Zelfstudie: Vraag voorspellen zonder code geautomatiseerde machine learning in de Azure Machine Learning-studio
Leer hoe u een tijdreeksprognosemodel maakt zonder één regel code te schrijven met behulp van geautomatiseerde machine learning in de Azure Machine Learning-studio. Dit model voorspelt de huurvraag voor een service voor het delen van fietsen.
U schrijft geen code in deze zelfstudie. U gebruikt de studio-interface om training uit te voeren. U leert hoe u de volgende taken uitvoert:
- Een gegevensset maken en laden.
- Een automatisch ML-experiment configureren en uitvoeren.
- Prognose-instellingen specificeren.
- De resultaten van het experiment verkennen.
- Het beste model implementeren.
Probeer ook geautomatiseerde machine learning voor deze andere modeltypen:
- Zie Zelfstudie: Een classificatiemodel maken met geautomatiseerde ML in Azure Machine Learning voor een voorbeeld zonder code van een classificatiemodel.
- Zie de zelfstudie: Een objectdetectiemodel trainen met AutoML en Python voor een codevoorbeeld van een objectdetectiemodel.
Vereisten
Een Azure Machine Learning-werkruimte. Zie Werkruimtebronnen maken.
Het gegevensbestand bike-no.csv downloaden
Meld u aan bij de studio
Voor deze zelfstudie maakt u een geautomatiseerd ML-experiment in Azure Machine Learning Studio, een geconsolideerde webinterface met hulpmiddelen voor machine learning waar gegevenswetenschappers, ongeacht hun vaardigheidsniveaus, scenario's kunnen uitvoeren. De studio wordt niet ondersteund in Internet Explorer-browsers.
Meld u aan bij Azure Machine Learning Studio.
Selecteer uw abonnement en de werkruimte die u heeft gemaakt.
Selecteer Aan de slag.
Selecteer in het linkerdeelvenster Geautomatiseerde ML in de sectie Maken.
Selecteer +Nieuwe geautomatiseerde ML-taak.
Gegevensset maken en laden
Voordat u uw experiment gaat configureren, uploadt u uw gegevensbestand naar uw werkruimte in de vorm van een Azure Machine Learning-gegevensset. Als u dit doet, kunt u ervoor zorgen dat uw gegevens op de juiste wijze zijn opgemaakt voor uw experiment.
Op het formulier Gegevensset selecteren, selecteert u Uit lokale bestanden in de keuzelijst +Gegevensset maken.
Geef uw gegevensset een naam en een optionele beschrijving in het formulier Basisinformatie. Het type gegevensset moet standaard in Tabelvorm zijn, omdat automatische ML in Azure Machine Learning Studio momenteel alleen ondersteuning biedt voor gegevenssets in tabelvorm.
Selecteer Volgende in de linkerbenedenhoek
Selecteer, in het formulier Gegevensarchief- en bestandsselectie het standaard gegevensarchief dat automatisch werd ingesteld bij het aanmaken van uw werkruimte, workspaceblobstore (Azure Blob Storage). Dit is de opslaglocatie waar u uw gegevensbestand uploadt.
Selecteer Bestanden uploaden in de vervolgkeuzelijst Uploaden .
Kies het bestand bike-no.csv op uw lokale computer. Dit is het bestand dat u hebt gedownload als vereiste.
Selecteer Volgende
Wanneer het uploaden is voltooid, worden de instellingen en het voorbeeldformulier automatisch ingevuld op basis van het bestandstype.
Controleer of het formulier Instellingen en voorbeeld als volgt is ingevuld en selecteer Volgende.
Veld Beschrijving Waarde voor zelfstudie File format Definieert de indeling en het type gegevens dat is opgeslagen in een bestand. Met scheidingstekens Scheidingsteken Een of meer tekens die de grens aangeven tussen afzonderlijke, onafhankelijke regio's in tekst zonder opmaak of andere gegevensstromen. Door komma's gescheiden Codering Identificeert welke bit-naar-tekenschematabel er moet gebruikt worden om uw gegevensset te lezen. UTF-8 Kolomkoppen Geeft aan hoe koppen van de gegevensset eventueel worden behandeld. Alleen het eerste bestand bevat kopteksten Rijen overslaan Geeft aan hoeveel rijen er eventueel worden overgeslagen in de gegevensset. Geen Met het formulier Schema kunt u uw gegevens verder configureren voor dit experiment.
