Hoge beschikbaarheid (betrouwbaarheid) in Azure Database for PostgreSQL - Flexibele server
VAN TOEPASSING OP: Azure Database for PostgreSQL - Flexibele server
Azure Database for PostgreSQL - Flexibele server
In dit artikel wordt hoge beschikbaarheid in Azure Database for PostgreSQL - Flexible Server beschreven, waaronder beschikbaarheidszones en herstel in meerdere regio's en bedrijfscontinuïteit. Zie Azure-betrouwbaarheid voor een gedetailleerder overzicht van betrouwbaarheid in Azure.
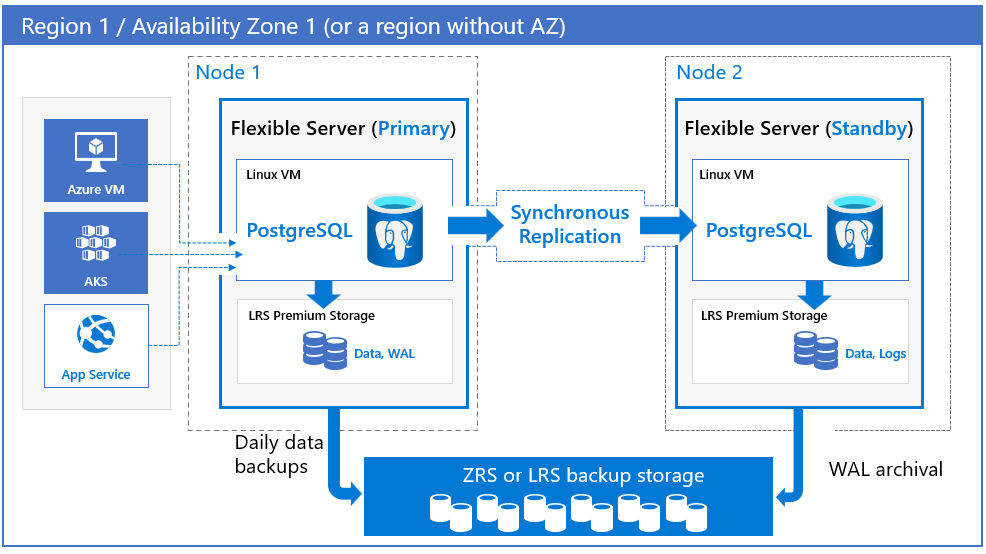
Azure Database for PostgreSQL - Flexible Server biedt ondersteuning voor hoge beschikbaarheid door fysiek gescheiden primaire en stand-byreplica's in te richten, binnen dezelfde beschikbaarheidszone (zonegebonden) of in meerdere beschikbaarheidszones (zone-redundant). Dit model voor hoge beschikbaarheid is ontworpen om ervoor te zorgen dat vastgelegde gegevens nooit verloren gaan in het geval van storingen. Bij het instellen van hoge beschikbaarheid (HA) worden gegevens synchroon doorgevoerd op zowel de primaire als stand-byservers. Het model is zo ontworpen dat de database geen single point of failure wordt in uw softwarearchitectuur. Zie Ondersteuning voor beschikbaarheidszones voor meer informatie over ondersteuning voor hoge beschikbaarheid en beschikbaarheidszone.
Ondersteuning voor beschikbaarheidszone
Beschikbaarheidszones zijn fysiek afzonderlijke groepen datacenters binnen elke Azure-regio. Wanneer één zone uitvalt, kunnen services een failover uitvoeren naar een van de resterende zones.
Zie Wat zijn beschikbaarheidszones in Azure voor meer informatie over beschikbaarheidszones?
Azure Database for PostgreSQL - Flexible Server ondersteunt zone-redundante en zonegebonden modellen voor configuraties met hoge beschikbaarheid. Beide configuraties met hoge beschikbaarheid maken automatische failover mogelijk met geen gegevensverlies tijdens geplande en ongeplande gebeurtenissen.
Zone-redundant. Zoneredundante hoge beschikbaarheid implementeert een stand-byreplica in een andere zone met automatische failovermogelijkheden. Zoneredundantie biedt het hoogste beschikbaarheidsniveau, maar vereist dat u toepassingsredundantie tussen zones configureert. Kies daarom zoneredundantie wanneer u bescherming wilt tegen storingen op beschikbaarheidszoneniveau en wanneer latentie in de beschikbaarheidszones acceptabel is. Hoewel er enige latentie van invloed kan zijn op schrijf- en doorvoerbewerkingen vanwege synchrone replicatie, heeft dit geen invloed op leesquery's. Deze impact is erg specifiek voor uw workloads, het SKU-type dat u selecteert en de regio.
