Parallelle taken gebruiken in pijplijnen
VAN TOEPASSING OP: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
In dit artikel wordt uitgelegd hoe u de CLI v2 en Python SDK v2 gebruikt om parallelle taken uit te voeren in Azure Machine Learning-pijplijnen. Parallelle taken versnellen de uitvoering van taken door herhaalde taken te distribueren op krachtige rekenclusters met meerdere knooppunten.
Machine learning-technici hebben altijd schaalvereisten voor hun trainings- of deductietaken. Wanneer een data scientist bijvoorbeeld één script biedt voor het trainen van een verkoopvoorspellingsmodel, moeten machine learning-technici deze trainingstaak toepassen op elk afzonderlijk gegevensarchief. Uitdagingen van dit uitschaalproces zijn lange uitvoeringstijden die vertragingen veroorzaken en onverwachte problemen waarvoor handmatige interventie nodig is om de taak actief te houden.
De kerntaak van Azure Machine Learning-parallellisatie is het splitsen van één seriële taak in minibatches en het verzenden van deze minibatches naar meerdere berekeningen die parallel moeten worden uitgevoerd. Parallelle taken verminderen de end-to-end uitvoeringstijd aanzienlijk en verwerken fouten ook automatisch. Overweeg om azure Machine Learning Parallel-taak te gebruiken om veel modellen op uw gepartitioneerde gegevens te trainen of om uw grootschalige batchdeductietaken te versnellen.
In een scenario waarin u bijvoorbeeld een objectdetectiemodel uitvoert op een grote set installatiekopieën, kunt u met parallelle Azure Machine Learning-taken uw installatiekopieën eenvoudig distribueren om aangepaste code parallel uit te voeren op een specifiek rekencluster. Parallellisatie kan de tijdskosten aanzienlijk verminderen. Parallelle Azure Machine Learning-taken kunnen uw proces ook vereenvoudigen en automatiseren om het efficiënter te maken.
Vereisten
- Een Azure Machine Learning-account en werkruimte hebben.
- Meer informatie over Azure Machine Learning-pijplijnen.
- Installeer de Azure CLI en de
mlextensie. Zie De CLI (v2) installeren, instellen en gebruiken voor meer informatie. Demlextensie installeert automatisch de eerste keer dat u eenaz mlopdracht uitvoert. - Meer informatie over het maken en uitvoeren van Azure Machine Learning-pijplijnen en -onderdelen met de CLI v2.
Een pijplijn maken en uitvoeren met een parallelle taakstap
Een parallelle Azure Machine Learning-taak kan alleen worden gebruikt als een stap in een pijplijntaak.
De volgende voorbeelden zijn afkomstig van een pijplijntaak uitvoeren met behulp van een parallelle taak in de pijplijn in de opslagplaats met Voorbeelden van Azure Machine Learning .
Voorbereiden op parallelle uitvoering
Voor deze parallelle taakstap is voorbereiding vereist. U hebt een invoerscript nodig waarmee de vooraf gedefinieerde functies worden geïmplementeerd. U moet ook kenmerken instellen in uw parallelle taakdefinitie die:
- Definieer en bind uw invoergegevens.
- Stel de methode voor gegevensdeling in.
- Configureer uw rekenresources.
- Roep het invoerscript aan.
In de volgende secties wordt beschreven hoe u de parallelle taak voorbereidt.
De instelling voor invoer en gegevensdeling declareren
Voor een parallelle taak moet één belangrijke invoer parallel worden gesplitst en verwerkt. De primaire indeling voor invoergegevens kan gegevens in tabelvorm of een lijst met bestanden zijn.
Verschillende gegevensindelingen hebben verschillende invoertypen, invoermodi en methoden voor gegevensdeling. In de volgende tabel worden de opties beschreven:
| Gegevensopmaak | Input type | Invoermodus | Methode voor gegevensverdeling |
|---|---|---|---|
| Bestandslijst | mltable of uri_folder |
ro_mount of download |
Op grootte (aantal bestanden) of op partitie |
| Gegevens in tabelvorm | mltable |
direct |
Op grootte (geschatte fysieke grootte) of op partitie |
Notitie
Als u tabellaire mltable als primaire invoergegevens gebruikt, moet u het volgende doen:
- Installeer de
mltablebibliotheek in uw omgeving, zoals in regel 9 van dit Conda-bestand. - Laat een MLTable-specificatiebestand onder het opgegeven pad vallen, waarbij de
transformations: - read_delimited:sectie is ingevuld. Zie Gegevensassets maken en beheren voor voorbeelden.
