Probleem met de ParallelRunStep oplossen
VAN TOEPASSING OP: Python SDK azureml v1
Python SDK azureml v1
In dit artikel leert u hoe u problemen kunt oplossen wanneer u fouten krijgt met behulp van de klasse ParallelRunStep van de Azure Machine Learning SDK.
Zie Problemen met machine learning-pijplijnen oplossen voor algemene tips voor het oplossen van problemen met een pijplijn.
Scripts lokaal testen
Uw ParallelRunStep wordt uitgevoerd als een stap in ML-pijplijnen. Mogelijk wilt u uw scripts lokaal testen als eerste stap.
Vereisten voor invoerscript
Het invoerscript voor een ParallelRunStepmoet een run() functie bevatten en eventueel een init() functie bevat:
-
init(): Gebruik deze functie voor kostbare of algemene voorbereiding voor latere verwerking. Gebruik het bijvoorbeeld om het model in een algemeen object te laden. Deze functie wordt slechts één keer aan het begin van het proces aangeroepen.Notitie
Als uw
initmethode een uitvoermap maakt, geeft u datparents=Trueenexist_ok=True. Deinitmethode wordt aangeroepen vanuit elk werkproces op elk knooppunt waarop de taak wordt uitgevoerd. -
run(mini_batch): De functie wordt uitgevoerd voor elkmini_batchexemplaar.-
mini_batch:ParallelRunSteproept de run-methode aan en geeft een lijst of pandasDataFramedoor als argument aan de methode. Elke vermelding in mini_batch kan een bestandspad zijn als invoer eenFileDatasetof een pandasDataFrameis als invoer eenTabularDataset. -
response: run()-methode moet resulteren in een pandas-DataFrameof een matrix. Voor append_row output_action worden deze geretourneerde elementen toegevoegd aan het algemene uitvoerbestand. Voor summary_only wordt de inhoud van de elementen genegeerd. Voor alle uitvoeracties geeft elk geretourneerde uitvoerelement een geslaagde uitvoering van een invoerelement in de mini-batch aan. Zorg dat er voldoende gegevens worden opgenomen in het resultaat van de uitvoering om invoer toe te wijzen aan de uitvoerresultaten. Uitvoeruitvoeringen worden geschreven in het uitvoerbestand en zijn niet gegarandeerd in volgorde. Gebruik een sleutel in de uitvoer om deze toe te wijzen aan invoer.Notitie
Eén uitvoerelement wordt verwacht voor één invoerelement.
-
%%writefile digit_identification.py
# Snippets from a sample script.
# Refer to the accompanying digit_identification.py
# (https://github.com/Azure/MachineLearningNotebooks/tree/master/how-to-use-azureml/machine-learning-pipelines/parallel-run)
# for the implementation script.
import os
import numpy as np
import tensorflow as tf
from PIL import Image
from azureml.core import Model
def init():
global g_tf_sess
# Pull down the model from the workspace
model_path = Model.get_model_path("mnist")
# Construct a graph to execute
tf.reset_default_graph()
saver = tf.train.import_meta_graph(os.path.join(model_path, 'mnist-tf.model.meta'))
g_tf_sess = tf.Session()
saver.restore(g_tf_sess, os.path.join(model_path, 'mnist-tf.model'))
def run(mini_batch):
print(f'run method start: {__file__}, run({mini_batch})')
resultList = []
in_tensor = g_tf_sess.graph.get_tensor_by_name("network/X:0")
output = g_tf_sess.graph.get_tensor_by_name("network/output/MatMul:0")
for image in mini_batch:
# Prepare each image
data = Image.open(image)
np_im = np.array(data).reshape((1, 784))
# Perform inference
inference_result = output.eval(feed_dict={in_tensor: np_im}, session=g_tf_sess)
# Find the best probability, and add it to the result list
best_result = np.argmax(inference_result)
resultList.append("{}: {}".format(os.path.basename(image), best_result))
return resultList
Als u een ander bestand of een andere map hebt in dezelfde map als uw deductiescript, dan kunt u ernaar verwijzen door de huidige werkmap te zoeken. Als u uw pakketten wilt importeren, kunt u uw pakketmap ook toevoegen aan sys.path.