U kunt de regio en de beschikbaarheidszones kiezen voor zowel primaire als stand-byservers. De stand-byreplicaserver wordt ingericht in de gekozen beschikbaarheidszone in dezelfde regio met een vergelijkbare reken-, opslag- en netwerkconfiguratie als de primaire server. Gegevensbestanden en transactielogboekbestanden (write-ahead-logboeken, a.k.a WAL) worden opgeslagen in lokaal redundante opslag (LRS) binnen elke beschikbaarheidszone, en slaan automatisch drie gegevenskopieën op. Een zone-redundante configuratie biedt fysieke isolatie van de hele stack tussen primaire en stand-byservers.

Zonegebonden. Kies een zonegebonden implementatie wanneer u het hoogste beschikbaarheidsniveau binnen één beschikbaarheidszone wilt bereiken, maar met de laagste netwerklatentie. U kunt de regio en de beschikbaarheidszone kiezen om zowel uw primaire databaseserver te implementeren. Een stand-byreplicaserver wordt automatisch ingericht en beheerd in dezelfde beschikbaarheidszone, met vergelijkbare reken-, opslag- en netwerkconfiguratie, als de primaire server. Een zonegebonden configuratie beschermt uw databases tegen storingen op knooppuntniveau en helpt ook bij het verminderen van de downtime van toepassingen tijdens geplande en ongeplande downtimegebeurtenissen. Gegevens van de primaire server worden gerepliceerd naar de stand-byreplica in de synchrone modus. In het geval van onderbreking van de primaire server wordt de server automatisch een failover uitgevoerd naar de stand-byreplica.


Notitie
Zowel zone-redundante als zone-redundante implementatiemodellen gedragen zich hetzelfde. Verschillende discussies in de volgende secties zijn van toepassing op beide, tenzij anders wordt beschreven.
Vereisten
Zoneredundantie:
De optie zoneredundantie is alleen beschikbaar in regio's die beschikbaarheidszones ondersteunen.
Zoneredundantie wordt niet ondersteund voor:
- Azure Database for PostgreSQL - SKU met één server.
- Burstable compute-laag.
- Regio's met beschikbaarheid in één zone.
Zonaal:
- De zonegebonden implementatieoptie is beschikbaar in alle Azure-regio's waar u Flexibele server kunt implementeren.
Functies voor hoge beschikbaarheid
Een stand-byreplica wordt geïmplementeerd in dezelfde VM-configuratie, waaronder vCores, opslag, netwerkinstellingen, als de primaire server.
U kunt ondersteuning voor beschikbaarheidszones toevoegen voor een bestaande databaseserver.
U kunt de stand-byreplica verwijderen door hoge beschikbaarheid uit te schakelen.
U kunt beschikbaarheidszones kiezen voor uw primaire en stand-bydatabaseservers voor zone-redundante beschikbaarheid.
Bewerkingen zoals stoppen, starten en opnieuw opstarten worden tegelijkertijd uitgevoerd op zowel de primaire server als stand-bydatabaseservers.
In zoneredundante en zonegebonden modellen worden automatische back-ups periodiek uitgevoerd vanaf de primaire databaseserver. Tegelijkertijd worden de transactielogboeken continu gearchiveerd in de back-upopslag vanuit de stand-byreplica. Als de regio beschikbaarheidszones ondersteunt, worden back-upgegevens opgeslagen in zone-redundante opslag (ZRS). In regio's die geen ondersteuning bieden voor beschikbaarheidszones, worden back-upgegevens opgeslagen op lokale redundante opslag (LRS).
Clients maken altijd verbinding met de hostnaam van de primaire databaseserver.
Wijzigingen in de serverparameters worden ook toegepast op de stand-byreplica.
Mogelijkheid om de server opnieuw op te starten om eventuele wijzigingen in statische serverparameters te detecteren.
Periodieke onderhoudsactiviteiten zoals secundaire versie-upgrades worden eerst uitgevoerd op de stand-by en, om downtime te verminderen, wordt de stand-by gepromoveerd tot primair, zodat workloads kunnen blijven ingeschakeld, terwijl de onderhoudstaken op het resterende knooppunt worden toegepast.
Status van hoge beschikbaarheid bewaken
Statuscontrole met hoge beschikbaarheid (HA) in Azure Database for PostgreSQL - Flexible Server biedt een doorlopend overzicht van de status en gereedheid van instanties met hoge beschikbaarheid. Deze bewakingsfunctie maakt gebruik van het RHC-framework (Resource Health Check) van Azure om problemen te detecteren en te waarschuwen die van invloed kunnen zijn op de failovergereedheid of algemene beschikbaarheid van uw database. Door belangrijke metrische gegevens te beoordelen, zoals verbindingsstatus, failoverstatus en status van gegevensreplicatie, kunt u proactief problemen oplossen en kunt u de uptime en prestaties van uw database behouden.
