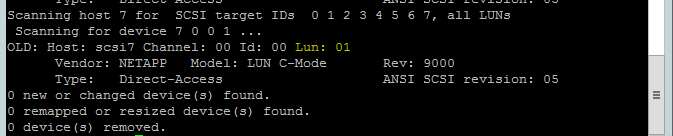
Voer de volgende opdracht uit op beide knooppunten om de apparaatnaam op te halen.
fdisk –lKies in de resultaten het apparaat met de grootte van 178 MiB.

Het SBD-apparaat initialiseren
Gebruik de volgende opdracht om het SBD-apparaat op beide knooppunten te initialiseren.
sbd -d <SBD Device Name> create
Gebruik de volgende opdracht op beide knooppunten om te controleren wat er naar het apparaat is geschreven.
sbd -d <SBD Device Name> dump
Het SUSE-cluster met hoge beschikbaarheid configureren
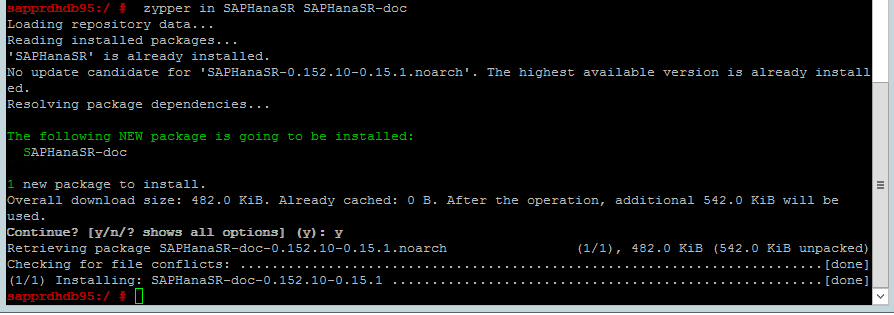
Gebruik de volgende opdracht om te controleren of ha_sles- en SAPHanaSR-doc-patronen op beide knooppunten zijn geïnstalleerd. Als ze niet zijn geïnstalleerd, installeert u ze.
zypper in -t pattern ha_sles zypper in SAPHanaSR SAPHanaSR-doc
Stel het cluster in met behulp van de
ha-cluster-initopdracht of de wizard yast2. In dit voorbeeld gebruiken we de wizard yast2. Voer deze stap alleen uit op het primaire knooppunt.Ga naar yast2>Cluster met hoge beschikbaarheid>.
Selecteer in het dialoogvenster dat wordt weergegeven over de installatie van het hawk-pakket annuleren omdat het halk2-pakket al is geïnstalleerd.
Selecteer Doorgaan in het dialoogvenster dat wordt weergegeven over doorgaan.
De verwachte waarde is het aantal geïmplementeerde knooppunten (in dit geval 2). Selecteer Next.
Voeg knooppuntnamen toe en selecteer vervolgens Voorgestelde bestanden toevoegen.
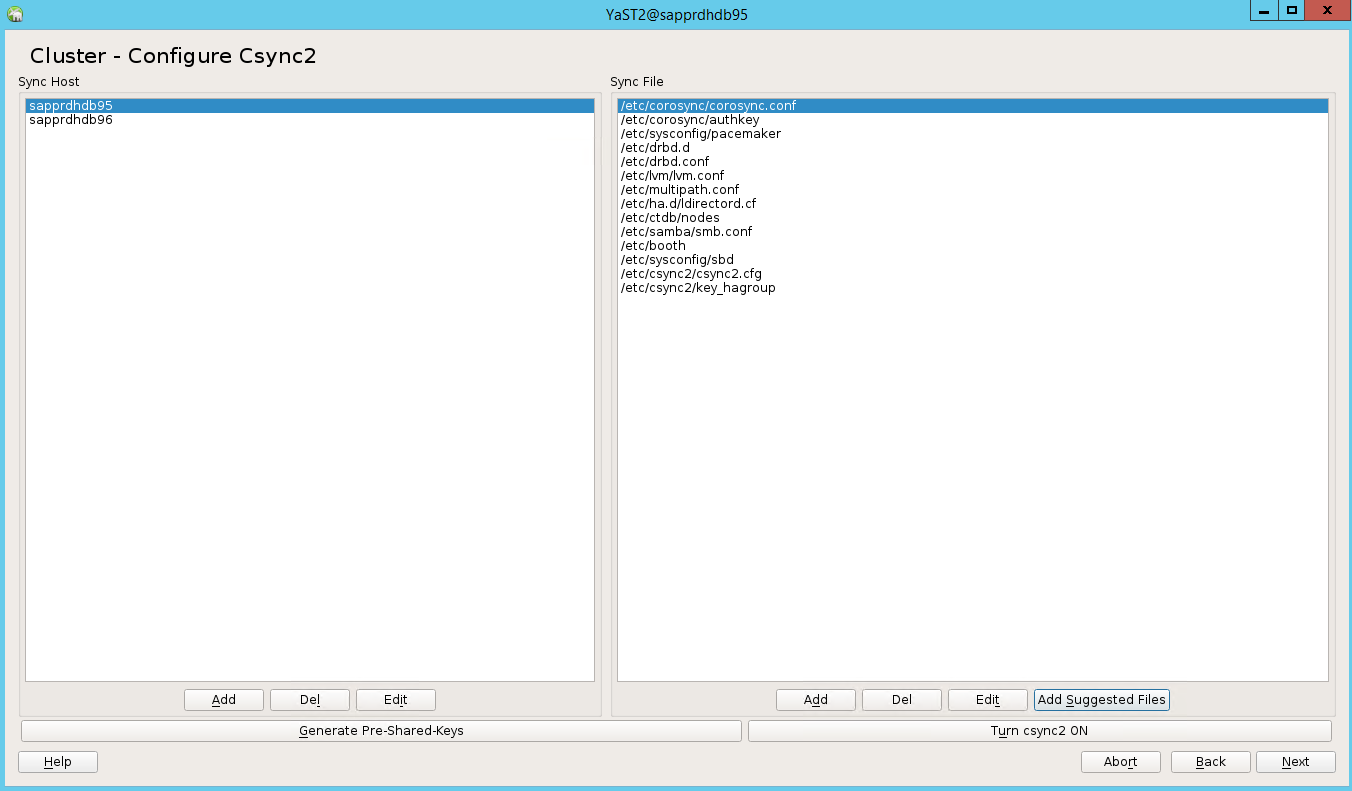
Selecteer Csync2 inschakelen.
Selecteer Vooraf gedeelde sleutels genereren.
Selecteer OK in het pop-upbericht dat wordt weergegeven.
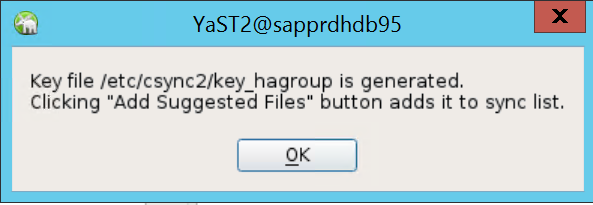
De verificatie wordt uitgevoerd met behulp van de IP-adressen en vooraf gedeelde sleutels in Csync2. Het sleutelbestand wordt gegenereerd met
csync2 -k /etc/csync2/key_hagroup.Kopieer het bestand key_hagroup handmatig naar alle leden van het cluster nadat het is gemaakt. Zorg ervoor dat u het bestand van node1 naar knooppunt2 kopieert. Selecteer vervolgens Volgende.