U kunt uw belangrijkste invoergegevens declareren met het input_data kenmerk in de YAML- of Python-taak en de gegevens binden met de gedefinieerde input parallelle taak met behulp van ${{inputs.<input name>}}. Vervolgens definieert u het kenmerk voor gegevensdeling voor uw primaire invoer, afhankelijk van uw methode voor gegevensverdeling.
| Methode voor gegevensverdeling | Naam van kenmerk | Type kenmerk | Voorbeeld van taak |
|---|---|---|---|
| Op grootte | mini_batch_size |
tekenreeks | Iris batch voorspelling |
| Op partitie | partition_keys |
lijst met tekenreeksen | Verkoopvoorspelling sinaasappelsap |
De rekenresources configureren voor parallelle uitvoering
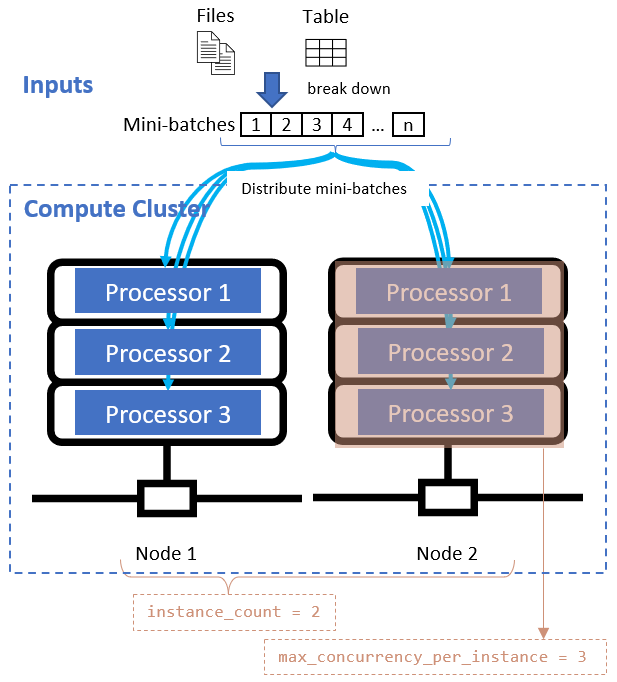
Nadat u het kenmerk voor gegevensdeling hebt gedefinieerd, configureert u de rekenresources voor uw parallelle uitvoering door de instance_count en max_concurrency_per_instance kenmerken in te stellen.
| Naam van kenmerk | Type | Description | Default value |
|---|---|---|---|
instance_count |
geheel getal | Het aantal knooppunten dat moet worden gebruikt voor de taak. | 1 |
max_concurrency_per_instance |
geheel getal | Het aantal processors op elk knooppunt. | Voor een GPU-rekenproces: 1. Voor een CPU-rekenproces: het aantal kernen. |
Deze kenmerken werken samen met het opgegeven rekencluster, zoals wordt weergegeven in het volgende diagram:
Het invoerscript aanroepen
Het invoerscript is één Python-bestand dat de volgende drie vooraf gedefinieerde functies met aangepaste code implementeert.
| Functienaam | Vereist | Omschrijving | Invoer | Retourneren |
|---|---|---|---|---|
Init() |
J | Algemene voorbereiding voordat u begint met het uitvoeren van minibatches. Gebruik deze functie bijvoorbeeld om het model in een globaal object te laden. | -- | -- |
Run(mini_batch) |
J | Implementeert hoofduitvoeringslogica voor minibatches. | mini_batch is pandas-dataframe als invoergegevens een tabellaire gegevens of bestandspadlijst zijn als invoergegevens een map zijn. |
Dataframe, lijst of tuple. |
Shutdown() |
N | Optionele functie om aangepaste opschoningen uit te voeren voordat de berekening naar de pool wordt geretourneerd. | -- | -- |
Belangrijk
Als u uitzonderingen wilt voorkomen bij het parseren van argumenten in Init() of Run(mini_batch) functies, gebruikt parse_known_args u in plaats van parse_args. Zie het iris_score voorbeeld voor een invoerscript met argumentparser.
Belangrijk
Voor de Run(mini_batch) functie moet een dataframe, lijst of tuple-item worden geretourneerd. De parallelle taak gebruikt het aantal dat retourneert om de succesitems onder die minibatch te meten. Het aantal minibatches moet gelijk zijn aan het aantal retourlijsten als alle items zijn verwerkt.
