Problemen met trage query's in Azure Database for PostgreSQL - Flexible Server oplossen en identificeren
VAN TOEPASSING OP:  Azure Database for PostgreSQL - Flexibele server
Azure Database for PostgreSQL - Flexibele server
In dit artikel wordt beschreven hoe u de hoofdoorzaak van trage query's kunt identificeren en diagnosticeren.
In dit artikel leert u het volgende:
- Hoe u trage query's kunt identificeren.
- Hoe u een trage procedure kunt identificeren, samen met deze procedure. Identificeer een trage query in een lijst met query's die deel uitmaken van dezelfde traag uitgevoerde opgeslagen procedure.
Vereisten
Schakel probleemoplossingsgidsen in door de stappen te volgen die worden beschreven in handleidingen voor probleemoplossing.
Configureer de
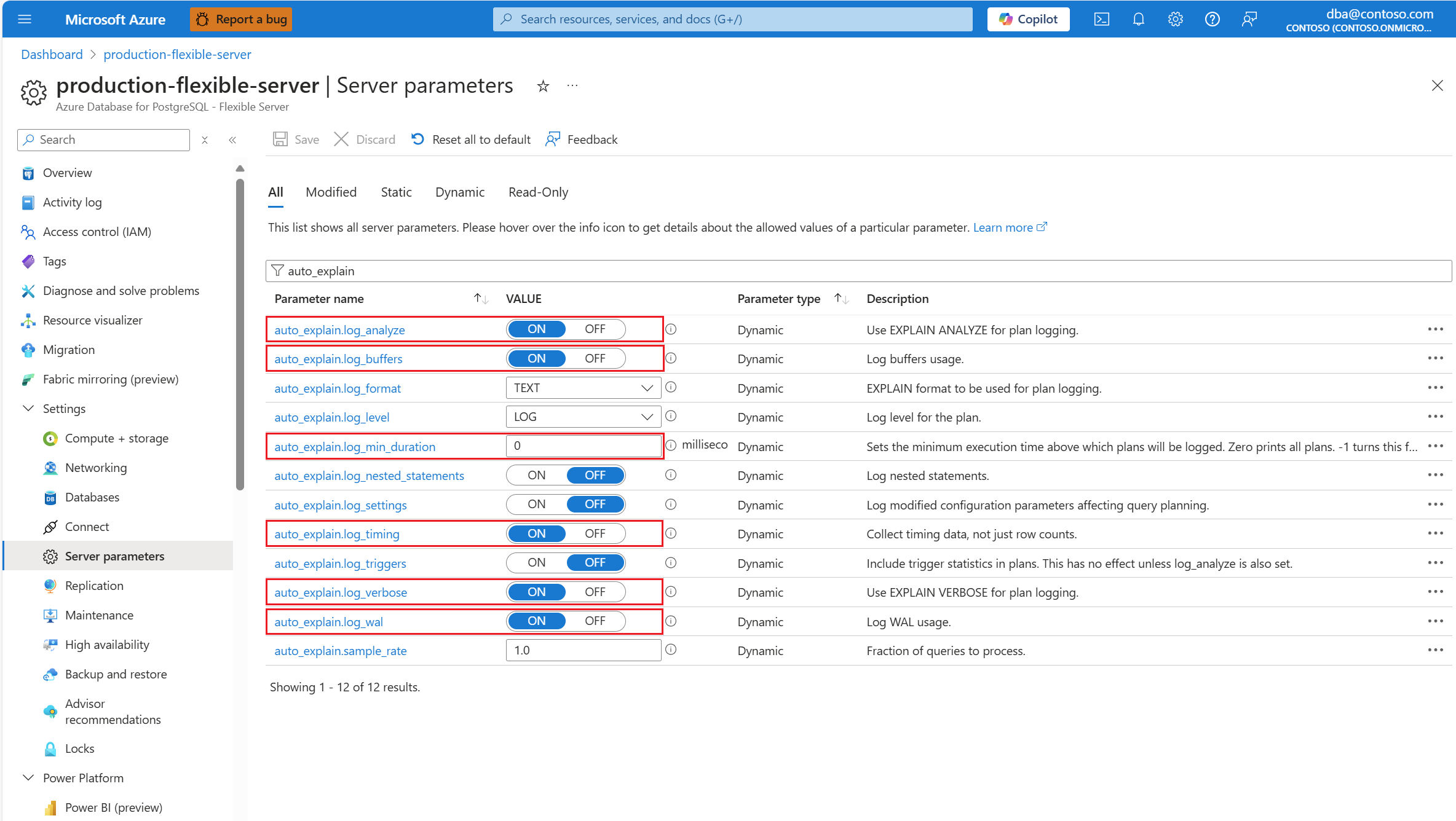
auto_explainextensie door de extensie toe te staan en te laden .Nadat de
auto_explainextensie is geconfigureerd, wijzigt u de volgende serverparameters, waarmee het gedrag van de extensie wordt bepaald:auto_explain.log_analyzeaanON.auto_explain.log_buffersaanON.auto_explain.log_min_durationvolgens wat redelijk is in uw scenario.auto_explain.log_timingaanON.auto_explain.log_verboseaanON.

