Mistral-modellen implementeren met Azure Machine Learning-studio
In dit artikel leert u hoe u Azure Machine Learning-studio kunt gebruiken om de Mistral-serie van modellen te implementeren als serverloze API's met facturering op basis van betalen per gebruik- token.
Mistral AI biedt twee categorieën modellen in Azure Machine Learning-studio. Deze modellen zijn beschikbaar in de modelcatalogus.
- Premium modellen: Mistral Large (2402), Mistral Large (2407), Mistral Large (2411), Mistral Small en Ministral-3B.
- Open modellen: Mistral Nemo, Mixtral-8x7B-Instruct-v01, Mixtral-8x7B-v01, Mistral-7B-Instruct-v01 en Mistral-7B-v01.
Alle premium-modellen en Mistral Nemo (een open model) kunnen worden geïmplementeerd als serverloze API's met betalen per gebruik-token gebaseerde facturering. De andere geopende modellen kunnen worden geïmplementeerd voor beheerde berekeningen in uw eigen Azure-abonnement.
U kunt door de Mistral-familie van modellen in de modelcatalogus bladeren door te filteren op de Mistral-verzameling.
Mistrale familie van modellen
Mistral Large-modellen zijn Mistral AI's meest geavanceerde Large Language Models (LLM). Ze kunnen worden gebruikt voor elke taaltaak, dankzij hun geavanceerde redenering, kennis en coderingsmogelijkheden. Er zijn verschillende Mistral Large-modelvarianten beschikbaar:
- Mistral Large (2402), ook afgekort als Mistral Large
- Mistral large (2407)
- Mistral large (2411)
Kenmerken van Mistral Large (2402), ook afgekort als Mistral Large, zijn:
- Gespecialiseerd in RAG. Cruciale informatie gaat niet verloren in het midden van lange contextvensters (maximaal 32 K-tokens).
- Sterk in coderen. Code genereren, beoordelen en opmerkingen. Ondersteunt alle reguliere coderingstalen.
- Multi-lingual per ontwerp. Beste prestaties in het Frans, Duits, Spaans, Italiaans en Engels. Tientallen andere talen worden ondersteund.
- Verantwoordelijke AI-compatibel. Efficiënte kaders gebakken in het model en extra veiligheidslaag met de optie safe_mode.
Kenmerken van Mistral Large (2407) zijn:
- Multi-lingual per ontwerp. Ondersteunt tientallen talen, waaronder Engels, Frans, Duits, Spaans en Italiaans.
- Bekwaam in coderen. Getraind op meer dan 80 programmeertalen, waaronder Python, Java, C, C++, JavaScript en Bash. Ook getraind in specifiekere talen, zoals Swift en Fortran.
- Agentgericht. Beschikt over agentische mogelijkheden met systeemeigen functie-aanroepen en JSON-uitvoer.
- Geavanceerd in redenering. Demonstreert geavanceerde wiskundige en redeneringsmogelijkheden.
Kenmerken van Mistral Large (2411) zijn hetzelfde als Mistral Large (2407) met de volgende extra kenmerken:
- Systeemprompts worden vóór elk gesprek geïnjecteerd.
- Betere prestaties voor lange inhoud.
- Verbeterde mogelijkheden voor het aanroepen van functies.
Belangrijk
Deze functie is momenteel beschikbaar als openbare preview-versie. Deze preview-versie wordt geleverd zonder een service level agreement en we raden deze niet aan voor productieworkloads. Misschien worden bepaalde functies niet ondersteund of zijn de mogelijkheden ervan beperkt.
Zie Aanvullende gebruiksvoorwaarden voor Microsoft Azure-previews voor meer informatie.
Mistral-serie van modellen implementeren als een serverloze API
Bepaalde modellen in de modelcatalogus kunnen worden geïmplementeerd als een serverloze API met betalen per gebruik-facturering. Dit soort implementatie biedt een manier om modellen als API te gebruiken zonder deze te hosten in uw abonnement, terwijl de bedrijfsbeveiliging en -naleving die organisaties nodig hebben, behouden blijven. Voor deze implementatieoptie is geen quotum van uw abonnement vereist.
