Zelfstudie 1: Een functieset ontwikkelen en registreren bij het beheerde functiearchief
Deze reeks zelfstudies laat zien hoe functies naadloos alle fasen van de levenscyclus van machine learning integreren: prototypen, training en operationalisatie.
U kunt het beheerde functiearchief van Azure Machine Learning gebruiken om functies te detecteren, te maken en operationeel te maken. De levenscyclus van machine learning omvat een prototypefase, waar u experimenteer met verschillende functies. Het omvat ook een operationalisatiefase, waarbij modellen worden geïmplementeerd en deductiestappen functiegegevens opzoeken. Functies fungeren als het bindweefsel in de machine learning-levenscyclus. Voor meer informatie over basisconcepten voor het beheerde functiearchief gaat u naar het archief met beheerde functies? en begrijpt u entiteiten op het hoogste niveau in resources voor het beheerde functiearchief.
In deze zelfstudie wordt beschreven hoe u een specificatie van een functieset maakt met aangepaste transformaties. Vervolgens wordt die functieset gebruikt om trainingsgegevens te genereren, materialisatie in te schakelen en een backfill uit te voeren. Materialisatie berekent de functiewaarden voor een functievenster en slaat deze waarden vervolgens op in een materialisatiearchief. Alle functiequery's kunnen deze waarden vervolgens gebruiken uit het materialisatiearchief.
Zonder materialisatie past een functiesetquery de transformaties onmiddellijk toe op de bron om de functies te berekenen voordat de waarden worden geretourneerd. Dit proces werkt goed voor de prototypefase. Voor trainings- en deductiebewerkingen in een productieomgeving raden we u echter aan de functies te materialiseren voor een grotere betrouwbaarheid en beschikbaarheid.
Deze zelfstudie is het eerste deel van de reeks zelfstudies voor het beheerde functiearchief. Hier leert u het volgende:
- Maak een nieuwe, minimale resource voor het functiearchief.
- Een functieset ontwikkelen en lokaal testen met functietransformatiemogelijkheden.
- Registreer een entiteit in het functiearchief bij het functiearchief.
- Registreer de functieset die u hebt ontwikkeld met de functieopslag.
- Genereer een dataframe voor een voorbeeldtraining met behulp van de functies die u hebt gemaakt.
- Schakel offline materialisatie in op de functiesets en vul de functiegegevens opnieuw in.
Deze reeks zelfstudies heeft twee sporen:
- De SDK-trace maakt alleen gebruik van Python SDK's. Kies dit spoor voor pure, op Python gebaseerde ontwikkeling en implementatie.
- De SDK en CLI-track maakt alleen gebruik van de Python SDK voor het ontwikkelen en testen van functiessets en maakt gebruik van de CLI voor CRUD-bewerkingen (maken, lezen, bijwerken en verwijderen). Dit spoor is handig in scenario's voor continue integratie en continue levering (CI/CD) of GitOps, waarbij CLI/YAML de voorkeur heeft.
Vereisten
Voordat u verdergaat met deze zelfstudie, moet u aan de volgende vereisten voldoen:
Een Azure Machine Learning-werkruimte. Ga naar Quickstart: Werkruimteresources maken voor meer informatie over het maken van werkruimten.
Voor uw gebruikersaccount hebt u de rol Eigenaar nodig voor de resourcegroep waarin het functiearchief wordt gemaakt.
Als u ervoor kiest om een nieuwe resourcegroep voor deze zelfstudie te gebruiken, kunt u eenvoudig alle resources verwijderen door de resourcegroep te verwijderen.
De notebookomgeving voorbereiden
In deze zelfstudie wordt een Azure Machine Learning Spark-notebook gebruikt voor ontwikkeling.
Selecteer notitieblokken in de Azure Machine Learning-studio-omgeving in het linkerdeelvenster en selecteer vervolgens het tabblad Voorbeelden.
Blader naar de map featurestore_sample (selecteer Samples>SDK v2>sdk>python>featurestore_sample) en selecteer Vervolgens Clone.
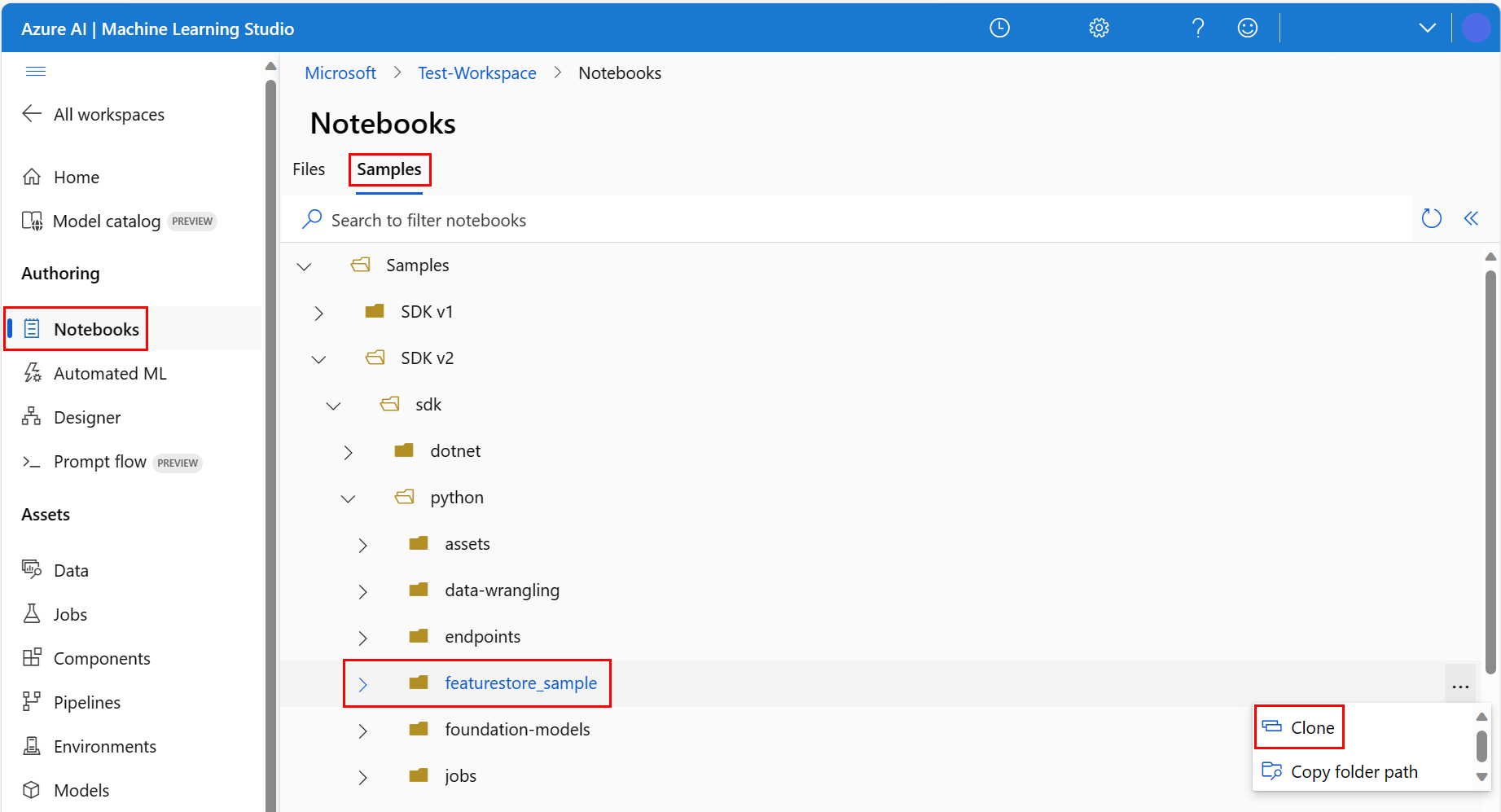
Het deelvenster Doelmap selecteren wordt geopend. Selecteer de gebruikersmap, selecteer vervolgens uw gebruikersnaam en selecteer ten slotte Klonen.