Klanten kunnen statuscontrole met hoge beschikbaarheid gebruiken om:
- Krijg realtime inzicht in de status van zowel primaire als stand-byreplica's, met statusindicatoren die potentiële problemen blootleggen, zoals verminderde prestaties of netwerkblokkering.
- Configureer waarschuwingen voor tijdige meldingen over eventuele wijzigingen in de hoge beschikbaarheidsstatus, zodat er onmiddellijk actie wordt ondernomen om potentiële onderbrekingen aan te pakken.
- Optimaliseer de failovergereedheid door problemen te identificeren en op te lossen voordat ze van invloed zijn op databasebewerkingen.
Voor een gedetailleerde handleiding over het configureren en interpreteren van statusstatussen voor hoge beschikbaarheid raadpleegt u het hoofdartikel over de statusbewaking van hoge beschikbaarheid (HA) voor Azure Database for PostgreSQL - Flexible Server.
Beperkingen voor hoge beschikbaarheid
Vanwege synchrone replicatie naar de stand-byserver, met name met een zone-redundante configuratie, kunnen toepassingen een verhoogde schrijf- en doorvoerlatentie ervaren.
Stand-byreplica kan niet worden gebruikt voor leesquery's.
Afhankelijk van de workload en activiteit op de primaire server kan het failoverproces langer duren dan 120 seconden vanwege het herstel dat is betrokken bij de stand-byreplica voordat het kan worden gepromoveerd.
De stand-byserver herstelt doorgaans WAL-bestanden op 40 MB/s. Voor grotere SKU's kan dit tarief oplopen tot maximaal 200 MB/s. Als uw werkbelasting deze limiet overschrijdt, kunt u langere tijd tegenkomen om het herstel te voltooien tijdens de failover of nadat u een nieuwe stand-by hebt gemaakt.
Als u de primaire databaseserver opnieuw opstart, wordt ook de stand-byreplica opnieuw opgestart.
Het configureren van een extra stand-by wordt niet ondersteund.
Het configureren van door de klant geïnitieerde beheertaken kan niet worden gepland tijdens het beheerde onderhoudsvenster.
Geplande gebeurtenissen zoals schaalcomputing en schaalopslag vindt eerst plaats op de stand-by en vervolgens op de primaire server. De server voert momenteel geen failover uit voor deze geplande bewerkingen.
Als logische decodering of logische replicatie is geconfigureerd met een flexibele server die is geconfigureerd voor beschikbaarheid, worden in het geval van een failover naar de stand-byserver de logische replicatiesites niet gekopieerd naar de stand-byserver. Als u logische replicatiesites wilt onderhouden en ervoor wilt zorgen dat gegevensconsistentie na een failover wordt uitgevoerd, wordt u aangeraden de extensie PG-failoversites te gebruiken. Raadpleeg de documentatie voor meer informatie over het inschakelen van deze extensie.
Het configureren van beschikbaarheidszones tussen privé (VNET) en openbare toegang met privé-eindpunten wordt niet ondersteund. U moet beschikbaarheidszones configureren binnen een VNET (verspreid over beschikbaarheidszones binnen een regio) of openbare toegang met privé-eindpunten.
Beschikbaarheidszones worden slechts binnen één regio geconfigureerd. Beschikbaarheidszones kunnen niet worden geconfigureerd in verschillende regio's.
SLA
Zonegebonden model biedt een SLA voor uptime van 99,95%.
Zoneredundantiemodel biedt een SLA voor uptime van 99,99%.
Een Azure Database for PostgreSQL - Flexibele server maken waarvoor beschikbaarheidszone is ingeschakeld
Voor meer informatie over het maken van een Azure Database for PostgreSQL - Flexible Server voor hoge beschikbaarheid met beschikbaarheidszones raadpleegt u quickstart: Een Azure Database for PostgreSQL - Flexible Server maken in Azure Portal.
Opnieuw implementeren en migreren van beschikbaarheidszone
Zie Hoge beschikbaarheid beheren in Flexibele server voor meer informatie over het in- of uitschakelen van configuratie met hoge beschikbaarheid op uw flexibele server in zowel zone-redundante als zone-redundante implementatiemodellen.