script_dir = os.path.realpath(os.path.join(__file__, '..',))
file_path = os.path.join(script_dir, "<file_name>")
packages_dir = os.path.join(file_path, '<your_package_folder>')
if packages_dir not in sys.path:
sys.path.append(packages_dir)
from <your_package> import <your_class>
Parameters voor ParallelRunConfig
ParallelRunConfig is de voornaamste configuratie voor ParallelRunStep-exemplaar in de Azure Machine Learning-pijplijn. U gebruikt dit om uw script te verpakken en de nodige parameters te configureren, waaronder alle volgende vermeldingen:
entry_script: Een gebruikersscript als een lokaal bestandspad dat parallel op meerdere knooppunten moet worden uitgevoerd. Alssource_directorydit aanwezig is, moet het relatieve pad worden gebruikt. Zoniet, gebruik dan een pad dat toegankelijk is op de machine.mini_batch_size: De grootte van de minibatch die aan éénrun()aanroep is doorgegeven. (optioneel; de standaardwaarde is10-bestanden voorFileDataseten1MBvoorTabularDataset.)- Voor
FileDatasetis dit het aantal bestanden met een minimumwaarde1. U kunt meerdere bestanden combineren in één mini-batch. - Voor
TabularDatasetis dit de grootte van de gegevens. Voorbeeldwaarden zijn1024,1024KB,10MBen1GB. De aanbevolen waarde is1MB. De mini-batch vanTabularDatasetzal nooit bestandsgrenzen overschrijden. Als er bijvoorbeeld meerdere .csv bestanden met verschillende grootten zijn, is de kleinste 100 kB en de grootste 10 MB. Alsmini_batch_size = 1MBde bestanden zijn ingesteld, worden de bestanden kleiner dan 1 MB behandeld als één minibatch en worden de bestanden die groter zijn dan 1 MB gesplitst in meerdere minibatches.Notitie
TabularDatasets die worden ondersteund door SQL, kunnen niet worden gepartitioneerd. TabularDatasets uit één parquet-bestand en één rijgroep kunnen niet worden gepartitioneerd.
- Voor
error_threshold: Het aantal recordfouten voorTabularDataseten bestandsfoutenFileDatasethiervoor moet tijdens de verwerking worden genegeerd. Zodra het aantal fouten voor de volledige invoer boven deze waarde komt, wordt de taak afgebroken. De drempelwaarde voor fouten geldt voor de volledige invoer, niet voor afzonderlijke mini-batches die naar derun()-methode verzonden worden. Het bereik is[-1, int.max].-1geeft aan dat alle fouten tijdens de verwerking worden genegeerd.output_action: Een van de volgende waarden geeft aan hoe de uitvoer is ingedeeld:-
summary_only: Het gebruikersscript moet de uitvoerbestanden opslaan. De uitvoer vanrun()wordt alleen gebruikt voor de berekening van de foutdrempelwaarde. -
append_row: Voor alle invoerParallelRunStepmaakt u één bestand in de uitvoermap om alle uitvoerwaarden, gescheiden door regel, toe te voegen.
-
append_row_file_name: Als u de naam van het uitvoerbestand voor append_row output_action wilt aanpassen (optioneel; standaardwaarde isparallel_run_step.txt).source_directory: Paden naar mappen die alle bestanden bevatten die moeten worden uitgevoerd op het rekendoel (optioneel).compute_target: AlleenAmlComputewordt ondersteund.node_count: het aantal rekenknooppunten dat moet worden gebruikt voor het uitvoeren van het gebruikersscript.process_count_per_node: het aantal werkprocessen per knooppunt om het invoerscript parallel uit te voeren. Voor een GPU-machine is de standaardwaarde 1. Voor een CPU-machine is de standaardwaarde het aantal kernen per knooppunt. Een werkproces roeptrun()herhaaldelijk aan door de minibatch door te geven die het als parameter krijgt. Het totale aantal werkprocessen in uw taak isprocess_count_per_node * node_count, waarmee het maximum aantalrun()gelijktijdige uitvoeringen wordt bepaald.environment: de Python-omgevingsdefinitie. U kunt deze configureren om een bestaande Python-omgeving te gebruiken of om een tijdelijke omgeving in te stellen. De definitie zorgt er ook voor dat de vereiste toepassingsafhankelijkheden worden ingesteld (optioneel).logging_level: Uitgebreidheid van logboeken. De waarden om uitgebreidheid te verhogen zijn:WARNING,INFOenDEBUG. (optioneel; de standaardwaarde isINFO)run_invocation_timeout: Derun()time-out voor aanroepen van de methode in seconden. (optioneel; standaardwaarde is60)run_max_try: Maximum aantal pogingen voorrun()een minibatch. Eenrun()is mislukt als er een uitzondering wordt gegenereerd of er niets wordt geretourneerd wanneerrun_invocation_timeoutis bereikt (optioneel; de standaardwaarde is3).