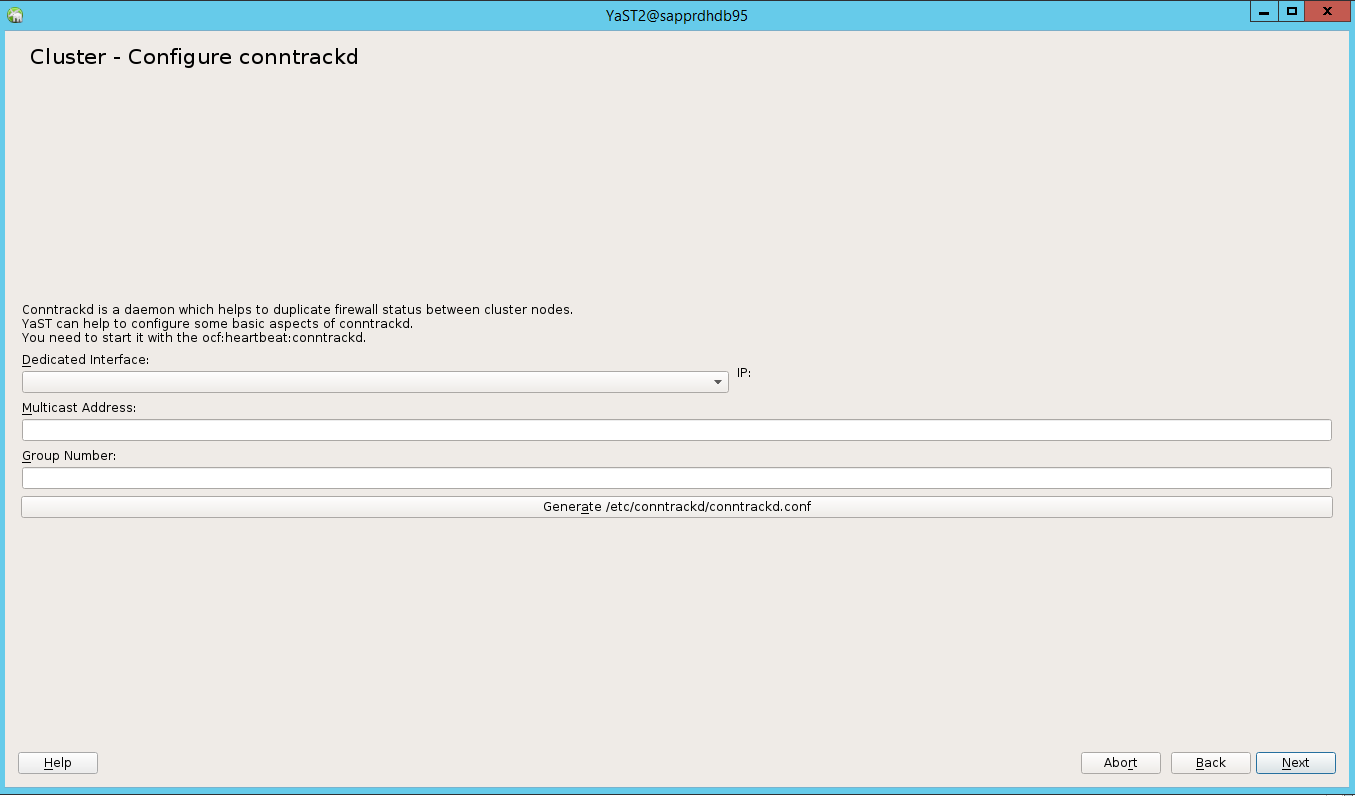
In de standaardoptie was Opstartenuit. Wijzig deze in Aan, zodat de pacemaker-service wordt gestart bij het opstarten. U kunt de keuze maken op basis van uw installatievereisten.
Selecteer Volgende en de clusterconfiguratie is voltooid.
De softdog-watchdog instellen
Voeg de volgende regel toe aan /etc/init.d/boot.local op beide knooppunten.
modprobe softdog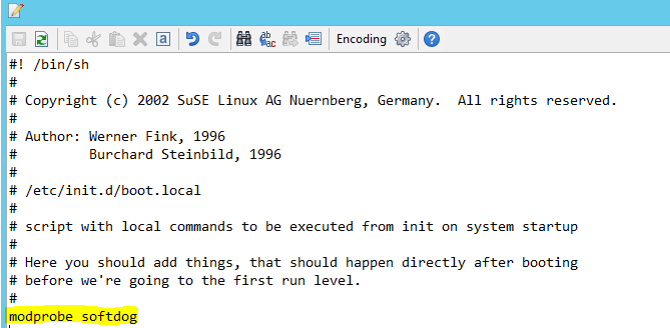
Gebruik de volgende opdracht om het bestand /etc/sysconfig/sbd op beide knooppunten bij te werken.
SBD_DEVICE="<SBD Device Name>"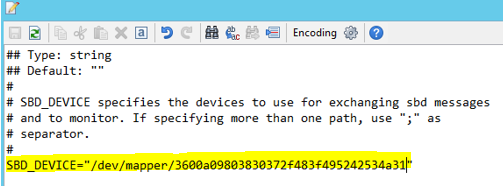
Laad de kernelmodule op beide knooppunten door de volgende opdracht uit te voeren.
modprobe softdog
Gebruik de volgende opdracht om ervoor te zorgen dat softdog wordt uitgevoerd op beide knooppunten.
lsmod | grep dog
Gebruik de volgende opdracht om het SBD-apparaat op beide knooppunten te starten.
/usr/share/sbd/sbd.sh start
Gebruik de volgende opdracht om de SBD-daemon op beide knooppunten te testen.
sbd -d <SBD Device Name> listDe resultaten tonen twee vermeldingen na configuratie op beide knooppunten.

Verzend het volgende testbericht naar een van uw knooppunten.
sbd -d <SBD Device Name> message <node2> <message>Gebruik op het tweede knooppunt (node2) de volgende opdracht om de status van het bericht te controleren.
sbd -d <SBD Device Name> list
Als u de SBD-configuratie wilt gebruiken, werkt u het bestand /etc/sysconfig/sbd als volgt bij op beide knooppunten.
SBD_DEVICE=" <SBD Device Name>" SBD_WATCHDOG="yes" SBD_PACEMAKER="yes" SBD_STARTMODE="clean" SBD_OPTS=""Gebruik de volgende opdracht om de pacemaker-service te starten op het primaire knooppunt (knooppunt1).
systemctl start pacemaker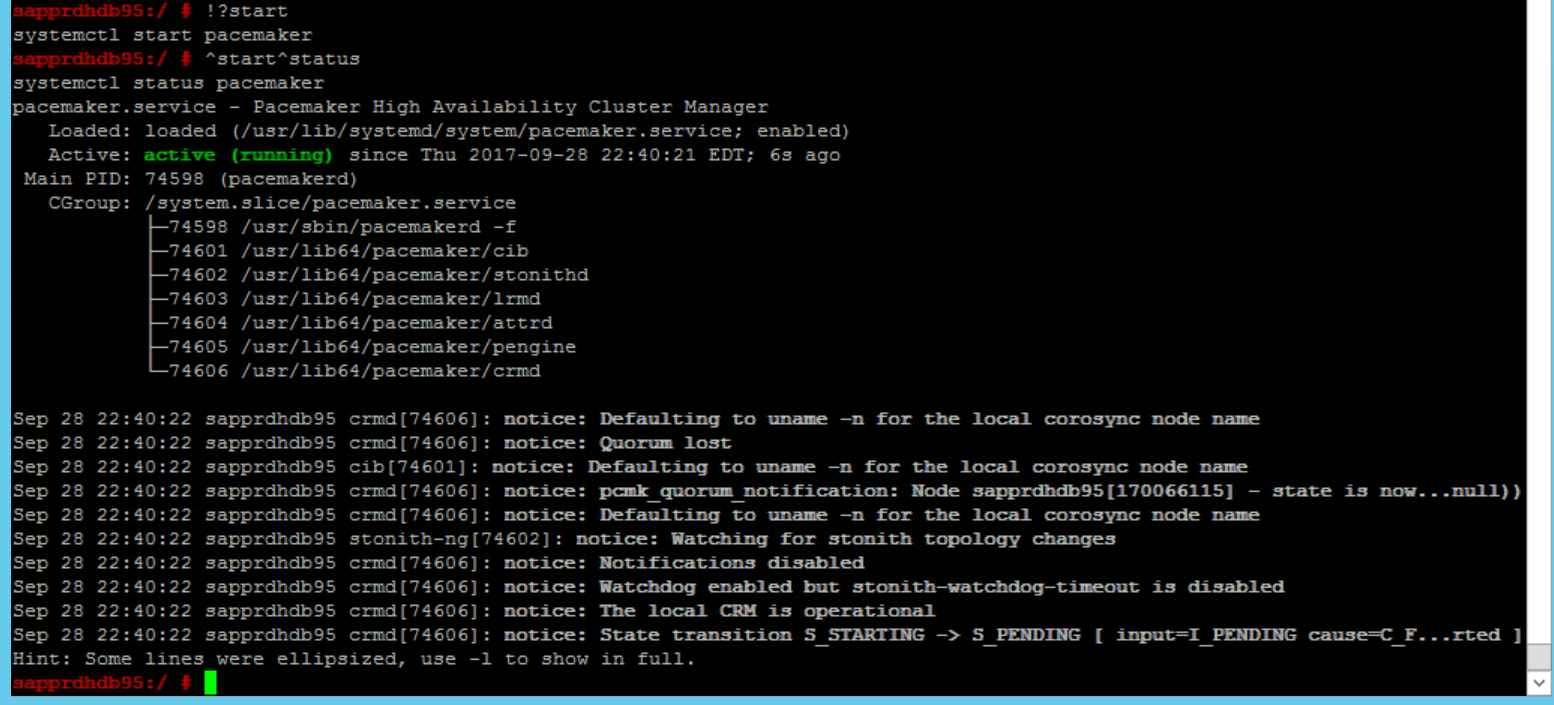
Als de pacemaker-service mislukt, raadpleegt u de sectie Scenario 5: Pacemaker-service mislukt verderop in dit artikel.