Notitie
Als u instelt op auto_explain.log_min_duration 0, begint de extensie met het vastleggen van alle query's die op de server worden uitgevoerd. Dit kan van invloed zijn op de prestaties van de database. Er moet een juiste due diligence worden uitgevoerd om te komen tot een waarde die als traag op de server wordt beschouwd. Als alle query's bijvoorbeeld in minder dan 30 seconden zijn voltooid en dat acceptabel is voor uw toepassing, wordt u aangeraden de parameter bij te werken naar 30000 milliseconden. Hiermee wordt een query vastgelegd die langer dan 30 seconden duurt.
Trage query identificeren
Met probleemoplossingsgidsen en auto_explain uitbreidingen beschrijven we het scenario met behulp van een voorbeeld.
We hebben een scenario waarin pieken in het CPU-gebruik tot 90% worden uitgevoerd en de oorzaak van de piek willen bepalen. Voer de volgende stappen uit om fouten in het scenario op te sporen:
Zodra u wordt gewaarschuwd door een CPU-scenario, selecteert u in het resourcemenu van het getroffen exemplaar van Azure Database for PostgreSQL Flexible Server, onder de sectie Bewaking, probleemoplossingsgidsen.
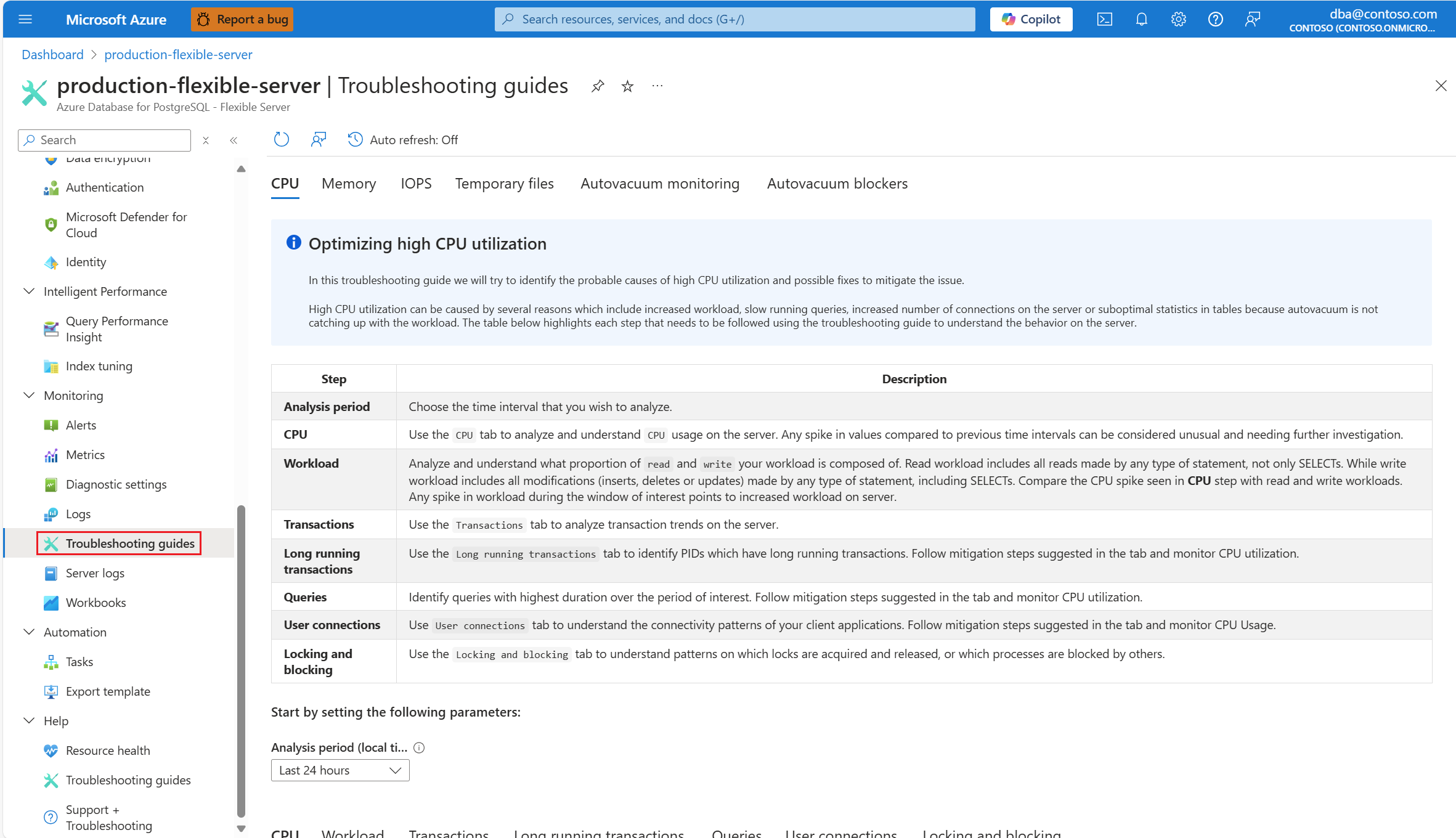
Selecteer het tabblad CPU . De probleemoplossingsgids voor het optimaliseren van hoog CPU-gebruik wordt geopend.
Selecteer in de vervolgkeuzelijst Analyseperiode (lokale tijd) het tijdsbereik waarop u de analyse wilt richten.

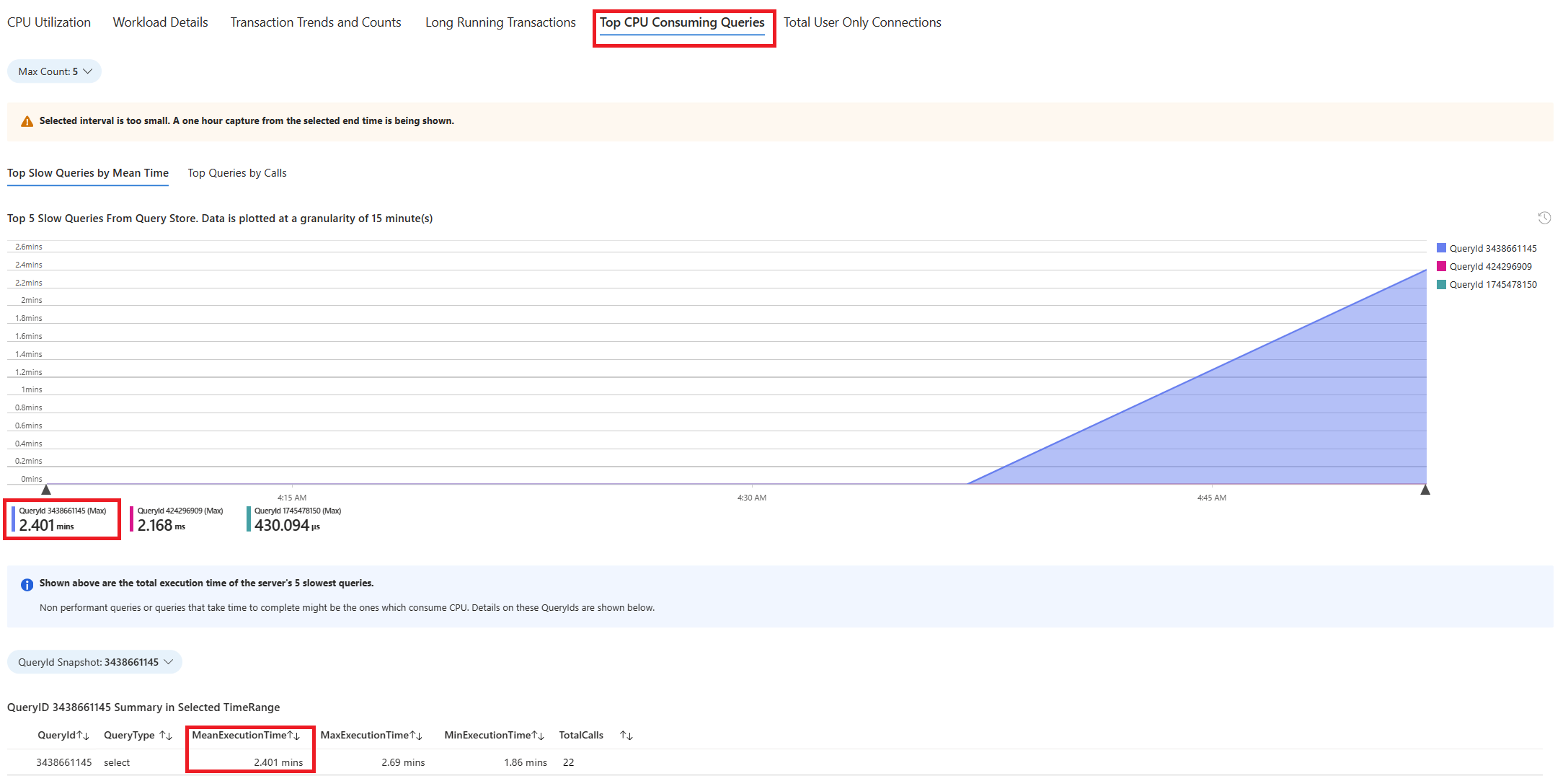
Selecteer het tabblad Query's . Hier ziet u details van alle query's die zijn uitgevoerd in het interval waarin 90% CPU-gebruik is gezien. Vanuit de momentopname lijkt het erop dat de query met de traagste gemiddelde uitvoeringstijd tijdens het tijdsinterval ongeveer 2,6 minuten was en de query 22 keer werd uitgevoerd tijdens het interval. Deze query is waarschijnlijk de oorzaak van de CPU-pieken.
Als u de werkelijke querytekst wilt ophalen, maakt u verbinding met de
azure_sysdatabase en voert u de volgende query uit.




psql -h <server>.postgres.database.azure.com -U <user> -d azure_sys
SELECT query_sql_text
FROM query_store.query_texts_view
WHERE query_text_id = <query_id>;
- In het voorbeeld dat werd overwogen, was de query die traag is gevonden:
SELECT c_id, SUM(c_balance) AS total_balance
FROM customer
GROUP BY c_w_id, c_id
ORDER BY c_w_id;
Gebruik Azure Database for PostgreSQL Flexible Server-logboeken om te begrijpen wat het exacte uitlegplan is gegenereerd. Telkens wanneer de query is uitgevoerd tijdens dat tijdvenster, moet de
auto_explainextensie een vermelding in de logboeken schrijven. Selecteer Logboeken in het resourcemenu onder de sectie Bewaking.
Selecteer het tijdsbereik waarin 90% CPU-gebruik is gevonden.
Voer de volgende query uit om de uitvoer van EXPLAIN ANALYZE op te halen voor de geïdentificeerde query.