U kunt mini_batch_size, node_count, process_count_per_node, logging_level, run_invocation_timeout en run_max_try als PipelineParameter opgeven, zodat u de parameterwaarden kunt aanpassen wanneer u een pijplijnuitvoering opnieuw verzendt.
Zichtbaarheid van CUDA-apparaten
Voor rekendoelen die zijn uitgerust met GPU's, wordt de omgevingsvariabele CUDA_VISIBLE_DEVICES ingesteld in werkprocessen. In AmlCompute vindt u het totale aantal GPU-apparaten in de omgevingsvariabele AZ_BATCHAI_GPU_COUNT_FOUND, dat automatisch wordt ingesteld. Als u wilt dat elk werkproces een toegewezen GPU heeft, stelt u process_count_per_node het aantal GPU-apparaten op een computer in. Vervolgens wordt elk werkproces toegewezen aan een unieke index.CUDA_VISIBLE_DEVICES Wanneer een werkproces om welke reden dan ook stopt, wordt door het volgende gestarte werkproces de vrijgegeven GPU-index gebruikt.
Wanneer het totale aantal GPU-apparaten kleiner is dan process_count_per_node, kunnen de werkprocessen met een kleinere index aan GPU-index worden toegewezen totdat alle GPU's zijn bezet.
Aangezien het totale aantal GPU-apparaten 2 is en process_count_per_node = 4 als voorbeeld proces 0 en proces 1 index 0 en 1 gebruikt. Proces 2 en 3 heeft niet de omgevingsvariabele. Voor een bibliotheek die deze omgevingsvariabele gebruikt voor GPU-toewijzing, heeft proces 2 en 3 geen GPU-apparaten en probeert geen GPU-apparaten te verkrijgen. Proces 0 releases GPU index 0 wanneer het stopt. Aan het volgende proces, indien van toepassing, dat proces 4 is, wordt GPU-index 0 toegewezen.
Zie CUDA Pro Tip: GPU-zichtbaarheid beheren met CUDA_VISIBLE_DEVICES voor meer informatie.
Parameters voor het maken van de ParallelRunStep
Maak de ParallelRunStep met het script, de omgevingsconfiguratie en de parameters. Geef het rekendoel op dat u al aan uw werkruimte hebt gekoppeld als het doel van de uitvoering voor uw deductiescript. Gebruik ParallelRunStep om de stap voor de batchdeductiepijplijn te maken, met de volgende parameters:
-
name: De naam van de stap, met de volgende naamgevingsbeperkingen: uniek, 3-32 tekens en regex ^[a-z]([-a-z0-9]*[a-z0-9])?$. -
parallel_run_config: EenParallelRunConfigobject, zoals eerder gedefinieerd. -
inputs: Een of meer Azure Machine Learning-gegevenssets met één type die moeten worden gepartitioneerd voor parallelle verwerking. -
side_inputs: een of meer referentiegegevens of gegevenssets die worden gebruikt als invoer aan de zijkant zonder dat ze hoeven te worden gepartitioneerd. -
output: EenOutputFileDatasetConfigobject dat het mappad aangeeft waarop de uitvoergegevens moeten worden opgeslagen. -
arguments: Een lijst met argumenten die zijn doorgegeven aan het gebruikersscript. Gebruik unknown_args om deze op te halen in uw invoerscript (optioneel). -
allow_reuse: Of de stap eerdere resultaten opnieuw moet gebruiken wanneer deze wordt uitgevoerd met dezelfde instellingen/invoer. Als deze parameterFalseis, dan wordt er altijd een nieuwe uitvoering gegenereerd voor deze stap tijdens pijplijnuitvoering. (optioneel; de standaardwaarde isTrue.)
from azureml.pipeline.steps import ParallelRunStep
parallelrun_step = ParallelRunStep(
name="predict-digits-mnist",
parallel_run_config=parallel_run_config,
inputs=[input_mnist_ds_consumption],
output=output_dir,
allow_reuse=True
)
Foutopsporing van scripts vanuit externe context
De overgang van het lokaal opsporen van fouten in een scorescript naar het opsporen van fouten in een scorescript in een werkelijke pijplijn kan een moeilijke sprong zijn. Zie de sectie machine learning-pijplijnen over foutopsporingsscripts vanuit een externe context voor informatie over het vinden van uw logboeken in de portal. Informatie in die sectie is ook van toepassing op een ParallelRunStep.