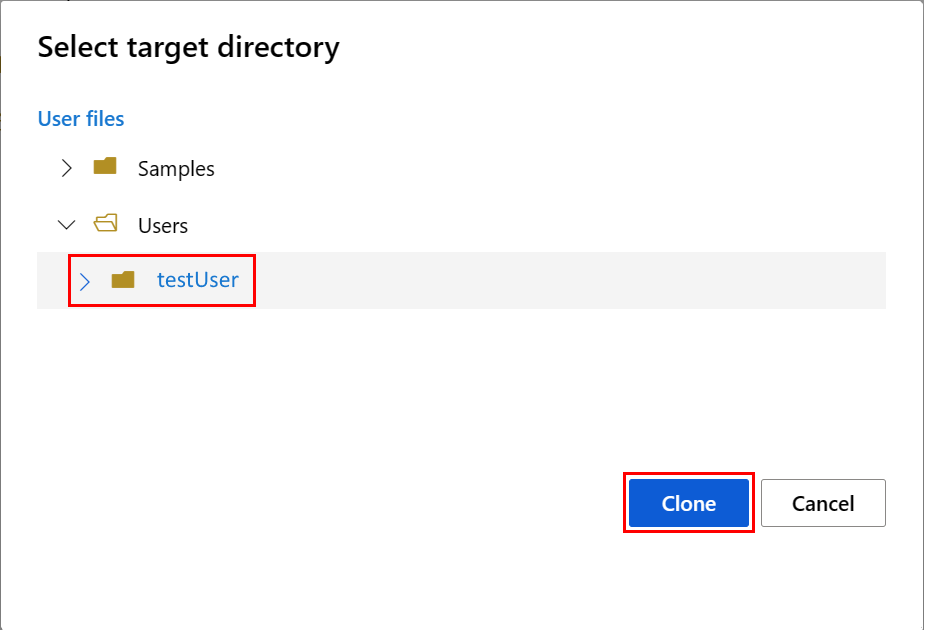
Als u de notebookomgeving wilt configureren, moet u het conda.yml-bestand uploaden:
- Selecteer Notitieblokken in het linkerdeelvenster en selecteer vervolgens het tabblad Bestanden .
- Blader naar de map env (selecteer Users>your_user_name>featurestore_sample>project>env) en selecteer vervolgens het conda.yml bestand.
- Selecteer Downloaden.
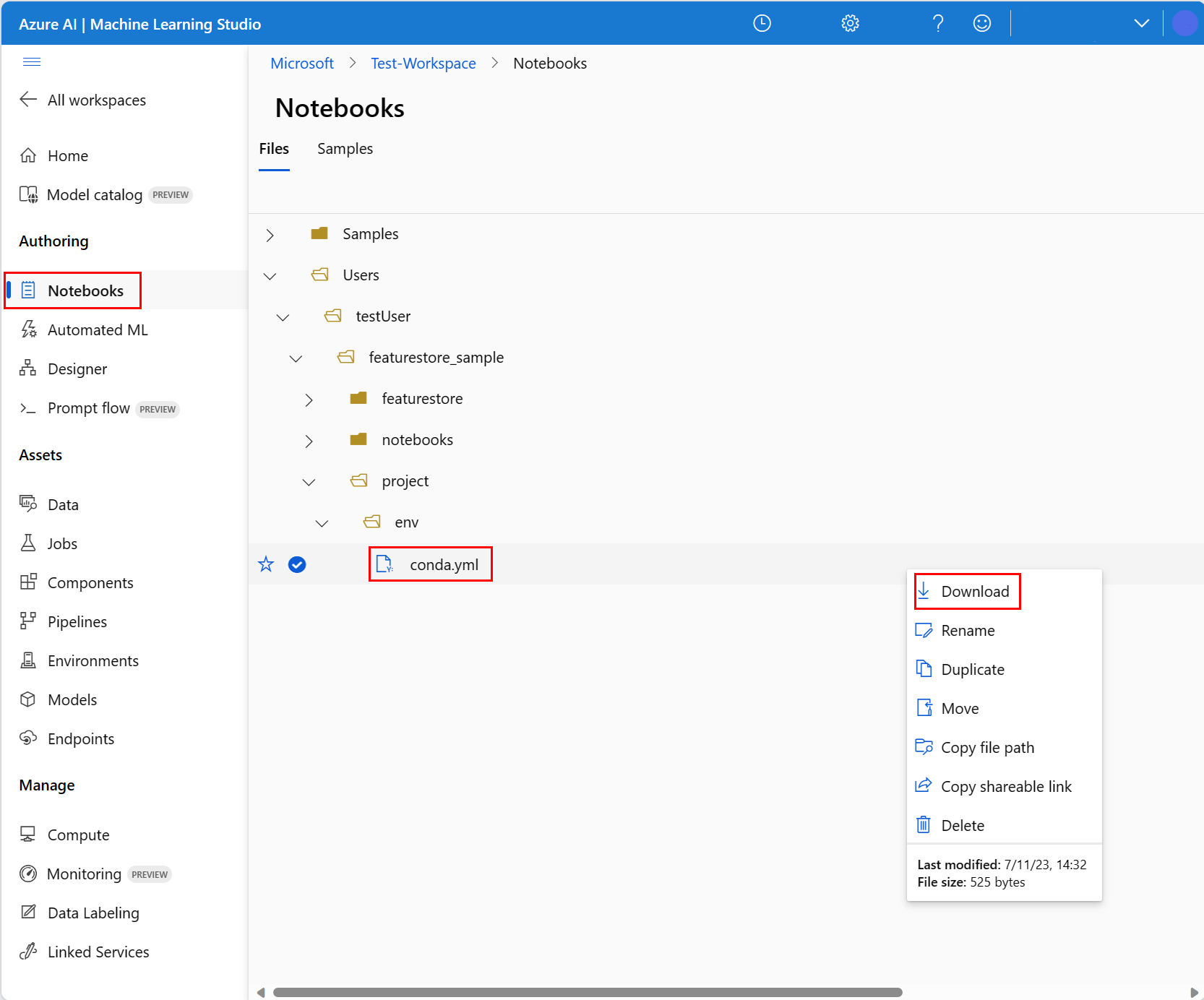
- Selecteer Serverloze Spark Compute in de bovenste navigatievervolgkeuzelijst Compute . Deze bewerking kan één tot twee minuten duren. Wacht tot een statusbalk bovenaan de sessie configureren wordt weergegeven.
- Selecteer Sessie configureren in de bovenste statusbalk.