Mistral Large, Mistral Large (2407), Mistral Large (2411), Mistral Small en Mistral Nemo kunnen worden geïmplementeerd als een serverloze API met betalen per gebruik-facturering en worden aangeboden door Mistral AI via de Microsoft Azure Marketplace. Mistral AI kan de gebruiksvoorwaarden en prijzen van deze modellen wijzigen of bijwerken.
Vereisten
Een Azure-abonnement met een geldige betalingswijze. Gratis of proefversie van Azure-abonnementen werkt niet. Als u geen Azure-abonnement hebt, maakt u eerst een betaald Azure-account .
Een Azure Machine Learning-werkruimte. Als u geen werkruimte hebt, gebruikt u de stappen in de quickstart: artikel Werkruimtebronnen maken om er een te maken. Het serverloze API-modelimplementatieaanbod voor in aanmerking komende modellen in de Mistral-serie is alleen beschikbaar in werkruimten die in deze regio's zijn gemaakt:
- VS - oost
- VS - oost 2
- VS - noord-centraal
- VS - zuid-centraal
- VS - west
- US - west 3
- Zweden - centraal
Voor een lijst met regio's die beschikbaar zijn voor elk van de modellen die serverloze API-eindpuntimplementaties ondersteunen, raadpleegt u De beschikbaarheid van regio's voor modellen in serverloze API-eindpunten
Op rollen gebaseerd toegangsbeheer van Azure (Azure RBAC) wordt gebruikt om toegang te verlenen tot bewerkingen in Azure Machine Learning. Als u de stappen in dit artikel wilt uitvoeren, moet aan uw gebruikersaccount de Azure AI Developer-rol voor de resourcegroep zijn toegewezen. Zie Beheer toegang tot een Azure Machine Learning-werkruimte voor meer informatie over machtigingen.
Een nieuwe implementatie maken
In de volgende stappen wordt de implementatie van Mistral Large gedemonstreerd, maar u kunt dezelfde stappen gebruiken om Mistral Nemo of een van de premium Mistral-modellen te implementeren door de modelnaam te vervangen.
Een implementatie maken:
Ga naar Azure Machine Learning-studio.
Selecteer de werkruimte waarin u uw model wilt implementeren. Als u de aanbieding voor serverloze API-modelimplementatie wilt gebruiken, moet uw werkruimte behoren tot een van de regio's die worden vermeld in de vereisten.
Kies het model dat u wilt implementeren, bijvoorbeeld het Mistral Large-model, in de modelcatalogus.
U kunt ook de implementatie initiëren door naar uw werkruimte te gaan en serverloze eindpunten voor eindpunten>>te selecteren.
Selecteer Implementeren op de overzichtspagina van het model in de modelcatalogus om een serverloos API-implementatievenster voor het model te openen.
Schakel het selectievakje in om het Aankoopbeleid van Microsoft te bevestigen.
