AutoML instellen voor het trainen van een tijdreeksprognosemodel met Python (SDKv1)
VAN TOEPASSING OP: Python SDK azureml v1
Python SDK azureml v1
In dit artikel leert u hoe u AutoML-training instelt voor tijdreeksprognosemodellen met geautomatiseerde ML van Azure Machine Learning in de Azure Machine Learning Python SDK.
Dit doet u als volgt:
- Gegevens voorbereiden voor tijdreeksmodellering.
- Specifieke tijdreeksparameters in een
AutoMLConfigobject configureren. - Voorspellingen uitvoeren met tijdreeksgegevens.
Voor een ervaring met weinig code raadpleegt u de zelfstudie: Vraag voorspellen met geautomatiseerde machine learning voor een voorbeeld van een tijdreeksprognose met behulp van geautomatiseerde ML in de Azure Machine Learning-studio.
In tegenstelling tot klassieke tijdreeksmethoden worden in geautomatiseerde ML eerdere tijdreekswaarden 'pivoted' om extra dimensies te worden voor de regressor samen met andere voorspellingen. Deze benadering bevat meerdere contextuele variabelen en hun relatie met elkaar tijdens de training. Omdat meerdere factoren invloed kunnen hebben op een prognose, is deze methode goed afgestemd op scenario's voor het voorspellen van echte wereld. Wanneer u bijvoorbeeld verkoopprognoses, interacties van historische trends, wisselkoers en prijs samen het verkoopresultaat aanzet.
Vereisten
Voor dit artikel hebt u het volgende nodig:
Een Azure Machine Learning-werkruimte. Zie Werkruimtebronnen maken om de werkruimte te maken.
In dit artikel wordt ervan uitgegaan dat u bekend bent met het instellen van een geautomatiseerd machine learning-experiment. Volg de instructies om de belangrijkste ontwerppatronen voor geautomatiseerde machine learning-experimenten te bekijken.
Belangrijk
Voor de Python-opdrachten in dit artikel is de meest recente
azureml-train-automlpakketversie vereist.- Installeer het meest recente
azureml-train-automlpakket in uw lokale omgeving. - Zie de releaseopmerkingen voor meer informatie over het nieuwste
azureml-train-automlpakket.
- Installeer het meest recente
Trainings- en validatiegegevens
Het belangrijkste verschil tussen een prognose van het type regressietaak en het regressietaaktype in geautomatiseerde ML is het opnemen van een functie in uw trainingsgegevens die een geldige tijdreeks vertegenwoordigen. Een reguliere tijdreeks heeft een goed gedefinieerde en consistente frequentie en heeft een waarde op elk steekproefpunt in een doorlopende periode.
Belangrijk
Wanneer u een model traint voor het voorspellen van toekomstige waarden, moet u ervoor zorgen dat alle functies die in de training worden gebruikt, kunnen worden gebruikt bij het uitvoeren van voorspellingen voor uw beoogde horizon. Wanneer u bijvoorbeeld een vraagprognose maakt, inclusief een functie voor de huidige aandelenkoers, kan de nauwkeurigheid van de training enorm toenemen. Als u echter van plan bent om te voorspellen met een lange horizon, kunt u mogelijk niet nauwkeurig toekomstige aandelenwaarden voorspellen die overeenkomen met toekomstige tijdreekspunten en de nauwkeurigheid van het model kan lijden.
U kunt afzonderlijke trainingsgegevens en validatiegegevens rechtstreeks in het AutoMLConfig object opgeven. Meer informatie over de AutoMLConfig.
Voor tijdreeksprognoses wordt standaard alleen ROCV (Rolling Origin Cross Validation) gebruikt voor validatie. ROCV verdeelt de reeks in trainings- en validatiegegevens met behulp van een begintijdpunt. Als u de oorsprong in de tijd schuift, worden de kruisvalidatievouwen gegenereerd. Deze strategie behoudt de integriteit van tijdreeksgegevens en elimineert het risico op gegevenslekken.
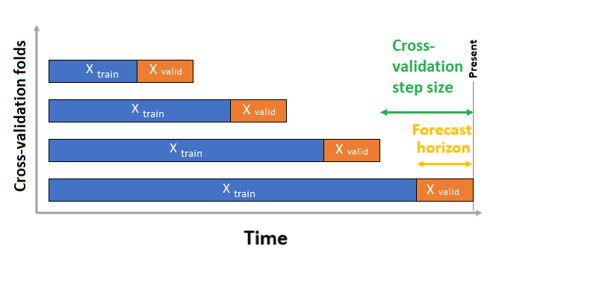
Geef uw trainings- en validatiegegevens door als één gegevensset aan de parameter training_data. Stel het aantal kruisvalidatievouwvouwen in met de parameter n_cross_validations en stel het aantal perioden tussen twee opeenvolgende kruisvalidatievouwen in met cv_step_size. U kunt parameters ook leeg laten en AutoML stelt ze automatisch in.