Het knooppunt toevoegen aan het cluster
Voer de volgende opdracht uit op node2 om dat knooppunt lid te laten worden van het cluster.
ha-cluster-join
Als u een fout ontvangt tijdens het toevoegen van het cluster, raadpleegt u de sectie Scenario 6: Node2 kan geen lid worden van het cluster verderop in dit artikel.
Het cluster valideren
Gebruik de volgende opdrachten om het cluster voor de eerste keer op beide knooppunten te controleren en optioneel te starten.
systemctl status pacemaker systemctl start pacemaker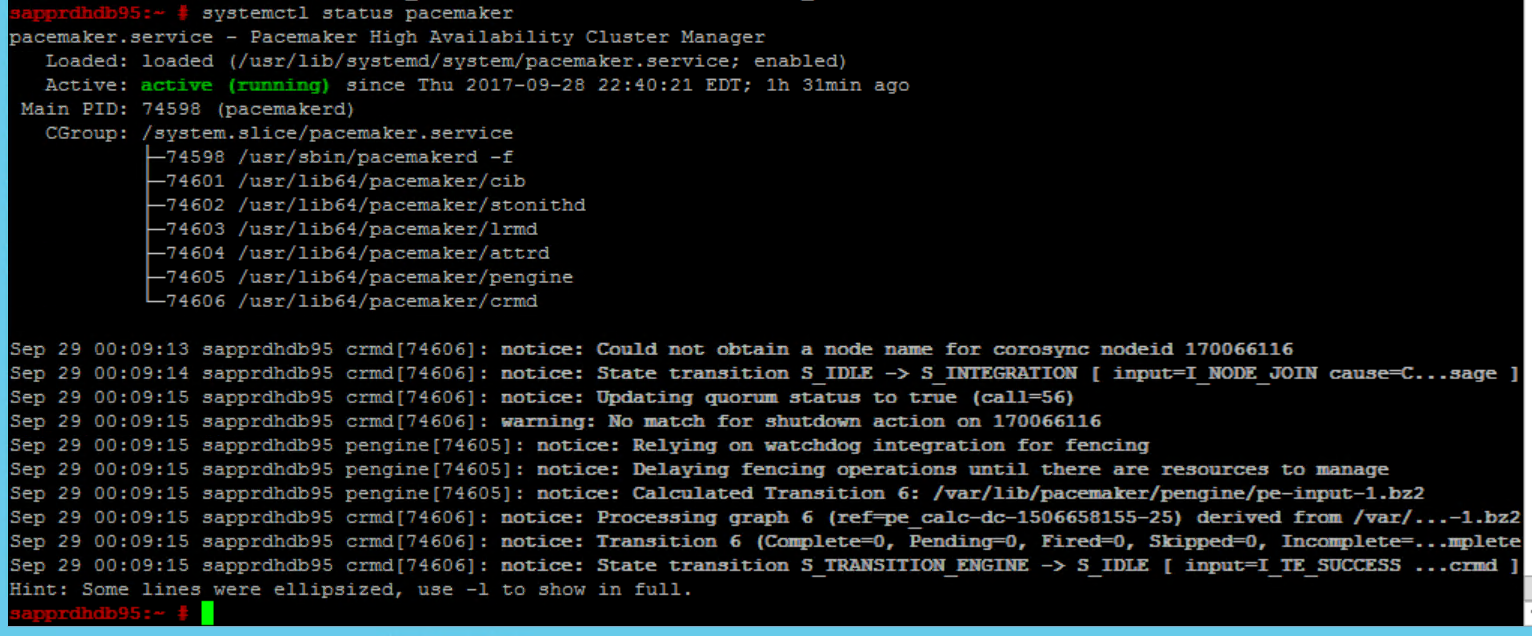
Voer de volgende opdracht uit om ervoor te zorgen dat beide knooppunten online zijn. U kunt deze uitvoeren op elk van de knooppunten van het cluster.
crm_mon
U kunt zich ook aanmelden bij hawk om de clusterstatus te controleren:
https://\<node IP>:7630. De standaardgebruiker is hacluster en het wachtwoord is linux. Indien nodig kunt u het wachtwoord wijzigen met behulp van depasswdopdracht .
Clustereigenschappen en -resources configureren
In deze sectie worden de stappen beschreven voor het configureren van de clusterresources. In dit voorbeeld stelt u de volgende resources in. U kunt de rest configureren (indien nodig) door te verwijzen naar de handleiding voor hoge beschikbaarheid van SUSE.
- Clusterboottrap
- Fencing-apparaat
- Virtueel IP-adres
Voer de configuratie alleen uit op het primaire knooppunt .
Maak het bootstrapbestand van het cluster en configureer het door de volgende tekst toe te voegen.
sapprdhdb95:~ # vi crm-bs.txt # enter the following to crm-bs.txt property $id="cib-bootstrap-options" \ no-quorum-policy="ignore" \ stonith-enabled="true" \ stonith-action="reboot" \ stonith-timeout="150s" rsc_defaults $id="rsc-options" \ resource-stickiness="1000" \ migration-threshold="5000" op_defaults $id="op-options" \ timeout="600"Gebruik de volgende opdracht om de configuratie toe te voegen aan het cluster.
crm configure load update crm-bs.txt
Configureer het fencing-apparaat door de resource toe te voegen, het bestand te maken en als volgt tekst toe te voegen.
# vi crm-sbd.txt # enter the following to crm-sbd.txt primitive stonith-sbd stonith:external/sbd \ params pcmk_delay_max="15"Gebruik de volgende opdracht om de configuratie toe te voegen aan het cluster.
crm configure load update crm-sbd.txtVoeg het virtuele IP-adres voor de resource toe door het bestand te maken en de volgende tekst toe te voegen.
# vi crm-vip.txt primitive rsc_ip_HA1_HDB10 ocf:heartbeat:IPaddr2 \ operations $id="rsc_ip_HA1_HDB10-operations" \ op monitor interval="10s" timeout="20s" \ params ip="10.35.0.197"Gebruik de volgende opdracht om de configuratie toe te voegen aan het cluster.
crm configure load update crm-vip.txtGebruik de
crm_monopdracht om de resources te valideren.In de resultaten worden de twee resources weergegeven.

U kunt de status ook controleren op het IP-adres> van https://< node:7630/cib/live/state.
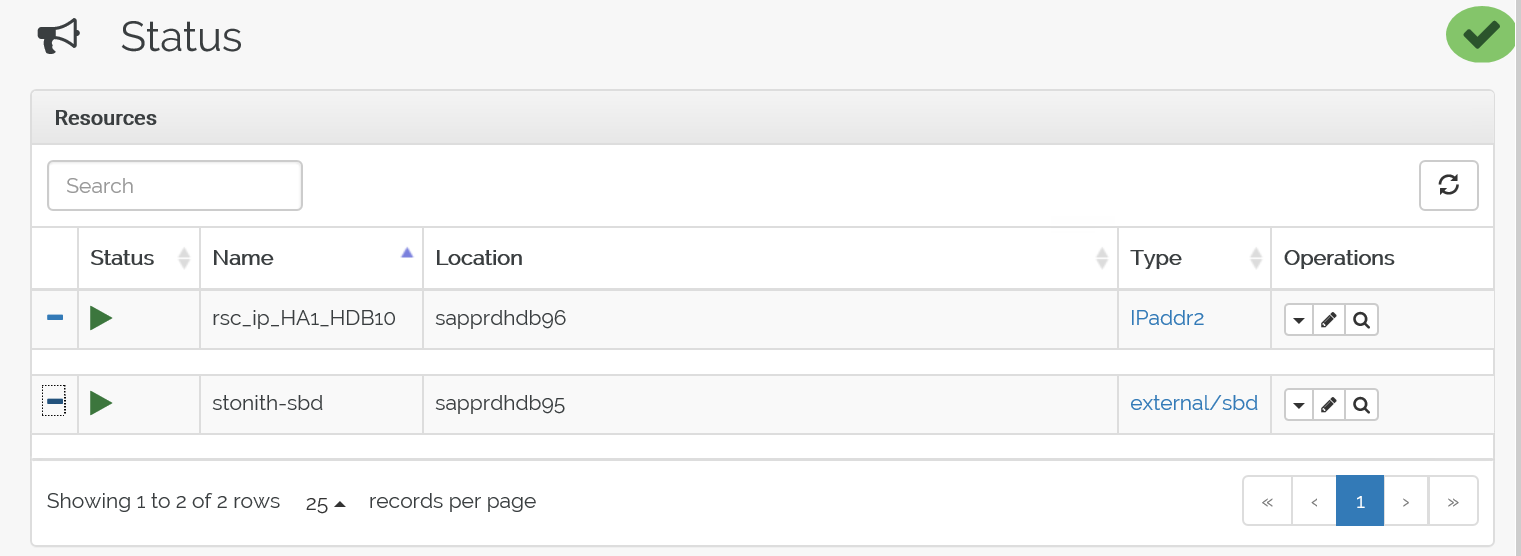
Het failoverproces testen
Als u het failoverproces wilt testen, gebruikt u de volgende opdracht om de pacemaker-service op knooppunt1 te stoppen.
