Toegang tot gegevens uit Azure-cloudopslag tijdens interactieve ontwikkeling
VAN TOEPASSING OP: Python SDK azure-ai-ml v2 (actueel)
Python SDK azure-ai-ml v2 (actueel)
Een machine learning-project begint meestal met experimentele gegevensanalyse (EDA), gegevensvoorverwerking (reiniging, functie-engineering) en omvat het bouwen van ML-modelprototypes om hypothesen te valideren. Deze prototypeprojectfase is zeer interactief van aard en is geschikt voor ontwikkeling in een Jupyter-notebook of in een IDE met een interactieve Python-console. In dit artikel leert u het volgende:
- Toegang tot gegevens van een Azure Machine Learning-gegevensopslag-URI alsof het een bestandssysteem is.
- Materialiseer gegevens in Pandas met behulp van de
mltablePython-bibliotheek. - Materialiseer Azure Machine Learning-gegevensassets in Pandas met behulp van de
mltablePython-bibliotheek. - Materialiseer gegevens via een expliciete download met het
azcopyhulpprogramma.
Vereisten
- Een Azure Machine Learning-werkruimte. Ga naar Azure Machine Learning-werkruimten beheren in de portal of met de Python SDK (v2) voor meer informatie.
- Een Azure Machine Learning-gegevensarchief. Ga naar Create datastores voor meer informatie.
Tip
In de richtlijnen in dit artikel wordt de toegang tot gegevens tijdens interactieve ontwikkeling beschreven. Dit is van toepassing op elke host die een Python-sessie kan uitvoeren. Dit kan uw lokale machine, een cloud-VM, een GitHub Codespace, enzovoort zijn. U wordt aangeraden een Azure Machine Learning-rekenproces te gebruiken: een volledig beheerd en vooraf geconfigureerd cloudwerkstation. Ga naar Een Azure Machine Learning-rekenproces maken voor meer informatie.
Belangrijk
Zorg ervoor dat u de nieuwste azure-fsspecen mltableazure-ai-ml Python-bibliotheken hebt geïnstalleerd in uw Python-omgeving:
pip install -U azureml-fsspec==1.3.1 mltable azure-ai-ml
De nieuwste azure-fsspec pakketversie kan na verloop van tijd mogelijk veranderen. Ga naar deze resource voor meer informatie over het azure-fsspec pakket.
Toegang tot gegevens vanuit een gegevensarchief-URI, zoals een bestandssysteem
Een Azure Machine Learning-gegevensarchief is een verwijzing naar een bestaand Azure-opslagaccount. De voordelen van het maken en gebruiken van het gegevensarchief zijn:
- Een veelgebruikte, gebruiksvriendelijke API voor interactie met verschillende opslagtypen (Blob/Files/ADLS).
- Eenvoudige detectie van nuttige gegevensarchieven in teambewerkingen.
- Ondersteuning van zowel op referenties gebaseerde (bijvoorbeeld SAS-token) als op identiteit gebaseerde toegang (gebruik Microsoft Entra ID of Manged Identity) om toegang te krijgen tot gegevens.
- Voor toegang op basis van referenties wordt de verbindingsgegevens beveiligd, zodat sleutelblootstelling in scripts ongeldig wordt.
- Blader door gegevens en kopieer-plak-gegevensopslag-URI's in de gebruikersinterface van Studio.
Een gegevensarchief-URI is een uniform resource-id, een verwijzing naar een opslaglocatie (pad) in uw Azure-opslagaccount. Een gegevensarchief-URI heeft deze indeling:
# Azure Machine Learning workspace details:
subscription = '<subscription_id>'
resource_group = '<resource_group>'
workspace = '<workspace>'
datastore_name = '<datastore>'
path_on_datastore = '<path>'
# long-form Datastore uri format:
uri = f'azureml://subscriptions/{subscription}/resourcegroups/{resource_group}/workspaces/{workspace}/datastores/{datastore_name}/paths/{path_on_datastore}'.
Deze Datastore-URI's zijn een bekende implementatie van de bestandssysteemspecificatie (fsspec): een geïntegreerde Pythonic-interface voor lokale, externe en ingesloten bestandssystemen en bytesopslag. Gebruik eerst pip om het azureml-fsspec pakket en het bijbehorende afhankelijkheidspakket azureml-dataprep te installeren. Vervolgens kunt u de implementatie van Azure Machine Learning-gegevensopslag fsspec gebruiken.