Vanwege de gedistribueerde aard van ParallelRunStep-taken zijn er logboeken uit verschillende bronnen. Er worden echter twee geconsolideerde bestanden gemaakt die informatie op hoog niveau bieden:
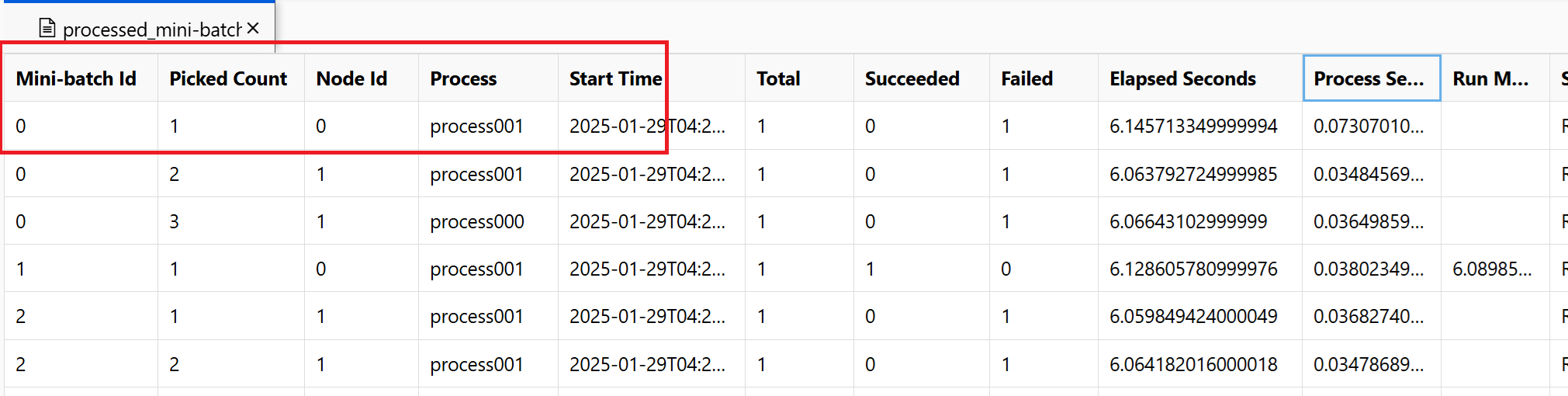
~/logs/job_progress_overview.txt: Dit bestand bevat informatie op hoog niveau over het aantal minibatches (ook wel taken genoemd) dat tot nu toe is gemaakt en het aantal minibatches dat tot nu toe is verwerkt. Op dit moment wordt het resultaat van de taak weergegeven. Als de taak mislukt, wordt het foutbericht weergegeven en waar u de probleemoplossing kunt starten.~/logs/job_result.txt: Het resultaat van de taak wordt weergegeven. Als de taak is mislukt, wordt het foutbericht weergegeven en waar u de probleemoplossing kunt starten.~/logs/job_error.txt: Dit bestand bevat een overzicht van de fouten in uw script.~/logs/sys/master_role.txt: Dit bestand biedt de principal-knooppuntweergave (ook wel orchestrator genoemd) van de actieve taak. Omvat het maken van taken, voortgangsbewaking, het uitvoeringsresultaat.~/logs/sys/job_report/processed_mini-batches.csv: Een tabel met alle minibatches die zijn verwerkt. Het toont het resultaat van elke uitvoering van minibatch, de id van het uitvoeringsagentknooppunt en de procesnaam. Ook worden de verstreken tijd en foutberichten opgenomen. Logboeken voor elke uitvoering van minibatches vindt u door de knooppunt-id en procesnaam te volgen.