Onderdelen en werkstroom voor hoge beschikbaarheid
Transactievoltooiing
Schrijf- en doorvoerbewerkingen die door transacties worden geactiveerd, worden eerst geregistreerd bij de WAL op de primaire server. Deze worden vervolgens gestreamd naar de stand-byserver met behulp van het Postgres-streamingprotocol. Zodra de logboeken zijn opgeslagen op de opslag van de stand-byserver, wordt de primaire server bevestigd voor schrijfvoltooiing. Alleen dan wordt de toepassing bevestigd dat de transactie is doorgevoerd. Met deze extra retour wordt meer latentie toegevoegd aan uw toepassing. Het effectpercentage is afhankelijk van de toepassing. Dit bevestigingsproces wacht niet totdat de logboeken zijn toegepast op de stand-byserver. De stand-byserver bevindt zich permanent in de herstelmodus totdat deze wordt gepromoveerd.
Statuscontrole
Flexibele serverstatuscontrole controleert periodiek op zowel de primaire als de stand-bystatus. Als na meerdere pings wordt gedetecteerd dat een primaire server niet bereikbaar is, start de service vervolgens een automatische failover naar de stand-byserver. Het algoritme voor statuscontrole is gebaseerd op meerdere gegevenspunten om fout-positieve situaties te voorkomen.
Failovermodi
Flexibele server ondersteunt twee failovermodi, geplande failover en niet-geplande failover. Wanneer de replicatie in beide modi is verbroken, voert de stand-byserver het herstel uit voordat deze als primaire server wordt gepromoveerd en wordt geopend voor lezen/schrijven. Wanneer automatische DNS-vermeldingen zijn bijgewerkt met het nieuwe eindpunt van de primaire server, kunnen toepassingen verbinding maken met de server met hetzelfde eindpunt. Er wordt een nieuwe stand-byserver op de achtergrond tot stand gebracht, zodat uw toepassing verbinding kan onderhouden.
Status van hoge beschikbaarheid
De status van primaire en stand-byservers wordt continu bewaakt en er worden passende acties ondernomen om problemen op te lossen, waaronder het activeren van een failover naar de stand-byserver. De onderstaande tabel bevat de mogelijke statussen voor hoge beschikbaarheid:
| -Status | Beschrijving |
|---|---|
| Initialiseren | Tijdens het maken van een nieuwe stand-byserver. |
| Gegevens repliceren | Nadat de stand-by is gemaakt, wordt de primaire machine onder de aandacht gebracht. |
| Gezond | Replicatie heeft een stabiele status en is in orde. |
| Failover | De databaseserver is bezig met het uitvoeren van een failover naar de stand-by. |
| Stand-by verwijderen | Tijdens het verwijderen van de stand-byserver. |
| Niet ingeschakeld | Hoge beschikbaarheid is niet ingeschakeld. |
Notitie
U kunt hoge beschikbaarheid inschakelen tijdens het maken van de server of op een later tijdstip. Als u hoge beschikbaarheid inschakelt of uitschakelt tijdens de fase na het maken, wordt aanbevolen om te werken wanneer de primaire serveractiviteit laag is.
Onverander gebleven bewerkingen
PostgreSQL-clienttoepassingen zijn verbonden met de primaire server met behulp van de databaseservernaam. Leesbewerkingen van toepassingen worden rechtstreeks vanaf de primaire server geleverd. Tegelijkertijd worden doorvoeringen en schrijfbewerkingen alleen aan de toepassing bevestigd nadat de logboekgegevens zijn opgeslagen op zowel de primaire server als de stand-byreplica. Vanwege deze extra retour kunnen toepassingen verhoogde latentie verwachten voor schrijf- en doorvoerbewerkingen. U kunt de status van de hoge beschikbaarheid in de portal bewaken.
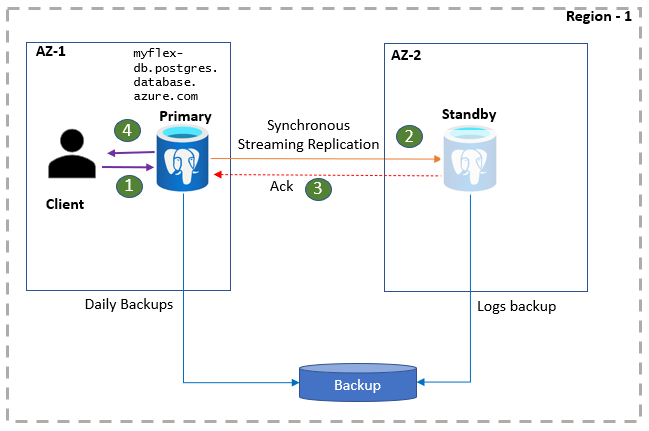
- Clients maken verbinding met de flexibele server en voeren schrijfbewerkingen uit.