AzureDiagnostics
| where Category contains 'PostgreSQLLogs'
| where Message contains "<snippet of SQL text identified or name of any of the tables referenced in the query>"
| project TimeGenerated, Message
In de berichtenkolom wordt het uitvoeringsplan opgeslagen, zoals wordt weergegeven in deze uitvoer:
2024-11-10 19:56:46 UTC-6525a8e7.2e3d-LOG: duration: 150692.864 ms plan:
Query Text: SELECT c_id, SUM(c_balance) AS total_balance
FROM customer
GROUP BY c_w_id,c_id
order by c_w_id;
GroupAggregate (cost=1906820.83..2131820.83 rows=10000000 width=40) (actual time=70930.833..129231.950 rows=10000000 loops=1)
Output: c_id, sum(c_balance), c_w_id
Group Key: customer.c_w_id, customer.c_id
Buffers: shared hit=44639 read=355362, temp read=77521 written=77701
-> Sort (cost=1906820.83..1931820.83 rows=10000000 width=13) (actual time=70930.821..81898.430 rows=10000000 loops=1)
Output: c_id, c_w_id, c_balance
Sort Key: customer.c_w_id, customer.c_id
Sort Method: external merge Disk: 225104kB
Buffers: shared hit=44639 read=355362, temp read=77521 written=77701
-> Seq Scan on public.customer (cost=0.00..500001.00 rows=10000000 width=13) (actual time=0.021..22997.697 rows=10000000 loops=1)
Output: c_id, c_w_id, c_balance
De query is ongeveer 2,5 minuten uitgevoerd, zoals wordt weergegeven in de gids voor probleemoplossing. De duration waarde van 150692,864 ms uit de uitvoer van het uitvoeringsplan dat is opgehaald, bevestigt dit. Gebruik de uitvoer van EXPLAIN ANALYZE om problemen verder op te lossen en de query af te stemmen.
Notitie
Waarnemer dat de query 22 keer tijdens het interval is uitgevoerd en dat de weergegeven logboeken een van deze vermeldingen bevatten die tijdens het interval zijn vastgelegd.
Trage query in een opgeslagen procedure identificeren
Met handleidingen voor probleemoplossing en auto_explain-extensie leggen we het scenario uit met behulp van een voorbeeld.
We hebben een scenario waarin pieken in het CPU-gebruik tot 90% worden uitgevoerd en de oorzaak van de piek willen bepalen. Voer de volgende stappen uit om fouten in het scenario op te sporen:
Zodra u wordt gewaarschuwd door een CPU-scenario, selecteert u in het resourcemenu van het getroffen exemplaar van Azure Database for PostgreSQL Flexible Server, onder de sectie Bewaking, probleemoplossingsgidsen.
Selecteer het tabblad CPU . De probleemoplossingsgids voor het optimaliseren van hoog CPU-gebruik wordt geopend.
Selecteer in de vervolgkeuzelijst Analyseperiode (lokale tijd) het tijdsbereik waarop u de analyse wilt richten.
