MLflow-modellen implementeren op online-eindpunten
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidige)
Azure CLI ml-extensie v2 (huidige)
In dit artikel leert u hoe u uw MLflow-model implementeert in een online-eindpunt voor realtime deductie. Wanneer u uw MLflow-model implementeert op een online-eindpunt, hoeft u geen scorescript of een omgeving op te geven. Deze functionaliteit wordt ook wel implementatie zonder code genoemd.
Voor implementatie zonder code, Azure Machine Learning:
- Python-pakketten die in het
conda.yamlbestand zijn opgegeven, worden dynamisch geïnstalleerd. Daarom worden afhankelijkheden geïnstalleerd tijdens de containerruntime. - Biedt een MLflow-basisinstallatiekopieën/gecureerde omgeving die de volgende items bevat:
azureml-inference-server-httpmlflow-skinny- Een scorescript voor deductie.
Tip
Werkruimten zonder openbare netwerktoegang: Voordat u MLflow-modellen kunt implementeren naar online-eindpunten zonder uitgaande connectiviteit, moet u de modellen verpakken (preview).< Door modelverpakkingen te gebruiken, kunt u voorkomen dat er een internetverbinding nodig is, waarvoor azure Machine Learning anders de benodigde Python-pakketten voor de MLflow-modellen dynamisch moet installeren.
Over het voorbeeld
In het voorbeeld ziet u hoe u een MLflow-model kunt implementeren op een online-eindpunt om voorspellingen uit te voeren. In het voorbeeld wordt een MLflow-model gebruikt dat is gebaseerd op de gegevensset Diabetes. Deze gegevensset bevat 10 basislijnvariabelen: leeftijd, geslacht, lichaamsmassaindex, gemiddelde bloeddruk en zes bloedserummetingen verkregen van 442 diabetespatiënten. Het bevat ook de reactie van belang, een kwantitatieve meting van ziektevoortgang één jaar na de basislijn.
Het model is getraind met behulp van een scikit-learn regressor en alle vereiste voorverwerking is verpakt als een pijplijn, waardoor dit model een end-to-end-pijplijn is die van onbewerkte gegevens naar voorspellingen gaat.
De informatie in dit artikel is gebaseerd op codevoorbeelden in de opslagplaats azureml-examples . Als u de opdrachten lokaal wilt uitvoeren zonder YAML en andere bestanden te hoeven kopiëren/plakken, kloont u de opslagplaats en wijzigt u vervolgens mappen cliin , als u de Azure CLI gebruikt. Als u de Azure Machine Learning SDK voor Python gebruikt, wijzigt u de mappen in sdk/python/endpoints/online/mlflow.
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli
Volgen in Jupyter Notebook
U kunt de stappen voor het gebruik van de Azure Machine Learning Python SDK volgen door het MLflow-model implementeren te openen in het notebook voor online-eindpunten in de gekloonde opslagplaats.
Vereisten
Voordat u de stappen in dit artikel volgt, moet u ervoor zorgen dat u over de volgende vereisten beschikt:
Een Azure-abonnement. Als u nog geen abonnement op Azure hebt, maak dan een gratis account aan voordat u begint. Probeer de gratis of betaalde versie van Azure Machine Learning.
Op rollen gebaseerd toegangsbeheer van Azure (Azure RBAC) wordt gebruikt om toegang te verlenen tot bewerkingen in Azure Machine Learning. Als u de stappen in dit artikel wilt uitvoeren, moet aan uw gebruikersaccount de rol eigenaar of inzender voor de Azure Machine Learning-werkruimte zijn toegewezen, of een aangepaste rol die toestaat
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*. Zie Toegang tot een Azure Machine Learning-werkruimte beheren voor meer informatie over rollen.U moet een MLflow-model hebben geregistreerd in uw werkruimte. In dit artikel wordt een model geregistreerd dat is getraind voor de gegevensset Diabetes in de werkruimte.
U moet ook het volgende doen:
- Installeer de Azure CLI en de
mlextensie in de Azure CLI. Zie De CLI (v2) installeren en instellen voor meer informatie over het installeren van de CLI.