- Wijzigingen worden gerepliceerd naar de stand-bysite.
- Primair ontvangt een bevestiging.
- Schrijfbewerkingen/doorvoeringen worden bevestigd.
Herstel naar een bepaald tijdstip van servers met hoge beschikbaarheid
Voor flexibele servers die zijn geconfigureerd met hoge beschikbaarheid, worden logboekgegevens in realtime gerepliceerd naar de stand-byserver. Gebruikersfouten op de primaire server, zoals een onbedoelde daling van een tabel of onjuiste gegevensupdates, worden gerepliceerd naar de stand-byreplica. U kunt dus geen stand-by gebruiken om dergelijke logische fouten te herstellen. Als u dergelijke fouten wilt herstellen, moet u een herstel naar een bepaald tijdstip uitvoeren vanuit de back-up. Met de functie voor herstel naar een bepaald tijdstip van een flexibele server kunt u herstellen naar de tijd voordat de fout is opgetreden. Een nieuwe databaseserver wordt hersteld als een flexibele server met één zone met een nieuwe door de gebruiker verstrekte servernaam voor databases die zijn geconfigureerd met hoge beschikbaarheid. U kunt de herstelde server gebruiken voor enkele gebruiksvoorbeelden:
U kunt de herstelde server gebruiken voor productie en eventueel hoge beschikbaarheid met stand-byreplica inschakelen op dezelfde zone of een andere zone in dezelfde regio.
Als u een object wilt herstellen, exporteert u het van de herstelde databaseserver en importeert u het naar de productiedatabaseserver.
Als u uw databaseserver wilt klonen voor test- en ontwikkelingsdoeleinden of voor andere doeleinden wilt herstellen, kunt u het herstel naar een bepaald tijdstip uitvoeren.
Als u wilt weten hoe u een herstel naar een bepaald tijdstip van een flexibele server uitvoert, raadpleegt u Herstel naar een bepaald tijdstip van een flexibele server.
Ondersteuning voor failover
Geplande failover
Geplande downtime-gebeurtenissen omvatten geplande periodieke software-updates en secundaire versie-upgrades van Azure. U kunt ook een geplande failover gebruiken om de primaire server te retourneren naar een beschikbaarheidszone van voorkeur. Wanneer deze bewerkingen zijn geconfigureerd in hoge beschikbaarheid, worden deze bewerkingen eerst toegepast op de stand-byreplica terwijl de toepassingen toegang blijven krijgen tot de primaire server. Zodra de stand-byreplica is bijgewerkt, worden primaire serververbindingen verwijderd en wordt een failover geactiveerd, waardoor de stand-byreplica wordt geactiveerd als de primaire replica met dezelfde databaseservernaam. Clienttoepassingen moeten opnieuw verbinding maken met dezelfde databaseservernaam op de nieuwe primaire server en kunnen hun bewerkingen hervatten. Er wordt een nieuwe stand-byserver gemaakt in dezelfde zone als de oude primaire server.
Voor andere door de gebruiker geïnitieerde bewerkingen, zoals scale-compute of scale-storage, worden de wijzigingen eerst toegepast op de stand-by, gevolgd door de primaire bewerking. Op dit moment wordt er voor de service geen failover-overschakeling uitgevoerd naar de stand-byserver. Daarom ondervinden apps tijdens het uitvoeren van de schaalbewerking op de primaire server een korte downtime.
U kunt deze functie ook gebruiken om een failover uit te voeren naar de stand-byserver met verminderde downtime. Uw primaire database kan zich bijvoorbeeld in een andere beschikbaarheidszone bevinden dan de toepassing, na een niet-geplande failover. U wilt de primaire server terugbrengen naar de vorige zone om met uw toepassing een punt te maken.