- Selecteer Python-pakketten.
- Selecteer Conda-bestanden uploaden.
- Selecteer het
conda.ymlbestand dat u hebt gedownload op uw lokale apparaat. - (Optioneel) Verhoog de time-out van de sessie (niet-actieve tijd in minuten) om de opstarttijd van het serverloze Spark-cluster te verminderen.
Open het notebook in de Azure Machine Learning-omgeving en selecteer vervolgens Sessie configureren.
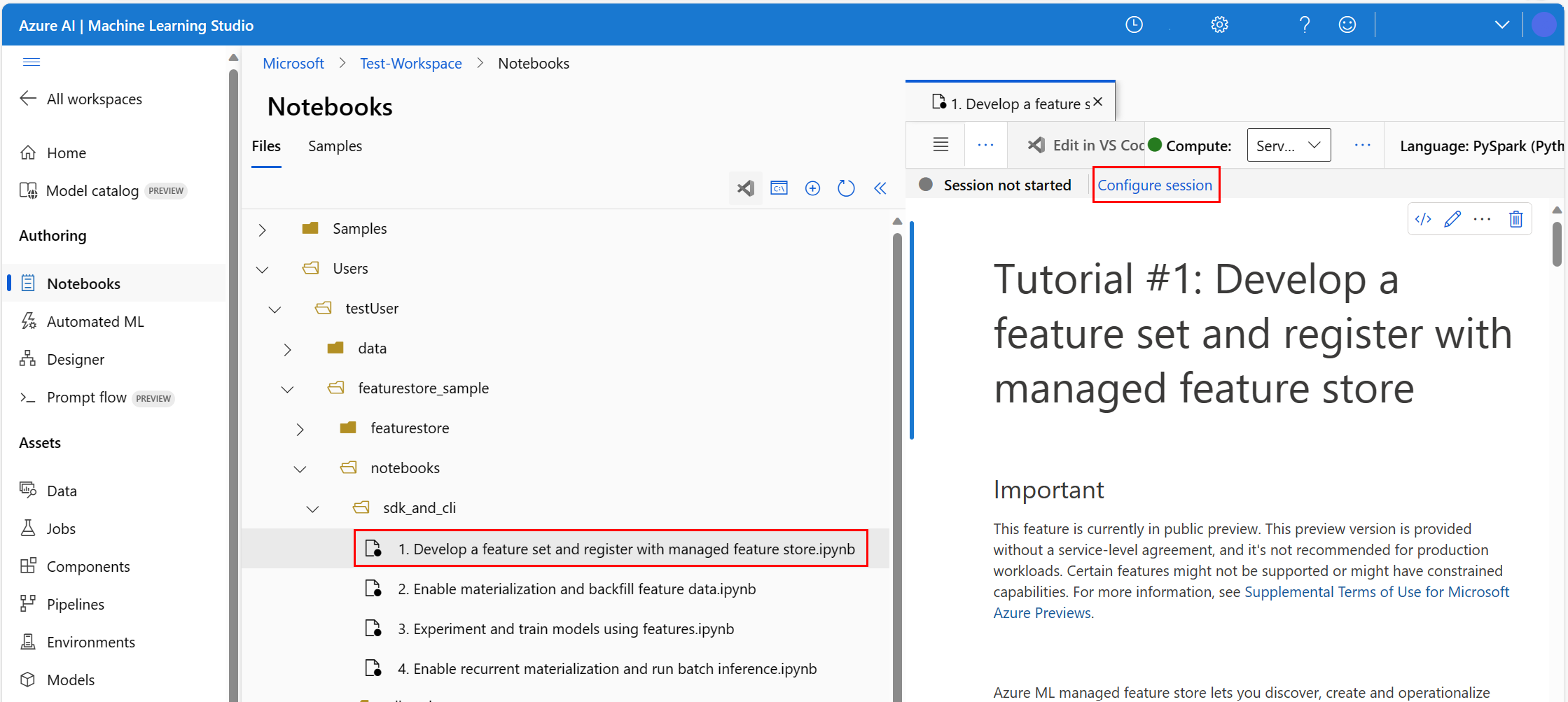
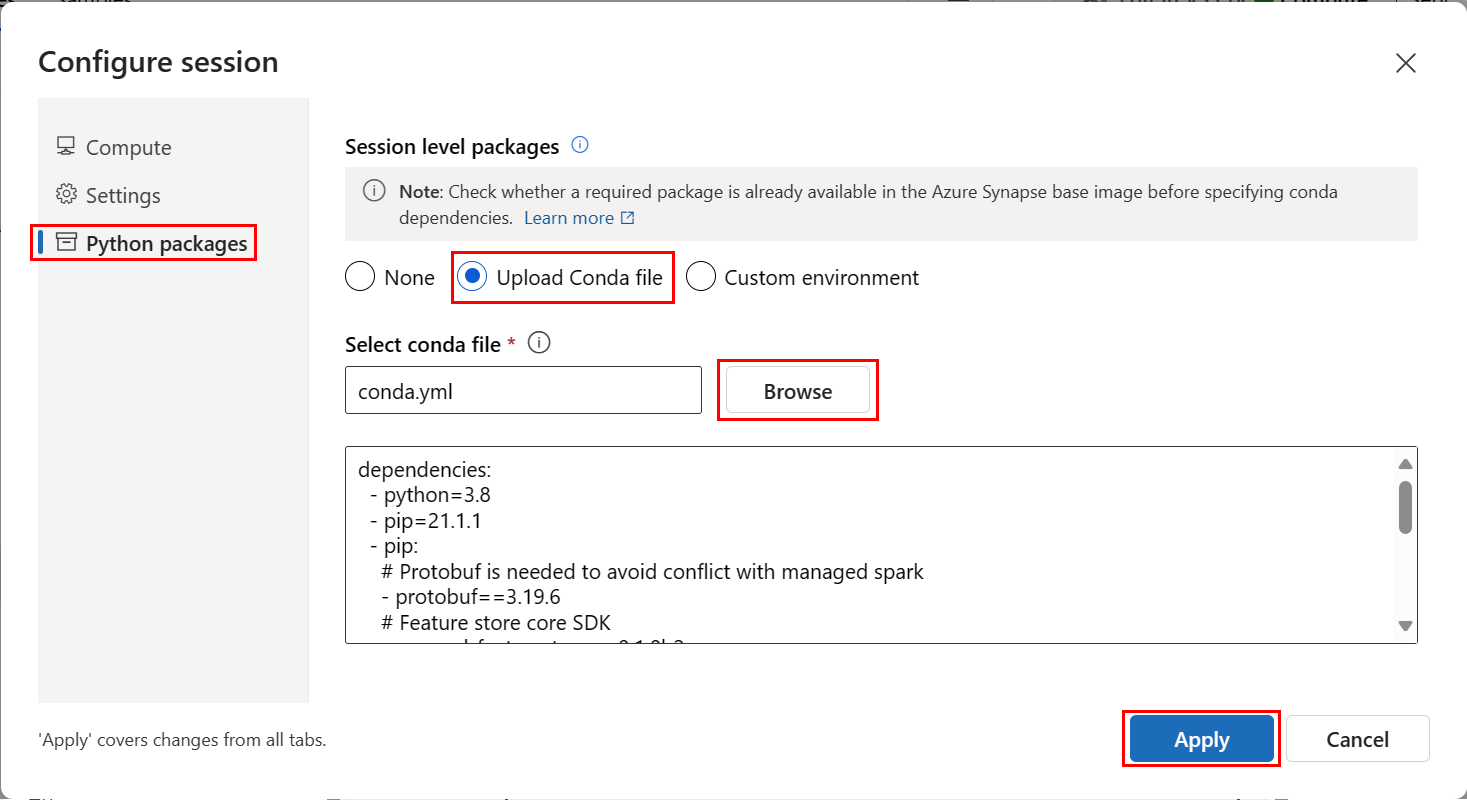
Selecteer Python-pakketten in het deelvenster Sessie configureren.
