Machine Learning-pijplijnen maken en uitvoeren met behulp van onderdelen met de Azure Machine Learning-studio
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidige)
Azure CLI ml-extensie v2 (huidige)
In dit artikel leert u hoe u machine learning-pijplijnen maakt en uitvoert met behulp van de Azure Machine Learning-studio en onderdelen. U kunt pijplijnen maken zonder onderdelen te gebruiken, maar onderdelen bieden een betere mate van flexibiliteit en hergebruik. Azure Machine Learning-pijplijnen kunnen worden gedefinieerd in YAML en worden uitgevoerd vanuit de CLI, geschreven in Python of samengesteld in Azure Machine Learning-studio Designer met slepen en neerzetten. Dit document is gericht op de gebruikersinterface van Azure Machine Learning-studio designer.
Vereisten
Als u geen Azure-abonnement hebt, maakt u een gratis account voordat u begint. Probeer de gratis of betaalde versie van Azure Machine Learning.
Een Azure Machine Learning-werkruimte Werkruimtebronnen maken.
Installeer en stel de Azure CLI-extensie voor Machine Learning in.
Kloon de opslagplaats met voorbeelden:
git clone https://github.com/Azure/azureml-examples --depth 1 cd azureml-examples/cli/jobs/pipelines-with-components/
Notitie
Designer ondersteunt twee typen onderdelen, klassieke vooraf gebouwde onderdelen (v1) en aangepaste onderdelen (v2). Deze twee typen onderdelen zijn NIET compatibel.
Klassieke vooraf samengestelde onderdelen bieden belangrijke vooraf gedefinieerde onderdelen voor gegevensverwerking en traditionele machine learning-taken, zoals regressie en classificatie. Klassieke vooraf gebouwde onderdelen worden nog steeds ondersteund, maar er zijn geen nieuwe onderdelen toegevoegd. Daarnaast biedt de implementatie van klassieke vooraf samengestelde onderdelen (v1) geen ondersteuning voor beheerde online-eindpunten (v2).
Met aangepaste onderdelen kunt u uw eigen code verpakken als onderdeel. Het biedt ondersteuning voor het delen van onderdelen in werkruimten en naadloze creatie in studio-, CLI v2- en SDK v2-interfaces.
Voor nieuwe projecten raden we u ten zeerste aan aangepaste onderdelen te gebruiken, die compatibel is met AzureML V2 en nieuwe updates blijven ontvangen.
Dit artikel is van toepassing op aangepaste onderdelen.
Onderdeel registreren in uw werkruimte
Als u een pijplijn wilt bouwen met behulp van onderdelen in de gebruikersinterface, moet u eerst onderdelen registreren bij uw werkruimte. U kunt de gebruikersinterface, CLI of SDK gebruiken om onderdelen in uw werkruimte te registreren, zodat u het onderdeel in de werkruimte kunt delen en opnieuw kunt gebruiken. Geregistreerde onderdelen ondersteunen automatisch versiebeheer, zodat u het onderdeel kunt bijwerken, maar ervoor zorgen dat pijplijnen waarvoor een oudere versie is vereist, blijven werken.
In het volgende voorbeeld wordt de gebruikersinterface gebruikt om onderdelen te registreren en de bronbestanden van het onderdeel bevinden zich in de cli/jobs/pipelines-with-components/basics/1b_e2e_registered_components map van de azureml-examples opslagplaats. U moet de opslagplaats eerst klonen naar lokaal.
Navigeer in uw Azure Machine Learning-werkruimte naar de pagina Onderdelen en selecteer Nieuw onderdeel. Een van de twee stijlpagina's wordt weergegeven:

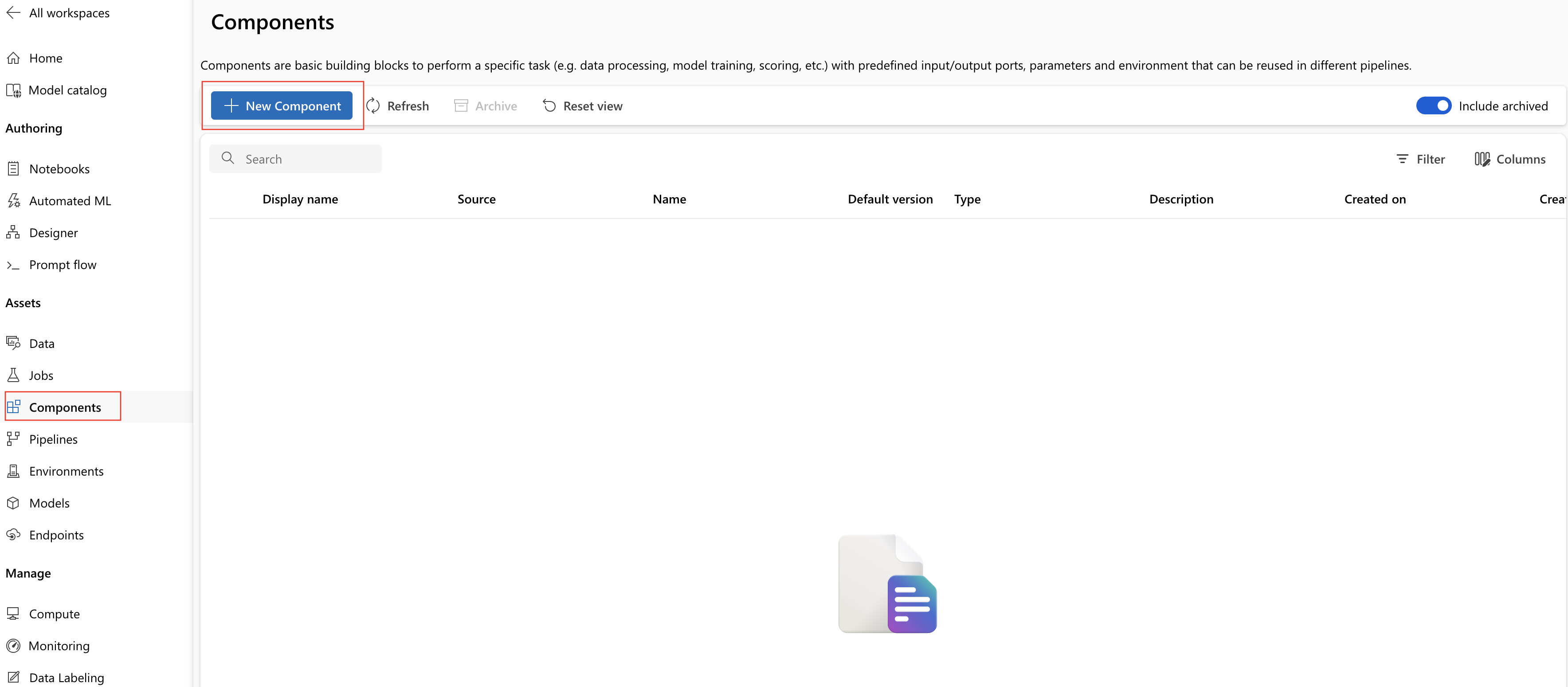


In dit voorbeeld wordt gebruikgemaakt train.ymlvan de map 1b_e2e_registered_components. Het YAML-bestand definieert de naam, het type, de interface, inclusief invoer en uitvoer, code, omgeving en opdracht van dit onderdeel. De code van dit onderdeel train.py bevindt zich onder ./train_src de map, waarin de uitvoeringslogica van dit onderdeel wordt beschreven. Zie de naslaginformatie over het YAML-schema van het opdrachtonderdeel voor meer informatie over het onderdeelschema.
Notitie
Wanneer u onderdelen registreert in de gebruikersinterface, die is gedefinieerd in het YAML-onderdeelbestand, code kan alleen verwijzen naar de huidige map waarin het YAML-bestand zich bevindt of de submappen. Dit betekent dat u de bovenliggende map niet kunt ../code herkennen voor de gebruikersinterface.
additional_includes kan alleen verwijzen naar de huidige of submap.
Op dit moment ondersteunt de gebruikersinterface alleen het registreren van onderdelen met command het type.
- Selecteer Uploaden uit map en selecteer de
1b_e2e_registered_componentsmap die u wilt uploaden. Selecteertrain.ymlin de vervolgkeuzelijst.

Selecteer Volgende onderaan en u kunt de details van dit onderdeel bevestigen. Nadat u hebt bevestigd, selecteert u Maken om het registratieproces te voltooien.
Herhaal de vorige stappen om het onderdeel Score en Eval te registreren.
score.ymleval.ymlNadat u de drie onderdelen hebt geregistreerd, kunt u uw onderdelen zien in de gebruikersinterface van studio.