VAN TOEPASSING OP: Python SDK azureml v1
automl_config = AutoMLConfig(task='forecasting',
training_data= training_data,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
...
**time_series_settings)
U kunt ook uw eigen validatiegegevens gebruiken, meer informatie over het configureren van gegevenssplitsingen en kruisvalidatie in AutoML.
Meer informatie over hoe AutoML kruisvalidatie toepast om te voorkomen dat modellen te veel passen.
Experiment configureren
Het AutoMLConfig object definieert de instellingen en gegevens die nodig zijn voor een geautomatiseerde machine learning-taak. Configuratie voor een prognosemodel is vergelijkbaar met de installatie van een standaardregressiemodel, maar bepaalde modellen, configuratieopties en featurization-stappen bestaan specifiek voor tijdreeksgegevens.
Ondersteunde modellen
Geautomatiseerde machine learning probeert automatisch verschillende modellen en algoritmen als onderdeel van het proces voor het maken en afstemmen van het model. Als gebruiker hoeft u het algoritme niet op te geven. Voor voorspellingsexperimenten maken zowel systeemeigen tijdreeks- als Deep Learning-modellen deel uit van het aanbevelingssysteem.
Tip
Traditionele regressiemodellen worden ook getest als onderdeel van het aanbevelingssysteem voor het voorspellen van experimenten. Bekijk een volledige lijst met de ondersteunde modellen in de SDK-referentiedocumentatie.
Configuratie-instellingen
Net als bij een regressieprobleem definieert u standaardtrainingsparameters zoals taaktype, aantal iteraties, trainingsgegevens en het aantal kruisvalidaties. Voor prognosetaken zijn de time_column_name en forecast_horizon parameters vereist om uw experiment te configureren. Als de gegevens meerdere tijdreeksen bevatten, zoals verkoopgegevens voor meerdere winkels of energiegegevens in verschillende statussen, detecteert geautomatiseerde ML dit automatisch en stelt de time_series_id_column_names parameter (preview) voor u in. U kunt ook aanvullende parameters opnemen om uw uitvoering beter te configureren. Zie de sectie optionele configuraties voor meer informatie over wat er kan worden opgenomen.
Belangrijk
Automatische identificatie van tijdreeksen is momenteel beschikbaar als openbare preview. Deze preview-versie wordt geleverd zonder een service level agreement. Misschien worden bepaalde functies niet ondersteund of zijn de mogelijkheden ervan beperkt. Zie Aanvullende gebruiksvoorwaarden voor Microsoft Azure-previews voor meer informatie.
| Parameternaam | Beschrijving |
|---|---|
time_column_name |
Wordt gebruikt om de datum/tijd-kolom op te geven in de invoergegevens die worden gebruikt voor het bouwen van de tijdreeks en het uitstellen van de frequentie. |
forecast_horizon |
Hiermee definieert u hoeveel perioden u wilt voorspellen. De horizon bevindt zich in eenheden van de tijdreeksfrequentie. Eenheden zijn gebaseerd op het tijdsinterval van uw trainingsgegevens, bijvoorbeeld maandelijks, wekelijks dat de prognose moet voorspellen. |
De volgende code,
- Gebruikt de
ForecastingParametersklasse om de prognoseparameters voor uw experimenttraining te definiëren - Hiermee stelt u het
time_column_nameday_datetimeveld in de gegevensset in. - Hiermee stelt u de
forecast_horizonop 50 in om te voorspellen voor de hele testset.
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecasting_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
freq='W')
Deze forecasting_parameters worden vervolgens doorgegeven aan uw standaardobject AutoMLConfig , samen met het forecasting taaktype, primaire metrische gegevens, afsluitcriteria en trainingsgegevens.
from azureml.core.workspace import Workspace
from azureml.core.experiment import Experiment
from azureml.train.automl import AutoMLConfig
import logging
automl_config = AutoMLConfig(task='forecasting',
primary_metric='normalized_root_mean_squared_error',
experiment_timeout_minutes=15,
enable_early_stopping=True,
training_data=train_data,
label_column_name=label,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
enable_ensembling=False,
verbosity=logging.INFO,
forecasting_parameters=forecasting_parameters)
De hoeveelheid gegevens die nodig is om een prognosemodel met geautomatiseerde ML te trainen, wordt beïnvloed door de forecast_horizon, n_cross_validationsen target_lags of target_rolling_window_size waarden die zijn opgegeven bij het configureren van uw AutoMLConfig.
Met de volgende formule wordt de hoeveelheid historische gegevens berekend die nodig is om tijdreeksfuncties te maken.
Minimale historische gegevens vereist: (2x forecast_horizon) + # +n_cross_validations max(max(target_lags), target_rolling_window_size)
Er Error exception wordt een gegenereerd voor een reeks in de gegevensset die niet voldoet aan de vereiste hoeveelheid historische gegevens voor de opgegeven relevante instellingen.