De implementatie van Azure Machine Learning-gegevensopslag fsspec verwerkt automatisch de referentie-/identiteitspassthrough die door het Azure Machine Learning-gegevensarchief wordt gebruikt. U kunt zowel accountsleutelblootstelling in uw scripts als extra aanmeldingsprocedures voorkomen op een rekenproces.
U kunt bijvoorbeeld rechtstreeks Gegevensopslag-URI's gebruiken in Pandas. In dit voorbeeld ziet u hoe u een CSV-bestand leest:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
df.head()
Tip
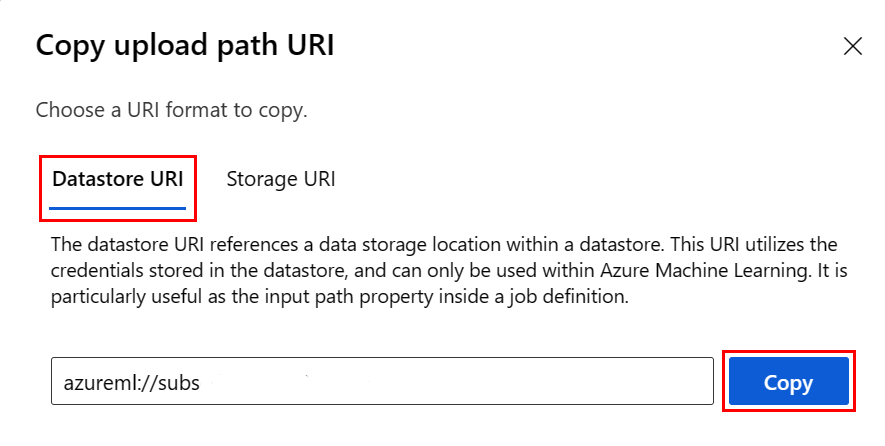
Om te voorkomen dat u de URI-indeling van het gegevensarchief onthoudt, kunt u de gegevensopslag-URI kopiëren en plakken vanuit de gebruikersinterface van Studio met de volgende stappen:
- Selecteer Gegevens in het linkermenu en selecteer vervolgens het tabblad Gegevensarchieven .
- Selecteer de naam van uw gegevensarchief en blader.
- Zoek het bestand/de map die u wilt lezen in Pandas en selecteer het beletselteken (...) ernaast. Selecteer URI kopiëren in het menu. U kunt de gegevensopslag-URI selecteren die u wilt kopiëren naar uw notebook/script.
U kunt ook een Azure Machine Learning-bestandssysteem instantiëren om bestandssysteemachtige opdrachten te verwerken, bijvoorbeeld ls, glob, exists. open
- De
ls()methode bevat bestanden in een specifieke map. U kunt ls(), ls(.), ls (<<folder_level_1>/<folder_level_2>) gebruiken om bestanden weer te geven. We ondersteunen zowel '.' als '.', in relatieve paden. - De
glob()methode ondersteunt '*' en '**' globbing. - De
exists()methode retourneert een Booleaanse waarde die aangeeft of er een opgegeven bestand bestaat in de huidige hoofdmap. - De
open()methode retourneert een bestandachtig object, dat kan worden doorgegeven aan elke andere bibliotheek die verwacht te werken met Python-bestanden. Uw code kan dit object ook gebruiken, alsof het een normaal Python-bestandsobject is. Deze bestandachtige objecten respecteren het gebruik vanwithcontexten, zoals wordt weergegeven in dit voorbeeld:
from azureml.fsspec import AzureMachineLearningFileSystem
# instantiate file system using following URI
fs = AzureMachineLearningFileSystem('azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastore*s*/datastorename')
fs.ls() # list folders/files in datastore 'datastorename'
# output example:
# folder1
# folder2
# file3.csv
# use an open context
with fs.open('./folder1/file1.csv') as f:
# do some process
process_file(f)
Bestanden uploaden via AzureMachineLearningFileSystem
from azureml.fsspec import AzureMachineLearningFileSystem
# instantiate file system using following URI
fs = AzureMachineLearningFileSystem('azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastorename>/paths/')
# you can specify recursive as False to upload a file
fs.upload(lpath='data/upload_files/crime-spring.csv', rpath='data/fsspec', recursive=False, **{'overwrite': 'MERGE_WITH_OVERWRITE'})
# you need to specify recursive as True to upload a folder
fs.upload(lpath='data/upload_folder/', rpath='data/fsspec_folder', recursive=True, **{'overwrite': 'MERGE_WITH_OVERWRITE'})
lpath is het lokale pad en rpath is het externe pad.