Voor dit voorbeeld negeert u de kolommen Informeel en Geregistreerd. Deze kolommen vormen een uitsplitsing van de kolom cnt, dus we nemen deze niet op.
Voor dit voorbeeld moet u ook de standaardwaarden voor de Eigenschappen en Type opgeven.
Selecteer Volgende.
Controleer of de informatie in het formulier Details bevestigen overeenkomt met wat voorheen in de formulieren Basisinformatie en Instellingen en voorbeeld werd ingevuld.
Selecteren Maken om uw gegevensset te voltooien.
Selecteer uw gegevensset wanneer deze verschijnt in de lijst.
Selecteer Volgende.
Taak configureren
Nadat u uw gegevens hebt geladen en geconfigureerd, stelt u uw externe rekendoel in en selecteert u welke kolom in uw gegevens u wilt voorspellen.
- Vul het taakformulier Configureren als volgt in:
Een naam voor het experiment invoeren:
automl-bikeshareSelecteer cnt als doelkolom, wat u wilt voorspellen. In deze kolom wordt het totale aantal gehuurde fietsen van bikeshare aangegeven.
Selecteer het rekencluster als rekentype.
Selecteer +Nieuw om uw rekendoel te configureren. Automatische ML ondersteunt alleen Azure Machine Learning-berekeningen.
Vul het formulier Virtuele machine selecteren in om uw rekenproces in te stellen.
Veld Beschrijving Waarde voor zelfstudie Virtuele-machinelaag Selecteer de prioriteit die het experiment moet krijgen Toegewezen VM-type Selecteer het type van de virtuele machine voor uw berekening. CPU (Central Processing Unit, centrale verwerkingseenheid) Grootte van de virtuele machine Selecteer de grootte van de virtuele machine voor uw berekening. Er wordt een lijst met aanbevolen grootten geboden, op basis van uw gegevens en het type experiment. Standard_DS12_V2 Selecteer Volgende om het formulier Instellingen configureren in te vullen.
Veld Beschrijving Waarde voor zelfstudie Naam berekening Een unieke naam die de context van uw berekening identificeert. bike-compute Min / Max knooppunten Als u gegevens wilt profilen, moet u een of meer knooppunten opgeven. Min. knooppunten: 1
Max. knooppunten: 6Seconden wachten voor omlaag schalen Niet-actieve tijd voordat het cluster automatisch omlaag wordt geschaald naar het minimum aantal knooppunten. 120 (standaardinstelling) Geavanceerde instellingen Instellingen voor het configureren en autoriseren van een virtueel netwerk voor uw experiment. Geen Selecteer Maken om het rekendoel op te halen.
Dit duurt enkele minuten.
Wanneer dit is voltooid, selecteert u uw nieuwe rekendoel uit de vervolgkeuzelijst.
Selecteer Volgende.
Prognose-instellingen selecteren
Voltooi de installatie voor uw automatische ML-experiment door het taaktype en de configuratie-instellingen van de machine learning op te geven.
Selecteer op het formulier Taaktype en instellingen de optie Prognose tijdreeks als het type machine learning-taak.
Selecteer datum als uw Tijdkolom en laat Tijdreeks-id’s leeg.
De frequentie is hoe vaak uw historische gegevens worden verzameld. Autodetectie behouden geselecteerd.
De prognoseperiode is hoe ver in de toekomst u voorspellingen wilt maken. Schakel Autodetectie uit en typ 14 in het veld.
Selecteer Aanvullende configuratie-instellingen weergeven en vul de velden als volgt in. Deze instellingen zijn bedoeld om de trainingstaak beter te besturen en om instellingen voor uw prognose op te geven. Anders worden de standaardinstellingen toegepast op basis van de selectie en gegevens van het experiment.