Stappen voor featurisatie
In elk geautomatiseerd machine learning-experiment worden automatisch schalen en normalisatietechnieken standaard toegepast op uw gegevens. Deze technieken zijn soorten featurization die bepaalde algoritmen helpen die gevoelig zijn voor functies op verschillende schalen. Meer informatie over standaard-featurisatiestappen in Featurization in AutoML
De volgende stappen worden echter alleen uitgevoerd voor forecasting taaktypen:
- Detecteer voorbeeldfrequentie van tijdreeksen (bijvoorbeeld elk uur, dagelijks, wekelijks) en maak nieuwe records voor ontbrekende tijdpunten om de reeks continu te maken.
- Ontbrekende waarden in het doel invoeren (via doorsturen) en functiekolommen (met behulp van mediaankolomwaarden)
- Functies maken op basis van tijdreeks-id's om vaste effecten in verschillende reeksen mogelijk te maken
- Op tijd gebaseerde functies maken om seizoensgebonden patronen te leren
- Categorische variabelen coderen naar numerieke hoeveelheden
- Detecteer de niet-stationaire tijdreeks en differentiëren ze automatisch om de impact van eenheidswortels te beperken.
Zie TimeIndexFeaturizer Class voor een volledige lijst met mogelijke functies die zijn gegenereerd op basis van tijdreeksgegevens.
Notitie
Geautomatiseerde machine learning-featurisatiestappen (functienormalisatie, verwerking van ontbrekende gegevens, het converteren van tekst naar numeriek, enzovoort) worden onderdeel van het onderliggende model. Wanneer u het model voor voorspellingen gebruikt, worden dezelfde featurization-stappen die tijdens de training worden toegepast, automatisch toegepast op uw invoergegevens.
Featurization aanpassen
U hebt ook de mogelijkheid om uw featurization-instellingen aan te passen om ervoor te zorgen dat de gegevens en functies die worden gebruikt om uw ML-model te trainen, resulteren in relevante voorspellingen.
Ondersteunde aanpassingen voor forecasting taken zijn onder andere:
| Aanpassing | Definitie |
|---|---|
| Update van kolomdoel | Overschrijf het automatisch gedetecteerde functietype voor de opgegeven kolom. |
| Parameterupdate voor transformatieprogramma | Werk de parameters voor de opgegeven transformator bij. Ondersteunt momenteel Imputer (fill_value en mediaan). |
| Kolommen neerzetten | Hiermee geeft u kolommen die moeten worden neergezet van worden gemetraliseerd. |
Als u featurizations wilt aanpassen met de SDK, geeft u "featurization": FeaturizationConfig dit op in uw AutoMLConfig object. Meer informatie over aangepaste featurizations.
Notitie
De functionaliteit voor neerzetkolommen is afgeschaft vanaf SDK-versie 1.19. Verwijder kolommen uit uw gegevensset als onderdeel van het opschonen van gegevens voordat u deze in uw geautomatiseerde ML-experiment gebruikt.
featurization_config = FeaturizationConfig()
# `logQuantity` is a leaky feature, so we remove it.
featurization_config.drop_columns = ['logQuantitity']
# Force the CPWVOL5 feature to be of numeric type.
featurization_config.add_column_purpose('CPWVOL5', 'Numeric')
# Fill missing values in the target column, Quantity, with zeroes.
featurization_config.add_transformer_params('Imputer', ['Quantity'], {"strategy": "constant", "fill_value": 0})
# Fill mising values in the `INCOME` column with median value.
featurization_config.add_transformer_params('Imputer', ['INCOME'], {"strategy": "median"})
Als u de Azure Machine Learning-studio voor uw experiment gebruikt, raadpleegt u hoe u featurization kunt aanpassen in de studio.
Optionele configuraties
Er zijn meer optionele configuraties beschikbaar voor het voorspellen van taken, zoals het inschakelen van deep learning en het opgeven van een doel-aggregatie van rolling vensters. Er is een volledige lijst met meer parameters beschikbaar in de referentiedocumentatie voor de ForecastingParameters SDK.
Frequentie en doelgegevensaggregatie
Gebruik de frequentie, freqde parameter om fouten te voorkomen die worden veroorzaakt door onregelmatige gegevens. Onregelmatige gegevens bevatten gegevens die geen vaste frequentie volgen, zoals uur- of daggegevens.
Voor zeer onregelmatige gegevens of voor verschillende zakelijke behoeften kunnen gebruikers desgewenst hun gewenste prognosefrequentie freqinstellen en de target_aggregation_function doelkolom van de tijdreeks aggregeren. Gebruik deze twee instellingen in uw AutoMLConfig object om tijd te besparen bij het voorbereiden van gegevens.
Ondersteunde aggregatiebewerkingen voor doelkolomwaarden zijn:
| Functie | Beschrijving |
|---|---|
sum |
Som van doelwaarden |
mean |
Gemiddelde of gemiddelde van doelwaarden |
min |
Minimumwaarde van een doel |
max |
Maximumwaarde van een doel |
Deep Learning inschakelen
Notitie
DNN-ondersteuning voor prognoses in Geautomatiseerde machine learning is in preview en wordt niet ondersteund voor lokale uitvoeringen of uitvoeringen die zijn geïnitieerd in Databricks.