Service pacemaker stopEr wordt een failover uitgevoerd voor de resources naar node2.
Stop de pacemaker-service op node2 en resources voeren een failover uit naar node1.
Dit is de status vóór failover:
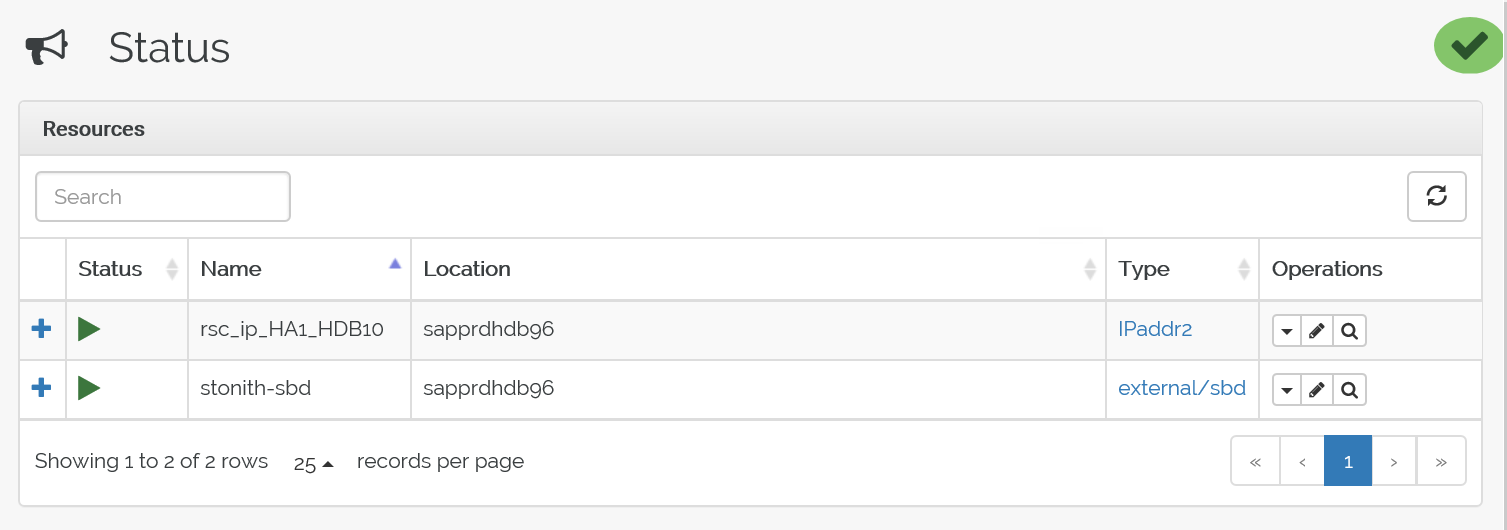
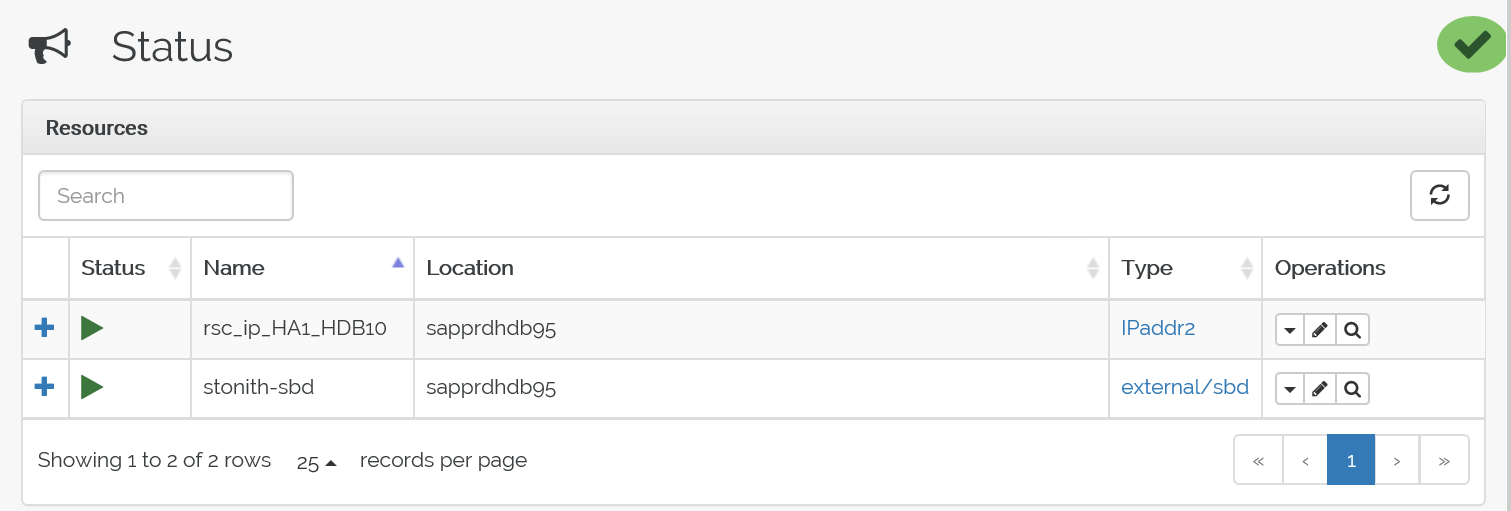
Dit is de status na een failover:

Problemen oplossen
In deze sectie worden foutscenario's beschreven die tijdens de installatie kunnen optreden.
Scenario 1: Clusterknooppunt niet online
Als een van de knooppunten niet online wordt weergegeven in Clusterbeheer, kunt u deze procedure proberen om deze online te brengen.
Gebruik de volgende opdracht om de iSCSI-service te starten.
service iscsid startGebruik de volgende opdracht om u aan te melden bij dat iSCSI-knooppunt.
iscsiadm -m node -lDe verwachte uitvoer ziet er als volgt uit:
sapprdhdb45:~ # iscsiadm -m node -l Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.11,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.12,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.22,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.21,3260] (multiple) Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.11,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.12,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.22,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.21,3260] successful.
Scenario 2: Yast2 geeft geen grafische weergave weer
Het grafische scherm yast2 wordt gebruikt om het cluster met hoge beschikbaarheid in dit artikel in te stellen. Als yast2 niet wordt geopend met het grafische venster zoals weergegeven en er een Qt-fout wordt gegenereerd, voert u de volgende stappen uit om de vereiste pakketten te installeren. Als het wordt geopend met het grafische venster, kunt u de stappen overslaan.
Hier volgt een voorbeeld van de Qt-fout:

Hier volgt een voorbeeld van de verwachte uitvoer:
Zorg ervoor dat u bent aangemeld als gebruiker 'root' en dat SMT is ingesteld om de pakketten te downloaden en te installeren.
Ga naar yast>Software>Software Management>Afhankelijkheden en selecteer vervolgens Aanbevolen pakketten installeren.
Notitie
Voer de stappen uit op beide knooppunten, zodat u toegang hebt tot de grafische weergave yast2 vanaf beide knooppunten.
In de volgende schermopname ziet u het verwachte scherm.