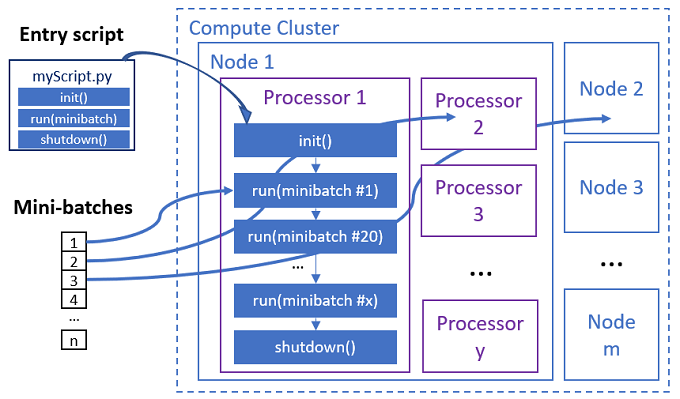
De parallelle taak voert de functies in elke processor uit, zoals wordt weergegeven in het volgende diagram.
Zie de volgende voorbeelden van invoerscripts:
- Afbeeldingsidentificatie voor een lijst met afbeeldingsbestanden
- Irisclassificatie voor een irisgegevens in tabelvorm
Als u het invoerscript wilt aanroepen, stelt u de volgende twee kenmerken in uw parallelle taakdefinitie in:
| Naam van kenmerk | Type | Omschrijving |
|---|---|---|
code |
tekenreeks | Lokaal pad naar de broncodemap die moet worden geüpload en gebruikt voor de taak. |
entry_script |
tekenreeks | Het Python-bestand dat de implementatie van vooraf gedefinieerde parallelle functies bevat. |
Voorbeeld van parallelle taakstap
De volgende parallelle taakstap declareert het invoertype, de modus en de gegevensverdelingsmethode, verbindt de invoer, configureert de berekening en roept het invoerscript aan.
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
Automatiseringsinstellingen overwegen
Parallelle Azure Machine Learning-taak bevat veel optionele instellingen waarmee de taak automatisch kan worden beheerd zonder handmatige tussenkomst. In de volgende tabel worden deze instellingen beschreven.
| Sleutel | Type | Description | Toegestane waarden | Default value | Instellen in kenmerk- of programmaargument |
|---|---|---|---|---|---|
mini_batch_error_threshold |
geheel getal | Aantal mislukte minibatches dat in deze parallelle taak moet worden genegeerd. Als het aantal mislukte minibatches hoger is dan deze drempelwaarde, wordt de parallelle taak gemarkeerd als mislukt. De minibatch is gemarkeerd als mislukt als: - Het aantal retourneert run() minder dan het aantal minibatches.- Uitzonderingen worden vastgelegd in aangepaste run() code. |
[-1, int.max] |
-1, wat betekent dat alle mislukte minibatches worden genegeerd |
Attribuut mini_batch_error_threshold |
mini_batch_max_retries |
geheel getal | Aantal nieuwe pogingen wanneer de minibatch mislukt of er een time-out optreedt. Als alle nieuwe pogingen mislukken, wordt de minibatch gemarkeerd als mislukt volgens de mini_batch_error_threshold berekening. |
[0, int.max] |
2 |
Attribuut retry_settings.max_retries |
mini_batch_timeout |
geheel getal | Time-out in seconden voor het uitvoeren van de aangepaste run() functie. Als de uitvoeringstijd hoger is dan deze drempelwaarde, wordt de minibatch afgebroken en gemarkeerd als mislukt om opnieuw proberen te activeren. |
(0, 259200] |
60 |
Attribuut retry_settings.timeout |
item_error_threshold |
geheel getal | De drempelwaarde voor mislukte items. Mislukte items worden geteld door het getal tussen invoer en retourneert van elke minibatch. Als de som van mislukte items hoger is dan deze drempelwaarde, wordt de parallelle taak gemarkeerd als mislukt. | [-1, int.max] |
-1, wat betekent dat alle fouten tijdens parallelle taak worden genegeerd |
Programmaargument--error_threshold |
allowed_failed_percent |
geheel getal | Vergelijkbaar met mini_batch_error_threshold, maar gebruikt het percentage mislukte minibatches in plaats van het aantal. |
[0, 100] |
100 |
Programmaargument--allowed_failed_percent |
overhead_timeout |
geheel getal | Time-out in seconden voor initialisatie van elke minibatch. Laad bijvoorbeeld minibatchgegevens en geef deze door aan de run() functie. |
(0, 259200] |
600 |
Programmaargument--task_overhead_timeout |
progress_update_timeout |
geheel getal | Time-out in seconden voor het bewaken van de voortgang van minibatchuitvoering. Als er geen voortgangsupdates worden ontvangen binnen deze time-outinstelling, wordt de parallelle taak gemarkeerd als mislukt. | (0, 259200] |