Logboeken die zijn gegenereerd op basis van invoerscript met behulp van de EntryScript-helper en afdrukinstructies vindt u in de volgende bestanden:
~/logs/user/entry_script_log/<node_id>/<process_name>.log.txt: Deze bestanden zijn de logboeken die zijn geschreven uit entry_script met behulp van de EntryScript-helper.~/logs/user/stdout/<node_id>/<process_name>.stdout.txt: Deze bestanden zijn de logboeken van stdout (bijvoorbeeld de afdrukinstructie) van entry_script.~/logs/user/stderr/<node_id>/<process_name>.stderr.txt: Deze bestanden zijn de logboeken van stderr van entry_script.
In de schermopname ziet u bijvoorbeeld dat minibatch 0 is mislukt op knooppunt 0 process001. De bijbehorende logboeken voor uw invoerscript vindt u in ~/logs/user/entry_script_log/0/process001.log.txten ~/logs/user/stdout/0/process001.log.txt~/logs/user/stderr/0/process001.log.txt
Wanneer u een volledig inzicht nodig hebt in hoe elk knooppunt het scorescript heeft uitgevoerd, bekijkt u de afzonderlijke proceslogboeken voor elk knooppunt. De proceslogboeken vindt u in de ~/logs/sys/node map, gegroepeerd op werkknooppunten:
~/logs/sys/node/<node_id>/<process_name>.txt: Dit bestand bevat gedetailleerde informatie over elke minibatch die is opgehaald of voltooid door een werkrol. Voor elke minibatch bevat dit bestand het volgende:- Het IP-adres en de PID van het werkproces.
- Het totale aantal items, het aantal verwerkte items en het aantal mislukte items.
- De begintijd, duur, procestijd en uitvoeringstijd.
U kunt ook de resultaten bekijken van periodieke controles van het resourcegebruik voor elk knooppunt. De logboekbestanden en installatiebestanden bevinden zich in deze map:
~/logs/perf: Ingesteld--resource_monitor_intervalom het controle-interval in seconden te wijzigen. Het standaardinterval is600, wat ongeveer 10 minuten is. Als u de bewaking wilt stoppen, stelt u de waarde in op0. Elke<node_id>map bevat:-
os/: Informatie over alle actieve processen in het knooppunt. Met één controle wordt een besturingssysteemopdracht uitgevoerd en wordt het resultaat opgeslagen in een bestand. In Linux ispsde opdracht . Gebruik in Windowstasklist.-
%Y%m%d%H: De naam van de submap is de tijd tot uur.-
processes_%M: Het bestand eindigt met de minuut van de controletijd.
-
-
-
node_disk_usage.csv: Gedetailleerd schijfgebruik van het knooppunt. -
node_resource_usage.csv: Overzicht van resourcegebruik van het knooppunt. -
processes_resource_usage.csv: Overzicht van resourcegebruik van elk proces.
-
Veelvoorkomende redenen voor taakfouten
SystemExit: 42
Exits 41 en 42 zijn PRS ontworpen afsluitcodes. Werkknooppunten sluiten af met 41 om rekenbeheer te waarschuwen dat deze onafhankelijk is beëindigd. Het wordt verwacht. Een leader-knooppunt kan worden afgesloten met 0 of 42, wat het taakresultaat aangeeft. Exit 42 betekent dat de taak is mislukt. De reden van de fout kan worden gevonden in ~/logs/job_result.txt. U kunt de vorige sectie volgen om fouten in uw taak op te sporen.
Gegevensmachtiging
Fout van de taak geeft aan dat de berekening geen toegang heeft tot invoergegevens. Als identiteitsgebaseerde gegevens worden gebruikt voor uw rekencluster en -opslag, kunt u verwijzen naar op identiteit gebaseerde gegevensverificatie.
Processen zijn onverwacht beëindigd
Processen kunnen vastlopen vanwege onverwachte of niet-verwerkte uitzonderingen. Het systeem beëindigt processen vanwege uitzonderingen met onvoldoende geheugen. In PRS-systeemlogboeken ~/logs/sys/node/<node-id>/_main.txtvindt u fouten zoals hieronder.
<process-name> exits with returncode -9.
Onvoldoende geheugen
~/logs/perf registreert het rekenresourceverbruik van processen. Het geheugengebruik van elke taakprocessor is te vinden. U kunt het totale geheugengebruik op het knooppunt schatten.
