AutoML instellen om Computer Vision-modellen te trainen
VAN TOEPASSING OP: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
In dit artikel leert u hoe u Computer Vision-modellen traint op afbeeldingsgegevens met geautomatiseerde ML. U kunt modellen trainen met behulp van de Azure Machine Learning CLI-extensie v2 of de Azure Machine Learning Python SDK v2.
Geautomatiseerde ML ondersteunt modeltraining voor Computer Vision-taken zoals afbeeldingsclassificatie, objectdetectie en exemplaarsegmentatie. Het schrijven van AutoML-modellen voor Computer Vision-taken wordt op het moment ondersteund via Azure Machine Learning Python SDK. De resulterende experimenten, modellen en uitvoer zijn toegankelijk vanuit de gebruikersinterface van Azure Machine Learning-studio. Meer informatie over geautomatiseerde ml voor Computer Vision-taken op afbeeldingsgegevens.
Vereisten
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidige)
- Een Azure Machine Learning-werkruimte. Zie Werkruimtebronnen maken om de werkruimte te maken.
- Installeer en stel CLI (v2) in en zorg ervoor dat u de
mlextensie installeert.
Selecteer uw taaktype
Geautomatiseerde ML voor installatiekopieën ondersteunt de volgende taaktypen:
| Taaktype | Syntaxis van AutoML-taak |
|---|---|
| afbeeldingsclassificatie | CLI v2: image_classification SDK v2: image_classification() |
| afbeeldingsclassificatie met meerdere labels | CLI v2: image_classification_multilabel SDK v2: image_classification_multilabel() |
| detectie van afbeeldingsobjecten | CLI v2: image_object_detection SDK v2: image_object_detection() |
| segmentatie van afbeeldingsexemplaren | CLI v2: image_instance_segmentation SDK v2: image_instance_segmentation() |
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidige)
Dit taaktype is een vereiste parameter en kan worden ingesteld met behulp van de task sleutel.
Voorbeeld:
task: image_object_detection
Trainings- en validatiegegevens
Als u Computer Vision-modellen wilt genereren, moet u gelabelde afbeeldingsgegevens als invoer voor modeltraining in de vorm van een MLTable. U kunt een MLTable van trainingsgegevens maken in JSONL-indeling.
Als uw trainingsgegevens een andere indeling hebben (zoals Pascal VOC of COCO), kunt u de helperscripts in de voorbeeldnotitieblokken toepassen om de gegevens te converteren naar JSONL. Meer informatie over het voorbereiden van gegevens voor computer Vision-taken met geautomatiseerde ML.
Notitie
De trainingsgegevens moeten ten minste 10 afbeeldingen hebben om een AutoML-taak te kunnen verzenden.
Waarschuwing
Het maken van gegevens in JSONL-indeling wordt alleen ondersteund met behulp van MLTable de SDK en CLI voor deze mogelijkheid. Het maken van de MLTable via gebruikersinterface wordt momenteel niet ondersteund.
JSONL-schemavoorbeelden
De structuur van de TabularDataset is afhankelijk van de taak die bij de hand is. Voor computer Vision-taaktypen bestaat deze uit de volgende velden:
| Veld | Beschrijving |
|---|---|
image_url |
Bevat bestandspad als een StreamInfo-object |
image_details |
Informatie over metagegevens van afbeeldingen bestaat uit hoogte, breedte en indeling. Dit veld is optioneel en bestaat dus al dan niet. |
label |
Een json-weergave van het afbeeldingslabel op basis van het taaktype. |
De volgende code is een JSONL-voorbeeldbestand voor afbeeldingsclassificatie:
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label": "cat"
}
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_02.jpeg",
"image_details":
{
"format": "jpeg",
"width": "3456px",
"height": "3467px"
},
"label": "dog"
}
De volgende code is een JSONL-voorbeeldbestand voor objectdetectie:
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label":
{
"label": "cat",
"topX": "1",
"topY": "0",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "true",
}
}
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_02.png",
"image_details":
{
"format": "jpeg",
"width": "1230px",
"height": "2356px"
},
"label":
{
"label": "dog",
"topX": "0",
"topY": "1",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "false",
}
}
Gegevens gebruiken
Zodra uw gegevens de JSONL-indeling hebben, kunt u training en validatie MLTable maken, zoals hieronder wordt weergegeven.
paths:
- file: ./train_annotations.jsonl
transformations:
- read_json_lines:
encoding: utf8
invalid_lines: error
include_path_column: false
- convert_column_types:
- columns: image_url
column_type: stream_info
Geautomatiseerde ML legt geen beperkingen op voor trainings- of validatiegegevensgrootte voor Computer Vision-taken. De maximale grootte van de gegevensset wordt alleen beperkt door de opslaglaag achter de gegevensset (bijvoorbeeld: blobarchief). Er is geen minimumaantal afbeeldingen of labels. We raden u echter aan om te beginnen met minimaal 10-15 voorbeelden per label om ervoor te zorgen dat het uitvoermodel voldoende is getraind. Hoe hoger het totale aantal labels/klassen, hoe meer voorbeelden u per label nodig hebt.
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidige)
Trainingsgegevens zijn een vereiste parameter en worden doorgegeven met behulp van de training_data sleutel. U kunt desgewenst een andere MLtable opgeven als validatiegegevens met de validation_data sleutel. Als er geen validatiegegevens zijn opgegeven, wordt standaard 20% van uw trainingsgegevens gebruikt voor validatie, tenzij u een argument met een andere waarde doorgeeft validation_data_size .
De naam van de doelkolom is een vereiste parameter en wordt gebruikt als doel voor een ML-taak onder supervisie. Het wordt doorgegeven met behulp van de target_column_name sleutel. Bijvoorbeeld:
target_column_name: label
training_data:
path: data/training-mltable-folder
type: mltable
validation_data:
path: data/validation-mltable-folder
type: mltable
Compute en uitvoering van het experiment instellen
Geef een rekendoel op voor geautomatiseerde ML om modeltraining uit te voeren. Geautomatiseerde ML-modellen voor computer vision-taken vereisen GPU-SKU's en ondersteunen NC- en ND-families. We raden de NCsv3-serie (met v100 GPU's) aan voor snellere training. Een rekendoel met een SKU met meerdere GPU-VM's maakt gebruik van meerdere GPU's om ook de training te versnellen. Daarnaast kunt u, wanneer u een rekendoel instelt met meerdere knooppunten, sneller modeltraining uitvoeren via parallelle uitvoering bij het afstemmen van hyperparameters voor uw model.
Notitie
Als u een rekenproces als rekendoel gebruikt, moet u ervoor zorgen dat meerdere AutoML-taken niet tegelijkertijd worden uitgevoerd. Zorg er ook voor dat deze max_concurrent_trials is ingesteld op 1 in uw taaklimieten.