Als de mappen die u opgeeft rpath nog niet bestaan, maken we de mappen voor u.
We ondersteunen drie 'overschrijfmodi':
- TOEVOEGEN: als er een bestand met dezelfde naam bestaat in het doelpad, behoudt APPEND het oorspronkelijke bestand
- FAIL_ON_FILE_CONFLICT: als er een bestand met dezelfde naam bestaat in het doelpad, genereert FAIL_ON_FILE_CONFLICT een fout
- MERGE_WITH_OVERWRITE: als er een bestand met dezelfde naam bestaat in het doelpad, MERGE_WITH_OVERWRITE dat bestaande bestand overschrijven met het nieuwe bestand
Bestanden downloaden via AzureMachineLearningFileSystem
# you can specify recursive as False to download a file
# downloading overwrite option is determined by local system, and it is MERGE_WITH_OVERWRITE
fs.download(rpath='data/fsspec/crime-spring.csv', lpath='data/download_files/, recursive=False)
# you need to specify recursive as True to download a folder
fs.download(rpath='data/fsspec_folder', lpath='data/download_folder/', recursive=True)
Voorbeelden
In deze voorbeelden ziet u het gebruik van de bestandssysteemspecificatie in veelvoorkomende scenario's.
Eén CSV-bestand lezen in Pandas
U kunt één CSV-bestand lezen in Pandas, zoals wordt weergegeven:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
Een map met CSV-bestanden lezen in Pandas
De Pandas-methode read_csv() biedt geen ondersteuning voor het lezen van een map met CSV-bestanden. U kunt dit afhandelen door de CSV-paden te gloeien en deze samen te brengen in een gegevensframe met de Pandas-methode concat() . In het volgende codevoorbeeld ziet u hoe u deze samenvoeging kunt bereiken met het Azure Machine Learning-bestandssysteem:
import pandas as pd
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# append csv files in folder to a list
dflist = []
for path in fs.glob('/<folder>/*.csv'):
with fs.open(path) as f:
dflist.append(pd.read_csv(f))
# concatenate data frames
df = pd.concat(dflist)
df.head()
CSV-bestanden lezen in Dask
In dit voorbeeld ziet u hoe u een CSV-bestand kunt lezen in een Dask-gegevensframe:
import dask.dd as dd
df = dd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
df.head()
Een map met Parquet-bestanden lezen in Pandas
Als onderdeel van een ETL-proces worden Parquet-bestanden meestal naar een map geschreven, die vervolgens bestanden kan verzenden die relevant zijn voor de ETL, zoals voortgang, doorvoeringen, enzovoort. In dit voorbeeld ziet u bestanden die zijn gemaakt op basis van een ETL-proces (bestanden die beginnen met _) die vervolgens een Parquet-bestand met gegevens produceren.
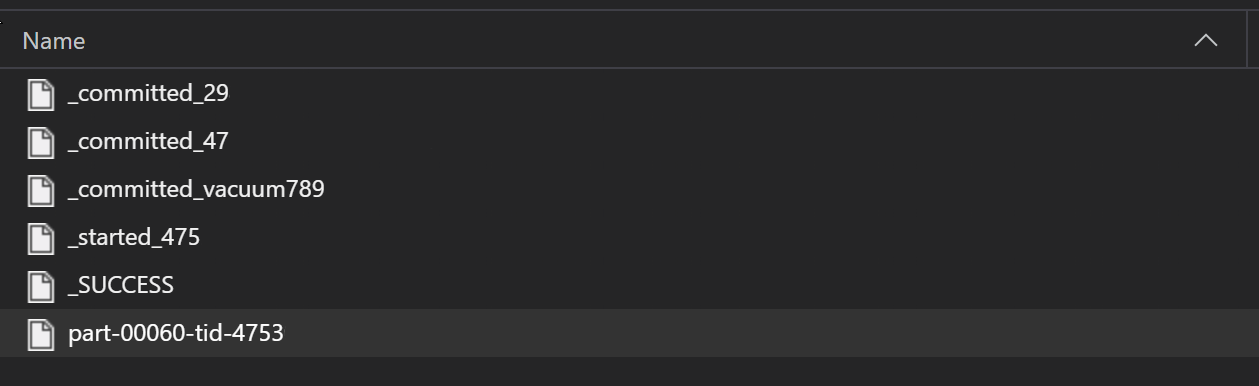
In deze scenario's leest u alleen de Parquet-bestanden in de map en negeert u de ETL-procesbestanden. In dit codevoorbeeld ziet u hoe glob-patronen alleen parquet-bestanden in een map kunnen lezen:
import pandas as pd
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# append parquet files in folder to a list
dflist = []
for path in fs.glob('/<folder>/*.parquet'):
with fs.open(path) as f:
dflist.append(pd.read_parquet(f))
# concatenate data frames
df = pd.concat(dflist)
df.head()
Toegang tot gegevens vanuit uw Azure Databricks-bestandssysteem (dbfs)
Bestandssysteemspecificatie (fsspec) heeft een reeks bekende implementaties, waaronder het Databricks-bestandssysteem (dbfs).