Aanvullende configuraties Beschrijving Waarde voor zelfstudie Primaire metrische gegevens Evaluatiewaarde waarmee het machine learning-algoritme wordt gemeten. Genormaliseerde wortel gemiddelde kwadraatfout Uitleg geven over het beste model Hiermee wordt automatisch uitleg gegeven over het beste model dat is gemaakt met geautomatiseerde ML. Inschakelen Geblokkeerde algoritmen Algoritmen die u niet wilt opnemen in de trainingstaak Extreme willekeurige structuren Aanvullende prognose-instellingen Deze instellingen helpen de nauwkeurigheid van het model te verbeteren.
Doelvertraging voorspellen: hoe ver terug u de vertraging van de doelvariabele wilt maken
Doelvenster voor rolling: hiermee geeft u de grootte op van het rolling venster waarvoor functies, zoals het maximum, de minimum en de som, worden gegenereerd.
Prognosedoelvertragingen: geen
Grootte van rollend venster: GeenCriterium voor afsluiten Als er aan een criterium is voldaan, wordt de trainingstaak gestopt. Trainingstaaktijd (uren): 3
Drempelwaarde voor metrische score: geenGelijktijdigheid Het maximum aantal parallelle iteraties uitgevoerd per iteratie Maximum aantal gelijktijdige iteraties: 6 Selecteer Opslaan.
Selecteer Volgende.
Op het formulier [Optioneel] Valideren en testen ,
- Selecteer kruisvalidatie in k-vouwen als validatietype.
- Selecteer 5 als uw aantal kruisvalidaties.
Experiment uitvoeren
Selecteer Voltooien om uw experiment uit te voeren. Het scherm Taakdetails wordt geopend met de taakstatus bovenaan het taaknummer. Deze status wordt bijgewerkt wanneer het experiment wordt uitgevoerd. Meldingen worden ook weergegeven in de rechterbovenhoek van Studio, zodat u op de hoogte blijft van de status van het experiment.
Belangrijk
De voorbereiding duurt 10-15 minuten om de experimenttaak voor te bereiden.
Zodra de uitvoering is gestart duurt het 2-3 minuten langer per iteratie.
In productie zou u waarschijnlijk even weglopen omdat dit proces tijd in beslag neemt. Terwijl u wacht, wordt u aangeraden de geteste algoritmen te verkennen op het tabblad Modellen.
Modellen bekijken
Ga naar het tabblad Modellen om de geteste algoritmen (modellen) te bekijken. De modellen worden standaard gerangschikt op hun metrische score terwijl ze worden voltooid. Voor deze zelfstudie staat het model dat het hoogst scoort op basis van de gekozen metrische gegevens Genormaliseerde wortel gemiddelde kwadraatfout bovenaan de lijst.
Terwijl u wacht tot alle experimentmodellen zijn voltooid, kunt u de Algoritmenaam van een volledig model selecteren om de prestatiedetails te bekijken.