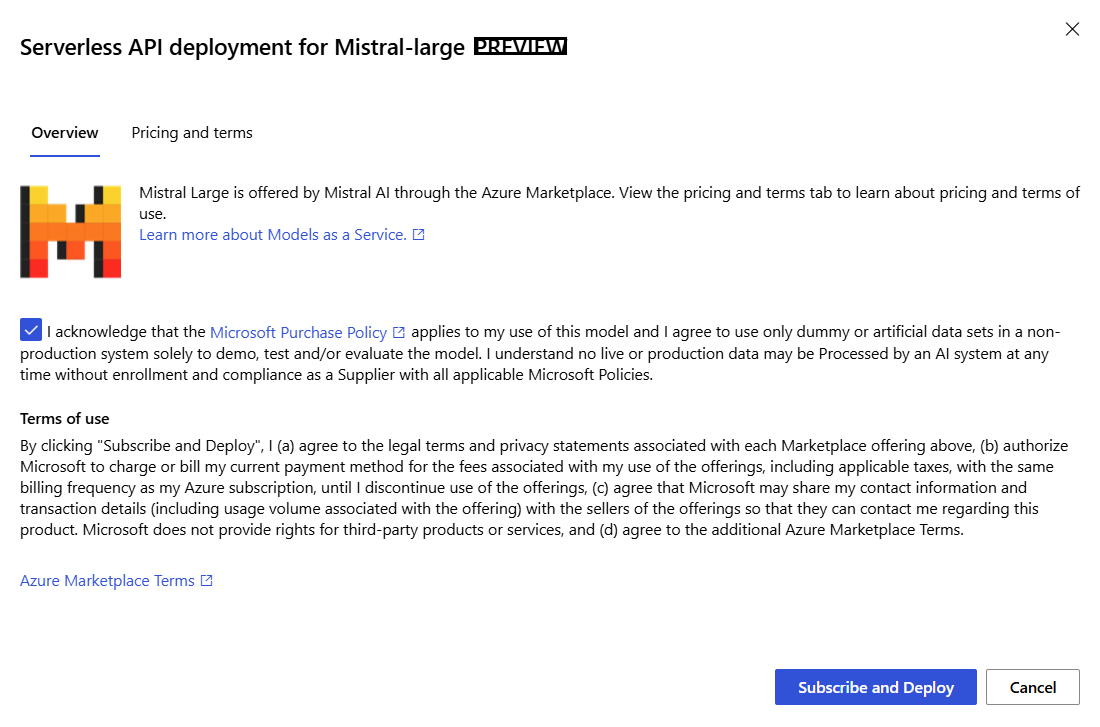
Selecteer in de implementatiewizard de koppeling naar azure Marketplace-voorwaarden voor meer informatie over de gebruiksvoorwaarden.
U kunt ook het tabblad Prijzen en voorwaarden selecteren voor meer informatie over prijzen voor het geselecteerde model.
Als dit de eerste keer is dat u het model in de werkruimte implementeert, moet u zich abonneren op uw werkruimte voor het specifieke aanbod (bijvoorbeeld Mistral Large). Voor deze stap is vereist dat uw account beschikt over de rolmachtigingen voor Azure AI Developer voor de resourcegroep, zoals vermeld in de vereisten. Elke werkruimte heeft een eigen abonnement op de specifieke Azure Marketplace-aanbieding, waarmee u uitgaven kunt beheren en bewaken. Selecteer Abonneren en implementeren. Op dit moment kunt u slechts één implementatie voor elk model in een werkruimte hebben.
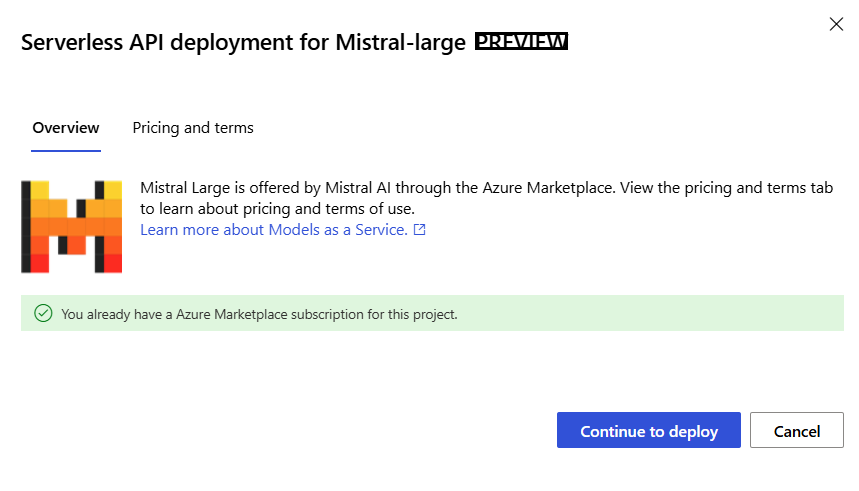
Nadat u zich hebt geabonneerd op de werkruimte voor het specifieke Azure Marketplace-aanbod, hoeven volgende implementaties van dezelfde aanbieding in dezelfde werkruimte zich niet opnieuw te abonneren. Als dit scenario op u van toepassing is, ziet u de optie Doorgaan om deze te selecteren.