Het rekendoel wordt doorgegeven met behulp van de compute parameter. Voorbeeld:
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidige)
compute: azureml:gpu-cluster
Experimenten configureren
Voor Computer Vision-taken kunt u afzonderlijke proefversies, handmatige sweeps of automatische opruimen starten. We raden u aan om te beginnen met een automatische opruimen om een eerste basislijnmodel op te halen. Vervolgens kunt u afzonderlijke proefversies uitproberen met bepaalde modellen en hyperparameterconfiguraties. Ten slotte kunt u met handmatige sweeps meerdere hyperparameterwaarden verkennen in de buurt van de meer veelbelovende modellen en hyperparameterconfiguraties. Deze driestapswerkstroom (automatische opruimen, individuele experimenten, handmatige sweeps) voorkomt het doorzoeken van de gehele hyperparameterruimte, die exponentieel toeneemt in het aantal hyperparameters.
Automatische sweeps kunnen concurrerende resultaten opleveren voor veel gegevenssets. Daarnaast vereisen ze geen geavanceerde kennis van modelarchitecturen, houden ze rekening met hyperparametercorrelaties en werken ze naadloos in verschillende hardware-instellingen. Al deze redenen maken ze een sterke optie voor de vroege fase van uw experimenten.
Primaire metrische gegevens
Een AutoML-trainingstaak maakt gebruik van een primaire metriek voor modeloptimalisatie en afstemming van hyperparameters. De primaire metriek is afhankelijk van het taaktype, zoals hieronder wordt weergegeven; andere primaire metrische waarden worden momenteel niet ondersteund.
- Nauwkeurigheid voor afbeeldingsclassificatie
- Snijpunt boven samenvoeging voor afbeeldingsclassificatie met meerdere labels
- Gemiddelde precisie voor de detectie van afbeeldingsobjecten
- Gemiddelde precisie voor segmentatie van afbeeldingsexemplaren
Taaklimieten
U kunt de resources beheren die zijn besteed aan uw Trainingstaak voor AutoML-installatiekopieën door de timeout_minutes, max_trials en de max_concurrent_trials voor de taak in de limietinstellingen op te geven, zoals beschreven in het onderstaande voorbeeld.
| Parameter | Detail |
|---|---|
max_trials |
Parameter voor het maximum aantal experimenten dat moet worden geveegd. Moet een geheel getal tussen 1 en 1000 zijn. Wanneer u alleen de standaard hyperparameters voor een bepaalde modelarchitectuur verkent, stelt u deze parameter in op 1. De standaardwaarde is 1. |
max_concurrent_trials |
Maximum aantal experimenten dat gelijktijdig kan worden uitgevoerd. Indien opgegeven, moet een geheel getal tussen 1 en 100 zijn. De standaardwaarde is 1. OPMERKING: max_concurrent_trials wordt intern beperkt max_trials . Als gebruikerssets max_concurrent_trials=4bijvoorbeeld , max_trials=2worden waarden intern bijgewerkt als max_concurrent_trials=2, max_trials=2. |
timeout_minutes |
De hoeveelheid tijd in minuten voordat het experiment wordt beëindigd. Als er geen is opgegeven, is het standaardexperiment timeout_minutes zeven dagen (maximaal 60 dagen) |
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidige)
limits:
timeout_minutes: 60
max_trials: 10
max_concurrent_trials: 2
Automatisch opruimen van model hyperparameters (AutoMode)
Belangrijk
Deze functie is momenteel beschikbaar als openbare preview-versie. Deze preview-versie wordt geleverd zonder een service level agreement. Misschien worden bepaalde functies niet ondersteund of zijn de mogelijkheden ervan beperkt. Zie Aanvullende gebruiksvoorwaarden voor Microsoft Azure-previews voor meer informatie.
Het is moeilijk om de beste modelarchitectuur en hyperparameters voor een gegevensset te voorspellen. In sommige gevallen kan ook de menselijke tijd die is toegewezen aan het afstemmen van hyperparameters beperkt zijn. Voor Computer Vision-taken kunt u een willekeurig aantal experimenten opgeven en het systeem bepaalt automatisch de regio van de hyperparameterruimte die moet worden geveegd. U hoeft geen hyperparameterzoekruimte, een steekproefmethode of een beleid voor vroegtijdige beëindiging te definiëren.
AutoMode activeren
U kunt automatische opruimen uitvoeren door de instelling in te stellen max_trials op een waarde die groter is dan 1 in limits en door niet de zoekruimte, steekproefmethode en beëindigingsbeleid op te geven. We noemen deze functionaliteit AutoMode; Zie het volgende voorbeeld.
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidige)
limits:
max_trials: 10
max_concurrent_trials: 2
Een aantal proefversies tussen 10 en 20 werkt waarschijnlijk goed voor veel gegevenssets. Het tijdbudget voor de AutoML-taak kan nog steeds worden ingesteld, maar we raden u aan dit alleen te doen als elke proefversie lang kan duren.
Waarschuwing
Het starten van automatische opruimen via de gebruikersinterface wordt momenteel niet ondersteund.
Individuele proefversies
In afzonderlijke proefversies bepaalt u rechtstreeks de modelarchitectuur en hyperparameters. De modelarchitectuur wordt doorgegeven via de model_name parameter.
Ondersteunde modelarchitecturen
De volgende tabel bevat een overzicht van de ondersteunde verouderde modellen voor elke Computer Vision-taak. Als u alleen deze verouderde modellen gebruikt, worden uitvoeringen geactiveerd met behulp van de verouderde runtime (waarbij elke afzonderlijke uitvoering of proefversie wordt ingediend als een opdrachttaak). Zie hieronder voor ondersteuning voor HuggingFace en MMDetection.
| Opdracht | modelarchitecturen | Letterlijke syntaxis van tekenreeksdefault_model* aangeduid met * |
|---|---|---|
| Afbeeldingsclassificatie (meerdere klassen en meerdere labels) |
MobileNet: Lichtgewicht modellen voor mobiele toepassingen ResNet: Restnetwerken ResNeSt: Aandachtsnetwerken splitsen SE-ResNeXt50: Squeeze-and-Excitation-netwerken ViT: Vision-transformatornetwerken |
mobilenetv2 resnet18 resnet34 resnet50 resnet101 resnet152 resnest50 resnest101 seresnext vits16r224 (klein) vitb16r224* (grondtal) vitl16r224 (groot) |
| Objectdetectie |
YOLOv5: Objectdetectiemodel met één fase Snellere RCNN ResNet FPN: modellen voor objectdetectie in twee fasen RetinaNet ResNet FPN: adresklasseonbalans met brandpuntverlies Opmerking: Raadpleeg model_size hyperparameter voor YOLOv5-modelgrootten. |
yolov5* fasterrcnn_resnet18_fpn fasterrcnn_resnet34_fpn fasterrcnn_resnet50_fpn fasterrcnn_resnet101_fpn fasterrcnn_resnet152_fpn retinanet_resnet50_fpn |
| Instantiesegmentatie | MaskRCNN ResNet FPN | maskrcnn_resnet18_fpn maskrcnn_resnet34_fpn maskrcnn_resnet50_fpn* maskrcnn_resnet101_fpn maskrcnn_resnet152_fpn |
Ondersteunde modelarchitecturen - HuggingFace en MMDetection
Met de nieuwe back-end die wordt uitgevoerd op Azure Machine Learning-pijplijnen, kunt u ook elk afbeeldingsclassificatiemodel van huggingFace Hub gebruiken dat deel uitmaakt van de bibliotheek met transformatoren (zoals microsoft/beit-base-patch16-224), evenals elk objectdetectie- of exemplaarsegmentatiemodel van de MMDetection-versie 3.1.0 Model Zoo (zoalsatss_r50_fpn_1x_coco).