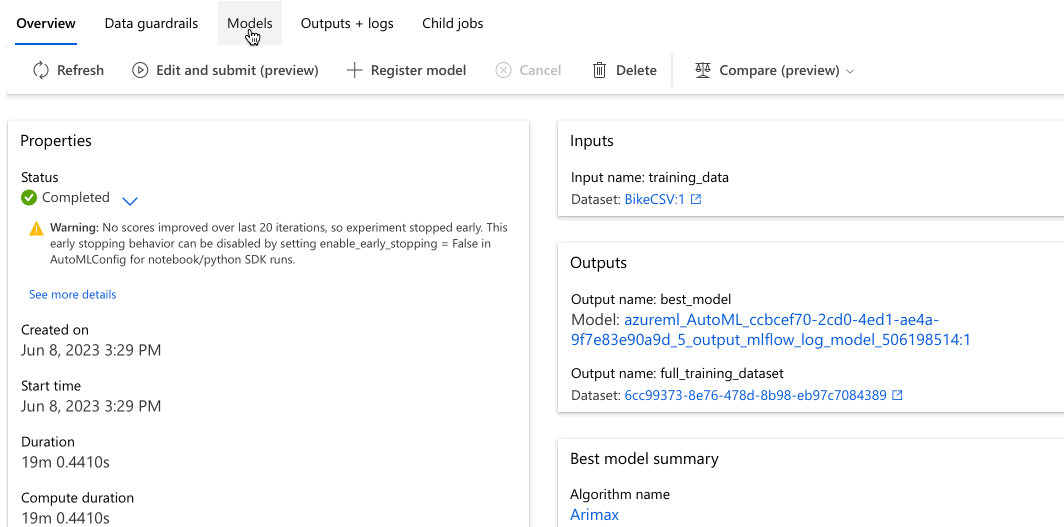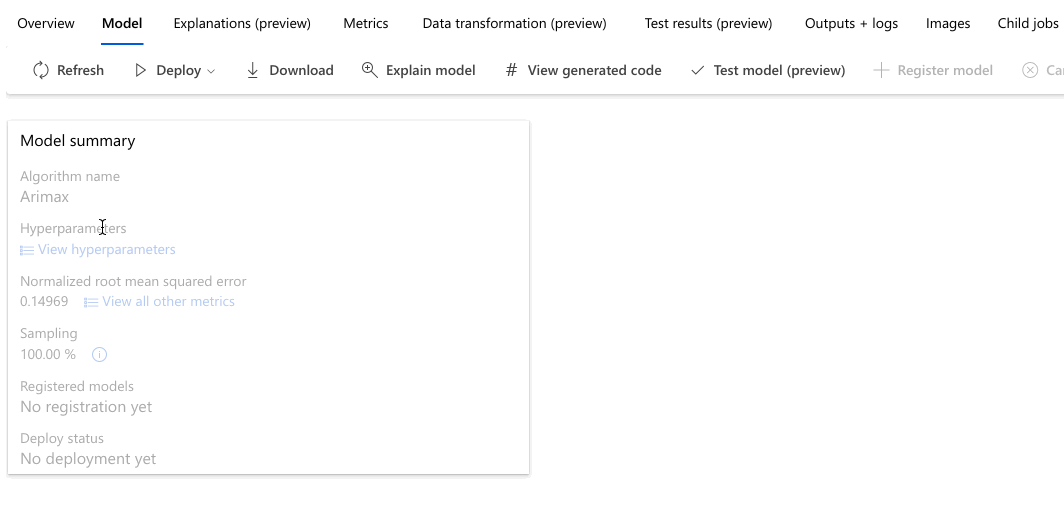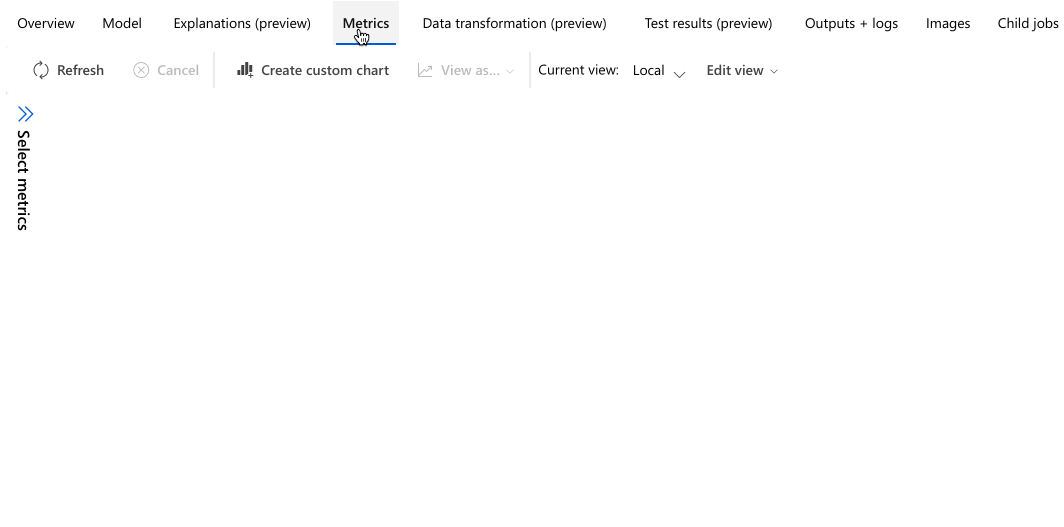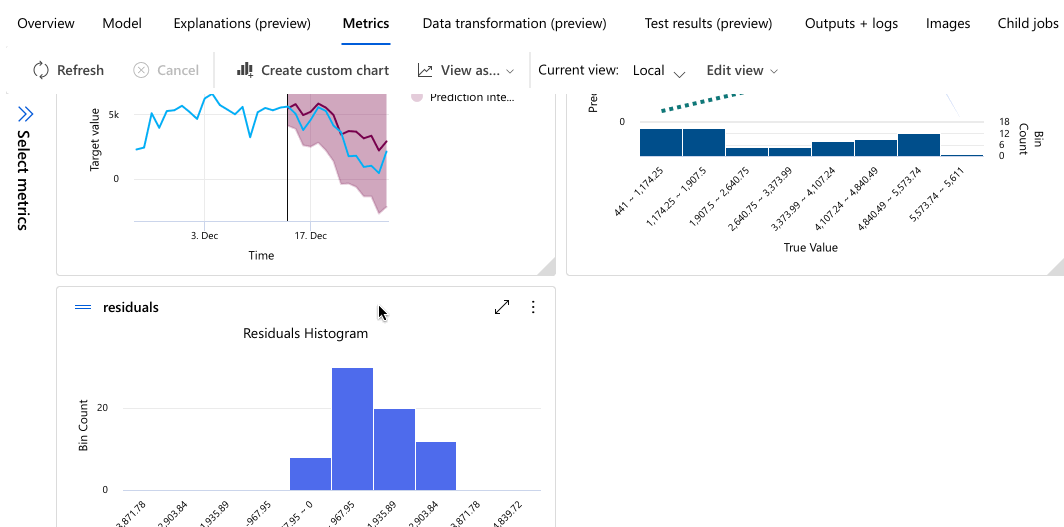
In het volgende voorbeeld wordt genavigeert om een model te selecteren in de lijst met modellen die door de taak zijn gemaakt. Vervolgens selecteert u het tabblad Overzicht en de tabbladen Metrische gegevens om de eigenschappen, metrische gegevens en prestatiegrafieken van het geselecteerde model weer te geven.
Model implementeren
Met geautomatiseerde machine learning in Azure Machine Learning Studio kunt u met enkele stappen het beste model implementeren als webservice. Implementatie is de integratie van het model zodat het nieuwe gegevens kan voorspellen en potentiële kansgebieden kan identificeren.
Voor dit experiment houdt het implementeren naar een webservice in dat het BikeShare-bedrijf nu een iteratieve en schaalbare weboplossing heeft voor het voorspellen van de vraag naar het huren van fietsen.
Zodra de taak is voltooid, gaat u terug naar de bovenliggende taakpagina door Taak 1 boven aan het scherm te selecteren.
In de sectie Beste modelsamenvatting , het beste model in de context van dit experiment, is geselecteerd op basis van de genormaliseerde gemiddelde kwadratische foutmetriek.
We implementeren dit model, maar houd er rekening mee dat implementatie ongeveer 20 minuten duurt. Het implementatieproces omvat verschillende stappen, waaronder het model registreren, resources genereren en ze configureren voor de webservice.
Selecteer het beste model om de modelspecifieke pagina te openen.
Selecteer de knop Implementeren in het gedeelte linksboven in het scherm.
Vul het deelvenster Een model implementeren als volgt in:
Veld Waarde Naam van implementatie Implementeren Bike share Beschrijving van implementatie implementatie van vraag naar bike share Rekentype Azure Compute Instance (ACI) selecteren Verificatie inschakelen Uitgeschakeld. Aangepaste implementatie-assets gebruiken Uitgeschakeld. Met Uitschakelen staat u toe dat het standaard stuurprogrammabestand (scorescript) en het omgevingsbestand automatisch worden gegenereerd. In dit voorbeeld gebruiken we de standaardwaarden in het menu Geavanceerd.