U kunt deep learning ook toepassen met deep neurale netwerken, DNN's, om de scores van uw model te verbeteren. Met deep learning van geautomatiseerde ML kunt u univariate en multivariate tijdreeksgegevens voorspellen.
Deep Learning-modellen hebben drie intrinsieke mogelijkheden:
- Ze kunnen leren van willekeurige toewijzingen van invoer naar uitvoer
- Ze ondersteunen meerdere invoer- en uitvoerwaarden
- Ze kunnen automatisch patronen extraheren in invoergegevens die over lange reeksen bestaan.
Als u Deep Learning wilt inschakelen, stelt u het enable_dnn=True in het AutoMLConfig object in.
automl_config = AutoMLConfig(task='forecasting',
enable_dnn=True,
...
forecasting_parameters=forecasting_parameters)
Waarschuwing
Wanneer u DNN inschakelt voor experimenten die zijn gemaakt met de SDK, worden de beste modeluitlegen uitgeschakeld.
Als u DNN wilt inschakelen voor een AutoML-experiment dat is gemaakt in de Azure Machine Learning-studio, raadpleegt u de taaktype-instellingen in de gebruikersinterface van studio.
Aggregatie van doelvensters
Vaak is de beste informatie voor een prognose de recente waarde van het doel. Met aggregaties voor rolling vensters kunt u een rolling aggregatie van gegevenswaarden toevoegen als functies. Het genereren en gebruiken van deze functies als extra contextuele gegevens helpt bij de nauwkeurigheid van het trainmodel.
Stel dat u de vraag naar energie wilt voorspellen. U kunt een doorlopende vensterfunctie van drie dagen toevoegen om rekening te houden met thermische veranderingen in verwarmde ruimten. In dit voorbeeld maakt u dit venster door het in te stellen target_rolling_window_size= 3 in de AutoMLConfig constructor.
In de tabel ziet u de resulterende functie-engineering die optreedt wanneer vensteraggregatie wordt toegepast. Kolommen voor minimum, maximum en som worden gegenereerd in een schuifvenster van drie op basis van de gedefinieerde instellingen. Elke rij heeft een nieuwe berekende functie, in het geval van de tijdstempel voor 8 september 2017 4:00 uur de maximum-, minimum- en somwaarden worden berekend met behulp van de vraagwaarden voor 8 september 2017 1:00 - 3:00 uur. Dit venster van drie diensten om gegevens voor de resterende rijen in te vullen.

Bekijk een Voorbeeld van Python-code voor het toepassen van de statistische doelfunctie voor rolling windows.
Verwerking van korte reeksen
Geautomatiseerde ML beschouwt een tijdreeks in een korte reeks als er onvoldoende gegevenspunten zijn om de train- en validatiefasen van modelontwikkeling uit te voeren. Het aantal gegevenspunten varieert voor elk experiment en is afhankelijk van de max_horizon, het aantal kruisvalidatiesplitsingen en de lengte van de modelzoekactie. Dit is het maximum aan geschiedenis dat nodig is om de tijdreeksfuncties te maken.
Geautomatiseerde ML biedt standaard verwerking van korte reeksen met de short_series_handling_configuration parameter in het ForecastingParameters object.
Als u de verwerking van korte reeksen wilt inschakelen, moet de freq parameter ook worden gedefinieerd. Als u een frequentie per uur wilt definiëren, stellen we deze in freq='H'. Bekijk de opties voor frequentiereeksen door naar de sectie DataOffset-objecten van de pandas-tijdreekspagina te gaan. Als u het standaardgedrag wilt wijzigen, short_series_handling_configuration = 'auto'werkt u de short_series_handling_configuration parameter in uw ForecastingParameter object bij.
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecast_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
short_series_handling_configuration='auto',
freq = 'H',
target_lags='auto')
De volgende tabel bevat een overzicht van de beschikbare instellingen voor short_series_handling_config.