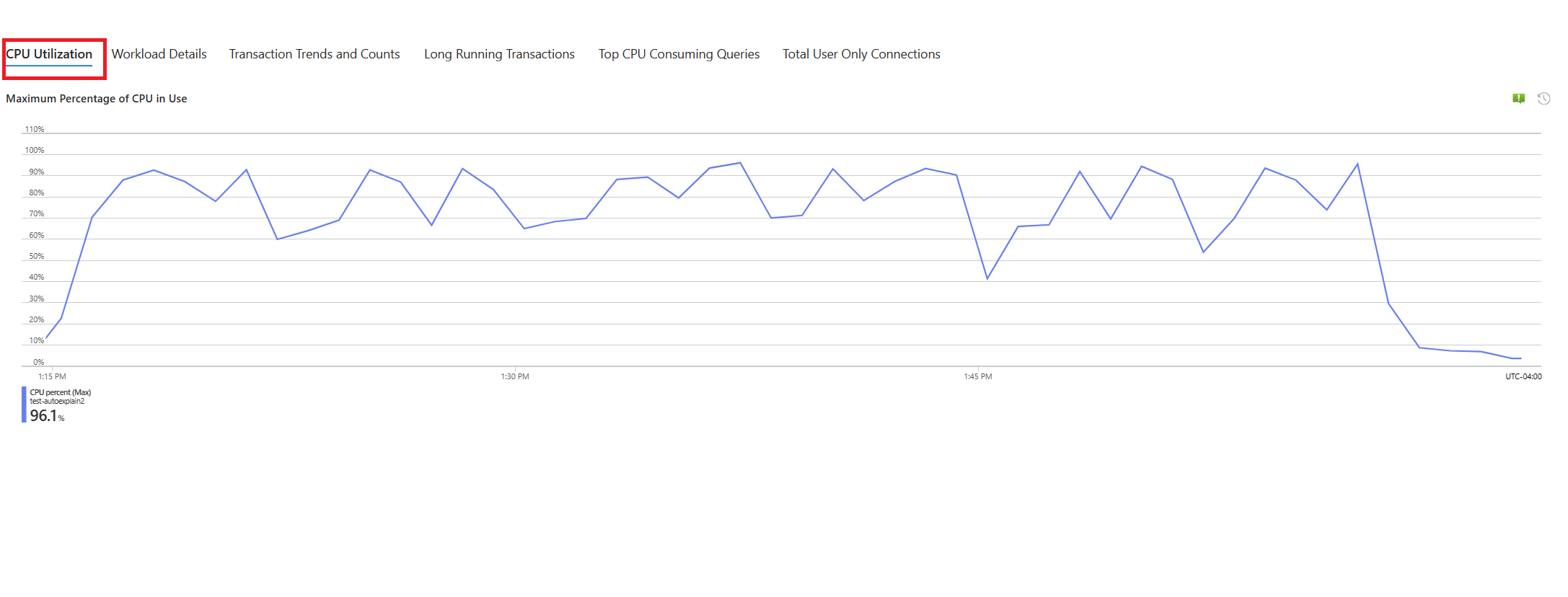
Selecteer het tabblad Query's . Hier ziet u details van alle query's die zijn uitgevoerd in het interval waarin 90% CPU-gebruik is gezien. Vanuit de momentopname lijkt het erop dat de query met de traagste gemiddelde uitvoeringstijd tijdens het tijdsinterval ongeveer 2,6 minuten was en de query 22 keer werd uitgevoerd tijdens het interval. Deze query is waarschijnlijk de oorzaak van de CPU-pieken.
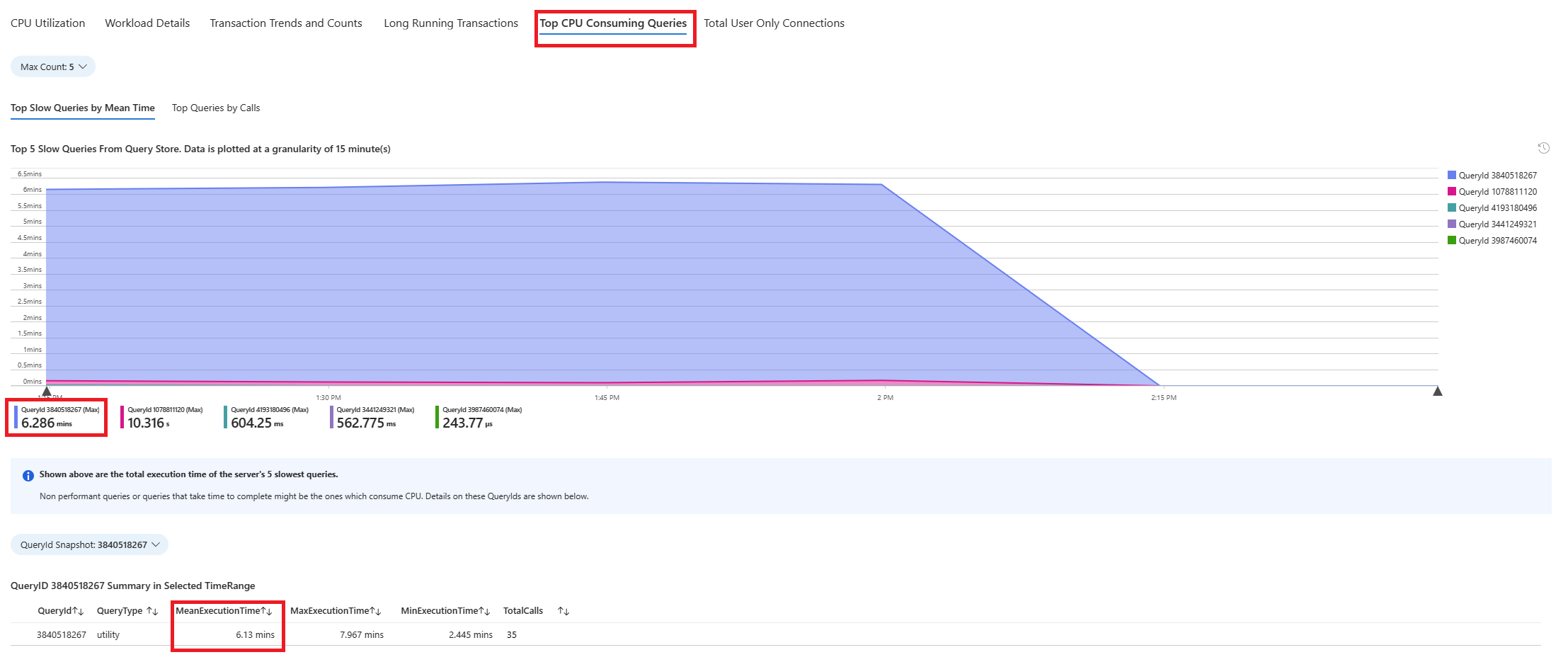
Maak verbinding met azure_sys database en voer de query uit om de werkelijke querytekst op te halen met behulp van het onderstaande script.


psql -h <server>.postgres.database.azure.com -U <user> -d azure_sys
SELECT query_sql_text
FROM query_store.query_texts_view
WHERE query_text_id = <query_id>;
- In het voorbeeld dat werd overwogen, was de gevonden query traag een opgeslagen procedure:
call autoexplain_test ();
- Gebruik Azure Database for PostgreSQL Flexible Server-logboeken om te begrijpen wat het exacte uitlegplan is gegenereerd. Telkens wanneer de query is uitgevoerd tijdens dat tijdvenster, moet de
auto_explainextensie een vermelding in de logboeken schrijven. Selecteer Logboeken in het resourcemenu onder de sectie Bewaking. Selecteer vervolgens in Tijdsbereik het tijdvenster waarin u de analyse wilt richten.

- Voer de volgende query uit om de analyse-uitvoer van de geïdentificeerde query op te halen.
AzureDiagnostics
| where Category contains 'PostgreSQLLogs'
| where Message contains "<snippet of SQL text identified or name of any of the tables referenced in the query>"
| project TimeGenerated, Message
De procedure heeft meerdere query's, die hieronder zijn gemarkeerd. De uitleg over het analyseren van de uitvoer van elke query die in de opgeslagen procedure wordt gebruikt, wordt aangemeld om verder te analyseren en problemen op te lossen. De uitvoeringstijd van de vastgelegde query's kan worden gebruikt om de traagste query's te identificeren die deel uitmaken van de opgeslagen procedure.