Naast het ondersteunen van elk model van HuggingFace Transfomers en MMDetection 3.1.0, bieden we ook een lijst met gecureerde modellen uit deze bibliotheken in het azureml-register. Deze gecureerde modellen zijn grondig getest en gebruiken standaard hyperparameters die zijn geselecteerd op basis van uitgebreide benchmarking om effectieve training te garanderen. De onderstaande tabel bevat een overzicht van deze gecureerde modellen.
| Opdracht | modelarchitecturen | Letterlijke syntaxis van tekenreeks |
|---|---|---|
| Afbeeldingsclassificatie (meerdere klassen en meerdere labels) |
BEiT ViT DeiT SwinV2 |
microsoft/beit-base-patch16-224-pt22k-ft22kgoogle/vit-base-patch16-224facebook/deit-base-patch16-224microsoft/swinv2-base-patch4-window12-192-22k |
| Objectdetectie |
Sparse R-CNN Vervormbare DETR VFNet YOLOF |
mmd-3x-sparse-rcnn_r50_fpn_300-proposals_crop-ms-480-800-3x_cocommd-3x-sparse-rcnn_r101_fpn_300-proposals_crop-ms-480-800-3x_coco mmd-3x-deformable-detr_refine_twostage_r50_16xb2-50e_coco mmd-3x-vfnet_r50-mdconv-c3-c5_fpn_ms-2x_coco mmd-3x-vfnet_x101-64x4d-mdconv-c3-c5_fpn_ms-2x_coco mmd-3x-yolof_r50_c5_8x8_1x_coco |
| Exemplaarsegmentatie | R-CNN maskeren | mmd-3x-mask-rcnn_swin-t-p4-w7_fpn_1x_coco |
We werken voortdurend de lijst met gecureerde modellen bij. U kunt de meest recente lijst met de gecureerde modellen voor een bepaalde taak ophalen met behulp van de Python SDK:
credential = DefaultAzureCredential()
ml_client = MLClient(credential, registry_name="azureml")
models = ml_client.models.list()
classification_models = []
for model in models:
model = ml_client.models.get(model.name, label="latest")
if model.tags['task'] == 'image-classification': # choose an image task
classification_models.append(model.name)
classification_models
Uitvoer:
['google-vit-base-patch16-224',
'microsoft-swinv2-base-patch4-window12-192-22k',
'facebook-deit-base-patch16-224',
'microsoft-beit-base-patch16-224-pt22k-ft22k']
Als u een HuggingFace- of MMDetection-model gebruikt, worden uitvoeringen geactiveerd met behulp van pijplijnonderdelen. Als zowel verouderde als HuggingFace/MMdetection-modellen worden gebruikt, worden alle uitvoeringen/experimenten geactiveerd met behulp van onderdelen.
Naast het beheren van de modelarchitectuur kunt u ook hyperparameters afstemmen die worden gebruikt voor modeltraining. Hoewel veel van de weergegeven hyperparameters modelneutraal zijn, zijn er exemplaren waarbij hyperparameters taakspecifiek of modelspecifiek zijn. Meer informatie over de beschikbare hyperparameters voor deze exemplaren.
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidige)
Als u de standaard hyperparameterwaarden wilt gebruiken voor een bepaalde architectuur (bijvoorbeeld yolov5), kunt u deze opgeven met behulp van de model_name sleutel in de sectie training_parameters. Bijvoorbeeld:
training_parameters:
model_name: yolov5
Hyperparameters van model handmatig opruimen
Bij het trainen van Computer Vision-modellen zijn modelprestaties sterk afhankelijk van de geselecteerde hyperparameterwaarden. Vaak wilt u de hyperparameters afstemmen om optimale prestaties te krijgen. Voor Computer Vision-taken kunt u hyperparameters opruimen om de optimale instellingen voor uw model te vinden. Met deze functie worden de mogelijkheden voor het afstemmen van hyperparameters in Azure Machine Learning toegepast. Meer informatie over het afstemmen van hyperparameters.
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidige)
search_space:
- model_name:
type: choice
values: [yolov5]
learning_rate:
type: uniform
min_value: 0.0001
max_value: 0.01
model_size:
type: choice
values: [small, medium]
- model_name:
type: choice
values: [fasterrcnn_resnet50_fpn]
learning_rate:
type: uniform
min_value: 0.0001
max_value: 0.001
optimizer:
type: choice
values: [sgd, adam, adamw]
min_size:
type: choice
values: [600, 800]
De zoekruimte voor parameters definiëren
U kunt de modelarchitecturen en hyperparameters definiëren om in de parameterruimte te vegen. U kunt één modelarchitectuur of meerdere modellen opgeven.
- Zie Afzonderlijke proefversies voor de lijst met ondersteunde modelarchitecturen voor elk taaktype.
- Zie Hyperparameters voor Computer Vision-taken hyperparameters voor elk type Computer Vision-taak.
- Zie de details over ondersteunde distributies voor discrete en continue hyperparameters.
Samplingmethoden voor de opruimen
Bij het opruimen van hyperparameters moet u de samplingmethode opgeven die moet worden gebruikt voor het opruimen van de gedefinieerde parameterruimte. Momenteel worden de volgende samplingmethoden ondersteund met de sampling_algorithm parameter:
| Steekproeftype | Syntaxis van AutoML-taak |
|---|---|
| Willekeurige steekproeven | random |
| Rastersampling | grid |
| Bayesiaanse steekproeven | bayesian |
Notitie
Momenteel ondersteunen alleen willekeurige en rastersampling voorwaardelijke hyperparameterruimten.
Beleid voor vroegtijdige beëindiging
U kunt automatisch slecht presterende proefversies beëindigen met een beleid voor vroegtijdige beëindiging. Vroegtijdige beëindiging verbetert de rekenefficiëntie, waardoor rekenresources worden bespaard die anders zouden zijn besteed aan minder veelbelovende experimenten. Geautomatiseerde ML voor installatiekopieën ondersteunt het volgende beleid voor vroegtijdige beëindiging met behulp van de early_termination parameter. Als er geen beëindigingsbeleid is opgegeven, worden alle proefversies uitgevoerd tot voltooiing.
| Beleid voor vroegtijdige beëindiging | Syntaxis van AutoML-taak |
|---|---|
| Bandit-beleid | CLI v2: bandit SDK v2: BanditPolicy() |
| Beleid voor het stoppen van mediaan | CLI v2: median_stopping SDK v2: MedianStoppingPolicy() |
| Selectiebeleid afkappen | CLI v2: truncation_selection SDK v2: TruncationSelectionPolicy() |
Meer informatie over het configureren van het beleid voor vroegtijdige beëindiging voor uw hyperparameter opruimen.