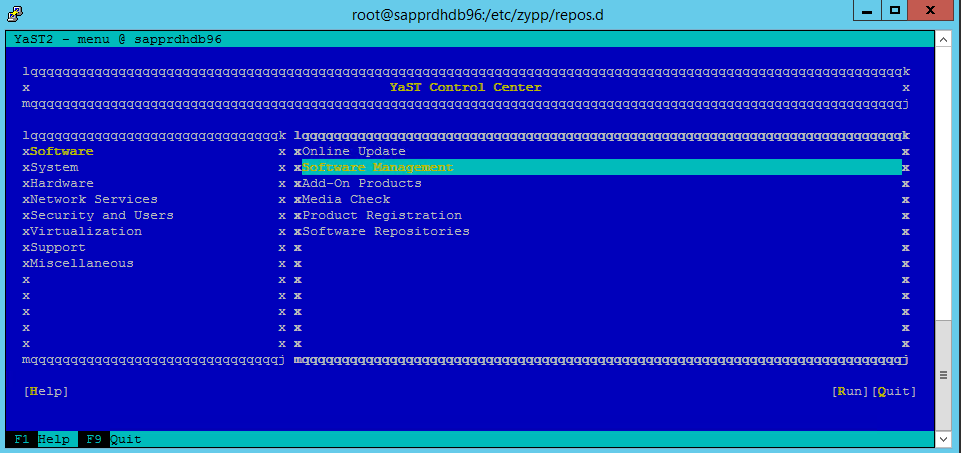
Selecteer onder Afhankelijkheden de optie Aanbevolen pakketten installeren.
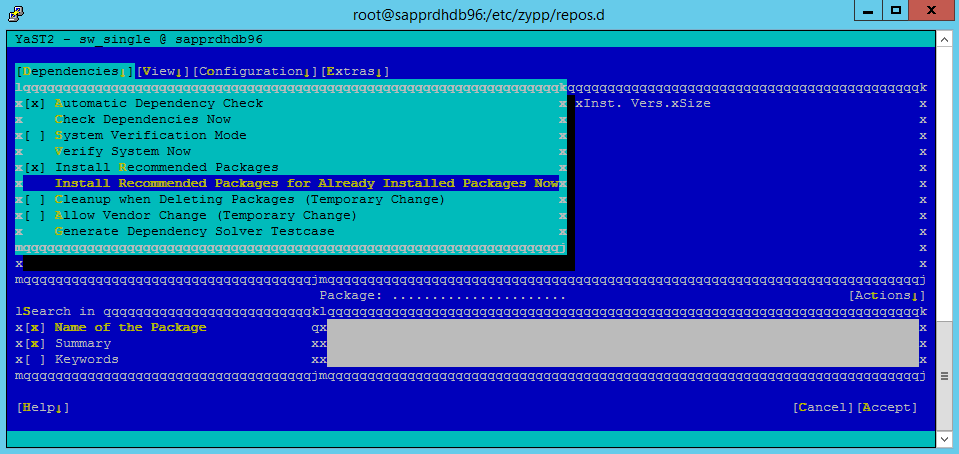
Controleer de wijzigingen en selecteer OK.
De installatie van het pakket wordt voortgezet.
Selecteer Next.
Wanneer het scherm Installatie voltooid wordt weergegeven, selecteert u Voltooien.
Gebruik de volgende opdrachten om de pakketten libqt4 en libyui-qt te installeren.
zypper -n install libqt4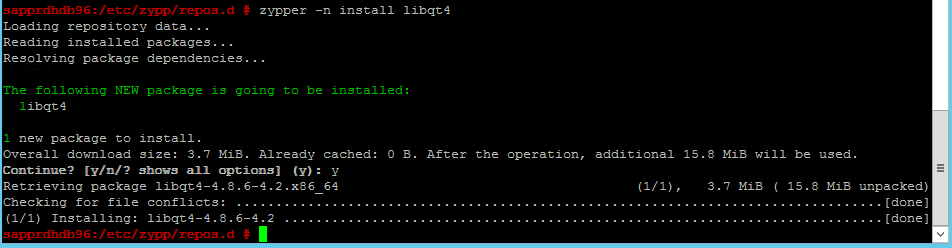
zypper -n install libyui-qt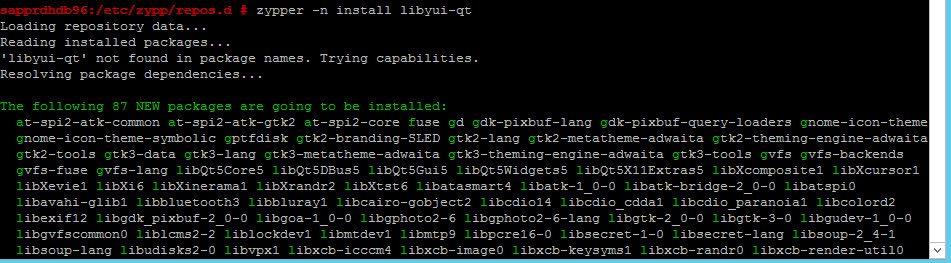

Yast2 kan nu de grafische weergave openen.
Scenario 3: Yast2 geeft de optie voor hoge beschikbaarheid niet weer
De optie voor hoge beschikbaarheid is alleen zichtbaar in het yast2-controlecentrum als u de andere pakketten installeert.
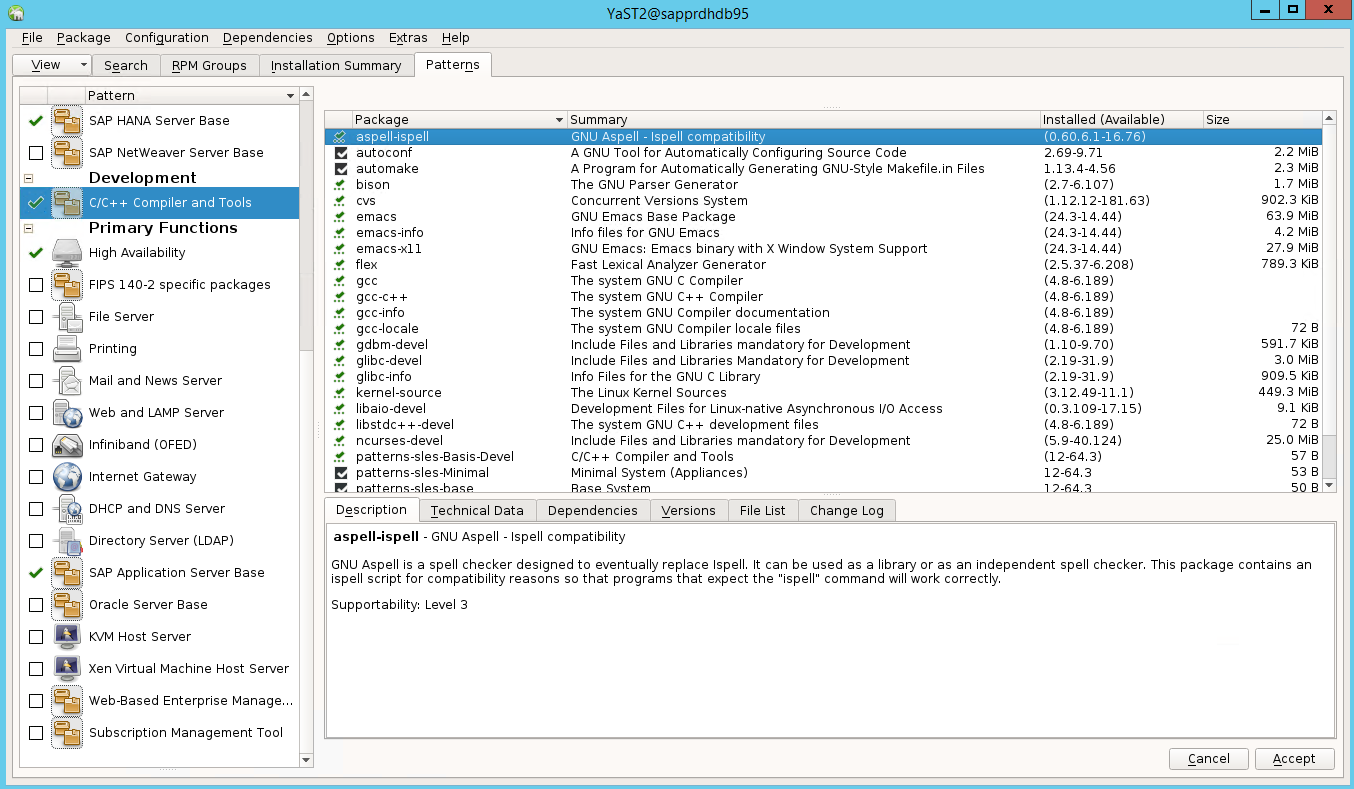
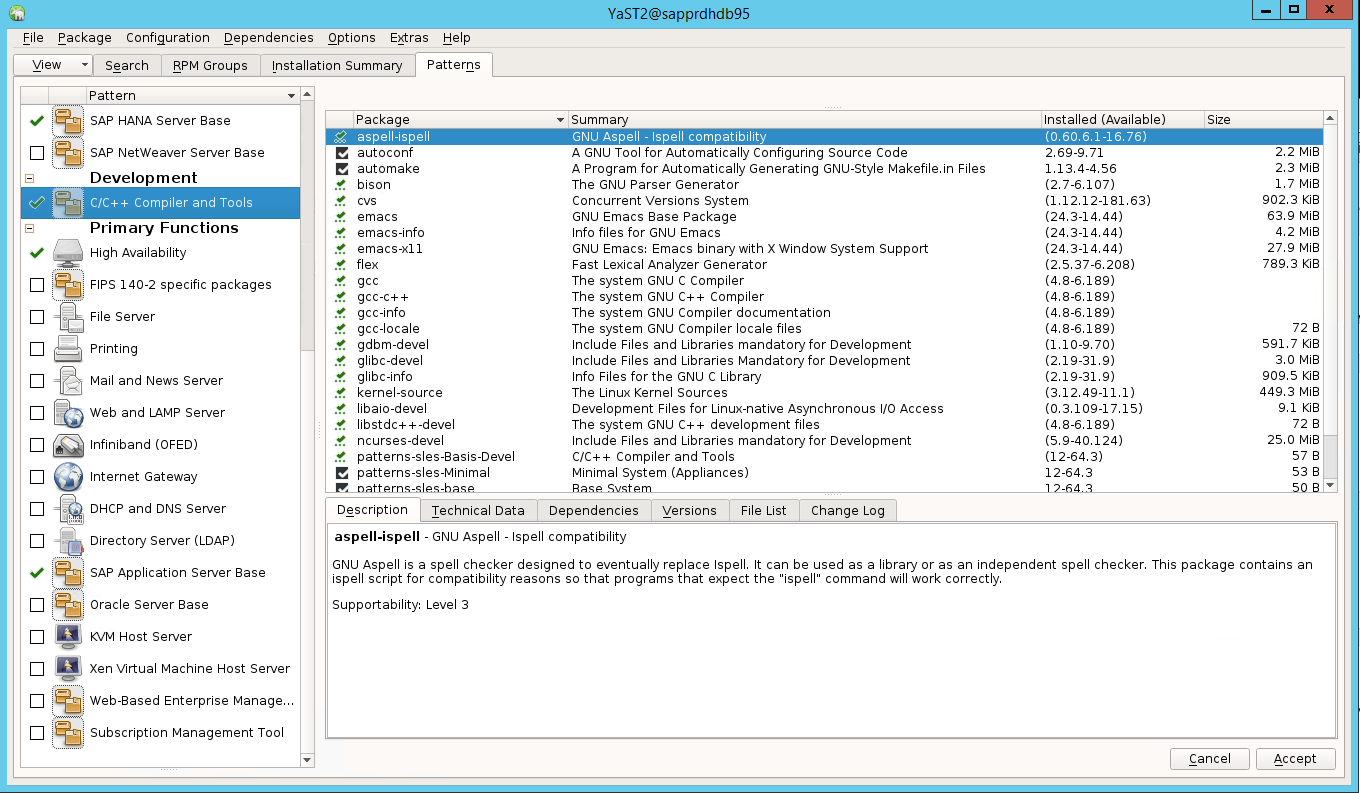
Ga naar Yast2>Software>Software Management. Selecteer vervolgens Software>Online Update.
Selecteer patronen voor de volgende items. Selecteer vervolgens Accepteren.
- SAP HANA-serverbasis
- C/C++-compiler en hulpprogramma's
- Hoge beschikbaarheid
- SAP-toepassingsserverbasis
Selecteer Doorgaan in de lijst met pakketten die zijn gewijzigd om afhankelijkheden op te lossen.
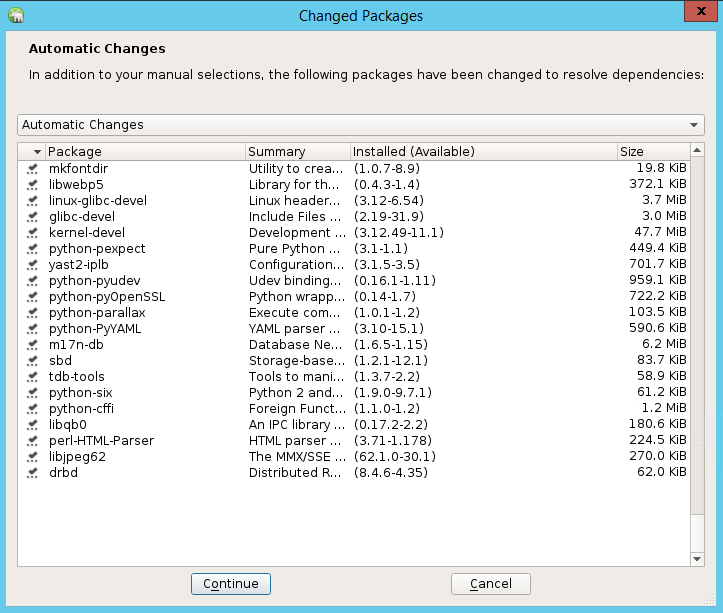
