Gegevens voorbereiden voor Computer Vision-taken met geautomatiseerde machine learning
VAN TOEPASSING OP: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Belangrijk
Ondersteuning voor het trainen van Computer Vision-modellen met geautomatiseerde ML in Azure Machine Learning is een experimentele openbare preview-functie. Misschien worden bepaalde functies niet ondersteund of zijn de mogelijkheden ervan beperkt. Zie Aanvullende gebruiksvoorwaarden voor Microsoft Azure-previews voor meer informatie.
In dit artikel leert u hoe u afbeeldingsgegevens voorbereidt voor het trainen van Computer Vision-modellen met geautomatiseerde machine learning in Azure Machine Learning. Als u modellen voor Computer Vision-taken met geautomatiseerde machine learning wilt genereren, moet u gelabelde afbeeldingsgegevens als invoer voor modeltraining in de vorm van een MLTable.
U kunt een MLTable van gelabelde trainingsgegevens maken in JSONL-indeling. Als uw gelabelde trainingsgegevens een andere indeling hebben, zoals Pascal Visual Object Classes (VOC) of COCO, kunt u een conversiescript gebruiken om het te converteren naar JSONL en vervolgens een MLTable. U kunt ook het hulpprogramma voor gegevenslabels van Azure Machine Learning gebruiken om afbeeldingen handmatig te labelen. Exporteer vervolgens de gelabelde gegevens die u wilt gebruiken voor het trainen van uw AutoML-model.
Vereisten
- Maak kennis met de geaccepteerde schema's voor JSONL-bestanden voor AutoML Computer Vision-experimenten.
Gelabelde gegevens ophalen
Als u Computer Vision-modellen wilt trainen met AutoML, moet u gelabelde trainingsgegevens ophalen. De afbeeldingen moeten worden geüpload naar de cloud. Labelaantekeningen moeten de JSONL-indeling hebben. U kunt het hulpprogramma Azure Machine Learning-gegevenslabels gebruiken om uw gegevens te labelen of u kunt beginnen met vooraf gelabelde afbeeldingsgegevens.
Azure Machine Learning-hulpprogramma voor gegevenslabels gebruiken om uw trainingsgegevens te labelen
Als u geen vooraf gelabelde gegevens hebt, kunt u het hulpprogramma voor gegevenslabels van Azure Machine Learning gebruiken om afbeeldingen handmatig te labelen. Met dit hulpprogramma worden automatisch de gegevens gegenereerd die vereist zijn voor training in de geaccepteerde indeling. Zie Een afbeeldingslabelproject instellen voor meer informatie.
Het hulpprogramma helpt bij het maken, beheren en bewaken van taken voor het labelen van gegevens voor:
- Afbeeldingsclassificatie (meerdere klassen en meerdere labels)
- Objectdetectie (begrenzingsvak)
- Exemplaarsegmentatie (veelhoek)
Als u al gelabelde gegevens hebt om te gebruiken, exporteert u die gelabelde gegevens als een Azure Machine Learning-gegevensset en opent u de gegevensset op het tabblad Gegevenssets in Azure Machine Learning-studio. U kunt deze geëxporteerde gegevensset doorgeven als invoer met behulp van azureml:<tabulardataset_name>:<version> de indeling. Zie De labels exporteren voor meer informatie.
Hier volgt een voorbeeld van het doorgeven van bestaande gegevenssets als invoer voor het trainen van Computer Vision-modellen.
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidige)
training_data:
path: azureml:odFridgeObjectsTrainingDataset:1
type: mltable
mode: direct
Vooraf gelabelde trainingsgegevens van lokale computer gebruiken
Als u gegevens hebt gelabeld die u wilt gebruiken om uw model te trainen, uploadt u de afbeeldingen naar Azure. U kunt uw installatiekopieën uploaden naar de standaard Azure Blob Storage van uw Azure Machine Learning-werkruimte. Registreer deze als een gegevensasset. Zie Gegevensassets maken en beheren voor meer informatie.
Met het volgende script worden de afbeeldingsgegevens op uw lokale computer geüpload op het pad ./data/odFridgeObjects naar het gegevensarchief in Azure Blob Storage. Vervolgens wordt er een nieuwe gegevensasset gemaakt met de naam fridge-items-images-object-detection in uw Azure Machine Learning-werkruimte.
Als er al een gegevensasset bestaat met de naam fridge-items-images-object-detection in uw Azure Machine Learning-werkruimte, werkt de code het versienummer van de gegevensasset bij en verwijst deze naar de nieuwe locatie waar de afbeeldingsgegevens zijn geüpload.