Pijplijn maken met behulp van een geregistreerd onderdeel
Maak een nieuwe pijplijn in de ontwerpfunctie. Vergeet niet om de optie Aangepast te selecteren.
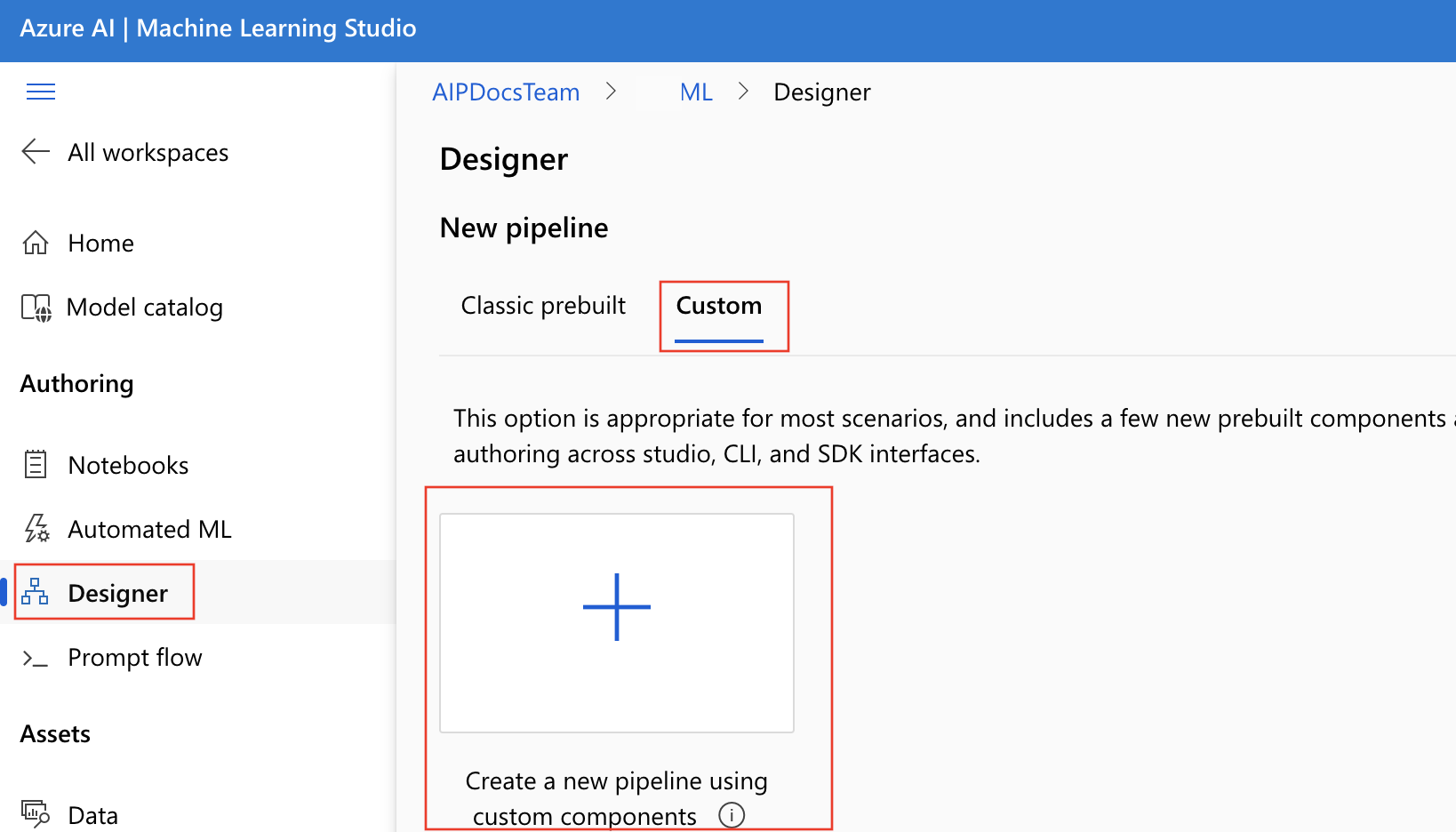
Geef de pijplijn een betekenisvolle naam door het potloodpictogram naast de automatisch gegenereerde naam te selecteren.