Fout met onvoldoende geheugen is te vinden in ~/system_logs/lifecycler/<node-id>/execution-wrapper.txt.
We raden u aan het aantal processen per knooppunt te verminderen of vm-grootte bij te werken als de rekenresources de limieten sluiten.
Onverwerkte uitzonderingen
In sommige gevallen kunnen de Python-processen de mislukte stack niet vangen. U kunt een omgevingsvariabele env["PYTHONFAULTHANDLER"]="true" toevoegen om de ingebouwde fouthandler van Python in te schakelen.
Minibatch Time-out
U kunt het argument aanpassen run_invocation_timeout op basis van uw minibatch-taken. Als u ziet dat de run()-functies meer tijd in beslag nemen dan verwacht, vindt u hier enkele tips.
Controleer de verstreken tijd en procestijd van de minibatch. De procestijd meet de CPU-tijd van het proces. Wanneer de procestijd aanzienlijk korter is dan verstreken, kunt u controleren of er zware IO-bewerkingen of netwerkaanvragen in de taken zijn. Lange latentie van deze bewerkingen is de veelvoorkomende reden van time-out voor minibatch.
Sommige specifieke minibatches duren langer dan andere. U kunt de configuratie bijwerken of met invoergegevens werken om de verwerkingstijd van de minibatch te verdelen.
Hoe kan ik logboek van mijn gebruikersscript vanuit een externe context?
ParallelRunStep kan meerdere processen uitvoeren op één knooppunt op basis van process_count_per_node. Als u logboeken van elk proces op knooppunten wilt ordenen en de afdruk- en logboekinstructie wilt combineren, wordt de ParallelRunStep-logboekregistratie die hieronder wordt weergegeven, aanbevolen. U krijgt een logboekregistratie van EntryScript en de logboeken worden weergegeven in de logboeken/gebruikersmap in de portal.
Een voorbeeld van een invoerscript met behulp van de logboekregistratie:
from azureml_user.parallel_run import EntryScript
def init():
"""Init once in a worker process."""
entry_script = EntryScript()
logger = entry_script.logger
logger.info("This will show up in files under logs/user on the Azure portal.")
def run(mini_batch):
"""Call once for a mini batch. Accept and return the list back."""
# This class is in singleton pattern. It returns the same instance as the one in init()
entry_script = EntryScript()
logger = entry_script.logger
logger.info(f"{__file__}: {mini_batch}.")
...
return mini_batch
Waar wordt het bericht van Python logging sink naartoe verzonden?
ParallelRunStep stelt een handler in op de hoofdlogger, waarmee het bericht wordt weggehaald logs/user/stdout/<node_id>/processNNN.stdout.txt.
logging is standaard ingesteld op INFO niveau. Standaard worden de onderstaande INFO niveaus niet weergegeven, zoals DEBUG.
Hoe kan ik naar een bestand schrijven om weer te geven in de portal?
Bestanden die naar /logs de map worden geschreven, worden geüpload en weergegeven in de portal.
U kunt de map logs/user/entry_script_log/<node_id> zoals hieronder ophalen en het bestandspad opstellen om te schrijven:
from pathlib import Path
from azureml_user.parallel_run import EntryScript
def init():
"""Init once in a worker process."""
entry_script = EntryScript()
log_dir = entry_script.log_dir
log_dir = Path(entry_script.log_dir) # logs/user/entry_script_log/<node_id>/.
log_dir.mkdir(parents=True, exist_ok=True) # Create the folder if not existing.
proc_name = entry_script.agent_name # The process name in pattern "processNNN".
fil_path = log_dir / f"{proc_name}_<file_name>" # Avoid conflicting among worker processes with proc_name.
Hoe kan ik aanmelden bij nieuwe processen afhandelen?
U kunt nieuwe processen in uw invoerscript subprocess met module maken, verbinding maken met hun invoer-/uitvoer-/foutpijpen en hun retourcodes verkrijgen.
De aanbevolen methode is het gebruik van de run() functie met capture_output=True. Fouten worden weergegeven in logs/user/error/<node_id>/<process_name>.txt.