- Installeer de Azure CLI en de
Verbinding maken met uw werkruimte
Maak eerst verbinding met de Azure Machine Learning-werkruimte waar u werkt.
az account set --subscription <subscription>
az configure --defaults workspace=<workspace> group=<resource-group> location=<location>
Het model registreren
U kunt alleen geregistreerde modellen implementeren op online-eindpunten. In dit geval hebt u al een lokale kopie van het model in de opslagplaats, dus u hoeft het model alleen in het register in de werkruimte te publiceren. U kunt deze stap overslaan als het model dat u probeert te implementeren al is geregistreerd.
MODEL_NAME='sklearn-diabetes'
az ml model create --name $MODEL_NAME --type "mlflow_model" --path "endpoints/online/ncd/sklearn-diabetes/model"

Wat gebeurt er als uw model is geregistreerd in een uitvoering?
Als uw model is geregistreerd in een uitvoering, kunt u het rechtstreeks registreren.
Als u het model wilt registreren, moet u weten waar het is opgeslagen. Als u de functie van autolog MLflow gebruikt, is het pad naar het model afhankelijk van het modeltype en het framework. Controleer de taakuitvoer om de naam van de map van het model te identificeren. Deze map bevat een bestand met de naam MLModel.
Als u de log_model methode gebruikt om uw modellen handmatig te registreren, geeft u het pad naar het model als argument door aan de methode. Als u bijvoorbeeld het model aanmeldt met behulp van mlflow.sklearn.log_model(my_model, "classifier"), wordt het pad waar het model is opgeslagen, aangeroepen classifier.
Gebruik de Azure Machine Learning CLI v2 om een model te maken op basis van de uitvoer van een trainingstaak. In het volgende voorbeeld wordt een model met de naam $MODEL_NAME geregistreerd met behulp van de artefacten van een taak met id $RUN_ID. Het pad waar het model is opgeslagen, is $MODEL_PATH.
az ml model create --name $MODEL_NAME --path azureml://jobs/$RUN_ID/outputs/artifacts/$MODEL_PATH
Notitie
Het pad $MODEL_PATH is de locatie waar het model is opgeslagen in de uitvoering.

Een MLflow-model implementeren op een online-eindpunt
Configureer het eindpunt waar het model wordt geïmplementeerd. In het volgende voorbeeld wordt de naam en verificatiemodus van het eindpunt geconfigureerd:
Stel een eindpuntnaam in door de volgende opdracht uit te voeren (vervang door
YOUR_ENDPOINT_NAMEeen unieke naam):export ENDPOINT_NAME="<YOUR_ENDPOINT_NAME>"Configureer het eindpunt:
create-endpoint.yaml
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json name: my-endpoint auth_mode: keyMaak het eindpunt:
az ml online-endpoint create --name $ENDPOINT_NAME -f endpoints/online/ncd/create-endpoint.yamlConfigureer de implementatie. Een implementatie is een set resources die vereist is voor het hosten van het model dat de werkelijke deductie uitvoert.
sklearn-deployment.yaml
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json name: sklearn-deployment endpoint_name: my-endpoint model: name: mir-sample-sklearn-ncd-model version: 2 path: sklearn-diabetes/model type: mlflow_model instance_type: Standard_DS3_v2 instance_count: 1Notitie
Automatische generatie van de
scoring_scriptenenvironmentworden alleen ondersteund voorpyfuncmodelsmaak. Zie MLflow-modelimplementaties aanpassen om een andere modelsmaak te gebruiken.De implementatie maken:
az ml online-deployment create --name sklearn-deployment --endpoint $ENDPOINT_NAME -f endpoints/online/ncd/sklearn-deployment.yaml --all-trafficAls uw eindpunt geen uitgaande connectiviteit heeft, gebruikt u modelverpakking (preview) door de vlag
--with-packageop te geven:az ml online-deployment create --with-package --name sklearn-deployment --endpoint $ENDPOINT_NAME -f endpoints/online/ncd/sklearn-deployment.yaml --all-trafficWijs al het verkeer toe aan de implementatie. Tot nu toe heeft het eindpunt één implementatie, maar er wordt geen verkeer aan het eindpunt toegewezen.