2024-11-10 17:52:45 UTC-6526d7f0.7f67-LOG: duration: 38459.176 ms plan:
Query Text: insert into customer_balance SELECT c_id, SUM(c_balance) AS total_balance FROM customer GROUP BY c_w_id,c_id order by c_w_id
Insert on public.customer_balance (cost=1906820.83..2231820.83 rows=0 width=0) (actual time=38459.173..38459.174 rows=0 loops=1)Buffers: shared hit=10108203 read=454055 dirtied=54058, temp read=77521 written=77701 WAL: records=10000000 fpi=1 bytes=640002197
-> Subquery Scan on "*SELECT*" (cost=1906820.83..2231820.83 rows=10000000 width=36) (actual time=20415.738..29514.742 rows=10000000 loops=1)
Output: "*SELECT*".c_id, "*SELECT*".total_balance Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> GroupAggregate (cost=1906820.83..2131820.83 rows=10000000 width=40) (actual time=20415.737..28574.266 rows=10000000 loops=1)
Output: customer.c_id, sum(customer.c_balance), customer.c_w_id Group Key: customer.c_w_id, customer.c_id Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> Sort (cost=1906820.83..1931820.83 rows=10000000 width=13) (actual time=20415.723..22023.515 rows=10000000 loops=1)
Output: customer.c_id, customer.c_w_id, customer.c_balance Sort Key: customer.c_w_id, customer.c_id Sort Method: external merge Disk: 225104kB Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> Seq Scan on public.customer (cost=0.00..500001.00 rows=10000000 width=13) (actual time=0.310..15061.471 rows=10000000 loops=1) Output: customer.c_id, customer.c_w_id, customer.c_balance Buffers: shared hit=1 read=400000
2024-11-10 17:52:07 UTC-6526d7f0.7f67-LOG: duration: 61939.529 ms plan:
Query Text: delete from customer_balance
Delete on public.customer_balance (cost=0.00..799173.51 rows=0 width=0) (actual time=61939.525..61939.526 rows=0 loops=1) Buffers: shared hit=50027707 read=620942 dirtied=295462 written=71785 WAL: records=50026565 fpi=34 bytes=2711252160
-> Seq Scan on public.customer_balance (cost=0.00..799173.51 rows=15052451 width=6) (actual time=3185.519..35234.061 rows=50000000 loops=1)
Output: ctid Buffers: shared hit=27707 read=620942 dirtied=26565 written=71785 WAL: records=26565 fpi=34 bytes=11252160
2024-11-10 17:51:05 UTC-6526d7f0.7f67-LOG: duration: 10387.322 ms plan:
Query Text: select max(c_id) from customer
Finalize Aggregate (cost=180185.84..180185.85 rows=1 width=4) (actual time=10387.220..10387.319 rows=1 loops=1) Output: max(c_id) Buffers: shared hit=37148 read=1204 written=69
-> Gather (cost=180185.63..180185.84 rows=2 width=4) (actual time=10387.214..10387.314 rows=1 loops=1)
Output: (PARTIAL max(c_id)) Workers Planned: 2 Workers Launched: 0 Buffers: shared hit=37148 read=1204 written=69
-> Partial Aggregate (cost=179185.63..179185.64 rows=1 width=4) (actual time=10387.012..10387.013 rows=1 loops=1) Output: PARTIAL max(c_id) Buffers: shared hit=37148 read=1204 written=69
-> Parallel Index Only Scan using customer_i1 on public.customer (cost=0.43..168768.96 rows=4166667 width=4) (actual time=0.446..7676.356 rows=10000000 loops=1)
Output: c_w_id, c_d_id, c_id Heap Fetches: 24 Buffers: shared hit=37148 read=1204 written=69
Notitie
Voor demonstratiedoeleinden worden slechts enkele query's weergegeven die in de procedure worden gebruikt door EXPLAIN ANALYZE. Het idee is dat u UITLEG ANALYSEREN-uitvoer van alle query's uit de logboeken kunt verzamelen en de traagste query's kunt identificeren en proberen deze af te stemmen.
Gerelateerde inhoud
- Problemen met een hoog CPU-gebruik in Azure Database for PostgreSQL - Flexibele server oplossen.
- Problemen met hoog IOPS-gebruik in Azure Database for PostgreSQL - Flexible Server oplossen.
- Problemen met hoog geheugengebruik in Azure Database for PostgreSQL - Flexible Server oplossen.
- Serverparameters in Azure Database for PostgreSQL - Flexible Server.
- Automatisch afstemmen in Azure Database for PostgreSQL - Flexible Server.