In de bibliotheek met ontwerpassets ziet u de tabbladen Gegevens, Model en Onderdelen . Ga naar het tabblad Onderdelen . U kunt de onderdelen zien die zijn geregistreerd in de vorige sectie. Als er te veel onderdelen zijn, kunt u zoeken met de naam van het onderdeel.

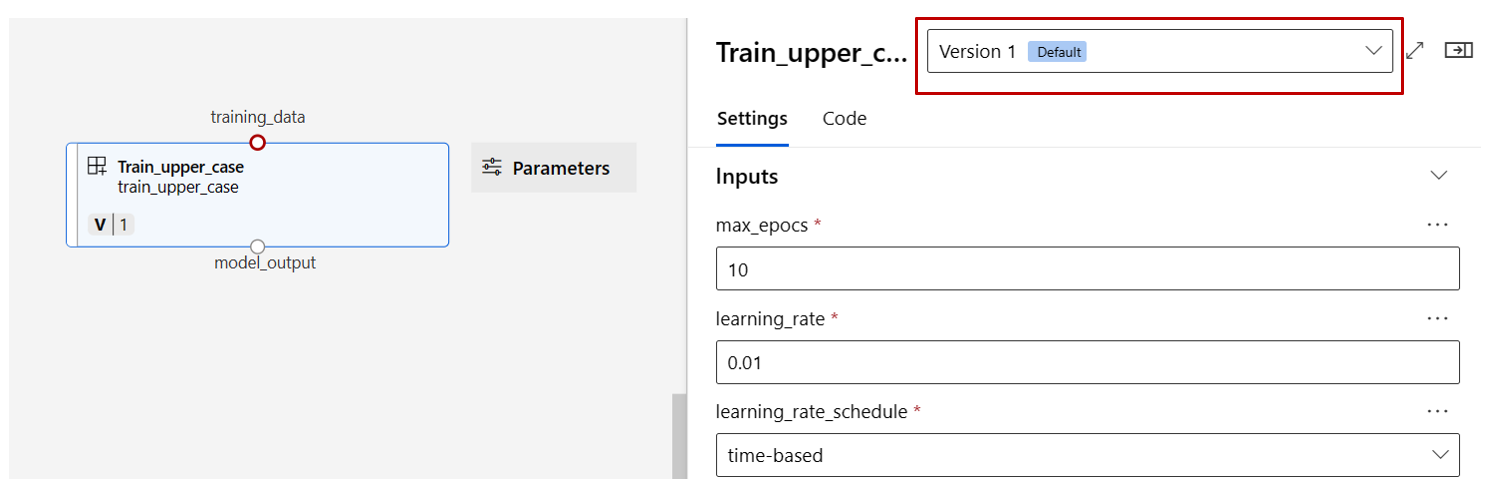
Zoek de onderdelen train, score en eval die zijn geregistreerd in de vorige sectie en sleep ze vervolgens op het canvas. Standaard wordt de standaardversie van het onderdeel gebruikt. Als u wilt overschakelen naar een specifieke versie, dubbelklikt u op het onderdeel om het onderdeelvenster te openen.
In dit voorbeeld gebruiken we de voorbeeldgegevens in de gegevensmap. Registreer de gegevens in uw werkruimte door het pictogram Toevoegen te selecteren in de assetbibliotheek van de ontwerper:> tabblad Gegevens, Typ = Map(uri_folder) en volg vervolgens de wizard om de gegevens te registreren. Het gegevenstype moet worden uri_folder om te worden afgestemd op de definitie van het trainonderdeel.

Sleep de gegevens vervolgens naar het canvas. Uw pijplijn ziet er nu uit zoals in de volgende schermopname.

Verbind de gegevens en onderdelen door verbindingen in het canvas te slepen.