Notitie
Raadpleeg deze zelfstudie voor een volledig voorbeeld van een sweep-configuratie.
U kunt alle gerelateerde parameters voor opruimen configureren, zoals wordt weergegeven in het volgende voorbeeld.
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidige)
sweep:
sampling_algorithm: random
early_termination:
type: bandit
evaluation_interval: 2
slack_factor: 0.2
delay_evaluation: 6
Vaste instellingen
U kunt vaste instellingen of parameters doorgeven die niet worden gewijzigd tijdens het opruimen van de parameterruimte, zoals wordt weergegeven in het volgende voorbeeld.
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidige)
training_parameters:
early_stopping: True
evaluation_frequency: 1
Gegevensvergroting
Over het algemeen kunnen de prestaties van deep learning-modellen vaak worden verbeterd met meer gegevens. Gegevensvergroting is een praktische techniek om de gegevensgrootte en variabiliteit van een gegevensset te vergroten, wat helpt om overfitting te voorkomen en de generalisatiemogelijkheden van het model voor niet-gebruikte gegevens te verbeteren. Geautomatiseerde ML past verschillende technieken voor gegevensvergroting toe op basis van de computer vision-taak, voordat invoerafbeeldingen aan het model worden ingevoerd. Op dit moment is er geen blootgestelde hyperparameter voor het beheren van gegevensvergrotingen.
| Opdracht | Betrokken gegevensset | Toegepaste techniek(en) voor gegevensvergroting |
|---|---|---|
| Afbeeldingsclassificatie (meerdere klassen en meerdere labels) | Training Validatie en test |
Willekeurige grootte wijzigen en bijsnijden, horizontale flip, kleur jitter (helderheid, contrast, verzadiging en tint), normalisatie met behulp van kanaalgewijze ImageNet's gemiddelde en standaarddeviatie Formaat wijzigen, centreren, normaliseren |
| Objectdetectie, exemplaarsegmentatie | Training Validatie en test |
Willekeurig bijsnijden rond begrenzingsvakken, uitvouwen, horizontaal spiegelen, normaliseren, formaat wijzigen Normalisatie, formaat wijzigen |
| Objectdetectie met yolov5 | Training Validatie en test |
Mozaïek, willekeurige affine (draaiing, vertaling, schaal, shear), horizontaal spiegelen Formaat van brievenbus wijzigen |
Momenteel worden de hierboven gedefinieerde uitbreidingen standaard toegepast voor een geautomatiseerde ML voor een installatiekopieëntaak. Geautomatiseerde ML voor afbeeldingen wordt onder twee vlaggen weergegeven om bepaalde uitbreidingen uit te schakelen om controle te bieden over uitbreidingen. Deze vlaggen worden momenteel alleen ondersteund voor objectdetectie- en instantiesegmentatietaken.
- apply_mosaic_for_yolo: deze vlag is alleen specifiek voor het Yolo-model. Als u deze instelt op False, wordt de uitbreiding van mozaïekgegevens uitgeschakeld, die op het trainingstijdstip wordt toegepast.
-
apply_automl_train_augmentations: Als u deze vlag instelt op onwaar, wordt de uitbreiding uitgeschakeld die tijdens de trainingstijd wordt toegepast voor de objectdetectie- en instantiesegmentatiemodellen. Zie de details in de bovenstaande tabel voor uitbreidingen.
- Voor niet-yolo-objectdetectiemodel en segmentatiemodellen van exemplaren schakelt deze vlag alleen de eerste drie uitbreidingen uit. Bijvoorbeeld: Willekeurig bijsnijden rond begrenzingsvakken, uitvouwen, horizontaal spiegelen. De normalisatie- en formaatvergrotingen worden nog steeds toegepast, ongeacht deze vlag.
- Voor Yolo-model schakelt deze vlag de willekeurige affine- en horizontale flip-uitbreidingen uit.
Deze twee vlaggen worden ondersteund via advanced_settings onder training_parameters en kunnen op de volgende manier worden beheerd.
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidige)
training_parameters:
advanced_settings: >
{"apply_mosaic_for_yolo": false}
training_parameters:
advanced_settings: >
{"apply_automl_train_augmentations": false}
Houd er rekening mee dat deze twee vlaggen onafhankelijk van elkaar zijn en ook kunnen worden gebruikt in combinatie met behulp van de volgende instellingen.
training_parameters:
advanced_settings: >
{"apply_automl_train_augmentations": false, "apply_mosaic_for_yolo": false}
In onze experimenten hebben we vastgesteld dat deze uitbreidingen het model helpen om beter te generaliseren. Wanneer deze uitbreidingen worden uitgeschakeld, raden we de gebruikers aan om ze te combineren met andere offline-uitbreidingen om betere resultaten te krijgen.
Incrementele training (optioneel)
Zodra de trainingstaak is voltooid, kunt u ervoor kiezen om het model verder te trainen door het getrainde modelcontrolepunt te laden. U kunt dezelfde gegevensset of een andere gegevensset gebruiken voor incrementele training. Als u tevreden bent met het model, kunt u ervoor kiezen om de training te stoppen en het huidige model te gebruiken.
Het controlepunt doorgeven via taak-id
U kunt de taak-id doorgeven waaruit u het controlepunt wilt laden.
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidige)
training_parameters:
checkpoint_run_id : "target_checkpoint_run_id"
De AutoML-taak verzenden
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidige)
Als u uw AutoML-taak wilt verzenden, voert u de volgende CLI v2-opdracht uit met het pad naar uw .yml-bestand, werkruimtenaam, resourcegroep en abonnements-id.
az ml job create --file ./hello-automl-job-basic.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Metrische gegevens voor uitvoer en evaluatie
De geautomatiseerde ML-trainingstaken genereren uitvoermodelbestanden, metrische evaluatiegegevens, logboeken en implementatieartefacten, zoals het scorebestand en het omgevingsbestand. Deze bestanden en metrische gegevens kunnen worden weergegeven op het tabblad Uitvoer en logboeken en metrische gegevens van de onderliggende taken.
Tip
Controleer hoe u naar de taakresultaten navigeert vanuit de sectie Taakresultaten weergeven .
Zie De resultaten van geautomatiseerde machine learning-experimenten evalueren voor definities en voorbeelden van de prestatiegrafieken en metrische gegevens voor elke taak.
Model registreren en implementeren
Zodra de taak is voltooid, kunt u het model registreren dat is gemaakt op basis van de beste proefversie (configuratie die heeft geresulteerd in de beste primaire metrische gegevens). U kunt het model registreren nadat u het hebt gedownload of door het azureml-pad met de bijbehorende jobid op te geven. Opmerking: Wanneer u de deductie-instellingen wilt wijzigen die hieronder worden beschreven, moet u het model downloaden en settings.json wijzigen en registreren met behulp van de bijgewerkte modelmap.