| Instelling | Beschrijving |
|---|---|
auto |
De standaardwaarde voor het verwerken van korte reeksen. - Als alle reeksen kort zijn, vult u de gegevens in. - Als niet alle reeksen kort zijn, zet u de korte reeks neer. |
pad |
Als short_series_handling_config = pad, dan voegt geautomatiseerde ML willekeurige waarden toe aan elke korte reeks gevonden. Hieronder ziet u de kolomtypen en waarmee ze zijn opgevuld: - Objectkolommen met NaN's - Numerieke kolommen met 0 - Booleaanse/logische kolommen met Onwaar - De doelkolom wordt gevuld met willekeurige waarden met het gemiddelde van nul en de standaarddeviatie van 1. |
drop |
Als short_series_handling_config = dropgeautomatiseerde ML de korte reeks afneemt en deze niet wordt gebruikt voor training of voorspelling. Voorspellingen voor deze reeks retourneren NaN's. |
None |
Er is geen reeks opgevuld of verwijderd |
Waarschuwing
Opvulling kan van invloed zijn op de nauwkeurigheid van het resulterende model, omdat we kunstmatige gegevens introduceren om eerdere training zonder fouten te krijgen. Als veel van de reeks kort zijn, ziet u mogelijk ook enige impact in de resultaten van de uitlegbaarheid
Detectie en verwerking van niet-stationaire tijdreeksen
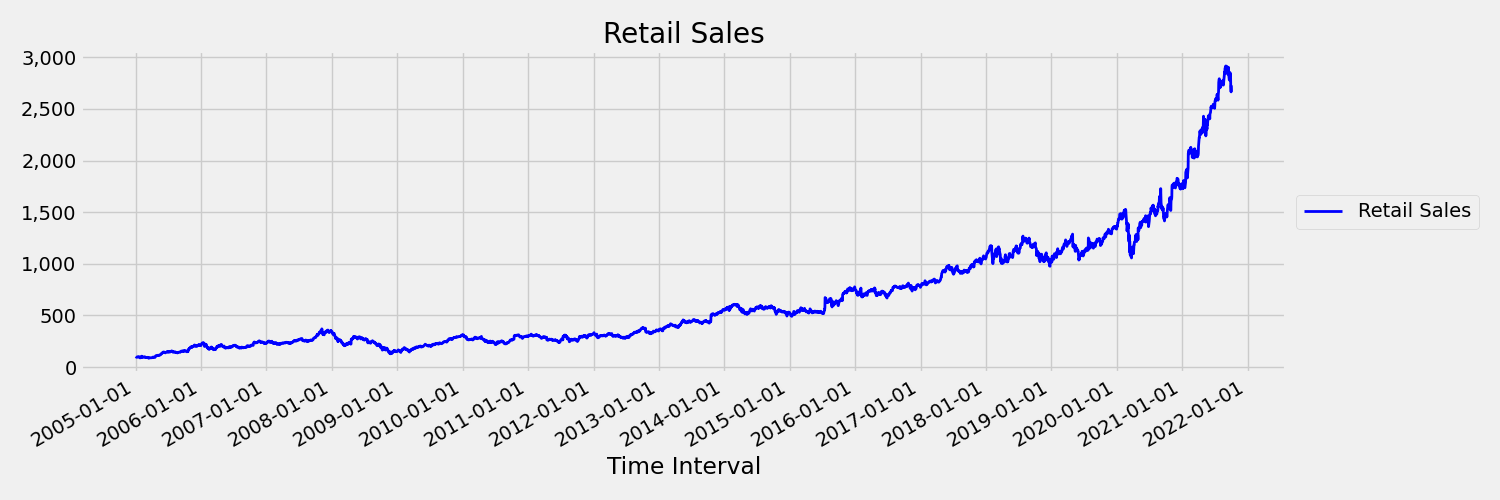
Een tijdreeks waarvan de momenten (gemiddelde en variantie) in de loop van de tijd veranderen, wordt een niet-stationair genoemd. Tijdreeksen die stochastische trends vertonen, zijn bijvoorbeeld niet-stationair van aard. Om dit te visualiseren, plot de onderstaande afbeelding een reeks die over het algemeen naar boven gaat. Bereken en vergelijk nu de gemiddelde (gemiddelde) waarden voor de eerste en de tweede helft van de reeks. Zijn ze hetzelfde? Hier is het gemiddelde van de reeks in de eerste helft van de plot kleiner dan in de tweede helft. Het feit dat het gemiddelde van de reeks afhankelijk is van het tijdsinterval dat men bekijkt, is een voorbeeld van de tijdsafhankelijke momenten. Hier is het gemiddelde van een reeks het eerste moment.