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidige)
Maak een .yml-bestand met de volgende configuratie.
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
name: fridge-items-images-object-detection
description: Fridge-items images Object detection
path: ./data/odFridgeObjects
type: uri_folder
Als u de afbeeldingen wilt uploaden als een gegevensasset, voert u de volgende CLI v2-opdracht uit met het pad naar uw .yml-bestand , werkruimtenaam, resourcegroep en abonnements-id.
az ml data create -f [PATH_TO_YML_FILE] --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Als u al uw gegevens in een bestaand gegevensarchief hebt, kunt u er een gegevensasset van maken. Geef het pad op naar de gegevens in het gegevensarchief in plaats van het pad van uw lokale computer. Werk de voorgaande code bij met het volgende codefragment.
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidige)
Maak een .yml-bestand met de volgende configuratie.
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
name: fridge-items-images-object-detection
description: Fridge-items images Object detection
path: azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/<path_to_image_data_folder>
type: uri_folder
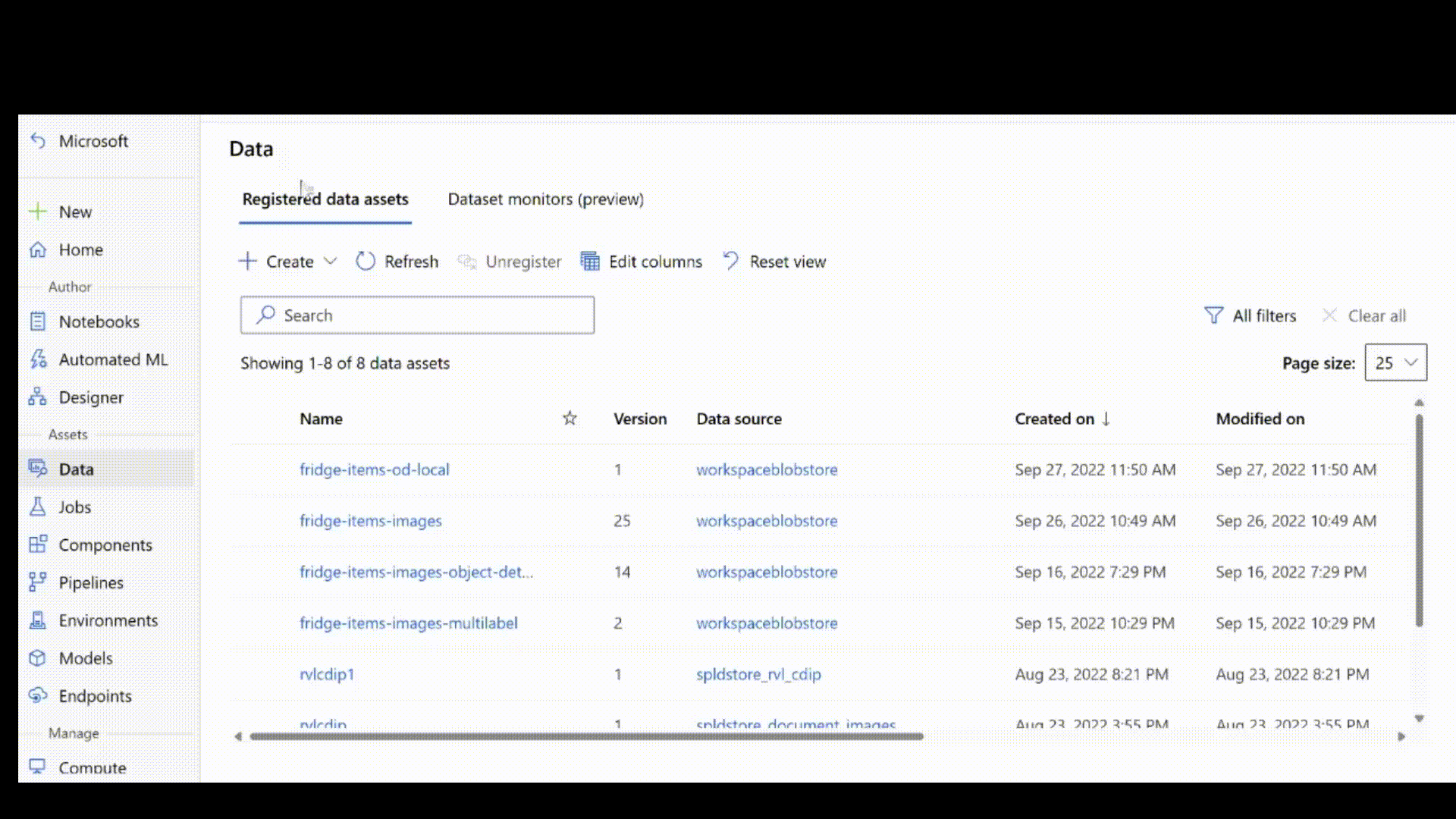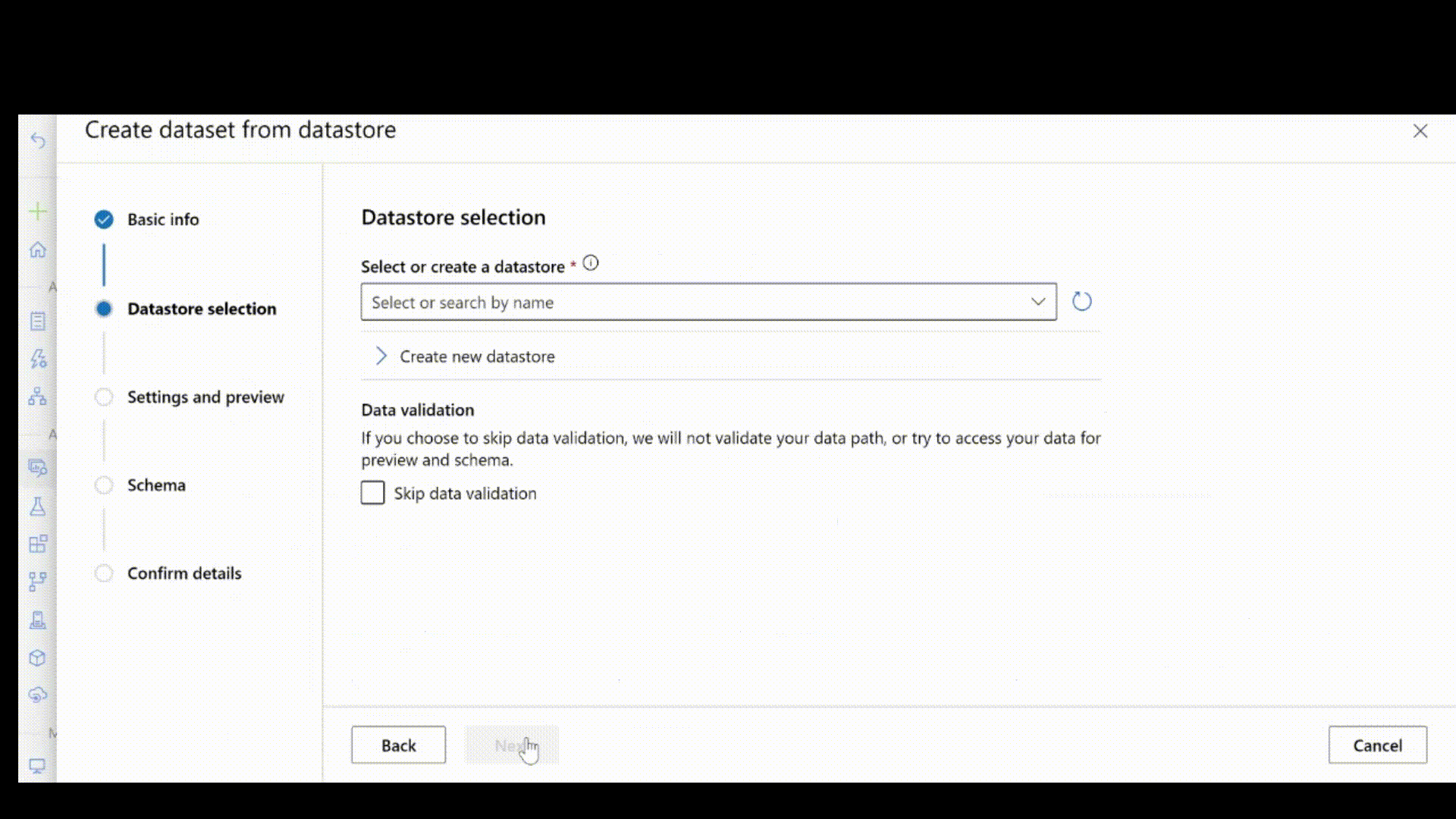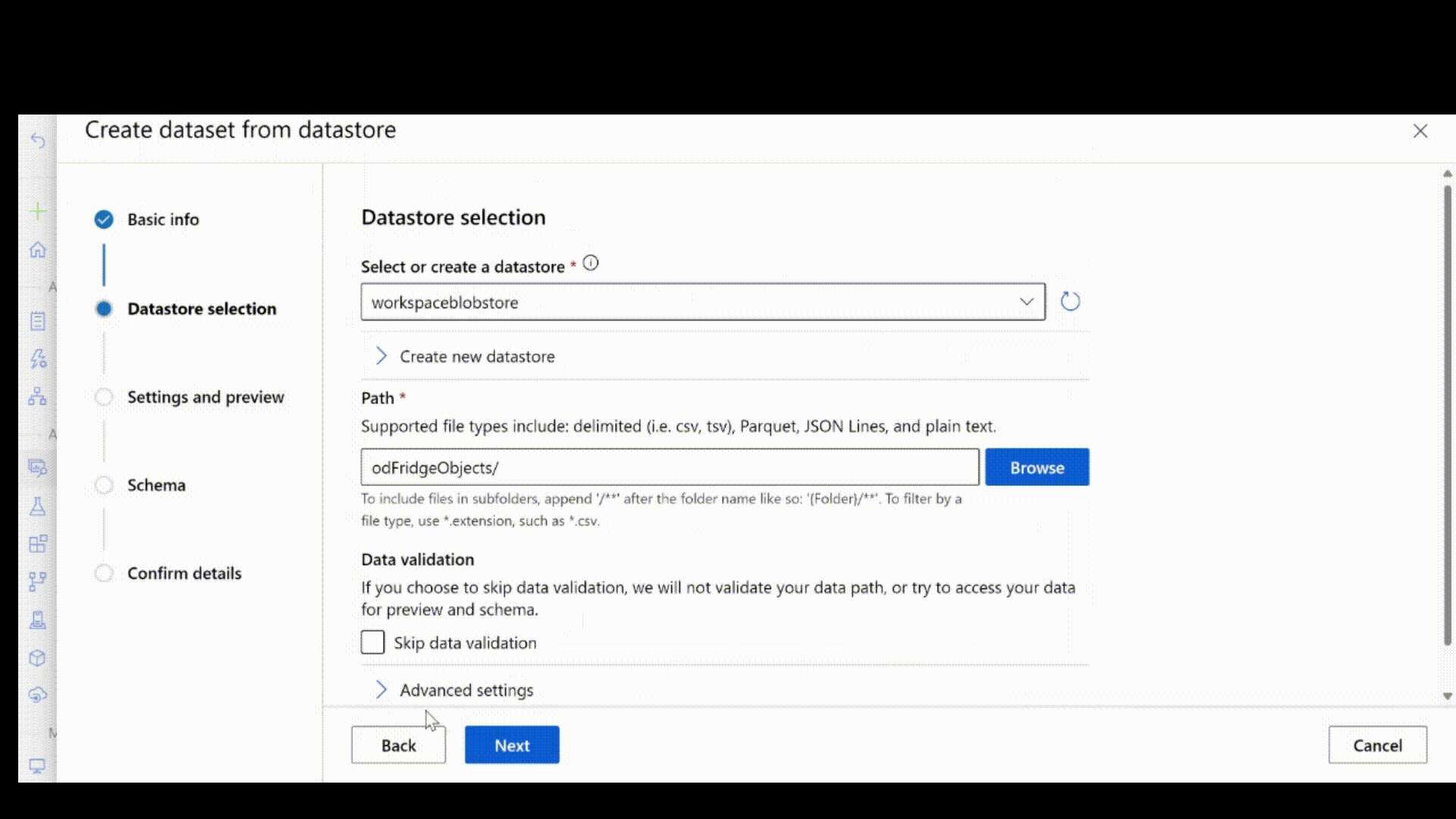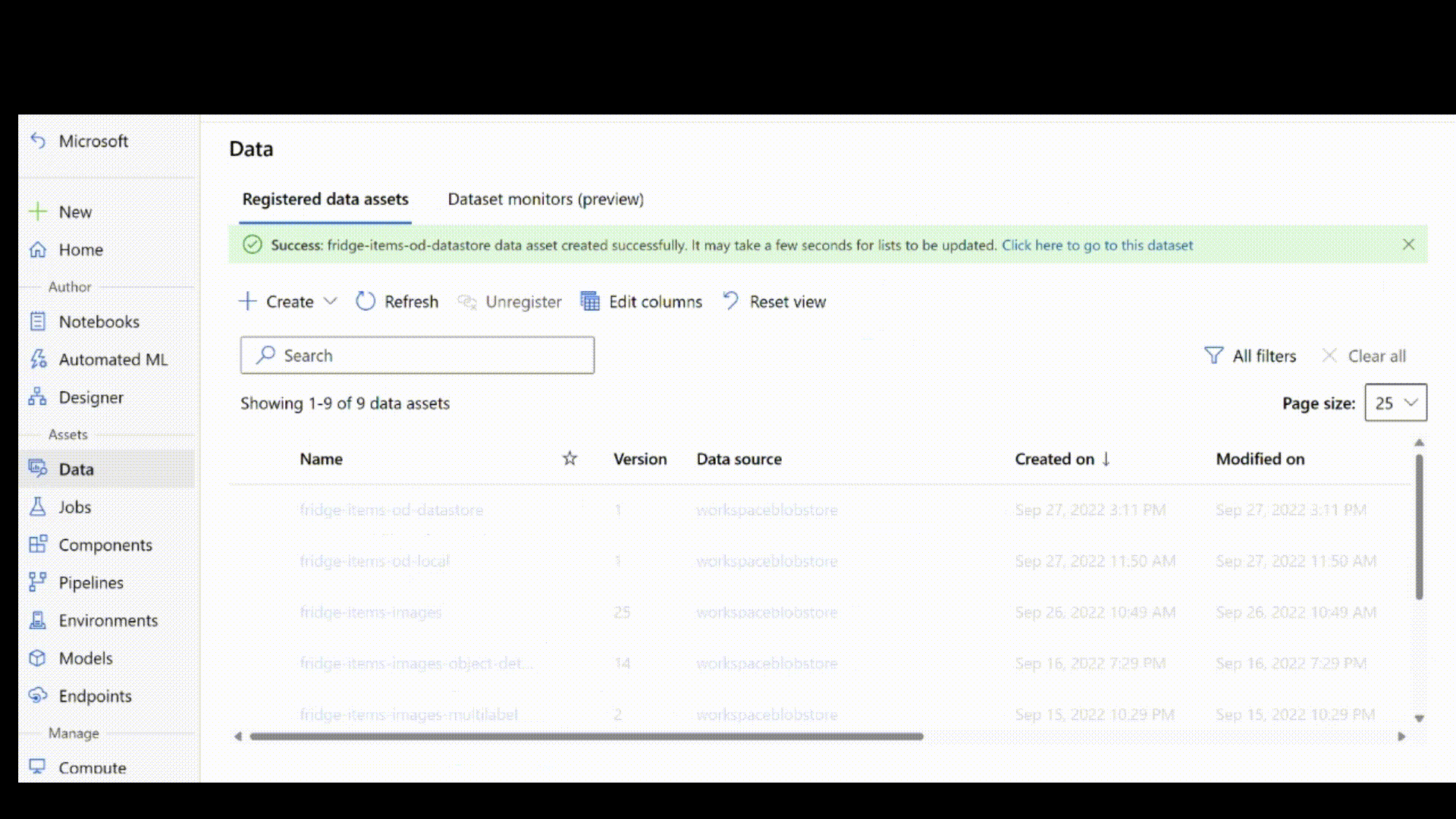
Haal vervolgens de labelaantekeningen op in JSONL-indeling. Het schema van gelabelde gegevens is afhankelijk van de computer vision-taak