Wanneer u deze functie uitvoert, wordt de stand-byserver eerst voorbereid om ervoor te zorgen dat deze wordt opgevangen met recente transacties, zodat de toepassing lees-/schrijfbewerkingen kan blijven uitvoeren. De stand-by wordt vervolgens gepromoveerd en de verbindingen met de primaire worden verbroken. Uw toepassing kan blijven schrijven naar de primaire server terwijl er een nieuwe stand-byserver op de achtergrond wordt gemaakt. Hier volgen de stappen voor geplande failover:
| Stap | Beschrijving | Verwachte downtime van de app? |
|---|---|---|
| 1 | Wacht totdat de stand-byserver is opgevangen met de primaire server. | Nee |
| 2 | Het interne bewakingssysteem initieert de failoverwerkstroom. | Nee |
| 3 | Schrijfbewerkingen van toepassingen worden geblokkeerd wanneer de stand-byserver zich dicht bij het primaire logboekreeksnummer (LSN) bevindt. | Ja |
| 4 | Stand-byserver wordt gepromoveerd tot een onafhankelijke server. | Ja |
| 5 | DNS-record wordt bijgewerkt met het IP-adres van de nieuwe stand-byserver. | Ja |
| 6 | Toepassing om opnieuw verbinding te maken en de lees-/schrijfbewerking te hervatten met een nieuwe primaire. | Nee |
| 7 | Er wordt een nieuwe stand-byserver in een andere zone tot stand gebracht. | Nee |
| 8 | De stand-byserver begint logboeken (van Azure Blob) te herstellen die tijdens de inrichting zijn gemist. | Nee |
| 9 | Er wordt een stabiele status tussen de primaire en de stand-byserver tot stand gebracht. | Nee |
| 10 | Het geplande failoverproces is voltooid. | Nee |
Downtime van toepassingen begint bij stap 3 en kan de bewerking na stap 5 hervatten. De rest van de stappen worden op de achtergrond uitgevoerd zonder dat dit van invloed is op schrijf- en doorvoerbewerkingen van toepassingen.
Tip
Met flexibele server kunt u optioneel door Azure geïnitieerde onderhoudsactiviteiten plannen door een venster van 60 minuten te kiezen op een dag van uw voorkeur waarin de activiteiten op de databases naar verwachting laag zijn. Azure-onderhoudstaken, zoals patchen of upgrades van secundaire versies, vinden plaats in dat venster. Als u geen aangepast venster kiest, wordt een door het systeem toegewezen venster van 1 uur tussen 11:00 - 7:00 uur lokale tijd geselecteerd voor uw server. Deze door Azure geïnitieerde onderhoudsactiviteiten worden ook uitgevoerd op de stand-byreplica voor flexibele servers die zijn geconfigureerd met beschikbaarheidszones.
Zie Geplande downtime-gebeurtenissen voor een lijst met mogelijke geplande downtime-gebeurtenissen.
Niet-geplande failover
Niet-geplande downtime kan optreden als gevolg van onvoorziene onderbrekingen, zoals onderliggende hardwarestoringen, netwerkproblemen en softwarefouten. Als de databaseserver die is geconfigureerd met hoge beschikbaarheid onverwacht uitvalt, wordt de stand-byreplica geactiveerd en kunnen de clients hun bewerkingen hervatten. Als deze niet is geconfigureerd met hoge beschikbaarheid (HA), wordt automatisch een nieuwe databaseserver ingericht als de poging tot opnieuw opstarten mislukt. Hoewel een niet-geplande downtime niet kan worden vermeden, helpt flexibele server de downtime te beperken door automatisch herstelbewerkingen uit te voeren zonder menselijke tussenkomst.
Zie Niet-geplande downtime voor informatie over niet-geplande failovers en downtime, inclusief mogelijke scenario's.
Failovertests (geforceerde failover)
Met een geforceerde failover kunt u een ongepland storingsscenario simuleren tijdens het uitvoeren van uw productieworkload en de downtime van uw toepassing observeren. U kunt ook een geforceerde failover gebruiken wanneer uw primaire server niet meer reageert.
Een geforceerde failover brengt de primaire server uit en initieert de failoverwerkstroom waarin de stand-by-promotiebewerking wordt uitgevoerd. Zodra de stand-by het herstelproces tot de laatste vastgelegde gegevens heeft voltooid, wordt het gepromoveerd tot de primaire server. DNS-records worden bijgewerkt en uw toepassing kan verbinding maken met de gepromoveerde primaire server. Uw toepassing kan blijven schrijven naar de primaire server terwijl er een nieuwe stand-byserver op de achtergrond wordt ingesteld, wat geen invloed heeft op de uptime.