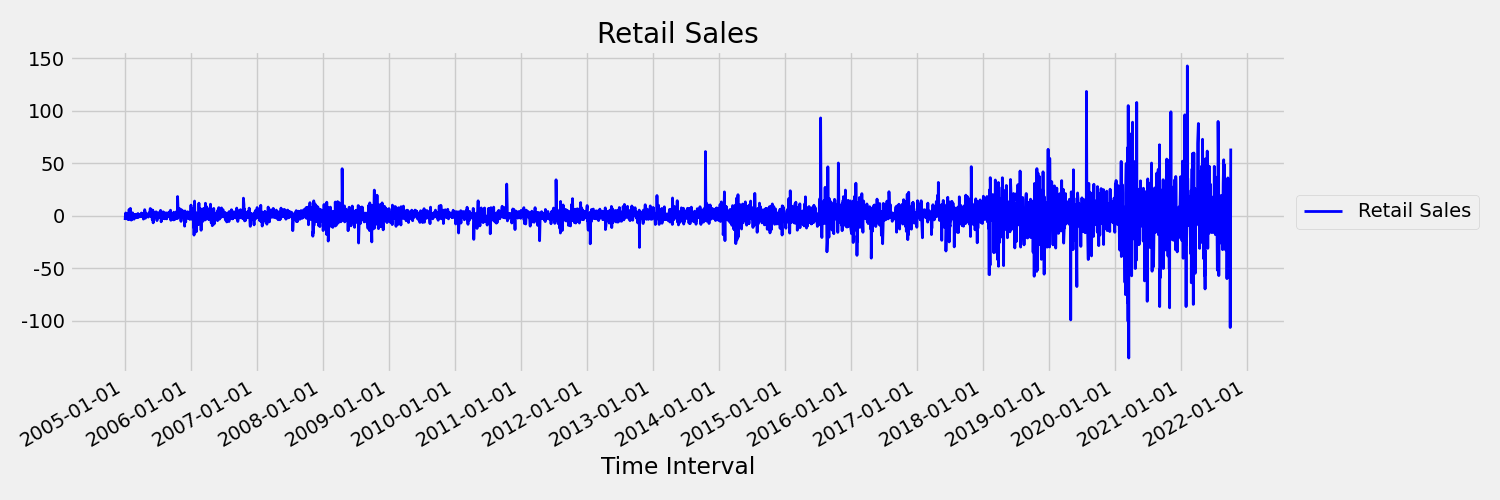
Laten we vervolgens de afbeelding bekijken, die de oorspronkelijke reeks in eerste verschillen uitzet, $x_t = y_t - y_{t-1}$ waarbij $x_t$ de wijziging is in de verkoop van de detailhandel en $y_t$ en $y_{t-1}$ de oorspronkelijke reeks en de eerste vertraging vertegenwoordigen. Het gemiddelde van de reeks is ruwweg constant, ongeacht het tijdsbestek dat men bekijkt. Dit is een voorbeeld van een eerste order stationaire tijdreeks. De reden dat we de eerste orderterm hebben toegevoegd, is omdat het eerste moment (gemiddelde) niet verandert met tijdsinterval, hetzelfde kan niet worden gezegd over de variantie, wat een tweede moment is.
AutoML Machine Learning-modellen kunnen niet inherent omgaan met stochastische trends of andere bekende problemen die verband houden met niet-stationaire tijdreeksen. Als gevolg hiervan is de nauwkeurigheid van de steekproefprognose 'slecht' als dergelijke trends aanwezig zijn.
AutoML analyseert automatisch de tijdreeksgegevensset om te controleren of deze stationair is of niet. Wanneer niet-stationaire tijdreeksen worden gedetecteerd, past AutoML automatisch een differentiërende transformatie toe om het effect van niet-stationaire tijdreeksen te beperken.
Het experiment uitvoeren.
Wanneer u het AutoMLConfig object gereed hebt, kunt u het experiment indienen. Nadat het model is voltooid, haalt u de best uitgevoerde iteratie op.
ws = Workspace.from_config()
experiment = Experiment(ws, "Tutorial-automl-forecasting")
local_run = experiment.submit(automl_config, show_output=True)
best_run, fitted_model = local_run.get_output()
Prognoses met het beste model
Gebruik de beste modeliteratie om waarden te voorspellen voor gegevens die niet zijn gebruikt om het model te trainen.
Modelnauwkeurigheid evalueren met een rolling prognose
Voordat u een model in productie neemt, moet u de nauwkeurigheid ervan evalueren op een testset die uit de trainingsgegevens blijkt. Een best practice procedure is een zogenaamde rolling evaluatie, waarmee de getrainde prognose in de loop van de tijd over de testset wordt gerold, metrische gegevens over gemiddelden van fouten in verschillende voorspellingsvensters om statistisch robuuste schattingen te verkrijgen voor een aantal gekozen metrische gegevens. In het ideale opzicht is de testset voor de evaluatie lang ten opzichte van de horizon van de prognose van het model. Schattingen van voorspellingsfouten kunnen anders statistisch luidruchtig zijn en daarom minder betrouwbaar.
Stel dat u een model traint op dagelijkse verkoop om de vraag tot twee weken (14 dagen) in de toekomst te voorspellen. Als er voldoende historische gegevens beschikbaar zijn, kunt u de laatste maanden reserveren tot zelfs een jaar van de gegevens voor de testset. De rolling evaluatie begint met het genereren van een 14-daagse prognose voor de eerste twee weken van de testset. Vervolgens wordt de prognose met een aantal dagen in de testset gevorderd en genereert u nog een 14-daagse prognose vanaf de nieuwe positie. Het proces wordt voortgezet totdat u aan het einde van de testset komt.
Als u een doorlopende evaluatie wilt uitvoeren, roept u de rolling_forecast methode van de fitted_modelaan en berekent u vervolgens de gewenste metrische gegevens over het resultaat. Stel dat u testsetfuncties hebt in een pandas DataFrame aangeroepen test_features_df en dat de testset werkelijke waarden van het doel bevat in een numpymatrix met de naam test_target. Een rolling evaluatie met behulp van de gemiddelde kwadratische fout wordt weergegeven in het volgende codevoorbeeld:
from sklearn.metrics import mean_squared_error
rolling_forecast_df = fitted_model.rolling_forecast(
test_features_df, test_target, step=1)
mse = mean_squared_error(
rolling_forecast_df[fitted_model.actual_column_name], rolling_forecast_df[fitted_model.forecast_column_name])
In dit voorbeeld is de stapgrootte voor de rolling prognose ingesteld op één, wat betekent dat de prognose één periode of één dag in ons voorbeeld van de vraagvoorspelling is ingesteld op elke iteratie. Het totale aantal prognoses dat wordt geretourneerd, rolling_forecast is dus afhankelijk van de lengte van de testset en deze stapgrootte. Zie de documentatie rolling_forecast() en de prognose weg van het notitieblok voor trainingsgegevens voor meer informatie en voorbeelden.