Upload het Conda-bestand:
- Selecteer Op het tabblad Python-pakketten het Conda-bestand uploaden.
- Blader naar de map die als host fungeert voor het Conda-bestand.
- Selecteer conda.yml en selecteer vervolgens Openen.
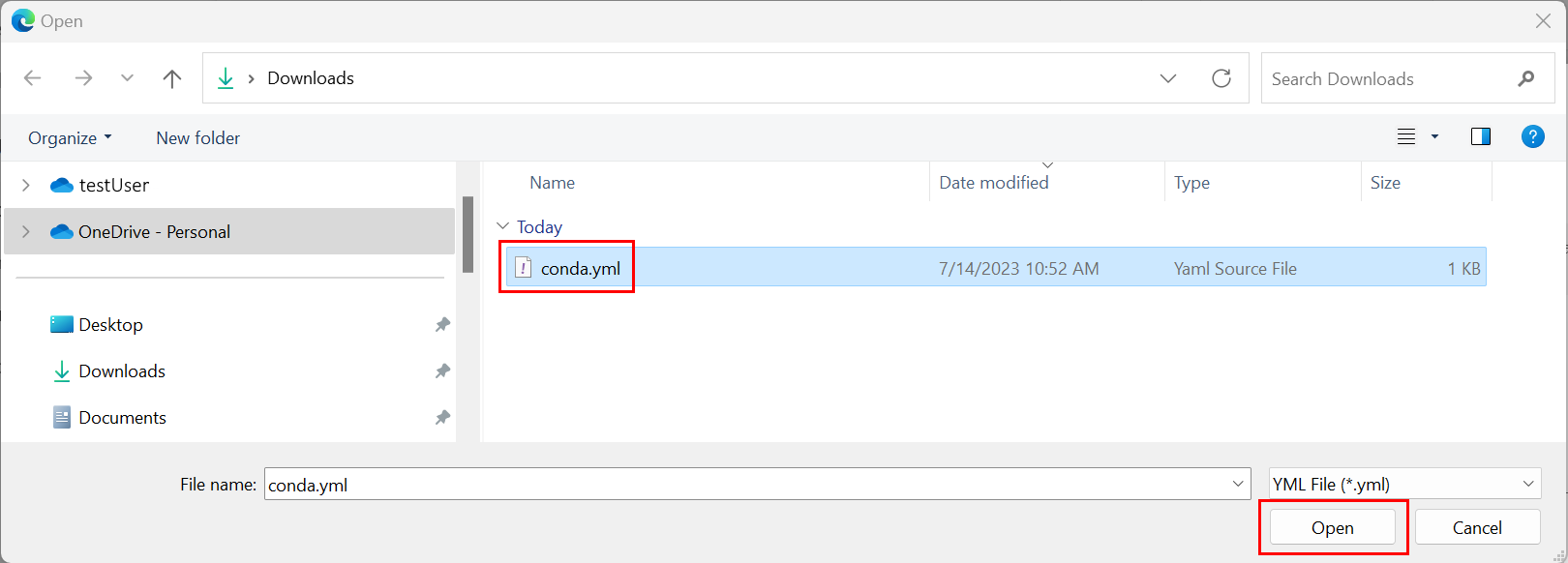
Selecteer Toepassen.






De Spark-sessie starten
# Run this cell to start the spark session (any code block will start the session ). This can take around 10 mins.
print("start spark session")De hoofdmap voor de voorbeelden instellen
import os
# Please update <your_user_alias> below (or any custom directory you uploaded the samples to).
# You can find the name from the directory structure in the left navigation panel.
root_dir = "./Users/<your_user_alias>/featurestore_sample"
if os.path.isdir(root_dir):
print("The folder exists.")
else:
print("The folder does not exist. Please create or fix the path")De CLI instellen
Niet van toepassing.
Notitie
U gebruikt een functiearchief om functies in projecten opnieuw te gebruiken. U gebruikt een projectwerkruimte (een Azure Machine Learning-werkruimte) om deductiemodellen te trainen door gebruik te maken van functies uit functiearchieven. Veel projectwerkruimten kunnen dezelfde functieopslag delen en opnieuw gebruiken.
In deze zelfstudie worden twee SDK's gebruikt:
CRUD SDK voor functiearchief
U gebruikt dezelfde
MLClientSDK (pakketnaamazure-ai-ml) die u gebruikt met de Azure Machine Learning-werkruimte. Een functiearchief wordt geïmplementeerd als een type werkruimte. Als gevolg hiervan wordt deze SDK gebruikt voor CRUD-bewerkingen voor functiearchieven, functiesets en entiteiten voor het onderdelenarchief.Feature store core SDK
Deze SDK (
azureml-featurestore) is bedoeld voor ontwikkeling en verbruik van functiessets. In latere stappen in deze zelfstudie worden deze bewerkingen beschreven:- Een specificatie van een functieset ontwikkelen.
- Functiegegevens ophalen.
- Een geregistreerde functieset weergeven of ophalen.
- Specificaties voor het ophalen van functies genereren en oplossen.
- Trainings- en deductiegegevens genereren met behulp van point-in-time joins.
Voor deze zelfstudie is geen expliciete installatie van deze SDK's vereist, omdat de eerdere conda.yml instructies deze stap behandelen.
Een minimaal functiearchief maken
Parameters voor het functiearchief instellen, waaronder naam, locatie en andere waarden.
# We use the subscription, resource group, region of this active project workspace. # You can optionally replace them to create the resources in a different subsciprtion/resource group, or use existing resources. import os featurestore_name = "<FEATURESTORE_NAME>" featurestore_location = "eastus" featurestore_subscription_id = os.environ["AZUREML_ARM_SUBSCRIPTION"] featurestore_resource_group_name = os.environ["AZUREML_ARM_RESOURCEGROUP"]Maak het functiearchief.
from azure.ai.ml import MLClient from azure.ai.ml.entities import ( FeatureStore, FeatureStoreEntity, FeatureSet, ) from azure.ai.ml.identity import AzureMLOnBehalfOfCredential ml_client = MLClient( AzureMLOnBehalfOfCredential(), subscription_id=featurestore_subscription_id, resource_group_name=featurestore_resource_group_name, ) fs = FeatureStore(name=featurestore_name, location=featurestore_location) # wait for feature store creation fs_poller = ml_client.feature_stores.begin_create(fs) print(fs_poller.result())Initialiseer een core SDK-client voor de functieopslag voor Azure Machine Learning.