Voor toegang tot gegevens uit de dbfs resource hebt u het volgende nodig:
- Instantienaam, in de vorm van
adb-<some-number>.<two digits>.azuredatabricks.net. U vindt deze waarde in de URL van uw Azure Databricks-werkruimte. - Persoonlijk toegangstoken (PAT); ga naar Verificatie met behulp van persoonlijke toegangstokens van Azure Databricks voor meer informatie over het maken van PAT
Met deze waarden moet u een omgevingsvariabele maken voor het PAT-token op uw rekenproces:
export ADB_PAT=<pat_token>
U kunt vervolgens toegang krijgen tot gegevens in Pandas, zoals wordt weergegeven in dit voorbeeld:
import os
import pandas as pd
pat = os.getenv(ADB_PAT)
path_on_dbfs = '<absolute_path_on_dbfs>' # e.g. /folder/subfolder/file.csv
storage_options = {
'instance':'adb-<some-number>.<two digits>.azuredatabricks.net',
'token': pat
}
df = pd.read_csv(f'dbfs://{path_on_dbfs}', storage_options=storage_options)
Afbeeldingen lezen met pillow
from PIL import Image
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
with fs.open('/<folder>/<image.jpeg>') as f:
img = Image.open(f)
img.show()
Voorbeeld van aangepaste pyTorch-gegevensset
In dit voorbeeld maakt u een aangepaste PyTorch-gegevensset voor het verwerken van afbeeldingen. We gaan ervan uit dat er een aantekeningsbestand (in CSV-indeling) bestaat, met deze algemene structuur:
image_path, label
0/image0.png, label0
0/image1.png, label0
1/image2.png, label1
1/image3.png, label1
2/image4.png, label2
2/image5.png, label2
In submappen worden deze afbeeldingen opgeslagen op basis van hun labels:
/
└── 📁images
├── 📁0
│ ├── 📷image0.png
│ └── 📷image1.png
├── 📁1
│ ├── 📷image2.png
│ └── 📷image3.png
└── 📁2
├── 📷image4.png
└── 📷image5.png
Een aangepaste PyTorch Dataset-klasse moet drie functies implementeren: __init__, __len__en __getitem__, zoals hier wordt weergegeven:
import os
import pandas as pd
from PIL import Image
from torch.utils.data import Dataset
class CustomImageDataset(Dataset):
def __init__(self, filesystem, annotations_file, img_dir, transform=None, target_transform=None):
self.fs = filesystem
f = filesystem.open(annotations_file)
self.img_labels = pd.read_csv(f)
f.close()
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
f = self.fs.open(img_path)
image = Image.open(f)
f.close()
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label
U kunt de gegevensset vervolgens instantiëren, zoals hier wordt weergegeven:
from azureml.fsspec import AzureMachineLearningFileSystem
from torch.utils.data import DataLoader
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# create the dataset
training_data = CustomImageDataset(
filesystem=fs,
annotations_file='/annotations.csv',
img_dir='/<path_to_images>/'
)
# Prepare your data for training with DataLoaders
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
Gegevens materialiseren in Pandas met behulp van mltable een bibliotheek
De mltable bibliotheek kan ook helpen bij het openen van gegevens in cloudopslag. Gegevens lezen in Pandas met mltable deze algemene indeling:
import mltable
# define a path or folder or pattern
path = {
'file': '<supported_path>'
# alternatives
# 'folder': '<supported_path>'
# 'pattern': '<supported_path>'
}
# create an mltable from paths
tbl = mltable.from_delimited_files(paths=[path])
# alternatives
# tbl = mltable.from_parquet_files(paths=[path])
# tbl = mltable.from_json_lines_files(paths=[path])
# tbl = mltable.from_delta_lake(paths=[path])
# materialize to Pandas
df = tbl.to_pandas_dataframe()
df.head()
Ondersteunde paden
De mltable bibliotheek ondersteunt het lezen van tabelgegevens uit verschillende padtypen:
| Locatie | Voorbeelden |
|---|---|
| Een pad op uw lokale computer | ./home/username/data/my_data |
| Een pad op een openbare HTTP(s)-server | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| Een pad in Azure Storage | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path> abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
| Een azure Machine Learning-gegevensarchief met een lange vorm | azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<wsname>/datastores/<name>/paths/<path> |
Notitie
mltable passthrough voor gebruikersreferenties voor paden in Azure Storage en Azure Machine Learning-gegevensarchieven. Als u geen toegang hebt tot de gegevens in de onderliggende opslag, hebt u geen toegang tot de gegevens.