Krijg de beste proefversie
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidige)
CLI example not available, please use Python SDK.
het model registreren
Registreer het model met behulp van het azureml-pad of uw lokaal gedownloade pad.
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidige)
az ml model create --name od-fridge-items-mlflow-model --version 1 --path azureml://jobs/$best_run/outputs/artifacts/outputs/mlflow-model/ --type mlflow_model --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Nadat u het model hebt geregistreerd dat u wilt gebruiken, kunt u het implementeren met behulp van het beheerde online-eindpunt deploy-managed-online-endpoint
Online-eindpunt configureren
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidige)
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: od-fridge-items-endpoint
auth_mode: key
Het eindpunt maken
Met behulp van de MLClient eerder gemaakte maken we het eindpunt in de werkruimte. Met deze opdracht wordt het maken van het eindpunt gestart en wordt een bevestigingsantwoord geretourneerd terwijl het maken van het eindpunt wordt voortgezet.
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidige)
az ml online-endpoint create --file .\create_endpoint.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Online-implementatie configureren
Een implementatie is een set resources die vereist is voor het hosten van het model dat de werkelijke deductie uitvoert. We maken een implementatie voor ons eindpunt met behulp van de ManagedOnlineDeployment klasse. U kunt GPU- of CPU-VM-SKU's gebruiken voor uw implementatiecluster.
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidige)
name: od-fridge-items-mlflow-deploy
endpoint_name: od-fridge-items-endpoint
model: azureml:od-fridge-items-mlflow-model@latest
instance_type: Standard_DS3_v2
instance_count: 1
liveness_probe:
failure_threshold: 30
success_threshold: 1
timeout: 2
period: 10
initial_delay: 2000
readiness_probe:
failure_threshold: 10
success_threshold: 1
timeout: 10
period: 10
initial_delay: 2000
De implementatie maken
Met behulp van de MLClient eerder gemaakte maken we nu de implementatie in de werkruimte. Met deze opdracht wordt het maken van de implementatie gestart en wordt er een bevestigingsantwoord geretourneerd terwijl de implementatie wordt gemaakt.
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidige)
az ml online-deployment create --file .\create_deployment.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
verkeer bijwerken:
De huidige implementatie is standaard ingesteld op 0% verkeer. u kunt instellen welk verkeerspercentage de huidige implementatie moet ontvangen. De som van de verkeerspercentages van alle implementaties met één eindpunt mag niet hoger zijn dan 100%.
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidige)
az ml online-endpoint update --name 'od-fridge-items-endpoint' --traffic 'od-fridge-items-mlflow-deploy=100' --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
U kunt het model ook implementeren vanuit de gebruikersinterface van Azure Machine Learning-studio. Navigeer naar het model dat u wilt implementeren op het tabblad Modellen van de geautomatiseerde ML-taak en selecteer implementeren en selecteer Implementeren in realtime-eindpunt .
 .
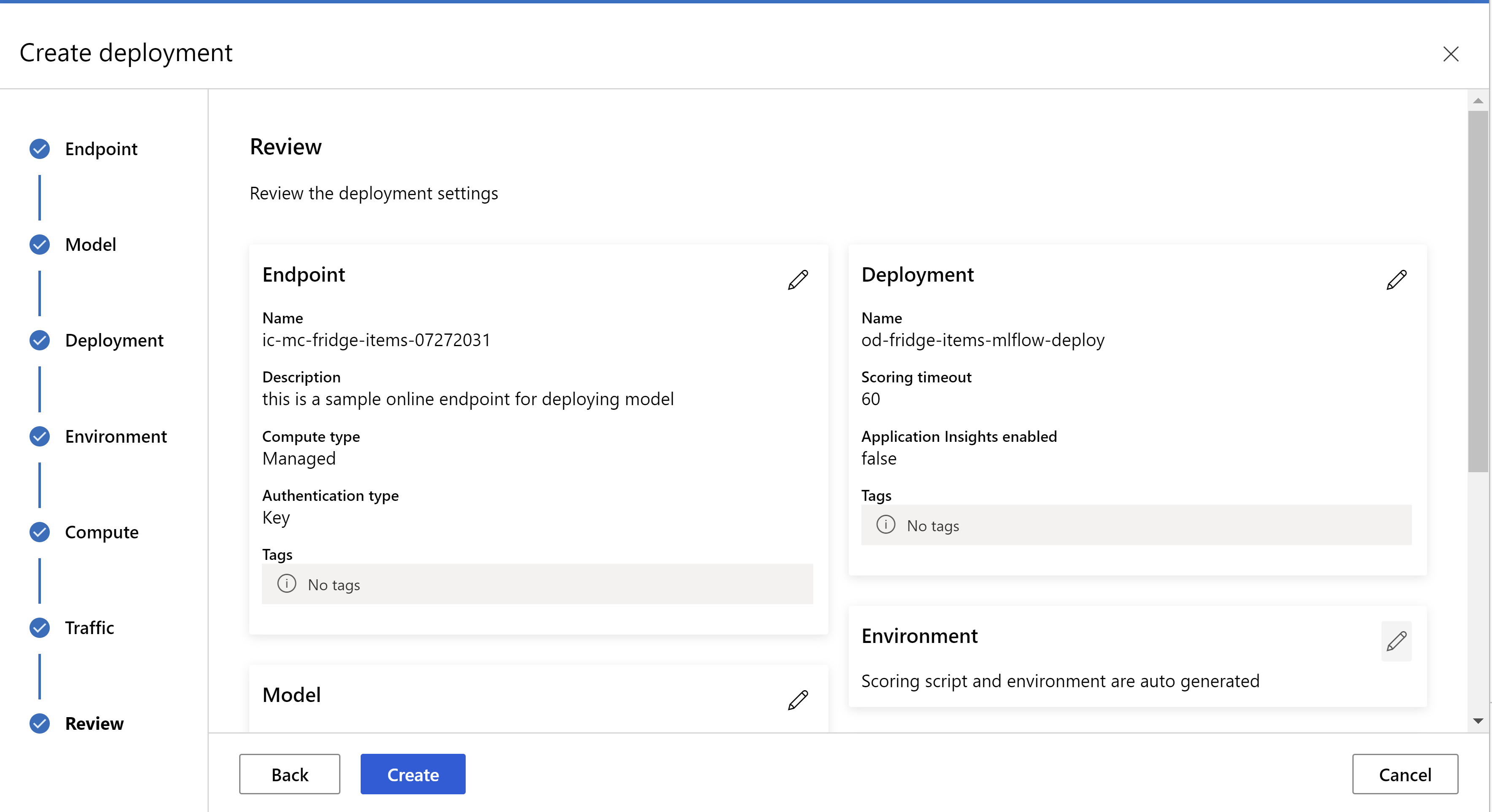
.