Zoals eerder in deze zelfstudie is uitgelegd, wordt de core SDK-client van de feature store gebruikt om functies te ontwikkelen en te gebruiken.
# feature store client from azureml.featurestore import FeatureStoreClient from azure.ai.ml.identity import AzureMLOnBehalfOfCredential featurestore = FeatureStoreClient( credential=AzureMLOnBehalfOfCredential(), subscription_id=featurestore_subscription_id, resource_group_name=featurestore_resource_group_name, name=featurestore_name, )Verken de rol 'Azure Machine Learning Datawetenschapper' in het functiearchief aan uw gebruikersidentiteit. Haal de waarde van uw Microsoft Entra-object-id op via De Azure-portal, zoals beschreven in De object-id van de gebruiker zoeken.
Wijs de azureML-Datawetenschapper rol toe aan uw gebruikersidentiteit, zodat deze resources in de werkruimte van het functiearchief kan maken. De machtigingen hebben mogelijk enige tijd nodig om door te geven.
Ga voor meer informatie over toegangsbeheer naar het toegangsbeheer beheren voor een beheerde functieopslagresource .
your_aad_objectid = "<USER_AAD_OBJECTID>" !az role assignment create --role "AzureML Data Scientist" --assignee-object-id $your_aad_objectid --assignee-principal-type User --scope $feature_store_arm_id
Prototype maken en een functieset ontwikkelen
In deze stappen bouwt u een functieset met de naam transactions met functies op basis van een rolling venster:
Verken de
transactionsbrongegevens.In dit notebook worden voorbeeldgegevens gebruikt die worden gehost in een openbaar toegankelijke blobcontainer. Het kan alleen worden gelezen in Spark via een
wasbsstuurprogramma. Wanneer u functiesets maakt met behulp van uw eigen brongegevens, host u deze in een Azure Data Lake Storage Gen2-account en gebruikt u eenabfssstuurprogramma in het gegevenspad.# remove the "." in the roor directory path as we need to generate absolute path to read from spark transactions_source_data_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/datasources/transactions-source/*.parquet" transactions_src_df = spark.read.parquet(transactions_source_data_path) display(transactions_src_df.head(5)) # Note: display(training_df.head(5)) displays the timestamp column in a different format. You can can call transactions_src_df.show() to see correctly formatted valueOntwikkel lokaal de functieset.
Een specificatie van een functieset is een zelfstandige definitie van een functieset die u lokaal kunt ontwikkelen en testen. Hier maakt u deze statistische functies voor rolling vensters:
transactions three-day counttransactions amount three-day avgtransactions amount three-day sumtransactions seven-day counttransactions amount seven-day avgtransactions amount seven-day sum
Bekijk het codebestand voor functietransformatie: featurestore/featuresets/transactions/transformation_code/transaction_transform.py. Let op de rolling aggregatie die is gedefinieerd voor de functies. Dit is een Spark-transformator.
Ga naar de resource Wat is een beheerd functiearchief? voor meer informatie over de functieset en transformaties.
from azureml.featurestore import create_feature_set_spec from azureml.featurestore.contracts import ( DateTimeOffset, TransformationCode, Column, ColumnType, SourceType, TimestampColumn, ) from azureml.featurestore.feature_source import ParquetFeatureSource transactions_featureset_code_path = ( root_dir + "/featurestore/featuresets/transactions/transformation_code" ) transactions_featureset_spec = create_feature_set_spec( source=ParquetFeatureSource( path="wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/datasources/transactions-source/*.parquet", timestamp_column=TimestampColumn(name="timestamp"), source_delay=DateTimeOffset(days=0, hours=0, minutes=20), ), feature_transformation=TransformationCode( path=transactions_featureset_code_path, transformer_class="transaction_transform.TransactionFeatureTransformer", ), index_columns=[Column(name="accountID", type=ColumnType.string)], source_lookback=DateTimeOffset(days=7, hours=0, minutes=0), temporal_join_lookback=DateTimeOffset(days=1, hours=0, minutes=0), infer_schema=True, )Exporteren als een specificatie van een functieset.
Als u de specificatie van de functieset wilt registreren bij het functiearchief, moet u die specificatie opslaan in een specifieke indeling.
Controleer de specificatie van de gegenereerde
transactionsfunctieset. Open dit bestand vanuit de bestandsstructuur om de specificatie featurestore/featuresets/accounts/spec/FeaturesetSpec.yaml weer te geven.De specificatie bevat deze elementen:
source: Een verwijzing naar een opslagresource. In dit geval is het een Parquet-bestand in een blobopslagresource.features: Een lijst met functies en hun gegevenstypen. Als u transformatiecode opgeeft, moet de code een DataFrame retourneren dat is toegewezen aan de functies en gegevenstypen.index_columns: De joinsleutels die vereist zijn voor toegang tot waarden uit de functieset.
Voor meer informatie over de specificatie gaat u naar de informatie over entiteiten op het hoogste niveau in het beheerde functiearchief en de CLI-functieset (v2) yamL-schemaresources .
Het behouden van de specificatie van de functieset biedt een ander voordeel: de specificatie van de functieset ondersteunt broncodebeheer.
import os # Create a new folder to dump the feature set specification. transactions_featureset_spec_folder = ( root_dir + "/featurestore/featuresets/transactions/spec" ) # Check if the folder exists, create one if it does not exist. if not os.path.exists(transactions_featureset_spec_folder): os.makedirs(transactions_featureset_spec_folder) transactions_featureset_spec.dump(transactions_featureset_spec_folder, overwrite=True)
Een entiteit in het functiearchief registreren
Als best practice helpen entiteiten bij het afdwingen van het gebruik van dezelfde joinsleuteldefinitie, in verschillende functiesets die gebruikmaken van dezelfde logische entiteiten. Voorbeelden van entiteiten zijn accounts en klanten. Entiteiten worden doorgaans eenmaal gemaakt en vervolgens opnieuw gebruikt in functiesets. Ga voor meer informatie naar de entiteiten op het hoogste niveau in het beheerde functiearchief.
Initialiseer de CRUD-client voor het functiearchief.
Zoals eerder in deze zelfstudie is uitgelegd,
MLClientwordt gebruikt voor het maken, lezen, bijwerken en verwijderen van een onderdeelarchiefasset. In het voorbeeld van de notebookcodecel die hier wordt weergegeven, wordt gezocht naar het functiearchief dat u in een eerdere stap hebt gemaakt. Hier kunt u dezelfde waarde die u eerder in deze zelfstudie hebt gebruikt, niet opnieuw gebruikenml_client, omdat deze waarde is gericht op het niveau van de resourcegroep. Het juiste bereik is een vereiste voor het maken van een functiearchief.In dit codevoorbeeld is het bereik van de client op het niveau van het functiearchief.