Als u wilt gebruiken Popen(), moet stdout/stderr worden omgeleid naar bestanden, zoals:
from pathlib import Path
from subprocess import Popen
from azureml_user.parallel_run import EntryScript
def init():
"""Show how to redirect stdout/stderr to files in logs/user/entry_script_log/<node_id>/."""
entry_script = EntryScript()
proc_name = entry_script.agent_name # The process name in pattern "processNNN".
log_dir = Path(entry_script.log_dir) # logs/user/entry_script_log/<node_id>/.
log_dir.mkdir(parents=True, exist_ok=True) # Create the folder if not existing.
stdout_file = str(log_dir / f"{proc_name}_demo_stdout.txt")
stderr_file = str(log_dir / f"{proc_name}_demo_stderr.txt")
proc = Popen(
["...")],
stdout=open(stdout_file, "w"),
stderr=open(stderr_file, "w"),
# ...
)
Notitie
Een werkrolproces voert systeemcode en de code van het invoerscript in hetzelfde proces uit.
Als er geen stdout of stderr opgegeven is, wordt de instelling van het werkproces overgenomen door subprocessen die zijn gemaakt in Popen() uw invoerscript.
stdout schrijft naar ~/logs/sys/node/<node_id>/processNNN.stdout.txt en stderr naar ~/logs/sys/node/<node_id>/processNNN.stderr.txt.
Hoe kan ik een bestand naar de uitvoermap schrijven en vervolgens weergeven in de portal?
U kunt de uitvoermap ophalen uit EntryScript de klasse en ernaar schrijven. Als u de geschreven bestanden wilt weergeven, selecteert u in de stap Uitvoeren in de Azure Machine Learning-portal het tabblad Uitvoer en logboeken . Selecteer de koppeling Gegevensuitvoer en voer vervolgens de stappen uit die in het dialoogvenster worden beschreven.
Gebruik EntryScript dit in uw invoerscript, zoals in dit voorbeeld:
from pathlib import Path
from azureml_user.parallel_run import EntryScript
def run(mini_batch):
output_dir = Path(entry_script.output_dir)
(Path(output_dir) / res1).write...
(Path(output_dir) / res2).write...
Hoe kan ik een zijinvoer, zoals een bestand of bestanden met een opzoektabel, doorgeven aan al mijn werknemers?
Gebruiker kan referentiegegevens doorgeven aan script met behulp van side_inputs parameter ParalleRunStep. Alle gegevenssets die worden geleverd als side_inputs worden gekoppeld op elk werkknooppunt. De gebruiker kan de locatie van koppelen ophalen door het argument door te geven.
Maak een gegevensset met de referentiegegevens, geef een lokaal koppelpad op en registreer het bij uw werkruimte. Geef deze door aan de side_inputs parameter van uw ParallelRunStep. Daarnaast kunt u het pad in de arguments sectie toevoegen om eenvoudig toegang te krijgen tot het gekoppelde pad.
Notitie
Gebruik FileDatasets alleen voor side_inputs.
local_path = "/tmp/{}".format(str(uuid.uuid4()))
label_config = label_ds.as_named_input("labels_input").as_mount(local_path)
batch_score_step = ParallelRunStep(
name=parallel_step_name,
inputs=[input_images.as_named_input("input_images")],
output=output_dir,
arguments=["--labels_dir", label_config],
side_inputs=[label_config],
parallel_run_config=parallel_run_config,
)
Daarna kunt u deze als volgt openen in uw script (bijvoorbeeld in uw init()-methode:
parser = argparse.ArgumentParser()
parser.add_argument('--labels_dir', dest="labels_dir", required=True)
args, _ = parser.parse_known_args()
labels_path = args.labels_dir
Invoergegevenssets gebruiken met verificatie van de service-principal?
Gebruiker kan invoergegevenssets doorgeven met verificatie van de service-principal die wordt gebruikt in de werkruimte. Voor het gebruik van een dergelijke gegevensset in ParallelRunStep moet de gegevensset worden geregistreerd om de ParallelRunStep-configuratie te maken.
service_principal = ServicePrincipalAuthentication(
tenant_id="***",
service_principal_id="***",
service_principal_password="***")
ws = Workspace(
subscription_id="***",
resource_group="***",
workspace_name="***",
auth=service_principal
)
default_blob_store = ws.get_default_datastore() # or Datastore(ws, '***datastore-name***')
ds = Dataset.File.from_files(default_blob_store, '**path***')
registered_ds = ds.register(ws, '***dataset-name***', create_new_version=True)
Voortgang controleren en analyseren
Deze sectie gaat over het controleren van de voortgang van een ParallelRunStep-taak en het controleren van de oorzaak van onverwacht gedrag.