Selecteer op de pagina Installatiestatus uitvoerende optie Volgende.
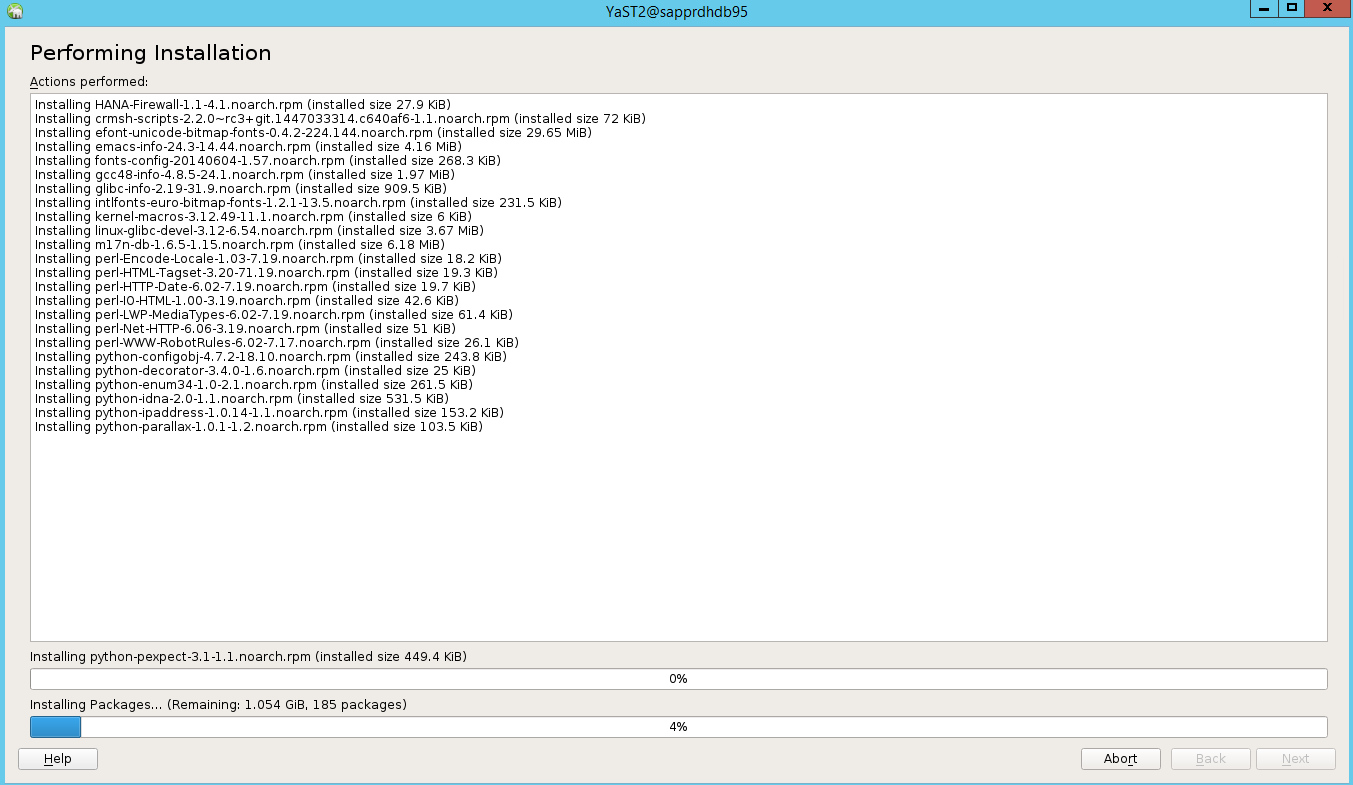
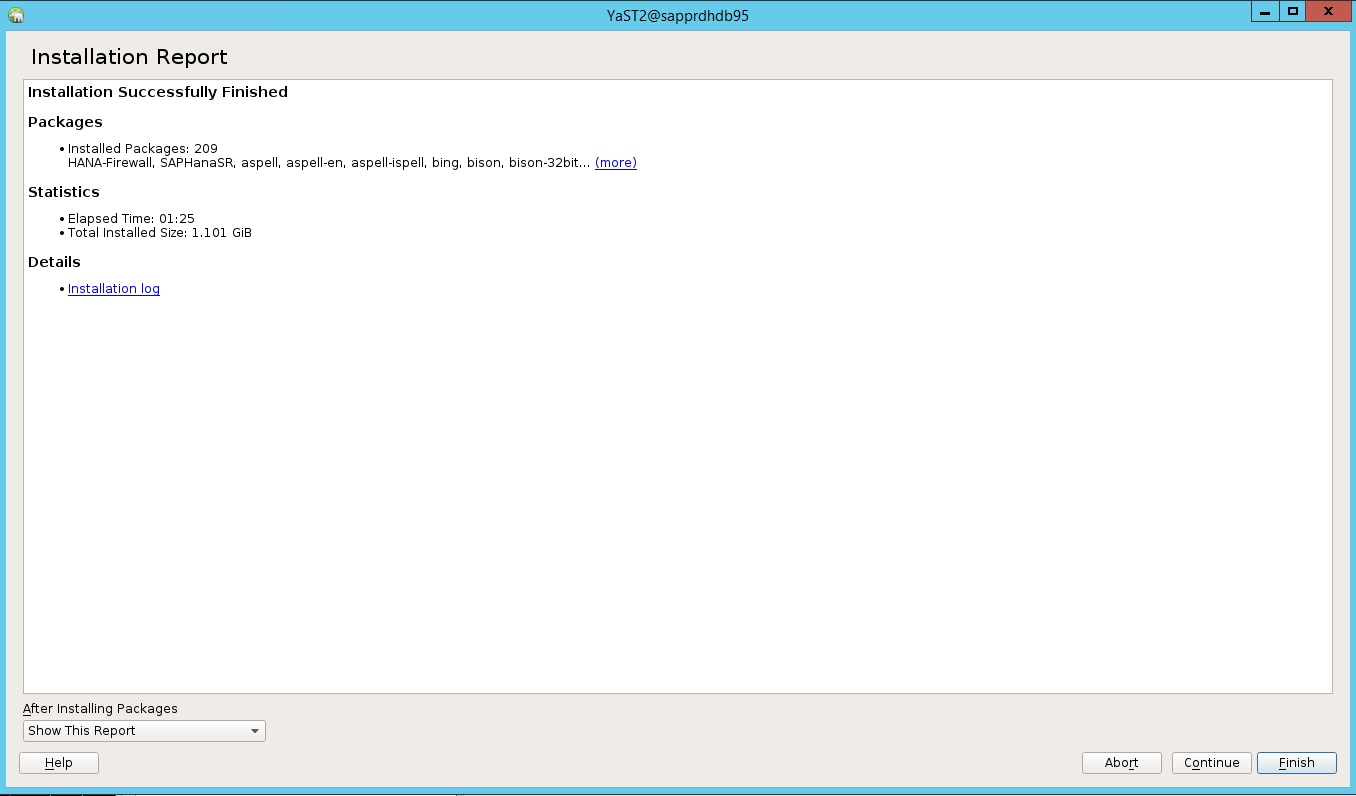
Wanneer de installatie is voltooid, wordt er een installatierapport weergegeven. Selecteer Finish.
Scenario 4: HANA-installatie mislukt met gcc-assembly's-fout
Als de installatie van HANA mislukt, krijgt u mogelijk de volgende fout.
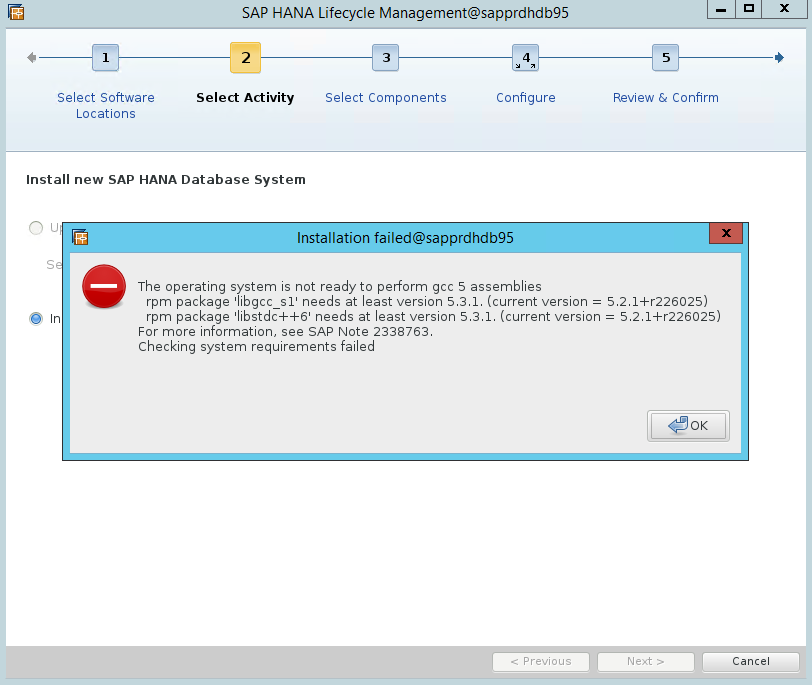
U kunt het probleem oplossen door de bibliotheken libgcc_sl en bibliothekentdc++6 te installeren, zoals wordt weergegeven in de volgende schermopname.
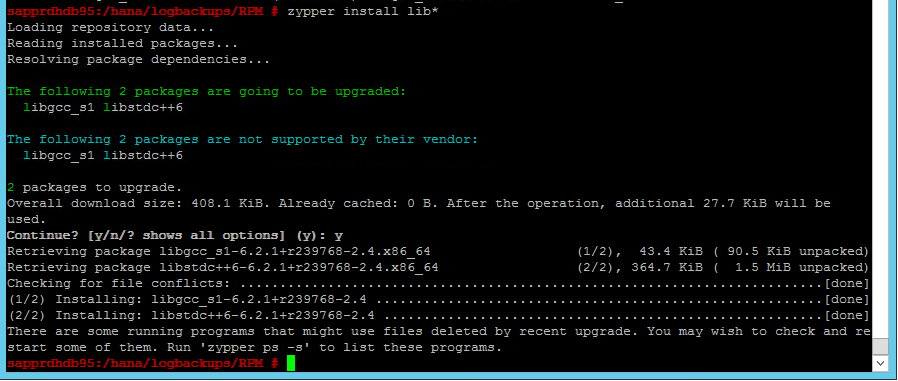
Scenario 5: Pacemaker-service mislukt
De volgende informatie wordt weergegeven als de pacemaker-service niet kan worden gestart.
sapprdhdb95:/ # systemctl start pacemaker
A dependency job for pacemaker.service failed. See 'journalctl -xn' for details.
sapprdhdb95:/ # journalctl -xn
-- Logs begin at Thu 2017-09-28 09:28:14 EDT, end at Thu 2017-09-28 21:48:27 EDT. --
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync configuration map
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync configuration ser
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync cluster closed pr
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync cluster quorum se