Hier volgen de stappen tijdens geforceerde failover:
| Stap | Beschrijving | Verwachte downtime van de app? |
|---|---|---|
| 1 | De primaire server wordt kort na ontvangst van de failoveraanvraag gestopt. | Ja |
| 2 | De toepassing ondervindt downtime omdat de primaire server niet beschikbaar is. | Ja |
| 3 | Intern bewakingssysteem detecteert de fout en initieert een failover naar de stand-byserver. | Ja |
| 4 | Stand-byserver gaat in de herstelmodus voordat deze volledig wordt gepromoveerd als een onafhankelijke server. | Ja |
| 5 | Het failoverproces wacht totdat het stand-byherstel is voltooid. | Ja |
| 6 | Zodra de server is bijgewerkt, wordt de DNS-record bijgewerkt met dezelfde hostnaam, maar met behulp van het IP-adres van de stand-by. | Ja |
| 7 | De toepassing kan opnieuw verbinding maken met de nieuwe primaire server en de bewerking hervatten. | Nee |
| 8 | Er wordt een stand-byserver in de voorkeurszone tot stand gebracht. | Nee |
| 9 | De stand-byserver begint logboeken (van Azure Blob) te herstellen die tijdens de inrichting zijn gemist. | Nee |
| 10 | Er wordt een stabiele status tussen de primaire en de stand-byserver tot stand gebracht. | Nee |
| 11 | Het geforceerde failoverproces is voltooid. | Nee |
Uitvaltijd van toepassingen wordt verwacht na stap 1 en blijft behouden totdat stap 6 is voltooid. De rest van de stappen worden op de achtergrond uitgevoerd zonder dat dit van invloed is op de schrijf- en doorvoerbewerkingen van de toepassing.
Belangrijk
Het end-to-endfailoverproces omvat (a) een failover naar de stand-byserver na de primaire fout en (b) het tot stand brengen van een nieuwe stand-byserver in een stabiele status. Wanneer uw toepassing uitvaltijd in beslag neemt totdat de failover naar de stand-by is voltooid, meet u de downtime vanuit het perspectief van uw toepassing/client in plaats van het algehele end-to-end-failoverproces.
Overwegingen bij het uitvoeren van geforceerde failovers
De totale end-to-end-bewerkingstijd kan worden gezien als langer dan de werkelijke downtime die de toepassing ondervindt.
Belangrijk
Bekijk altijd de downtime vanuit het perspectief van de toepassing.
Voer geen directe back-to-back-failovers uit. Wacht ten minste 15-20 minuten tussen failovers, zodat de nieuwe stand-byserver volledig tot stand kan worden gebracht.
Het is raadzaam om een geforceerde failover uit te voeren tijdens een periode met weinig activiteit om de downtime te verminderen.
Best practices voor PostgreSQL-statistieken na een failover
Na een PostgreSQL-failover omvat het primaire mechanisme voor het onderhouden van optimale databaseprestaties inzicht in de verschillende rollen van pg_statistic en de pg_stat_* -tabellen. De pg_statistic tabel bevat optimalisatiestatistieken, die cruciaal zijn voor de queryplanner. Deze statistieken omvatten gegevensdistributies in tabellen en blijven intact na een failover, zodat de queryplanner de uitvoering van query's effectief kan blijven optimaliseren op basis van nauwkeurige, historische gegevensdistributiegegevens.
Daarentegen worden de pg_stat_* tabellen, die activiteitsstatistieken vastleggen, zoals het aantal scans, tuples lezen en updates, opnieuw ingesteld bij failover. Een voorbeeld van een dergelijke tabel is pg_stat_user_tables, waarmee activiteiten voor door de gebruiker gedefinieerde tabellen worden bijgehouden. Deze reset is ontworpen om de operationele status van de nieuwe primaire nauwkeurig weer te geven, maar betekent ook het verlies van historische activiteitsgegevens die het autovacuumproces en andere operationele efficiëntie kunnen informeren.
Gezien dit onderscheid wordt aanbevolen om een PostgreSQL-failover uit te voeren ANALYZE. Met deze actie worden de pg_stat_* tabellen bijgewerkt, zoals , met pg_stat_user_tablesnieuwe activiteitsstatistieken, waardoor het autovacuumproces wordt geholpen en ervoor zorgt dat de databaseprestaties optimaal blijven in de nieuwe rol. Deze proactieve stap overbrugt de kloof tussen het behouden van essentiële optimizer-statistieken en het vernieuwen van metrische gegevens over activiteit, zodat deze overeenkomt met de huidige status van de database.
Zone-down ervaring
Zonegebonden: Als u wilt herstellen na een fout op zoneniveau, kunt u herstel naar een bepaald tijdstip uitvoeren met behulp van de back-up. U kunt een aangepast herstelpunt kiezen met de laatste tijd om de meest recente gegevens te herstellen. Er wordt een nieuwe flexibele server geïmplementeerd in een andere niet-betrokken zone. De tijd die nodig is om te herstellen, is afhankelijk van de vorige back-up en het volume van transactielogboeken dat moet worden hersteld.
Zie Back-up en herstel in Azure Database for PostgreSQL-Flexible Server voor meer informatie over herstel naar een bepaald tijdstip.