De voortgang van de taak controleren
Naast het bekijken van de algehele status van de StepRun, kan het aantal geplande/verwerkte minibatches en de voortgang van het genereren van uitvoer worden weergegeven in ~/logs/job_progress_overview.<timestamp>.txt. Het bestand wordt dagelijks gedraaid. U kunt deze controleren met het grootste tijdstempel voor de meest recente informatie.
Wat moet ik controleren of er een tijdje geen voortgang is?
U kunt nagaan ~/logs/sys/error of er een uitzondering is. Als er geen is, duurt het waarschijnlijk lang voordat uw invoerscript lang duurt, kunt u voortgangsgegevens in uw code afdrukken om het tijdrovende deel te vinden of toevoegen "--profiling_module", "cProfile" aan het ParallelRunSteparguments bestand om een profielbestand te genereren met <process_name>.profile de naam onder ~/logs/sys/node/<node_id> de map.
Wanneer stopt een baan?
Als deze niet is geannuleerd, kan de taak stoppen met de status:
- Voltooid. Alle minibatches worden verwerkt en de uitvoer wordt gegenereerd voor
append_rowde modus. - Mislukt. Als
error_thresholdde inwaardeParameters for ParallelRunConfigis overschreden, of er treedt een systeemfout op tijdens de taak.
Waar vind ik de hoofdoorzaak van de fout?
U kunt de lead ~/logs/job_result.txt volgen om de oorzaak en het gedetailleerde foutenlogboek te vinden.
Heeft een knooppuntfout invloed op het taakresultaat?
Niet als er andere beschikbare knooppunten in het aangewezen rekencluster zijn. ParallelRunStep kan onafhankelijk van elk knooppunt worden uitgevoerd. Fout met één knooppunt mislukt niet voor de hele taak.
Wat gebeurt er als init de functie in het invoerscript mislukt?
ParallelRunStep heeft een mechanisme om het opnieuw te proberen voor een bepaalde tijd om kans te geven op herstel na tijdelijke problemen, zonder dat de taakfout te lang wordt vertraagd. Het mechanisme is als volgt:
- Als na het starten
initvan een knooppunt op alle agents blijft mislukken, wordt het proberen3 * process_count_per_nodena fouten gestopt. - Als de taak wordt gestart,
initmislukken alle agents van alle knooppunten niet meer als de taak langer dan 2 minuten wordt uitgevoerd en er fouten zijn2 * node_count * process_count_per_node. - Als alle agents langer dan
3 * run_invocation_timeout + 30seconden vastzitteninit, mislukt de taak vanwege een te lange voortgang.
Wat gebeurt er met OutOfMemory? Hoe kan ik de oorzaak controleren?
Het proces kan worden beëindigd door het systeem. ParallelRunStep stelt de huidige poging in om de minibatch te verwerken naar de foutstatus en probeert het mislukte proces opnieuw op te starten. U kunt controleren ~logs/perf/<node_id> of het geheugengebruiksproces wordt gevonden.
Waarom heb ik veel processNNN-bestanden?
ParallelRunStep start nieuwe werkprocessen ter vervanging van de processen die abnormaal zijn afgesloten. Elk proces genereert een set processNNN bestanden als logboek. Als het proces echter is mislukt vanwege een uitzondering tijdens de init functie van het gebruikersscript en dat de fout continu wordt herhaald voor 3 * process_count_per_node tijden, wordt er geen nieuw werkproces gestart.
Volgende stappen
Bekijk deze Jupyter-notebooks die Azure Machine Learning-pijplijnen demonstreren
Raadpleeg de SDK-naslaginformatie voor hulp bij het pakket azureml-pipeline-steps .
Raadpleeg de referentiedocumentatie voor de klasse ParallelRunConfig en documentatie voor de klasse ParallelRunStep.
Volg de geavanceerde zelfstudie over het gebruik van pijplijnen met ParallelRunStep. In de zelfstudie ziet u hoe u een ander bestand als zijinvoer doorgeeft.