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync profile loading s
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [MAIN ] Corosync Cluster Engine exiting normally
Sep 28 21:48:27 sapprdhdb95 systemd[1]: Dependency failed for Pacemaker High Availability Cluster Manager
-- Subject: Unit pacemaker.service has failed
-- Defined-By: systemd
-- Support: https://lists.freedesktop.org/mailman/listinfo/systemd-devel
--
-- Unit pacemaker.service has failed.
--
-- The result is dependency.
sapprdhdb95:/ # tail -f /var/log/messages
2017-09-28T18:44:29.675814-04:00 sapprdhdb95 corosync[57600]: [QB ] withdrawing server sockets
2017-09-28T18:44:29.676023-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync cluster closed process group service v1.01
2017-09-28T18:44:29.725885-04:00 sapprdhdb95 corosync[57600]: [QB ] withdrawing server sockets
2017-09-28T18:44:29.726069-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync cluster quorum service v0.1
2017-09-28T18:44:29.726164-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync profile loading service
2017-09-28T18:44:29.776349-04:00 sapprdhdb95 corosync[57600]: [MAIN ] Corosync Cluster Engine exiting normally
2017-09-28T18:44:29.778177-04:00 sapprdhdb95 systemd[1]: Dependency failed for Pacemaker High Availability Cluster Manager.