Dynamisch berekend door andere instellingen | Programmaargument--progress_update_timeout |
first_task_creation_timeout |
geheel getal | Time-out in seconden voor het controleren van de tijd tussen de start van de taak en de uitvoering van de eerste minibatch. | (0, 259200] |
600 |
Programmaargument--first_task_creation_timeout |
logging_level |
tekenreeks | Het niveau van logboeken dat moet worden gedumpt naar logboekbestanden van gebruikers. | INFO, WARNING of DEBUG |
INFO |
Attribuut logging_level |
append_row_to |
tekenreeks | Verzamel alle retourneert van elke uitvoering van de minibatch en voert deze uit in dit bestand. Kan verwijzen naar een van de uitvoer van de parallelle taak met behulp van de expressie ${{outputs.<output_name>}} |
Attribuut task.append_row_to |
||
copy_logs_to_parent |
tekenreeks | Booleaanse optie of u de voortgang, het overzicht en de logboeken van de taak naar de bovenliggende pijplijntaak wilt kopiëren. | True of False |
False |
Programmaargument--copy_logs_to_parent |
resource_monitor_interval |
geheel getal | Tijdsinterval in seconden om resourcegebruik van knooppunten (bijvoorbeeld cpu of geheugen) te dumpen om de map onder het pad logboeken/sys/perf te registreren. Opmerking: frequente dumpresourcelogboeken vertragen de uitvoeringssnelheid enigszins. Stel deze waarde in om het dumpen van resourcegebruik te 0 stoppen. |
[0, int.max] |
600 |
Programmaargument--resource_monitor_interval |
Met de volgende voorbeeldcode worden deze instellingen bijgewerkt:
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
program_arguments: >-
--model ${{inputs.score_model}}
--error_threshold 5
--allowed_failed_percent 30
--task_overhead_timeout 1200
--progress_update_timeout 600
--first_task_creation_timeout 600
--copy_logs_to_parent True
--resource_monitor_interva 20
append_row_to: ${{outputs.job_output_file}}
De pijplijn met parallelle taakstap maken
In het volgende voorbeeld ziet u de volledige pijplijntaak met de parallelle taakstap inline:
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: iris-batch-prediction-using-parallel
description: The hello world pipeline job with inline parallel job
tags:
tag: tagvalue
owner: sdkteam
settings:
default_compute: azureml:cpu-cluster
jobs:
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
program_arguments: >-
--model ${{inputs.score_model}}
--error_threshold 5
--allowed_failed_percent 30
--task_overhead_timeout 1200
--progress_update_timeout 600
--first_task_creation_timeout 600
--copy_logs_to_parent True
--resource_monitor_interva 20
append_row_to: ${{outputs.job_output_file}}
De pijplijntaak verzenden
Verzend uw pijplijntaak met parallelle stap met behulp van de az ml job create CLI-opdracht:
az ml job create --file pipeline.yml
Parallelle stap controleren in de gebruikersinterface van Studio
Nadat u een pijplijntaak hebt verzonden, krijgt u met de SDK- of CLI-widget een web-URL-koppeling naar de pijplijngrafiek in de Azure Machine Learning-studio-gebruikersinterface.
Als u de resultaten van parallelle taken wilt weergeven, dubbelklikt u op de parallelle stap in de pijplijngrafiek, selecteert u het tabblad Instellingen in het detailvenster, vouwt u Instellingen voor uitvoeren uit en vouwt u vervolgens de sectie Parallel uit.

Als u fouten in parallelle taken wilt opsporen, selecteert u het tabblad Uitvoer en logboeken , vouwt u de map met logboeken uit en controleert u job_result.txt om te begrijpen waarom de parallelle taak is mislukt. Zie readme.txt in dezelfde map voor informatie over de structuur van logboekregistratie van parallelle taken.