Geef de implementatie een naam. Deze naam maakt deel uit van de URL van de implementatie-API. Deze URL moet uniek zijn in elke Azure-regio.
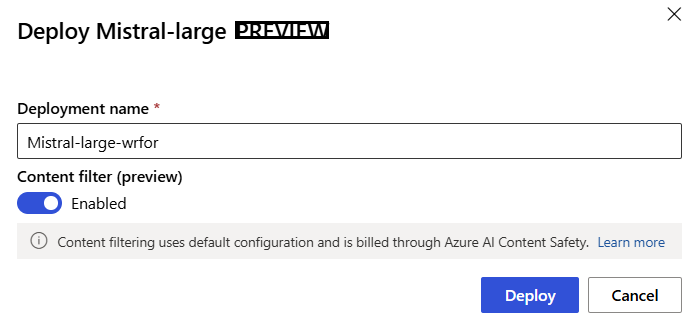
Selecteer Implementeren. Wacht totdat de implementatie is voltooid en u wordt omgeleid naar de pagina met serverloze eindpunten.
Selecteer het eindpunt om de pagina Details te openen.
Selecteer het tabblad Testen om te beginnen met interactie met het model.
U kunt altijd de details, URL en toegangssleutels van het eindpunt vinden door naar serverloze eindpunten van werkruimte-eindpunten>> te navigeren.



Voor meer informatie over facturering voor Mistral-modellen die zijn geïmplementeerd als een serverloze API met facturering op basis van betalen per gebruik-token, raadpleegt u Kosten- en quotumoverwegingen voor mistrale modellen die als een service zijn geïmplementeerd.
De Mistral-serie van modellen als een service gebruiken
U kunt Mistral-modellen gebruiken met behulp van de chat-API.
- Selecteer serverloze eindpunten> in de werkruimte.
- Zoek en selecteer de implementatie die u hebt gemaakt.
- Kopieer de doel-URL en de sleuteltokenwaarden.
- Maak een API-aanvraag met behulp van de Azure AI-modeldeductie-API op de route
/chat/completionsen de systeemeigen Mistral Chat-API op/v1/chat/completions.
Zie de naslagsectie voor meer informatie over het gebruik van de API's.
Naslaginformatie voor de Mistral-serie van modellen die zijn geïmplementeerd als een service
Mistral-modellen accepteren zowel de Azure AI-modeldeductie-API op de route /chat/completions als de systeemeigen Mistral Chat-API op /v1/chat/completions.
Azure AI-modelinferentie-API
Het API-schema voor Azure AI-modeldeductie vindt u in de naslagwerken voor chatvoltooiingen en er kan een OpenAPI-specificatie worden verkregen van het eindpunt zelf.