# MLClient for feature store. fs_client = MLClient( AzureMLOnBehalfOfCredential(), featurestore_subscription_id, featurestore_resource_group_name, featurestore_name, )Registreer de
accountentiteit bij het functiearchief.Maak een
accountentiteit met de joinsleutelaccountIDvan het typestring.from azure.ai.ml.entities import DataColumn, DataColumnType account_entity_config = FeatureStoreEntity( name="account", version="1", index_columns=[DataColumn(name="accountID", type=DataColumnType.STRING)], stage="Development", description="This entity represents user account index key accountID.", tags={"data_typ": "nonPII"}, ) poller = fs_client.feature_store_entities.begin_create_or_update(account_entity_config) print(poller.result())
De transactiefunctieset registreren bij het functiearchief
Gebruik deze code om een onderdelensetasset te registreren bij het functiearchief. Vervolgens kunt u die asset opnieuw gebruiken en deze eenvoudig delen. Registratie van een functiesetasset biedt beheerde mogelijkheden, waaronder versiebeheer en materialisatie. Latere stappen in deze reeks zelfstudies hebben betrekking op beheerde mogelijkheden.
from azure.ai.ml.entities import FeatureSetSpecification
transaction_fset_config = FeatureSet(
name="transactions",
version="1",
description="7-day and 3-day rolling aggregation of transactions featureset",
entities=[f"azureml:account:1"],
stage="Development",
specification=FeatureSetSpecification(path=transactions_featureset_spec_folder),
tags={"data_type": "nonPII"},
)
poller = fs_client.feature_sets.begin_create_or_update(transaction_fset_config)
print(poller.result())De gebruikersinterface van het functiearchief verkennen
Het maken en bijwerken van onderdelenopslagassets kan alleen worden uitgevoerd via de SDK en CLI. U kunt de gebruikersinterface gebruiken om te zoeken of door het functiearchief te bladeren:
- Open de algemene landingspagina van Azure Machine Learning.
- Selecteer Functiearchieven in het linkerdeelvenster.
- Selecteer in de lijst met toegankelijke functiearchieven het functiearchief dat u eerder in deze zelfstudie hebt gemaakt.
De rol Lezer van opslagblobgegevenslezer toegang verlenen tot uw gebruikersaccount in het offlinearchief
De rol Opslagblobgegevenslezer moet worden toegewezen aan uw gebruikersaccount in het offlinearchief. Dit zorgt ervoor dat het gebruikersaccount gerealiseerde functiegegevens kan lezen uit het offline materialisatiearchief.
Haal de waarde van uw Microsoft Entra-object-id op via De Azure-portal, zoals beschreven in De object-id van de gebruiker zoeken.
Informatie ophalen over het offline materialisatiearchief op de pagina Overzicht van het functiearchief in de gebruikersinterface van de functieopslag. U vindt de waarden voor de abonnements-id van het opslagaccount, de naam van de opslagaccountresourcegroep en de naam van het opslagaccount voor het offline materialisatiearchief in de kaart Offline materialisatieopslag .
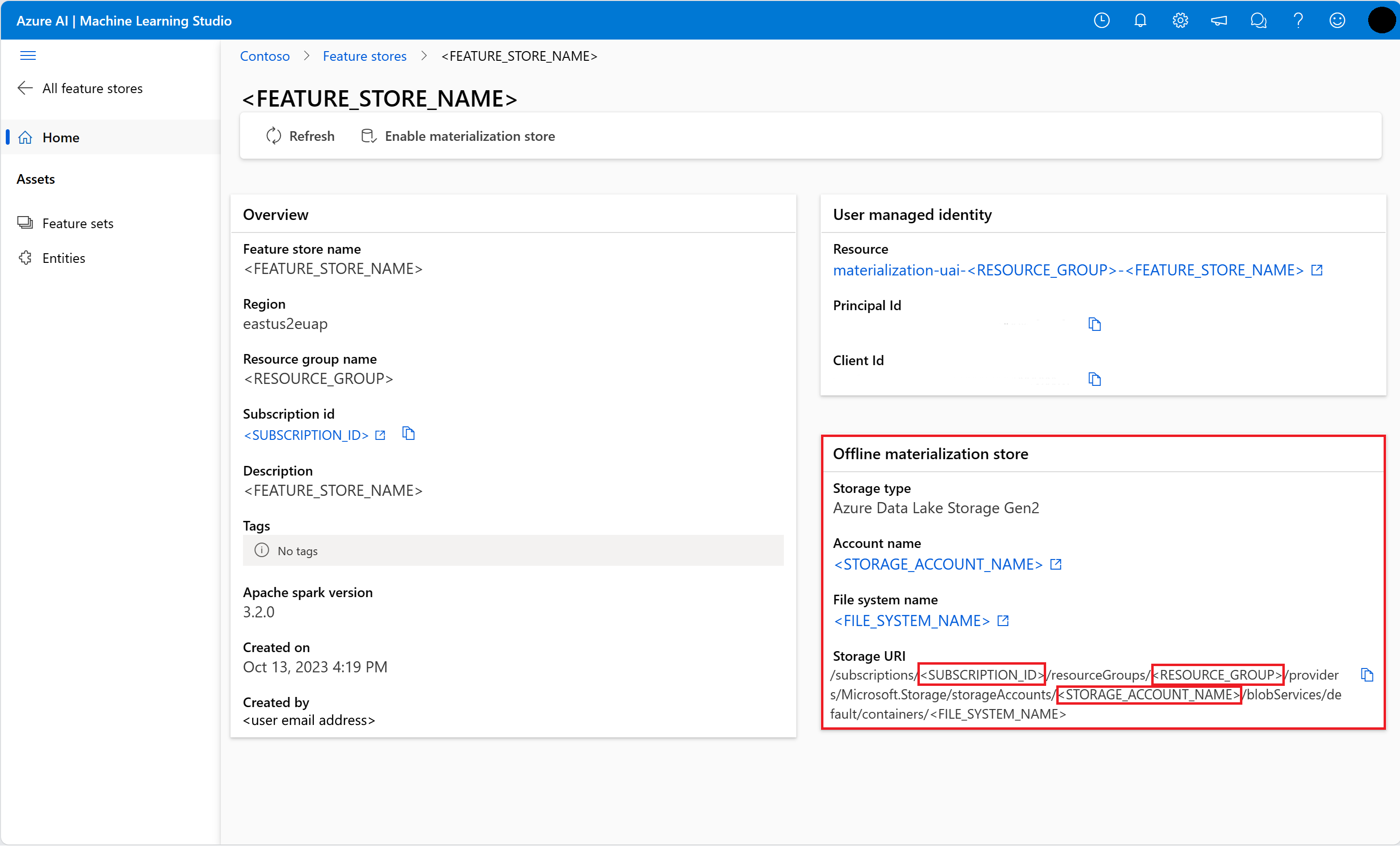
Voor meer informatie over toegangsbeheer gaat u naar het toegangsbeheer beheren voor een beheerde functieopslagresource .
Voer deze codecel uit voor roltoewijzing. De machtigingen hebben mogelijk enige tijd nodig om door te geven.
# This utility function is created for ease of use in the docs tutorials. It uses standard azure API's. # You can optionally inspect it `featurestore/setup/setup_storage_uai.py`. import sys sys.path.insert(0, root_dir + "/featurestore/setup") from setup_storage_uai import grant_user_aad_storage_data_reader_role your_aad_objectid = "<USER_AAD_OBJECTID>" storage_subscription_id = "<SUBSCRIPTION_ID>" storage_resource_group_name = "<RESOURCE_GROUP>" storage_account_name = "<STORAGE_ACCOUNT_NAME>" grant_user_aad_storage_data_reader_role( AzureMLOnBehalfOfCredential(), your_aad_objectid, storage_subscription_id, storage_resource_group_name, storage_account_name, )

Een dataframe voor training genereren met behulp van de geregistreerde functieset
Observatiegegevens laden.