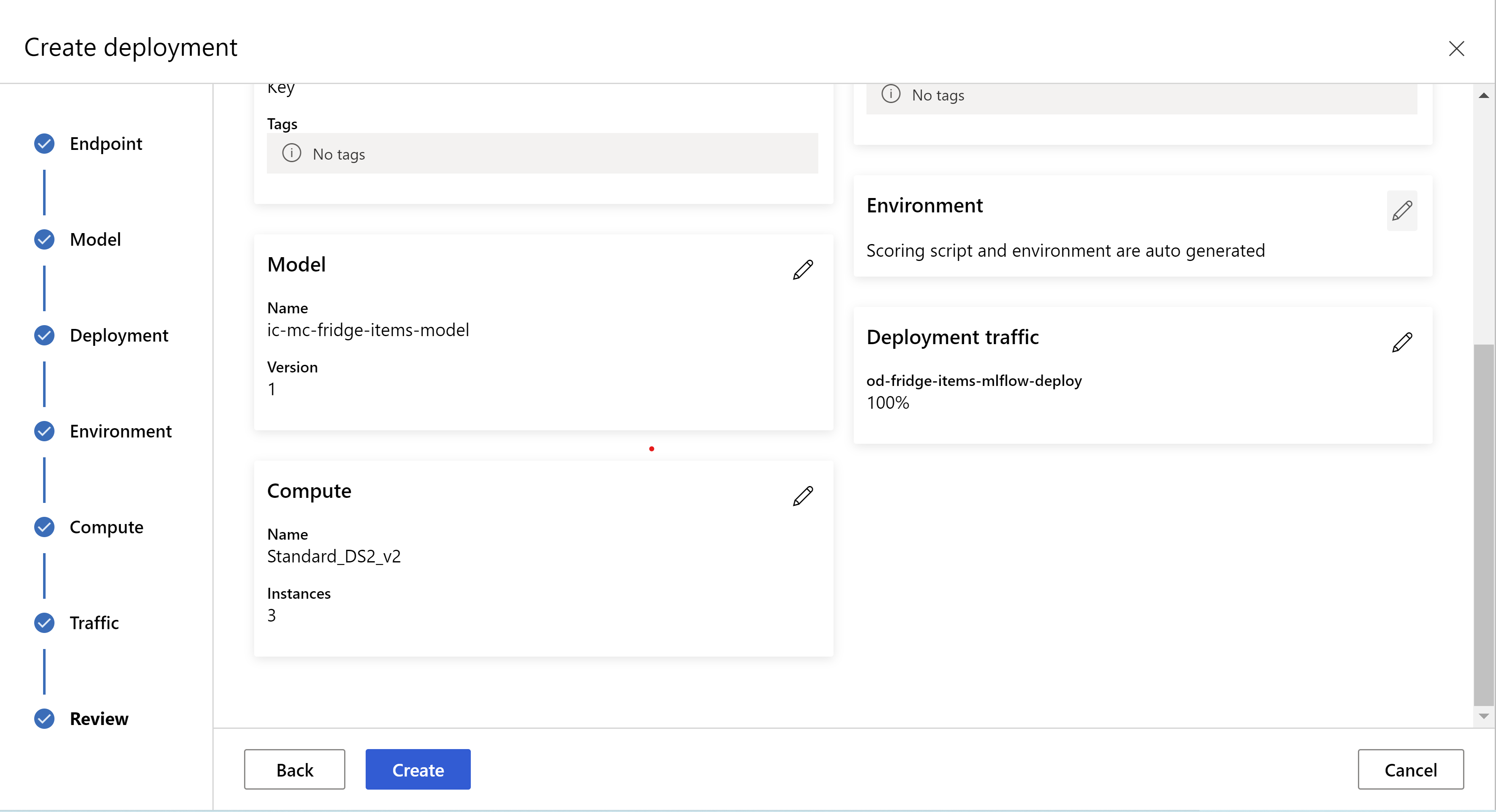
Zo ziet uw beoordelingspagina eruit. we kunnen het exemplaartype, het aantal exemplaren selecteren en het verkeerspercentage voor de huidige implementatie instellen.
 .
.
 .
.
Deductie-instellingen bijwerken
In de vorige stap hebben we een bestand mlflow-model/artifacts/settings.json gedownload van het beste model. die kan worden gebruikt om de deductie-instellingen bij te werken voordat u het model registreert. Hoewel het raadzaam is om dezelfde parameters te gebruiken als de training voor de beste prestaties.
Elk van de taken (en sommige modellen) heeft een set parameters. Standaard gebruiken we dezelfde waarden voor de parameters die zijn gebruikt tijdens de training en validatie. Afhankelijk van het gedrag dat we nodig hebben bij het gebruik van het model voor deductie, kunnen we deze parameters wijzigen. Hieronder vindt u een lijst met parameters voor elk taaktype en elk model.
| Opdracht | Parameternaam | Standaardinstelling |
|---|---|---|
| Afbeeldingsclassificatie (meerdere klassen en meerdere labels) | valid_resize_sizevalid_crop_size |
256 224 |
| Objectdetectie | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_img |
600 1333 0,3 0,5 100 |
Objectdetectie met yolov5 |
img_sizemodel_sizebox_score_threshnms_iou_thresh |
640 Normaal 0,1 0,5 |
| Instantiesegmentatie | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_imgmask_pixel_score_thresholdmax_number_of_polygon_pointsexport_as_imageimage_type |
600 1333 0,3 0,5 100 0,5 100 Onwaar JPG |
Raadpleeg Hyperparameters voor computer vision-taken in geautomatiseerde machine learning voor een gedetailleerde beschrijving van taakspecifieke hyperparameters.
Als u tiling wilt gebruiken en het gedrag van de tegel wilt beheren, zijn de volgende parameters beschikbaar: tile_grid_sizeen tile_overlap_ratiotile_predictions_nms_thresh. Raadpleeg een klein objectdetectiemodel trainen met Behulp van AutoML voor meer informatie over deze parameters.
De implementatie testen
Controleer deze sectie De implementatie testen om de implementatie te testen en de detecties van het model te visualiseren.
Uitleg genereren voor voorspellingen
Belangrijk
Deze instellingen zijn momenteel beschikbaar als openbare preview. Ze worden aangeboden zonder een service level agreement. Misschien worden bepaalde functies niet ondersteund of zijn de mogelijkheden ervan beperkt. Zie Aanvullende gebruiksvoorwaarden voor Microsoft Azure-previews voor meer informatie.
Waarschuwing
Model explainability wordt alleen ondersteund voor classificatie van meerdere klassen en classificatie met meerdere labels.