Dubbelklik op één onderdeel. U ziet een rechterdeelvenster waarin u het onderdeel kunt configureren.
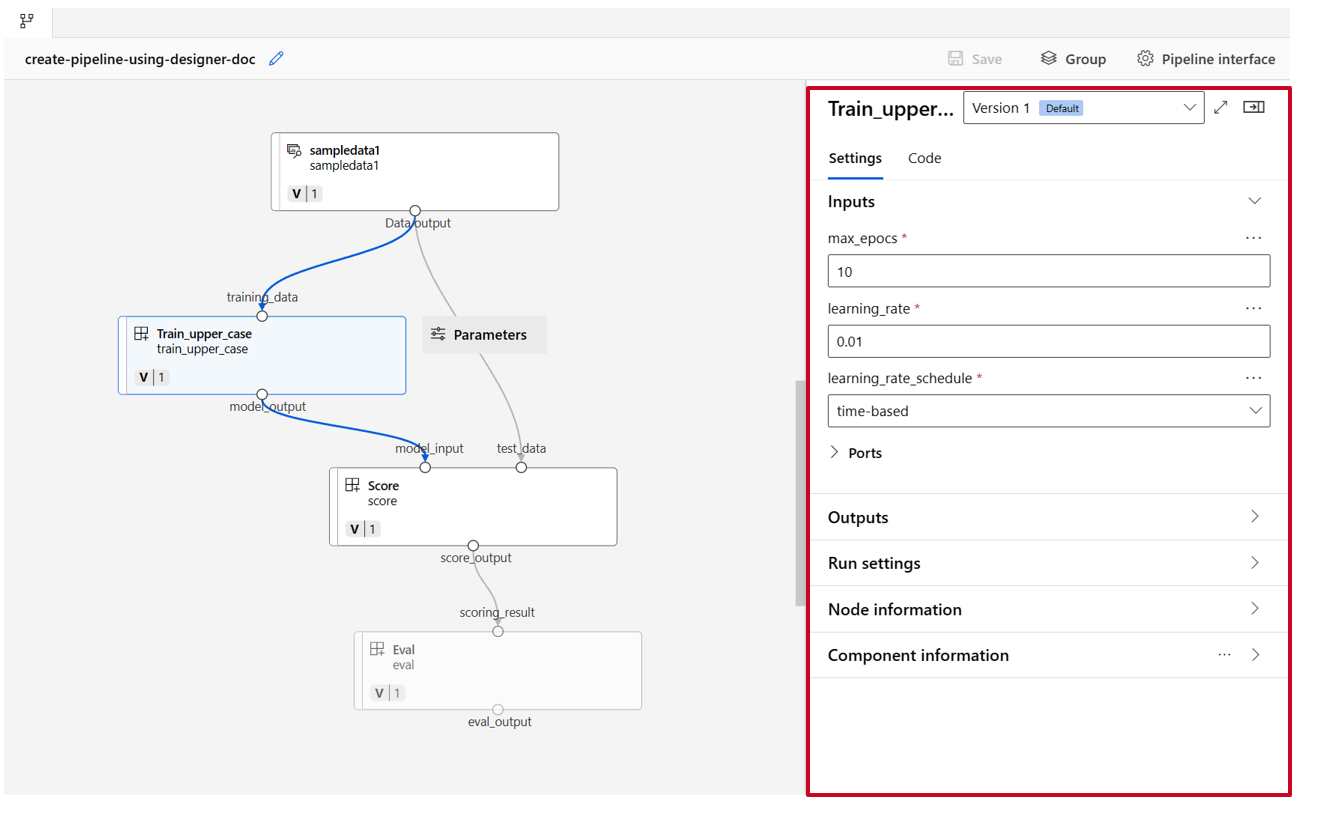
Voor onderdelen met primitieve typeinvoer, zoals getal, geheel getal, tekenreeks en booleaanse waarde, kunt u waarden van dergelijke invoer wijzigen in het detailvenster van het onderdeel, onder de sectie Invoer .
U kunt ook de uitvoerinstellingen wijzigen (waar de uitvoer van het onderdeel moet worden opgeslagen) en instellingen uitvoeren (rekendoel om dit onderdeel uit te voeren) in het rechterdeelvenster.
We gaan nu de max_epocs invoer van het trainonderdeel promoveren naar invoer op pijplijnniveau. Als u dit doet, kunt u elke keer een andere waarde aan deze invoer toewijzen voordat u de pijplijn verzendt.
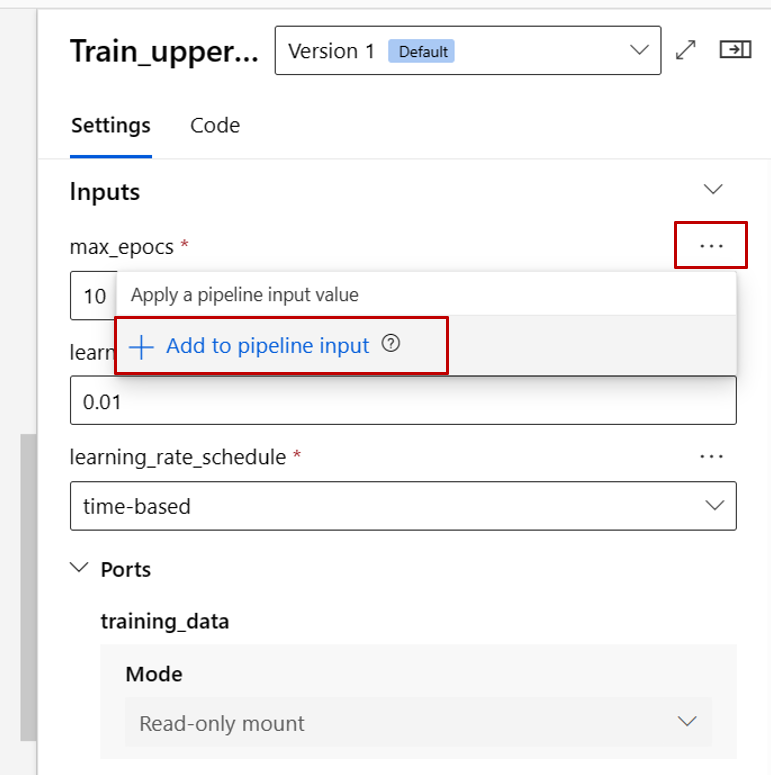