Observatiegegevens bevatten doorgaans de kerngegevens die worden gebruikt voor training en deductie. Deze gegevens worden samengevoegd met de functiegegevens om de volledige trainingsgegevensresource te maken.
Observatiegegevens zijn gegevens die tijdens de gebeurtenis zelf zijn vastgelegd. Hier bevat het kerntransactiegegevens, waaronder transactie-id, account-id en transactiebedragwaarden. Omdat u deze gebruikt voor training, heeft het ook een toegevoegde doelvariabele (is_fraud).
observation_data_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/observation_data/train/*.parquet" observation_data_df = spark.read.parquet(observation_data_path) obs_data_timestamp_column = "timestamp" display(observation_data_df) # Note: the timestamp column is displayed in a different format. Optionally, you can can call training_df.show() to see correctly formatted valueHaal de geregistreerde functieset op en vermeld de bijbehorende functies.
# Look up the featureset by providing a name and a version. transactions_featureset = featurestore.feature_sets.get("transactions", "1") # List its features. transactions_featureset.features# Print sample values. display(transactions_featureset.to_spark_dataframe().head(5))Selecteer de functies die deel uitmaken van de trainingsgegevens. Gebruik vervolgens de SDK voor het functiearchief om de trainingsgegevens zelf te genereren.
from azureml.featurestore import get_offline_features # You can select features in pythonic way. features = [ transactions_featureset.get_feature("transaction_amount_7d_sum"), transactions_featureset.get_feature("transaction_amount_7d_avg"), ] # You can also specify features in string form: featureset:version:feature. more_features = [ f"transactions:1:transaction_3d_count", f"transactions:1:transaction_amount_3d_avg", ] more_features = featurestore.resolve_feature_uri(more_features) features.extend(more_features) # Generate training dataframe by using feature data and observation data. training_df = get_offline_features( features=features, observation_data=observation_data_df, timestamp_column=obs_data_timestamp_column, ) # Ignore the message that says feature set is not materialized (materialization is optional). We will enable materialization in the subsequent part of the tutorial. display(training_df) # Note: the timestamp column is displayed in a different format. Optionally, you can can call training_df.show() to see correctly formatted valueEen punt-in-time join voegt de functies toe aan de trainingsgegevens.
Offline materialisatie inschakelen voor de transactions functieset
Nadat de materialisatie van functieset is ingeschakeld, kunt u een backfill uitvoeren. U kunt ook terugkerende materialisatietaken plannen. Ga naar de derde zelfstudie in de reeksresource voor meer informatie.
Stel spark.sql.shuffle.partitions in het yaml-bestand in op basis van de grootte van de functiegegevens
De spark-configuratie spark.sql.shuffle.partitions is een OPTIONELE parameter die van invloed kan zijn op het aantal parquet-bestanden dat (per dag) wordt gegenereerd wanneer de functieset wordt gerealiseerd in de offlineopslag. De standaardwaarde van deze parameter is 200. Als best practice vermijdt u het genereren van veel kleine Parquet-bestanden. Als het ophalen van offlinefuncties traag wordt na de materialisatie van functieset, gaat u naar de bijbehorende map in het offlinearchief om te controleren of het probleem te veel kleine Parquet-bestanden (per dag) omvat en past u de waarde van deze parameter dienovereenkomstig aan.
Notitie
De voorbeeldgegevens die in dit notebook worden gebruikt, zijn klein. Daarom is deze parameter ingesteld op 1 in het bestand featureset_asset_offline_enabled.yaml.
from azure.ai.ml.entities import (
MaterializationSettings,
MaterializationComputeResource,
)
transactions_fset_config = fs_client._featuresets.get(name="transactions", version="1")
transactions_fset_config.materialization_settings = MaterializationSettings(
offline_enabled=True,
resource=MaterializationComputeResource(instance_type="standard_e8s_v3"),
spark_configuration={
"spark.driver.cores": 4,
"spark.driver.memory": "36g",
"spark.executor.cores": 4,
"spark.executor.memory": "36g",
"spark.executor.instances": 2,
"spark.sql.shuffle.partitions": 1,
},
schedule=None,
)
fs_poller = fs_client.feature_sets.begin_create_or_update(transactions_fset_config)
print(fs_poller.result())U kunt de functiesetasset ook opslaan als een YAML-resource.
## uncomment to run
transactions_fset_config.dump(
root_dir
+ "/featurestore/featuresets/transactions/featureset_asset_offline_enabled.yaml"
)Backfill-gegevens voor de transactions functieset
Zoals eerder is uitgelegd, worden de functiewaarden voor een functievenster berekend en worden deze berekende waarden opgeslagen in een materialisatiearchief. Functiever materialisatie verhoogt de betrouwbaarheid en beschikbaarheid van de berekende waarden. Alle functiequery's gebruiken nu de waarden uit het materialisatiearchief. Met deze stap wordt een eenmalige backfill uitgevoerd voor een functievenster van 18 maanden.
Notitie
Mogelijk moet u een backfillgegevensvensterwaarde bepalen. Het venster moet overeenkomen met het venster van uw trainingsgegevens. Als u bijvoorbeeld 18 maanden aan gegevens wilt gebruiken voor training, moet u functies 18 maanden ophalen. Dit betekent dat u een backfill moet uitvoeren voor een venster van 18 maanden.
Deze codecel materialiseert gegevens op basis van de huidige status Geen of Onvolledig voor het gedefinieerde functievenster.
from datetime import datetime
from azure.ai.ml.entities import DataAvailabilityStatus
st = datetime(2022, 1, 1, 0, 0, 0, 0)
et = datetime(2023, 6, 30, 0, 0, 0, 0)
poller = fs_client.feature_sets.begin_backfill(
name="transactions",
version="1",
feature_window_start_time=st,
feature_window_end_time=et,
data_status=[DataAvailabilityStatus.NONE],
)
print(poller.result().job_ids)# Get the job URL, and stream the job logs.
fs_client.jobs.stream(poller.result().job_ids[0])Tip
- De
timestampkolom moet de indeling volgenyyyy-MM-ddTHH:mm:ss.fffZ. - De
feature_window_start_timeenfeature_window_end_timegranulariteit is beperkt tot seconden. Eventuele milliseconden in hetdatetimeobject worden genegeerd. - Er wordt alleen een materialisatietaak verzonden als de gegevens in het functievenster overeenkomen met de
data_statusgedefinieerde taak tijdens het indienen van de backfilltaak.
Voorbeeldgegevens uit de functieset afdrukken. De uitvoerinformatie laat zien dat de gegevens zijn opgehaald uit het materialisatiearchief. De get_offline_features() methode heeft de training- en deductiegegevens opgehaald. Het maakt standaard ook gebruik van het materialisatiearchief.
# Look up the feature set by providing a name and a version and display few records.
transactions_featureset = featurestore.feature_sets.get("transactions", "1")
display(transactions_featureset.to_spark_dataframe().head(5))Verder verkennen van offline functie materialisatie
U kunt de materialisatiestatus van functies verkennen voor een functieset in de gebruikersinterface van Materialization-taken .
Open de algemene landingspagina van Azure Machine Learning.