Mistral Chat-API
Gebruik de methode POST om de aanvraag naar de /v1/chat/completions route te verzenden:
Aanvragen
POST /v1/chat/completions HTTP/1.1
Host: <DEPLOYMENT_URI>
Authorization: Bearer <TOKEN>
Content-type: application/json
Aanvraagschema
Payload is een tekenreeks met JSON-indeling die de volgende parameters bevat:
| Sleutel | Type | Default | Beschrijving |
|---|---|---|---|
messages |
string |
Geen standaardwaarde. Deze waarde moet worden opgegeven. | Het bericht of de geschiedenis van berichten die moeten worden gebruikt om het model te vragen. |
stream |
boolean |
False |
Met streaming kunnen de gegenereerde tokens worden verzonden als gebeurtenissen die alleen door de server worden verzonden wanneer ze beschikbaar zijn. |
max_tokens |
integer |
8192 |
Het maximum aantal tokens dat moet worden gegenereerd tijdens de voltooiing. Het tokenaantal van uw prompt plus max_tokens kan de contextlengte van het model niet overschrijden. |
top_p |
float |
1 |
Een alternatief voor steekproeven met temperatuur, zogenaamde kernsampling, waarbij het model rekening houdt met de resultaten van de tokens met top_p waarschijnlijkheidsmassa. 0,1 betekent dus dat alleen de tokens die de top 10% kansdichtheid omvatten, worden beschouwd. Over het algemeen raden we aan om te top_p wijzigen of temperature, maar niet beide. |
temperature |
float |
1 |
De te gebruiken steekproeftemperatuur tussen 0 en 2. Hogere waarden betekenen de modelvoorbeelden breder de distributie van tokens. Nul betekent hebzuchtige steekproeven. We raden u aan deze parameter of top_p, maar niet beide te wijzigen. |
ignore_eos |
boolean |
False |
Of u het EOS-token moet negeren en tokens wilt blijven genereren nadat het EOS-token is gegenereerd. |
safe_prompt |
boolean |
False |
Of er een veiligheidsprompt moet worden geïnjecteerd voor alle gesprekken. |
Het messages object heeft de volgende velden:
| Sleutel | Type | Weergegeven als |
|---|---|---|
content |
string |
De inhoud van het bericht. Inhoud is vereist voor alle berichten. |
role |
string |
De rol van de auteur van het bericht. Een van system, userof assistant. |
Aanvraagvoorbeeld
Tekst
{
"messages":
[
{
"role": "system",
"content": "You are a helpful assistant that translates English to Italian."
},
{
"role": "user",
"content": "Translate the following sentence from English to Italian: I love programming."
}
],
"temperature": 0.8,
"max_tokens": 512,
}
Antwoordschema
De nettolading van het antwoord is een woordenlijst met de volgende velden.
| Sleutel | Type | Description |
|---|---|---|
id |
string |
Een unieke id voor de voltooiing. |
choices |
array |
De lijst met voltooiingskeuzen die het model heeft gegenereerd voor de invoerberichten. |
created |
integer |
De Unix-tijdstempel (in seconden) van het moment waarop de voltooiing is gemaakt. |
model |
string |
De model_id gebruikt voor voltooiing. |
object |
string |
Het objecttype, dat altijd chat.completionis. |
usage |
object |
Gebruiksstatistieken voor de voltooiingsaanvraag. |
Tip
In de streamingmodus is voor elk deel van het antwoord finish_reason altijd null, behalve van de laatste die wordt beëindigd door een nettolading [DONE]. In elk choices object wordt de sleutel voor messages gewijzigd door delta.
Het choices object is een woordenlijst met de volgende velden.
| Sleutel | Type | Description |
|---|---|---|
index |
integer |
Keuzeindex. Wanneer best_of> 1, is de index in deze matrix mogelijk niet in orde en is dit 0 mogelijk niet.n-1 |
messages of delta |
string |
Voltooiing van chat resulteert in messages object. Wanneer de streamingmodus wordt gebruikt, delta wordt de sleutel gebruikt. |
finish_reason |
string |
De reden waarom het model geen tokens meer genereert: - stop: het model raakt een natuurlijk stoppunt of een meegeleverde stopreeks. - length: als het maximum aantal tokens is bereikt. - content_filter: Wanneer RAI moderatie en CMP dwingt - content_filter_error: een fout tijdens het toezicht en kon geen beslissing nemen over het antwoord - null: API-antwoord wordt nog steeds uitgevoerd of onvolledig. |
logprobs |
object |
De logboekkans van de gegenereerde tokens in de uitvoertekst. |
Het usage object is een woordenlijst met de volgende velden.