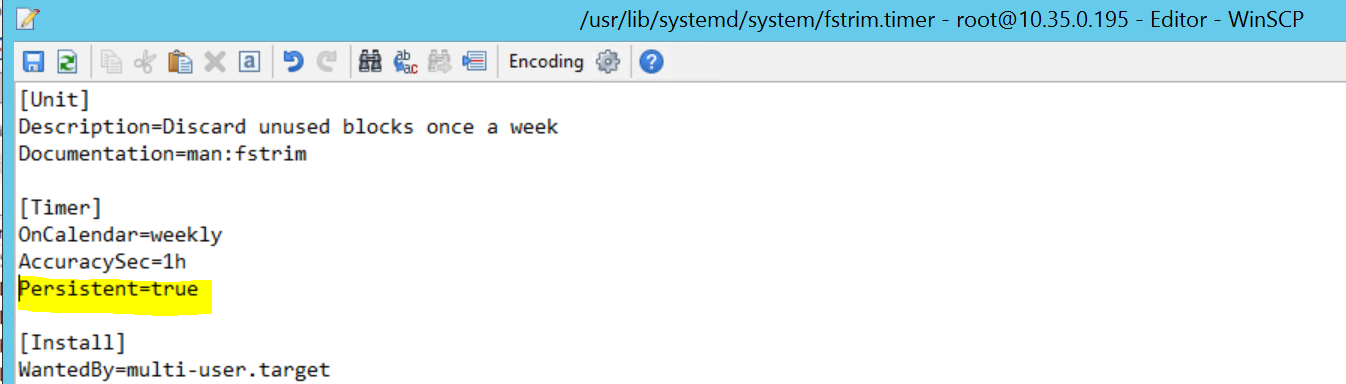
2017-09-28T18:44:40.141030-04:00 sapprdhdb95 systemd[1]: [/usr/lib/systemd/system/fstrim.timer:8] Unknown lvalue 'Persistent' in section 'Timer'
2017-09-28T18:45:01.275038-04:00 sapprdhdb95 cron[57995]: pam_unix(crond:session): session opened for user root by (uid=0)
2017-09-28T18:45:01.308066-04:00 sapprdhdb95 CRON[57995]: pam_unix(crond:session): session closed for user root
U kunt dit oplossen door de volgende regel te verwijderen uit het bestand /usr/lib/systemd/system/fstrim.timer:
Persistent=true
Scenario 6: Node2 kan niet deelnemen aan het cluster
De volgende fout wordt weergegeven als er een probleem is met het toevoegen van node2 aan het bestaande cluster via de opdracht ha-cluster-join .
ERROR: Can’t retrieve SSH keys from <Primary Node>
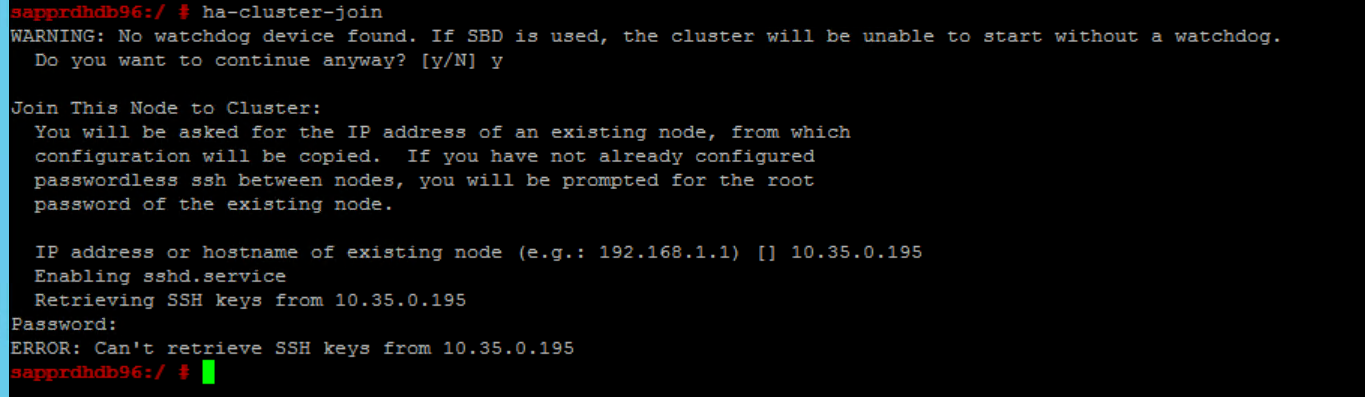
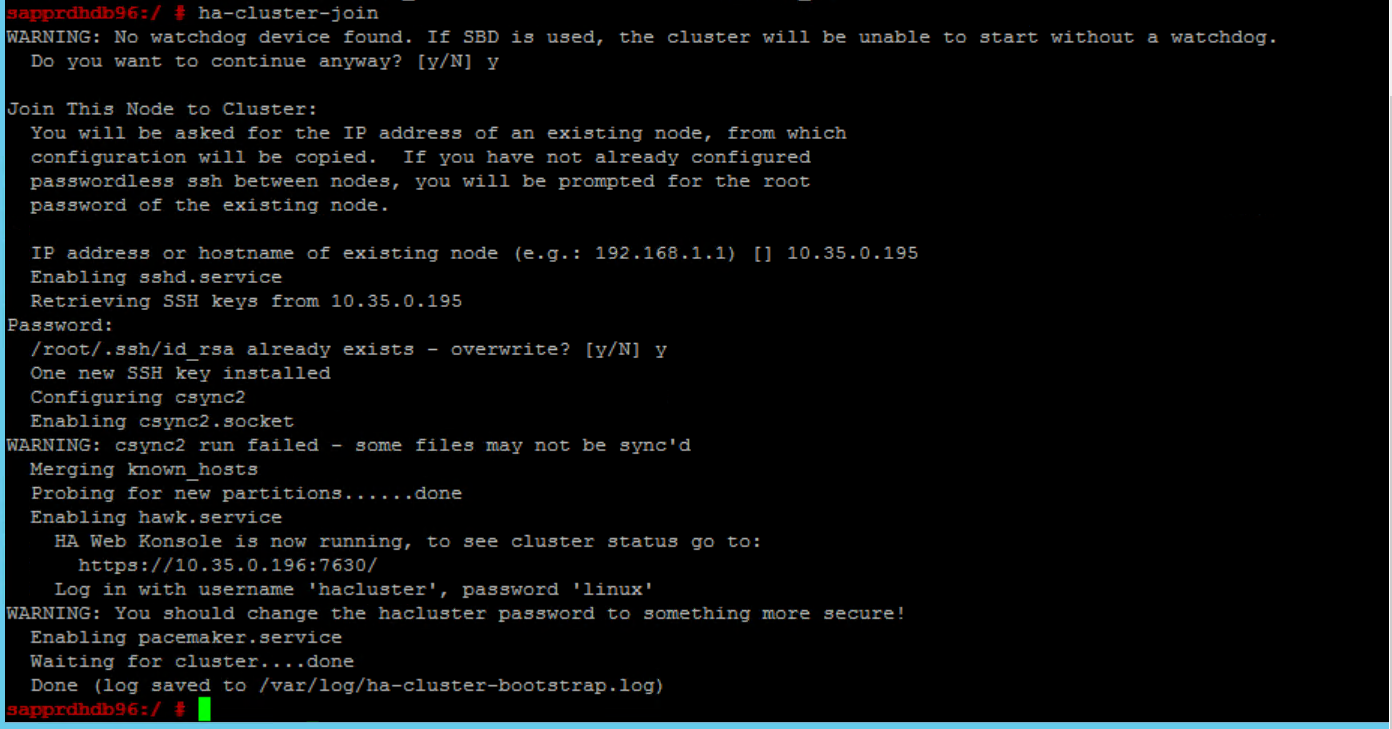
U kunt dit als volgt oplossen:
Voer de volgende opdrachten uit op beide knooppunten.
ssh-keygen -q -f /root/.ssh/id_rsa -C 'Cluster Internal' -N '' cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys

Controleer of node2 is toegevoegd aan het cluster.
Volgende stappen
Meer informatie over het instellen van hoge beschikbaarheid van SUSE vindt u in de volgende artikelen:
- Scenario met geoptimaliseerde prestaties van SAP HANA SR (SUSE-website)
- Schermen en schermen ( SUSE-website)
- Wees voorbereid op het gebruik van Pacemaker-cluster voor SAP HANA – Deel 1: Basisprincipes (SAP-blog)
- Wees voorbereid op het gebruik van Pacemaker-cluster voor SAP HANA – Deel 2: storing van beide knooppunten (SAP-blog)
- Back-up en herstel van het besturingssysteem