Selecteer Functiearchieven in het linkerdeelvenster.
Selecteer in de lijst met toegankelijke functiearchieven het functiearchief waarvoor u backfill hebt uitgevoerd.
Selecteer het tabblad Materialisatietaken .
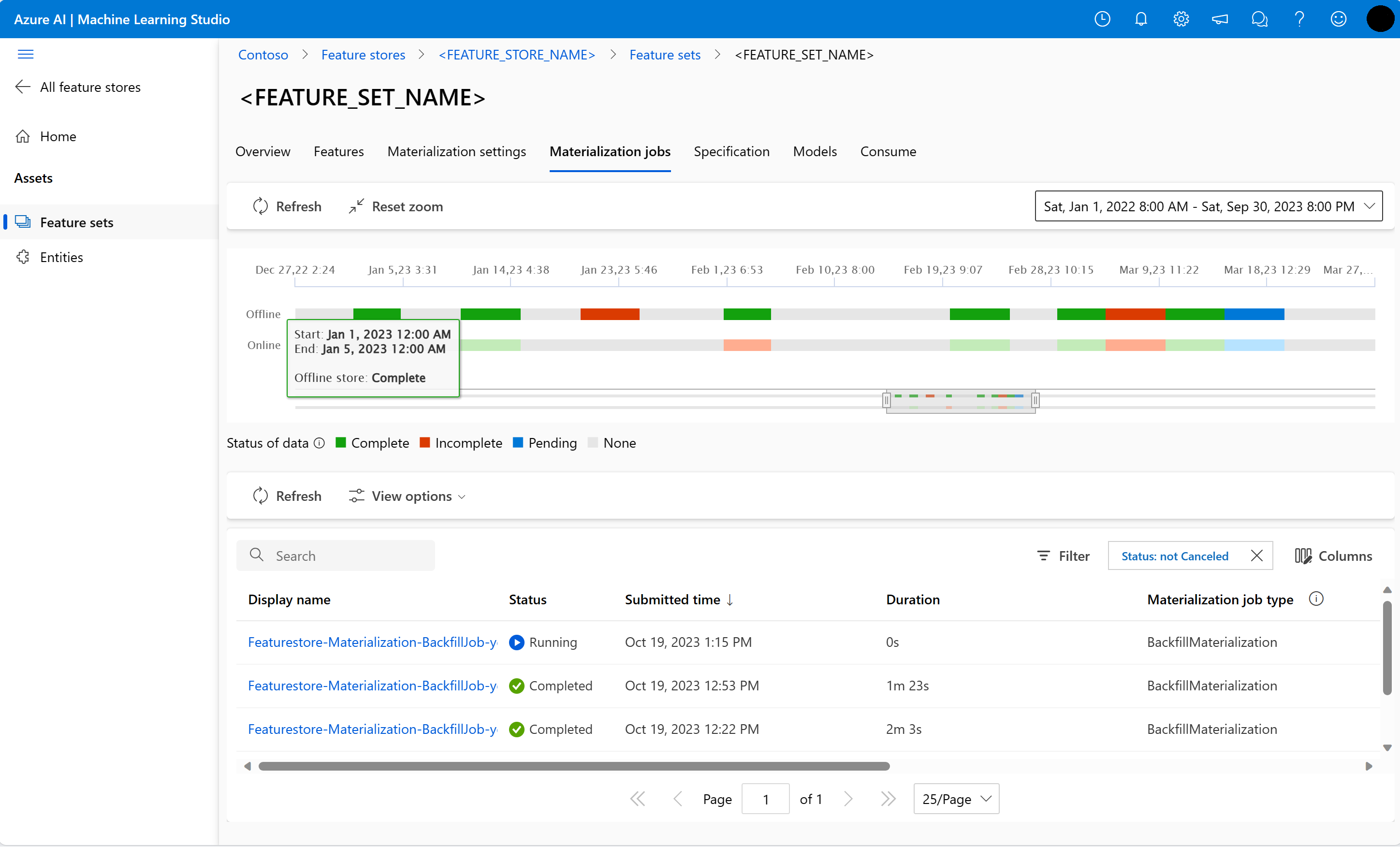

De status van gegevens materialisatie kan zijn
- Voltooid (groen)
- Onvolledig (rood)
- In behandeling (blauw)
- Geen (grijs)
Een gegevensinterval vertegenwoordigt een aaneengesloten gedeelte van gegevens met dezelfde gegevens materialisatiestatus. De eerdere momentopname heeft bijvoorbeeld 16 gegevensintervallen in het offline materialisatiearchief.
De gegevens kunnen maximaal 2000 gegevensintervallen bevatten. Als uw gegevens meer dan 2000 gegevensintervallen bevatten, maakt u een nieuwe versie van de functieset.
U kunt een lijst opgeven met meer dan één gegevensstatus (bijvoorbeeld
["None", "Incomplete"]) in één backfilltaak.Tijdens het doorvoeren wordt een nieuwe materialisatietaak verzonden voor elk gegevensinterval dat binnen het gedefinieerde functievenster valt.
Als een materialisatietaak in behandeling is of als die taak wordt uitgevoerd voor een gegevensinterval dat nog niet is ingevuld, wordt er geen nieuwe taak verzonden voor dat gegevensinterval.
U kunt een mislukte materialisatietaak opnieuw proberen.
Notitie
De taak-id van een mislukte materialisatietaak ophalen:
- Navigeer naar de gebruikersinterface voor materialisatietaken van de functieset.
- Selecteer de weergavenaam van een specifieke taak met de status Mislukt.
- Zoek de taak-id onder de eigenschap Naam op de pagina Taakoverzicht. Begint met
Featurestore-Materialization-.
poller = fs_client.feature_sets.begin_backfill(
name="transactions",
version=version,
job_id="<JOB_ID_OF_FAILED_MATERIALIZATION_JOB>",
)
print(poller.result().job_ids)
Offline materialisatiearchief bijwerken
- Als een offline materialisatiearchief moet worden bijgewerkt op het niveau van het functiearchief, moeten alle onderdelensets in het functiearchief offline materialisatie uitgeschakeld hebben.
- Als offline materialisatie is uitgeschakeld voor een functieset, wordt de materialisatiestatus van de gegevens die al zijn gerealiseerd in het offline materialisatiearchief opnieuw ingesteld. Het opnieuw instellen geeft gegevens weer die al onbruikbaar zijn. U moet materialisatietaken opnieuw indienen nadat u offline materialisatie hebt ingeschakeld.
In deze zelfstudie zijn de trainingsgegevens gebouwd met functies uit het functiearchief, materialisatie ingeschakeld voor offlinefunctieopslag en een backfill uitgevoerd. Vervolgens voert u modeltraining uit met behulp van deze functies.
Opschonen
In de vijfde zelfstudie in de reeks wordt beschreven hoe u de resources verwijdert.
Volgende stappen
- Zie de volgende zelfstudie in de reeks: Experimenteer en train modellen met behulp van functies.
- Meer informatie over concepten en entiteiten op het hoogste niveau in het beheerde functiearchief.
- Meer informatie over identiteits- en toegangsbeheer voor het beheerde functiearchief.
- Bekijk de gids voor probleemoplossing voor het opslaan van beheerde functies.
- Bekijk de YAML-verwijzing.