| Sleutel | Type | Weergegeven als |
|---|---|---|
prompt_tokens |
integer |
Aantal tokens in de prompt. |
completion_tokens |
integer |
Het aantal tokens dat is gegenereerd tijdens de voltooiing. |
total_tokens |
integer |
Totaal aantal tokens. |
Het logprobs object is een woordenlijst met de volgende velden:
| Sleutel | Type | Weergegeven als |
|---|---|---|
text_offsets |
array van integers |
De positie of index van elk token in de voltooiingsuitvoer. |
token_logprobs |
array van float |
Geselecteerd logprobs uit woordenlijst in top_logprobs matrix. |
tokens |
array van string |
Geselecteerde tokens. |
top_logprobs |
array van dictionary |
Matrix van woordenlijst. In elke woordenlijst is de sleutel het token en de waarde is de prob. |
Responsvoorbeeld
De volgende JSON is een voorbeeldantwoord:
{
"id": "12345678-1234-1234-1234-abcdefghijkl",
"object": "chat.completion",
"created": 2012359,
"model": "",
"choices": [
{
"index": 0,
"finish_reason": "stop",
"message": {
"role": "assistant",
"content": "Sure, I\'d be happy to help! The translation of ""I love programming"" from English to Italian is:\n\n""Amo la programmazione.""\n\nHere\'s a breakdown of the translation:\n\n* ""I love"" in English becomes ""Amo"" in Italian.\n* ""programming"" in English becomes ""la programmazione"" in Italian.\n\nI hope that helps! Let me know if you have any other sentences you\'d like me to translate."
}
}
],
"usage": {
"prompt_tokens": 10,
"total_tokens": 40,
"completion_tokens": 30
}
}
Meer deductievoorbeelden
| Voorbeeldtype | Sample notebook |
|---|---|
| CLI met behulp van CURL- en Python-webaanvragen | webrequests.ipynb |
| OpenAI SDK (experimenteel) | openaisdk.ipynb |
| LangChain | langchain.ipynb |
| Mistral AI | mistralai.ipynb |
| LiteLLM | litellm.ipynb |
Kosten en quota
Kosten- en quotumoverwegingen voor de Mistral-serie van modellen die als een service zijn geïmplementeerd
Mistral-modellen die als een service worden geïmplementeerd, worden aangeboden door Mistral AI via Azure Marketplace en geïntegreerd met Azure Machine Learning-studio voor gebruik. U krijgt de prijzen voor Azure Marketplace wanneer u het model implementeert.
Telkens wanneer een werkruimte zich abonneert op een bepaald modelaanbod vanuit Azure Marketplace, wordt er een nieuwe resource gemaakt om de kosten te traceren die zijn gekoppeld aan het verbruik. Dezelfde resource wordt gebruikt om de kosten te traceren die zijn gekoppeld aan deductie; er zijn echter meerdere meters beschikbaar om elk scenario onafhankelijk te traceren.
Zie Monitoring van kosten voor modellen die worden aangeboden via Azure Marketplace voor meer informatie over het traceren van kosten.
Het quotum wordt beheerd per implementatie. Elke implementatie heeft een frequentielimiet van 200.000 tokens per minuut en 1000 API-aanvragen per minuut. Momenteel beperken we echter tot één implementatie per model per werkruimte. Neem contact op met de ondersteuning voor Microsoft Azure als de huidige frequentielimieten niet voldoende zijn voor uw scenario's.
Inhoud filteren
Modellen die zijn geïmplementeerd als een service met betalen per gebruik, worden beveiligd door azure AI-inhoudsveiligheid. Als de veiligheid van Azure AI-inhoud is ingeschakeld, passeren zowel de prompt als de voltooiing een ensemble van classificatiemodellen die zijn gericht op het detecteren en voorkomen van de uitvoer van schadelijke inhoud. Het systeem voor inhoudsfiltering (preview) detecteert en onderneemt actie op specifieke categorieën van mogelijk schadelijke inhoud in invoerprompts en uitvoervoltooiingen. Meer informatie over Azure AI Content Safety.
Gerelateerde inhoud
- Modelcatalogus en verzamelingen
- Modelafschapping en buitengebruikstelling in Azure AI-modelcatalogus
- Beschikbaarheid van regio's voor modellen in serverloze API-eindpunten
- Een machine learning-model implementeren en beoordelen met behulp van een online-eindpunt
- Kosten voor Azure AI Foundry plannen en beheren