Voorspelling in de toekomst
De functie forecast_quantiles() staat specificaties toe van wanneer voorspellingen moeten worden gestart, in tegenstelling tot de predict() methode, die doorgaans wordt gebruikt voor classificatie- en regressietaken. De methode forecast_quantiles() genereert standaard een puntprognose of een gemiddelde/mediaanprognose, die geen kegel van onzekerheid heeft. Meer informatie vindt u in de prognose weg van het notitieblok voor trainingsgegevens.
In het volgende voorbeeld vervangt u eerst alle waarden door y_pred NaN. De oorsprong van de prognose bevindt zich aan het einde van de trainingsgegevens in dit geval. Als u echter slechts de tweede helft van y_pred het NaNgetal hebt vervangen, blijven de numerieke waarden in de eerste helft ongewijzigd, maar worden de NaN waarden in de tweede helft voorspeld. De functie retourneert zowel de voorspelde waarden als de uitgelijnde functies.
U kunt de forecast_destination parameter in de forecast_quantiles() functie ook gebruiken om waarden tot een opgegeven datum te voorspellen.
label_query = test_labels.copy().astype(np.float)
label_query.fill(np.nan)
label_fcst, data_trans = fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
Vaak willen klanten de voorspellingen op een specifiek kwantiel van de distributie begrijpen. Wanneer de prognose bijvoorbeeld wordt gebruikt voor het beheren van voorraad, zoals boodschappenartikelen of virtuele machines voor een cloudservice. In dergelijke gevallen is het controlepunt meestal iets als 'we willen dat het item op voorraad is en niet 99% van de tijd oploopt'. Hieronder ziet u hoe u opgeeft welke kwantielen u wilt zien voor uw voorspellingen, zoals 50e of 95e percentiel. Als u geen kwantiel opgeeft, zoals in het bovenstaande codevoorbeeld, worden alleen de 50e percentielvoorspellingen gegenereerd.
# specify which quantiles you would like
fitted_model.quantiles = [0.05,0.5, 0.9]
fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
U kunt metrische modelgegevens berekenen, zoals rmSE (root mean squared error) of gemiddelde absolute percentagefout (MAPE) om u te helpen de prestaties van modellen te schatten. Zie de sectie Evalueren van het notitieblok fietsshares voor een voorbeeld.
Nadat de algehele nauwkeurigheid van het model is vastgesteld, is de meest realistische volgende stap het gebruik van het model om onbekende toekomstige waarden te voorspellen.
Geef een gegevensset op in dezelfde indeling als de testset test_dataset , maar met toekomstige datum/tijd, en de resulterende voorspellingsset zijn de voorspelde waarden voor elke tijdreeksstap. Stel dat de laatste tijdreeksrecords in de gegevensset 12-31-2018 waren. Als u de vraag voor de volgende dag wilt voorspellen (of zo veel perioden als u moet voorspellen, <= forecast_horizon), maakt u één record voor een tijdreeks voor elke winkel voor 01/01/2019.
day_datetime,store,week_of_year
01/01/2019,A,1
01/01/2019,A,1
Herhaal de benodigde stappen om deze toekomstige gegevens in een dataframe te laden en vervolgens uit te voeren best_run.forecast_quantiles(test_dataset) om toekomstige waarden te voorspellen.
Notitie
In-sample voorspellingen worden niet ondersteund voor prognoses met geautomatiseerde ML wanneer target_lags en/of target_rolling_window_size zijn ingeschakeld.
Prognose op schaal
Er zijn scenario's waarin één machine learning-model onvoldoende is en er meerdere machine learning-modellen nodig zijn. Bijvoorbeeld het voorspellen van de verkoop voor elke afzonderlijke winkel voor een merk of het aanpassen van een ervaring aan individuele gebruikers. Het bouwen van een model voor elk exemplaar kan leiden tot verbeterde resultaten op veel machine learning-problemen.
Groeperen is een concept in tijdreeksprognoses waarmee tijdreeksen kunnen worden gecombineerd om een afzonderlijk model per groep te trainen. Deze benadering kan met name handig zijn als u tijdreeksen hebt waarvoor het soepeler maken, vullen of entiteiten in de groep nodig zijn dat kan profiteren van geschiedenis of trends van andere entiteiten. Veel modellen en hiërarchische tijdreeksprognoses zijn oplossingen die worden mogelijk gemaakt door geautomatiseerde machine learning voor deze grootschalige prognosescenario's.