Notitie
Aangepaste onderdelen en de klassieke vooraf samengestelde ontwerponderdelen kunnen niet samen worden gebruikt.
Pijplijn verzenden
Selecteer Configureren en verzenden om de pijplijn te verzenden.

Vervolgens ziet u een stapsgewijze wizard. Volg de wizard om de pijplijntaak te verzenden.

In de basisstap kunt u het experiment, de weergavenaam van de taak, de taakbeschrijving, enzovoort configureren.
In de stap Invoer en uitvoer kunt u de invoer/uitvoer configureren die naar pijplijnniveau worden gepromoveerd. In de vorige stap hebben we de max_epocs van het trainingsonderdeel gepromoveerd naar pijplijninvoer, dus u moet hier waarde kunnen zien en toewijzen aan max_epocs .
In runtime-instellingen kunt u het standaardgegevensarchief en de standaard rekenkracht van de pijplijn configureren. Dit is de standaardgegevensopslag/compute voor alle onderdelen in de pijplijn. Als u echter expliciet een ander reken- of gegevensarchief instelt voor een onderdeel, respecteert het systeem de instelling op onderdeelniveau. Anders wordt de standaardwaarde voor de pijplijn gebruikt.
De stap Beoordelen en verzenden is de laatste stap om alle configuraties te controleren voordat u het verzendt. De wizard onthoudt de configuratie van uw laatste keer als u de pijplijn ooit verzendt.
Nadat u de pijplijntaak hebt verzonden, ziet u bovenaan een bericht met een koppeling naar de taakdetails. U kunt deze koppeling selecteren om de taakdetails te bekijken.

Identiteit opgeven in pijplijntaak
Wanneer u een pijplijntaak verzendt, kunt u de identiteit opgeven voor toegang tot de gegevens onder Run settings. De standaardidentiteit is AMLToken die ondertussen geen enkele identiteit heeft gebruikt die we zowel UserIdentity als Managed. De UserIdentityidentiteit van de taak-inzender wordt gebruikt om toegang te krijgen tot invoergegevens en het resultaat naar de uitvoermap te schrijven. Als u opgeeft Managed, gebruikt het systeem de beheerde identiteit voor toegang tot de invoergegevens en schrijft het resultaat naar de uitvoermap.

Volgende stappen
- Gebruik deze Jupyter-notebooks op GitHub om machine learning-pijplijnen verder te verkennen
- Meer informatie over het gebruik van CLI v2 voor het maken van pijplijnen met behulp van onderdelen.
- Meer informatie over het gebruik van SDK v2 voor het maken van pijplijnen met behulp van onderdelen