Enkele voordelen van het gebruik van Uitlegbare AI (XAI) met AutoML voor afbeeldingen:
- Verbetert de transparantie in de voorspellingen van het complexe vision-model
- Helpt de gebruikers om inzicht te krijgen in de belangrijke functies/pixels in de invoerafbeelding die bijdragen aan de modelvoorspellingen
- Helpt bij het oplossen van problemen met de modellen
- Helpt bij het detecteren van de vooroordelen
Uitleg
Uitleg zijn kenmerktoewijzingen of gewichten die aan elke pixel in de invoerafbeelding worden gegeven op basis van de bijdrage aan de voorspelling van het model. Elk gewicht kan negatief zijn (negatief gecorreleerd met de voorspelling) of positief (positief gecorreleerd met de voorspelling). Deze toeschrijvingen worden berekend op basis van de voorspelde klasse. Voor classificatie met meerdere klassen wordt per steekproef precies één toeschrijvingsmatrix van grootte [3, valid_crop_size, valid_crop_size] gegenereerd, terwijl voor classificatie met meerdere labels voor elke voorspelde label/klasse voor elke steekproef een toeschrijvingsmatrix van grootte [3, valid_crop_size, valid_crop_size] wordt gegenereerd.
Met behulp van uitlegbare AI in AutoML voor afbeeldingen op het geïmplementeerde eindpunt kunnen gebruikers visualisaties van uitleg krijgen (toeschrijvingen over een invoerafbeelding) en/of toeschrijvingen (multidimensionale matrix van grootte[3, valid_crop_size, valid_crop_size]) voor elke afbeelding. Naast visualisaties kunnen gebruikers ook toeschrijvingsmatrices krijgen om meer controle te krijgen over de uitleg (zoals het genereren van aangepaste visualisaties met behulp van toeschrijvingen of het onderzoeken van segmenten van toeschrijvingen). Alle uitlegalgoritmen maken gebruik van bijgesneden vierkante afbeeldingen met grootte valid_crop_size voor het genereren van toeschrijvingen.
Uitleg kan worden gegenereerd op basis van een online-eindpunt of batcheindpunt. Zodra de implementatie is voltooid, kan dit eindpunt worden gebruikt om de uitleg voor voorspellingen te genereren. Zorg ervoor dat u in onlineimplementaties de parameter ManagedOnlineDeployment doorgeeft request_settings = OnlineRequestSettings(request_timeout_ms=90000) aan en instelt request_timeout_ms op de maximale waarde om time-outproblemen te voorkomen tijdens het genereren van uitleg (raadpleeg de sectie Over het registreren en implementeren van modellen). Sommige XAI-methoden (explainability), zoals xrai het verbruiken van meer tijd (speciaal voor classificatie met meerdere labels, omdat we toewijzingen en/of visualisaties moeten genereren voor elk voorspeld label). Daarom raden we elk GPU-exemplaar aan voor snellere uitleg. Zie de schemadocumenten voor meer informatie over invoer- en uitvoerschema voor het genereren van uitleg.
We ondersteunen de volgende geavanceerde uitlegalgoritmen in AutoML voor afbeeldingen:
- XRAI (xrai)
- Geïntegreerde kleurovergangen (integrated_gradients)
- Begeleide GradCAM (guided_gradcam)
- Begeleide BackPropagation (guided_backprop)
In de volgende tabel worden de uitlegsalgoritmespecifieke afstemmingsparameters voor XRAI en Geïntegreerde kleurovergangen beschreven. Begeleide backpropagation en begeleide gradcam vereisen geen afstemmingsparameters.
| XAI-algoritme | Algoritmespecifieke parameters | Standaardwaarden |
|---|---|---|
xrai |
1. n_steps: Het aantal stappen dat door de benaderingsmethode wordt gebruikt. Een groter aantal stappen leidt tot betere benaderingen van toeschrijvingen (uitleg). Bereik van n_steps is [2, inf), maar de prestaties van toeschrijvingen beginnen na 50 stappen te convergeren. Optional, Int 2. xrai_fast: Of u een snellere versie van XRAI wilt gebruiken. als True, dan rekentijd voor uitleg sneller is, maar leidt tot minder nauwkeurige uitleg (toeschrijvingen) Optional, Bool |
n_steps = 50 xrai_fast = True |
integrated_gradients |
1. n_steps: Het aantal stappen dat door de benaderingsmethode wordt gebruikt. Een groter aantal stappen leidt tot betere toeschrijvingen (uitleg). Bereik van n_steps is [2, inf), maar de prestaties van toeschrijvingen beginnen na 50 stappen te convergeren.Optional, Int 2. approximation_method: Methode voor het benaderen van de integraal. Beschikbare methoden voor benadering zijn riemann_middle en gausslegendre.Optional, String |
n_steps = 50 approximation_method = riemann_middle |
Intern XRAI-algoritme maakt gebruik van geïntegreerde kleurovergangen.
n_steps Parameter is dus vereist voor zowel geïntegreerde kleurovergangen als XRAI-algoritmen. Een groter aantal stappen verbruikt meer tijd voor het benaderen van de uitleg en kan leiden tot time-outproblemen op het online-eindpunt.
We raden u aan om XRAI > Guided GradCAM > Integrated Gradients > Guided BackPropagation-algoritmen te gebruiken voor betere uitleg, terwijl Guided BackPropagation > Guided GradCAM > Integrated Gradients > XRAI wordt aanbevolen voor snellere uitleg in de opgegeven volgorde.
Een voorbeeldaanvraag voor het online-eindpunt ziet er als volgt uit. Met deze aanvraag worden verklaringen gegenereerd wanneer model_explainability deze is ingesteld op True. Met de volgende aanvraag worden visualisaties en toeschrijvingen gegenereerd met behulp van een snellere versie van het XRAI-algoritme met 50 stappen.
import base64
import json
def read_image(image_path):
with open(image_path, "rb") as f:
return f.read()
sample_image = "./test_image.jpg"
# Define explainability (XAI) parameters
model_explainability = True
xai_parameters = {"xai_algorithm": "xrai",
"n_steps": 50,
"xrai_fast": True,
"visualizations": True,
"attributions": True}
# Create request json
request_json = {"input_data": {"columns": ["image"],
"data": [json.dumps({"image_base64": base64.encodebytes(read_image(sample_image)).decode("utf-8"),
"model_explainability": model_explainability,
"xai_parameters": xai_parameters})],
}
}
request_file_name = "sample_request_data.json"
with open(request_file_name, "w") as request_file:
json.dump(request_json, request_file)
resp = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name=deployment.name,
request_file=request_file_name,
)
predictions = json.loads(resp)
Zie de GitHub Notebook-opslagplaats voor geautomatiseerde machine learning-voorbeelden voor meer informatie over het genereren van uitleg.
Visualisaties interpreteren
Geïmplementeerd eindpunt retourneert base64 gecodeerde afbeeldingstekenreeks als beide model_explainability en visualizations zijn ingesteld op True. De base64-tekenreeks decoderen zoals beschreven in notebooks of de volgende code gebruiken om de base64-afbeeldingstekenreeksen in de voorspelling te decoderen en te visualiseren.
import base64
from io import BytesIO
from PIL import Image
def base64_to_img(base64_img_str):
base64_img = base64_img_str.encode("utf-8")
decoded_img = base64.b64decode(base64_img)
return BytesIO(decoded_img).getvalue()
# For Multi-class classification:
# Decode and visualize base64 image string for explanations for first input image
# img_bytes = base64_to_img(predictions[0]["visualizations"])
# For Multi-label classification:
# Decode and visualize base64 image string for explanations for first input image against one of the classes
img_bytes = base64_to_img(predictions[0]["visualizations"][0])
image = Image.open(BytesIO(img_bytes))
In de volgende afbeelding wordt de visualisatie van uitleg voor een voorbeeldafbeelding beschreven.