Selecteer Implementeren.
Bovenaan het taakscherm wordt een groen bericht weergegeven waarin staat dat de implementatie is gestart. De voortgang van de implementatie kan u vinden in het deelvenster Modeloverzicht onder Status implementen.
Zodra de implementatie is voltooid, hebt u een operationele webservice om voorspellingen te genereren.
Ga verder met de Volgende stappen voor meer informatie over het gebruik van uw nieuwe webservice en test uw voorspellingen met de ingebouwde ondersteuning voor Azure Machine Learning van Power BI.
Resources opschonen
Implementatiebestanden zijn groter dan gegevens- en experimentbestanden. Daarom kost het meer om ze op te slaan. Verwijder alleen de implementatiebestanden om de kosten voor uw account te beperken, of als u uw werkruimte en experimentbestanden wilt behouden. Zo niet, verwijder dan de volledige resourcegroep als u geen enkel bestand wilt gebruiken.
Het implementatie-exemplaar verwijderen
Verwijder alleen het implementatie-exemplaar van Azure Machine Learning indien u de resourcegroep en werkruimte wilt behouden voor andere zelfstudies en verkenning.
Ga naar de Azure Machine Learning Studio. Ga naar uw werkruimte en selecteer Eindpunten aan de linkerkant onder het deelvenster Assets.
Selecteer de implementatie die u wilt verwijderen en vervolgens Verwijderen.
Selecteer Doorgaan.
De resourcegroep verwijderen
Belangrijk
De resources die u hebt gemaakt, kunnen worden gebruikt als de vereisten voor andere Azure Machine Learning-zelfstudies en artikelen met procedures.
Als u niet van plan bent om een van de resources te gebruiken die u hebt gemaakt, verwijdert u deze zodat er geen kosten in rekening worden gebracht:
Voer in azure Portal in het zoekvak resourcegroepen in en selecteer deze in de resultaten.
Selecteer de resourcegroep die u hebt gemaakt uit de lijst.
Selecteer op de pagina Overzicht de optie Resourcegroep verwijderen.
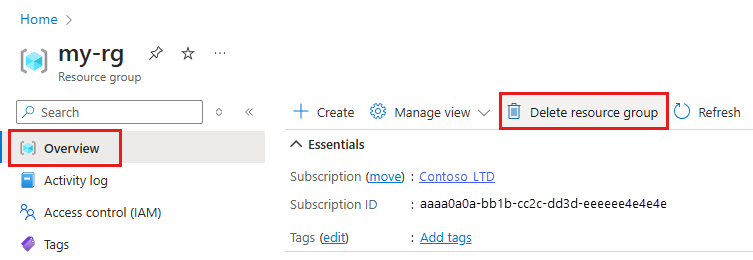
Voer de naam van de resourcegroup in. Selecteer daarna Verwijderen.
Volgende stappen
In deze zelfstudie hebt u gebruikgemaakt van geautomatiseerde ML in de Azure Machine Learning Studio voor het maken en implementeren van een tijdreeks-prognosemodel waarmee de vraag naar bikeshare-verhuur wordt voorspeld.
- Meer informatie over geautomatiseerde machine learning.
- Raadpleeg het artikel Geautomatiseerde machine learning-resultaten begrijpen voor meer informatie over metrische classificatiegegevens en grafieken.
- Voor meer informatie over veelgestelde vragen over prognoses.
Notitie
Deze bikeshare-gegevensset is gewijzigd voor deze zelfstudie. Deze gegevensset is beschikbaar gemaakt als onderdeel van een Kaggle-wedstrijd en was oorspronkelijk beschikbaar via Capital Bikeshare. Hij kan ook worden gevonden in de UCI Machine Learning-database.
Bron: Fanaee-T, Hadi en Aangemerkt, Joao, Event labeling combineren ensemble detectoren en achtergrondkennis, Progress in Artificial Intelligence (2013): pp. 1-15, Springer Berlin Heidelberg.