Zone-redundant: Flexibele server wordt binnen 60-120 seconden automatisch overgeschakeld naar de stand-byserver, zonder gegevensverlies.
Configuraties zonder beschikbaarheidszones
Hoewel het niet wordt aanbevolen, kunt u uw flexibele server configureren zonder hoge beschikbaarheid ingeschakeld. Voor flexibele servers die zijn geconfigureerd zonder hoge beschikbaarheid, biedt de service lokale redundante opslag met drie kopieën van gegevens, zone-redundante back-up (in regio's waar deze wordt ondersteund) en ingebouwde servertolerantie om automatisch een vastgelopen server opnieuw op te starten en de server te verplaatsen naar een ander fysiek knooppunt. Sla voor uptime van 99,9% wordt aangeboden in deze configuratie. Tijdens geplande of niet-geplande failovergebeurtenissen, als de server uitvalt, behoudt de service de beschikbaarheid van de servers met behulp van de volgende geautomatiseerde procedure:
- Er wordt een nieuwe Linux reken-VM ingericht.
- De opslag met gegevensbestanden wordt toegewezen aan de nieuwe virtuele machine.
- PostgreSQL-database-engine wordt online gebracht op de nieuwe virtuele machine.
In de onderstaande afbeelding ziet u de overgang tussen VM en opslagfout.

Herstel na noodgevallen en bedrijfscontinuïteit tussen regio's
In het geval van een regiobrede ramp kan Azure bescherming bieden tegen regionale of grote geografische rampen met herstel na noodgevallen door gebruik te maken van een andere regio. Zie de architectuur voor herstel na noodgevallen van Azure naar Azure voor meer informatie over de architectuur voor herstel na noodgevallen van Azure.
Flexibele server biedt functies die gegevens beschermen en downtime voor uw bedrijfskritieke databases beperken tijdens geplande en ongeplande downtimegebeurtenissen. Flexibele server is gebouwd op de Azure-infrastructuur die robuuste tolerantie en beschikbaarheid biedt, biedt functies voor bedrijfscontinuïteit die foutbeveiliging bieden, de vereisten voor hersteltijd aanpakken en blootstelling aan gegevensverlies verminderen. Wanneer u uw toepassingen ontwerpt, moet u rekening houden met de downtimetolerantie ( de beoogde hersteltijd ( RTO) en blootstelling aan gegevensverlies - de beoogde herstelpunt (RPO). Uw bedrijfskritieke database vereist bijvoorbeeld strengere uptime dan een testdatabase.
Herstel na noodgevallen in geografie in meerdere regio's
Geografisch redundante back-up en herstel
Geografisch redundante back-up en herstel bieden de mogelijkheid om uw server in een andere regio te herstellen in het geval van een noodgeval. Het biedt ook ten minste 99,9999999999999999 procent (16 negens) duurzaamheid van back-upobjecten gedurende een jaar.
Geografisch redundante back-up kan alleen worden geconfigureerd op het moment dat de server wordt gemaakt. Wanneer de server is geconfigureerd met geografisch redundante back-up, worden de back-upgegevens en transactielogboeken asynchroon naar de gekoppelde regio gekopieerd via opslagreplicatie.
Zie geografisch redundante back-up en herstel voor meer informatie over geografisch redundante back-up en herstel.
Leesreplica's
Leesreplica's voor meerdere regio's kunnen worden geïmplementeerd om uw databases te beschermen tegen storingen op regioniveau. Leesreplica's worden asynchroon bijgewerkt met behulp van de fysieke replicatietechnologie van PostgreSQL en kunnen de primaire replica vertraging oplopen. Leesreplica's worden ondersteund in de rekenlagen voor algemeen gebruik en geoptimaliseerd voor geheugen.
Zie Leesreplica's voor meer informatie over leesreplicafuncties en overwegingen.
Detectie, melding en beheer van storingen
Als uw server is geconfigureerd met geografisch redundante back-up, kunt u geo-herstel uitvoeren in de gekoppelde regio. Er wordt een nieuwe server ingericht en hersteld naar de laatst beschikbare gegevens die naar deze regio zijn gekopieerd.
U kunt ook leesreplica's in meerdere regio's gebruiken. In het geval van een regiofout kunt u herstel na noodgevallen uitvoeren door uw leesreplica te promoveren tot een zelfstandige, leesbare server. RPO duurt naar verwachting maximaal 5 minuten (mogelijk gegevensverlies), behalve in het geval van ernstige regionale storingen wanneer de RPO zich op het moment van storing dicht bij de replicatievertraging kan bevinden.
Zie Niet-geplande downtime beperken en herstellen na regionale noodgeval voor meer informatie over ongeplande uitval.