Veel modellen
Met de Azure Machine Learning-oplossing voor veel modellen met geautomatiseerde machine learning kunnen gebruikers miljoenen modellen parallel trainen en beheren. Veel modellen De oplossingsversneller maakt gebruik van Azure Machine Learning-pijplijnen om het model te trainen. Een pijplijnobject en ParalleRunStep worden gebruikt en vereisen specifieke configuratieparameters die zijn ingesteld via ParallelRunConfig.
In het volgende diagram ziet u de werkstroom voor de vele modellenoplossing.

De volgende code laat zien welke belangrijke parameters gebruikers nodig hebben om hun vele modellen uit te voeren. Zie het voorbeeld van het voorspellen van veel modellen- geautomatiseerde ML-notebook voor een groot aantal modellen
from azureml.train.automl.runtime._many_models.many_models_parameters import ManyModelsTrainParameters
partition_column_names = ['Store', 'Brand']
automl_settings = {"task" : 'forecasting',
"primary_metric" : 'normalized_root_mean_squared_error',
"iteration_timeout_minutes" : 10, #This needs to be changed based on the dataset. Explore how long training is taking before setting this value
"iterations" : 15,
"experiment_timeout_hours" : 1,
"label_column_name" : 'Quantity',
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
"time_column_name": 'WeekStarting',
"max_horizon" : 6,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,}
mm_paramters = ManyModelsTrainParameters(automl_settings=automl_settings, partition_column_names=partition_column_names)
Hiërarchische tijdreeksprognoses
In de meeste toepassingen hebben klanten behoefte aan inzicht in hun prognoses op macro- en microniveau van het bedrijf. Prognoses kunnen de verkoop van producten op verschillende geografische locaties voorspellen of inzicht krijgen in de verwachte vraag van werknemers naar verschillende organisaties in een bedrijf. De mogelijkheid om een machine learning-model te trainen om op intelligente wijze hiërarchiegegevens te voorspellen, is essentieel.
Een hiërarchische tijdreeks is een structuur waarin elk van de unieke reeksen wordt gerangschikt in een hiërarchie op basis van dimensies zoals geografie of producttype. In het volgende voorbeeld ziet u gegevens met unieke kenmerken die een hiërarchie vormen. Onze hiërarchie wordt gedefinieerd door: het producttype, zoals hoofdtelefoons of tablets, de productcategorie, die producttypen splitst in accessoires en apparaten, en de regio waarin de producten worden verkocht.

Om dit verder te visualiseren, bevatten de bladniveaus van de hiërarchie alle tijdreeksen met unieke combinaties van kenmerkwaarden. Elk hoger niveau in de hiërarchie beschouwt één minder dimensie voor het definiëren van de tijdreeks en voegt elke set onderliggende knooppunten van het lagere niveau samen in een bovenliggend knooppunt.

De hiërarchische oplossing voor tijdreeksen is gebouwd boven op de oplossing Veel modellen en deelt een vergelijkbare configuratie-instelling.
De volgende code toont de belangrijkste parameters voor het instellen van uw hiërarchische tijdreeksprognoses. Zie de hiërarchische tijdreeks: geautomatiseerd ML-notebook voor een end-to-end-voorbeeld.
from azureml.train.automl.runtime._hts.hts_parameters import HTSTrainParameters
model_explainability = True
engineered_explanations = False # Define your hierarchy. Adjust the settings below based on your dataset.
hierarchy = ["state", "store_id", "product_category", "SKU"]
training_level = "SKU"# Set your forecast parameters. Adjust the settings below based on your dataset.
time_column_name = "date"
label_column_name = "quantity"
forecast_horizon = 7
automl_settings = {"task" : "forecasting",
"primary_metric" : "normalized_root_mean_squared_error",
"label_column_name": label_column_name,
"time_column_name": time_column_name,
"forecast_horizon": forecast_horizon,
"hierarchy_column_names": hierarchy,
"hierarchy_training_level": training_level,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,
"model_explainability": model_explainability,# The following settings are specific to this sample and should be adjusted according to your own needs.
"iteration_timeout_minutes" : 10,
"iterations" : 10,
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
}
hts_parameters = HTSTrainParameters(
automl_settings=automl_settings,
hierarchy_column_names=hierarchy,
training_level=training_level,
enable_engineered_explanations=engineered_explanations
)
Voorbeeldnotebooks
Zie de notebooks met prognosevoorbeelden voor gedetailleerde codevoorbeelden van geavanceerde prognoseconfiguratie, waaronder:
- vakantiedetectie en featurization
- kruisvalidatie rolling-origin
- configureerbare vertragingen
- functies voor aggregatie van doorlopende vensters
Volgende stappen
- Meer informatie over het implementeren van een AutoML-model naar een online-eindpunt.
- Meer informatie over interpreteerbaarheid: modeluitleg in geautomatiseerde machine learning (preview).
- Meer informatie over hoe AutoML voorspellingsmodellen bouwt.