die u bij de hand hebt. Zie Gegevensschema's voor het trainen van Computer Vision-modellen met geautomatiseerde machine learning voor meer informatie over het vereiste JSONL-schema voor elk taaktype.
Als uw trainingsgegevens een andere indeling hebben, zoals pascal VOC of COCO, kunnen helperscripts de gegevens converteren naar JSONL. De scripts zijn beschikbaar in notebookvoorbeelden.
Nadat u het .jsonl-bestand hebt gemaakt, kunt u het registreren als een gegevensasset met behulp van de gebruikersinterface. Zorg ervoor dat u typt stream in schemasectie, zoals wordt weergegeven in deze animatie.
Vooraf gelabelde trainingsgegevens uit Azure Blob Storage gebruiken
Als uw gelabelde trainingsgegevens aanwezig zijn in een container in Azure Blob Storage, kunt u deze rechtstreeks openen. Maak een gegevensarchief naar die container. Zie Gegevensassets maken en beheren voor meer informatie.
MLTable maken
Nadat uw gelabelde gegevens de JSONL-indeling hebben, kunt u deze gebruiken om te maken MLTable zoals wordt weergegeven in dit yaml-fragment. MLtable verpakt uw gegevens in een verbruiksobject voor training.
paths:
- file: ./train_annotations.jsonl
transformations:
- read_json_lines:
encoding: utf8
invalid_lines: error
include_path_column: false
- convert_column_types:
- columns: image_url
column_type: stream_info
Vervolgens kunt u de MLTable gegevensinvoer voor uw AutoML-trainingstaak doorgeven. Zie AutoML instellen voor het trainen van Computer Vision-modellen voor meer informatie.