Deze stap is niet vereist in de Azure CLI, omdat u de vlag hebt gebruikt tijdens het
--all-trafficmaken. Als u verkeer wilt wijzigen, kunt u de opdrachtaz ml online-endpoint update --trafficgebruiken. Zie Verkeer geleidelijk bijwerken voor meer informatie over het bijwerken van verkeer.Werk de eindpuntconfiguratie bij:
Deze stap is niet vereist in de Azure CLI, omdat u de vlag hebt gebruikt tijdens het
--all-trafficmaken. Als u verkeer wilt wijzigen, kunt u de opdrachtaz ml online-endpoint update --trafficgebruiken. Zie Verkeer geleidelijk bijwerken voor meer informatie over het bijwerken van verkeer.


Het eindpunt aanroepen
Zodra uw implementatie gereed is, kunt u deze gebruiken om een aanvraag te verwerken. Een manier om de implementatie te testen, is door gebruik te maken van de ingebouwde aanroepfunctie in de implementatieclient die u gebruikt. De volgende JSON is een voorbeeldaanvraag voor de implementatie.
sample-request-sklearn.json
{"input_data": {
"columns": [
"age",
"sex",
"bmi",
"bp",
"s1",
"s2",
"s3",
"s4",
"s5",
"s6"
],
"data": [
[ 1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0 ],
[ 10.0,2.0,9.0,8.0,7.0,6.0,5.0,4.0,3.0,2.0]
],
"index": [0,1]
}}
Notitie
input_data wordt in dit voorbeeld gebruikt in plaats van inputs dat wordt gebruikt in MLflow-server. Dit komt doordat Azure Machine Learning een andere invoerindeling vereist om automatisch de swagger-contracten voor de eindpunten te kunnen genereren. Zie Verschillen tussen modellen die zijn geïmplementeerd in ingebouwde Azure Machine Learning- en MLflow-server voor meer informatie over verwachte invoerindelingen.
Dien als volgt een aanvraag in bij het eindpunt:
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/ncd/sample-request-sklearn.json
Het antwoord is vergelijkbaar met de volgende tekst:
[
11633.100167144921,
8522.117402884991
]
Belangrijk
Testen via lokale eindpunten wordt momenteel niet ondersteund voor MLflow-implementatie zonder code.
MLflow-modelimplementaties aanpassen
U hoeft geen scorescript op te geven in de implementatiedefinitie van een MLflow-model naar een online-eindpunt. U kunt er echter voor kiezen om dit te doen en aan te passen hoe deductie wordt uitgevoerd.
Doorgaans wilt u de implementatie van uw MLflow-model aanpassen wanneer:
- Het model heeft
PyFuncer geen smaak op. - U moet de manier waarop het model wordt uitgevoerd aanpassen, bijvoorbeeld om een specifieke smaak te gebruiken om het model te laden met behulp van
mlflow.<flavor>.load_model(). - U moet pre-/postverwerking uitvoeren in uw scoreroutine wanneer dit niet wordt gedaan door het model zelf.
- De uitvoer van het model kan niet mooi worden weergegeven in tabelgegevens. Het is bijvoorbeeld een tensor die een afbeelding vertegenwoordigt.
Belangrijk
Als u ervoor kiest om een scorescript op te geven voor een implementatie van een MLflow-model, moet u ook de omgeving opgeven waarin de implementatie wordt uitgevoerd.
Stappen
Een MLflow-model implementeren met een aangepast scorescript:
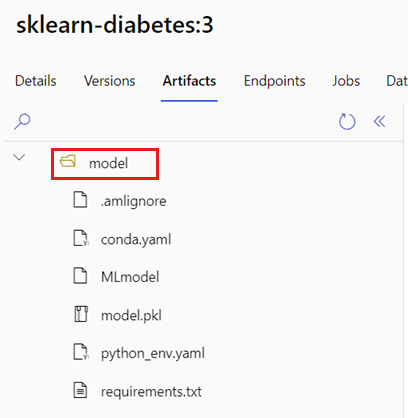
Identificeer de map waar uw MLflow-model zich bevindt.
a. Ga naar de Azure Machine Learning Studio.
b. Ga naar de sectie Modellen .
c. Selecteer het model dat u wilt implementeren en ga naar het tabblad Artefacten .
d. Noteer de map die wordt weergegeven. Deze map is opgegeven toen het model werd geregistreerd.