De gecodeerde base64-afbeelding bevat vier afbeeldingssecties binnen een raster van 2 x 2.
- Afbeelding in de linkerbovenhoek (0, 0) is de bijgesneden invoerafbeelding
- Afbeelding in de rechterbovenhoek (0, 1) is de heatmap van toeschrijvingen op een kleurenschaal bgyw (blauw groen geel wit) waarbij de bijdrage van witte pixels aan de voorspelde klasse de hoogste en blauwe pixels de laagste is.
- Afbeelding linksonder (1, 0) is een gemengde heatmap met toewijzingen op bijgesneden invoerafbeelding
- Afbeelding rechtsonder (1, 1) is de bijgesneden invoerafbeelding met de bovenste 30 procent van de pixels op basis van toeschrijvingsscores.
Toeschrijvingen interpreteren
Geïmplementeerd eindpunt retourneert toeschrijvingen als beide model_explainabilityattributions zijn ingesteld op True. Raadpleeg voor meer informatie de notebooks voor classificaties van meerdere klassen en classificaties met meerdere labels.
Deze toeschrijvingen geven de gebruikers meer controle over het genereren van aangepaste visualisaties of het onderzoeken van scoren op pixelniveau. In het volgende codefragment wordt een manier beschreven om aangepaste visualisaties te genereren met behulp van een toeschrijvingsmatrix. Zie de schemadocumenten voor meer informatie over het schema van toeschrijvingen voor classificatie met meerdere klassen en classificatie met meerdere labels.
Gebruik de exacte valid_resize_size en valid_crop_size waarden van het geselecteerde model om de uitleg te genereren (standaardwaarden zijn respectievelijk 256 en 224). De volgende code maakt gebruik van de functionaliteit van Captum-visualisaties om aangepaste visualisaties te genereren. Gebruikers kunnen elke andere bibliotheek gebruiken om visualisaties te genereren. Raadpleeg de hulpprogramma's voor het visualiseren van captum voor meer informatie.
import colorcet as cc
import numpy as np
from captum.attr import visualization as viz
from PIL import Image
from torchvision import transforms
def get_common_valid_transforms(resize_to=256, crop_size=224):
return transforms.Compose([
transforms.Resize(resize_to),
transforms.CenterCrop(crop_size)
])
# Load the image
valid_resize_size = 256
valid_crop_size = 224
sample_image = "./test_image.jpg"
image = Image.open(sample_image)
# Perform common validation transforms to get the image used to generate attributions
common_transforms = get_common_valid_transforms(resize_to=valid_resize_size,
crop_size=valid_crop_size)
input_tensor = common_transforms(image)
# Convert output attributions to numpy array
# For Multi-class classification:
# Selecting attribution matrix for first input image
# attributions = np.array(predictions[0]["attributions"])
# For Multi-label classification:
# Selecting first attribution matrix against one of the classes for first input image
attributions = np.array(predictions[0]["attributions"][0])
# visualize results
viz.visualize_image_attr_multiple(np.transpose(attributions, (1, 2, 0)),
np.array(input_tensor),
["original_image", "blended_heat_map"],
["all", "absolute_value"],
show_colorbar=True,
cmap=cc.cm.bgyw,
titles=["original_image", "heatmap"],
fig_size=(12, 12))
Grote gegevenssets
Als u AutoML gebruikt om te trainen op grote gegevenssets, zijn er enkele experimentele instellingen die nuttig kunnen zijn.
Belangrijk
Deze instellingen zijn momenteel beschikbaar als openbare preview. Ze worden aangeboden zonder een service level agreement. Misschien worden bepaalde functies niet ondersteund of zijn de mogelijkheden ervan beperkt. Zie Aanvullende gebruiksvoorwaarden voor Microsoft Azure-previews voor meer informatie.
Training voor meerdere GPU's en meerdere knooppunten
Standaard traint elk model op één VIRTUELE machine. Als het trainen van een model te veel tijd in beslag neemt, kan het helpen om VM's te gebruiken die meerdere GPU's bevatten. De tijd voor het trainen van een model op grote gegevenssets moet ongeveer lineair afnemen ten opzichte van het aantal gebruikte GPU's. (Een model moet bijvoorbeeld ongeveer twee keer zo snel trainen op een VIRTUELE machine met twee GPU's als op een VIRTUELE machine met één GPU.) Als de tijd voor het trainen van een model nog steeds hoog is op een virtuele machine met meerdere GPU's, kunt u het aantal virtuele machines verhogen dat wordt gebruikt om elk model te trainen. Net als bij training met meerdere GPU's moet de tijd voor het trainen van een model op grote gegevenssets ook afnemen in ongeveer lineaire verhouding tot het aantal gebruikte VM's. Wanneer u een model traint op meerdere VM's, moet u een reken-SKU gebruiken die InfiniBand ondersteunt voor de beste resultaten. U kunt het aantal VIRTUELE machines configureren dat wordt gebruikt om één model te trainen door de node_count_per_trial eigenschap van de AutoML-taak in te stellen.
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidige)
properties:
node_count_per_trial: "2"
Afbeeldingsbestanden streamen vanuit opslag
Standaard worden alle afbeeldingsbestanden gedownload naar de schijf voorafgaand aan de modeltraining. Als de grootte van de afbeeldingsbestanden groter is dan de beschikbare schijfruimte, mislukt de taak. In plaats van alle installatiekopieën naar schijf te downloaden, kunt u ervoor kiezen om installatiekopieën vanuit Azure Storage te streamen wanneer ze nodig zijn tijdens de training. Afbeeldingsbestanden worden rechtstreeks vanuit Azure Storage naar het systeemgeheugen gestreamd, waardoor de schijf wordt overgeslagen. Tegelijkertijd worden zoveel mogelijk bestanden uit de opslag op de schijf opgeslagen om het aantal aanvragen voor opslag te minimaliseren.
Notitie
Als streaming is ingeschakeld, moet u ervoor zorgen dat het Azure-opslagaccount zich in dezelfde regio bevindt als de rekenkracht om de kosten en latentie te minimaliseren.
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidige)
training_parameters:
advanced_settings: >
{"stream_image_files": true}
Voorbeeldnotebooks
Bekijk gedetailleerde codevoorbeelden en gebruiksvoorbeelden in de GitHub notebookopslagplaats voor geautomatiseerde machine learning voorbeelden. Controleer de mappen met het voorvoegsel 'automl-image-' voor voorbeelden die specifiek zijn voor het bouwen van Computer Vision-modellen.
Codevoorbeelden
Bekijk gedetailleerde codevoorbeelden en gebruiksvoorbeelden in de opslagplaats met azureml-voorbeelden voor geautomatiseerde machine learning-voorbeelden.