Maak een scorescript. U ziet hoe de mapnaam
modeldie u eerder hebt geïdentificeerd, is opgenomen in deinit()functie.Tip
Het volgende scorescript wordt gegeven als voorbeeld van het uitvoeren van deductie met een MLflow-model. U kunt dit script aanpassen aan uw behoeften of de onderdelen ervan aanpassen aan uw scenario.
score.py
import logging import os import json import mlflow from io import StringIO from mlflow.pyfunc.scoring_server import infer_and_parse_json_input, predictions_to_json def init(): global model global input_schema # "model" is the path of the mlflow artifacts when the model was registered. For automl # models, this is generally "mlflow-model". model_path = os.path.join(os.getenv("AZUREML_MODEL_DIR"), "model") model = mlflow.pyfunc.load_model(model_path) input_schema = model.metadata.get_input_schema() def run(raw_data): json_data = json.loads(raw_data) if "input_data" not in json_data.keys(): raise Exception("Request must contain a top level key named 'input_data'") serving_input = json.dumps(json_data["input_data"]) data = infer_and_parse_json_input(serving_input, input_schema) predictions = model.predict(data) result = StringIO() predictions_to_json(predictions, result) return result.getvalue()Waarschuwing
MLflow 2.0-advies: Het opgegeven scorescript werkt met zowel MLflow 1.X als MLflow 2.X. Houd er echter rekening mee dat de verwachte invoer-/uitvoerindelingen voor deze versies kunnen variëren. Controleer de omgevingsdefinitie die wordt gebruikt om ervoor te zorgen dat u de verwachte MLflow-versie gebruikt. U ziet dat MLflow 2.0 alleen wordt ondersteund in Python 3.8+.
Maak een omgeving waarin het scorescript kan worden uitgevoerd. Omdat het model een MLflow-model is, worden de conda-vereisten ook opgegeven in het modelpakket. Zie de MLmodel-indeling voor meer informatie over de bestanden die zijn opgenomen in een MLflow-model. Vervolgens bouwt u de omgeving met behulp van de conda-afhankelijkheden van het bestand. U moet echter ook het pakket
azureml-inference-server-httpopnemen, dat vereist is voor online-implementaties in Azure Machine Learning.Het conda-definitiebestand is als volgt:
conda.yml
channels: - conda-forge dependencies: - python=3.9 - pip - pip: - mlflow - scikit-learn==1.2.2 - cloudpickle==2.2.1 - psutil==5.9.4 - pandas==2.0.0 - azureml-inference-server-http name: mlflow-envNotitie
Het
azureml-inference-server-httppakket is toegevoegd aan het oorspronkelijke conda-afhankelijkhedenbestand.U gebruikt dit conda-afhankelijkhedenbestand om de omgeving te maken:
De omgeving wordt inline gemaakt in de implementatieconfiguratie.
De implementatie maken:
Maak een implementatieconfiguratiebestand deployment.yml:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json name: sklearn-diabetes-custom endpoint_name: my-endpoint model: azureml:sklearn-diabetes@latest environment: image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04 conda_file: sklearn-diabetes/environment/conda.yml code_configuration: code: sklearn-diabetes/src scoring_script: score.py instance_type: Standard_F2s_v2 instance_count: 1De implementatie maken:
az ml online-deployment create -f deployment.ymlZodra de implementatie is voltooid, kunt u aanvragen verwerken. Een manier om de implementatie te testen, is door een voorbeeldaanvraagbestand samen met de
invokemethode te gebruiken.sample-request-sklearn.json
{"input_data": { "columns": [ "age", "sex", "bmi", "bp", "s1", "s2", "s3", "s4", "s5", "s6" ], "data": [ [ 1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0 ], [ 10.0,2.0,9.0,8.0,7.0,6.0,5.0,4.0,3.0,2.0] ], "index": [0,1] }}Dien als volgt een aanvraag in bij het eindpunt:
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/ncd/sample-request-sklearn.jsonHet antwoord is vergelijkbaar met de volgende tekst:
{ "predictions": [ 11633.100167144921, 8522.117402884991 ] }Waarschuwing
MLflow 2.0 advies: In MLflow 1.X ontbreekt de
predictionssleutel.



Resources opschonen
Wanneer u klaar bent met het gebruik van het eindpunt, verwijdert u de bijbehorende resources:
az ml online-endpoint delete --name $ENDPOINT_NAME --yes