Bestanden, mappen en globs
mltable ondersteunt het lezen van:
- bestand(en) - bijvoorbeeld:
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-csv.csv - map(s) - bijvoorbeeld
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-folder/ - glob-patroon (en) - bijvoorbeeld
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-folder/*.csv - een combinatie van bestanden, mappen en/of globbing patronen
mltable flexibiliteit maakt het mogelijk om gegevens te materialiseren, in één dataframe, van een combinatie van lokale en cloudopslagresources en combinaties van bestanden/mappen/globs. Voorbeeld:
path1 = {
'file': 'abfss://filesystem@account1.dfs.core.windows.net/my-csv.csv'
}
path2 = {
'folder': './home/username/data/my_data'
}
path3 = {
'pattern': 'abfss://filesystem@account2.dfs.core.windows.net/folder/*.csv'
}
tbl = mltable.from_delimited_files(paths=[path1, path2, path3])
Ondersteunde bestandsindelingen
mltable ondersteunt de volgende bestandsindelingen:
- Tekst met scheidingstekens (bijvoorbeeld: CSV-bestanden):
mltable.from_delimited_files(paths=[path]) - Parquet:
mltable.from_parquet_files(paths=[path]) - Delta:
mltable.from_delta_lake(paths=[path]) - Indeling van JSON-regels:
mltable.from_json_lines_files(paths=[path])
Voorbeelden
Een CSV-bestand lezen
Werk de tijdelijke aanduidingen (<>) in dit codefragment bij met uw specifieke gegevens:
import mltable
path = {
'file': 'abfss://<filesystem>@<account>.dfs.core.windows.net/<folder>/<file_name>.csv'
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Parquet-bestanden in een map lezen
In dit voorbeeld ziet u hoe mltable u glob-patronen , zoals jokertekens, kunt gebruiken om ervoor te zorgen dat alleen de Parquet-bestanden worden gelezen.
Werk de tijdelijke aanduidingen (<>) in dit codefragment bij met uw specifieke gegevens:
import mltable
path = {
'pattern': 'abfss://<filesystem>@<account>.dfs.core.windows.net/<folder>/*.parquet'
}
tbl = mltable.from_parquet_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Gegevensassets lezen
In deze sectie wordt beschreven hoe u toegang hebt tot uw Azure Machine Learning-gegevensassets in Pandas.
Tabelasset
Als u eerder een tabelasset hebt gemaakt in Azure Machine Learning (een mltableof V1 TabularDataset), kunt u die tabelasset laden in Pandas met deze code:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
tbl = mltable.load(f'azureml:/{data_asset.id}')
df = tbl.to_pandas_dataframe()
df.head()
Bestandsasset
Als u een bestandsasset (bijvoorbeeld een CSV-bestand) hebt geregistreerd, kunt u die asset lezen in een Pandas-gegevensframe met deze code:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
path = {
'file': data_asset.path
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Mapasset
Als u een mapasset (of een V1FileDataset) hebt geregistreerd,uri_folder bijvoorbeeld een map met een CSV-bestand, kunt u die asset lezen in een Pandas-gegevensframe met deze code:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
path = {
'folder': data_asset.path
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Een notitie over het lezen en verwerken van grote gegevensvolumes met Pandas
Tip
Pandas is niet ontworpen voor het verwerken van grote gegevenssets. Pandas kan alleen gegevens verwerken die in het geheugen van het rekenproces passen.
Voor grote gegevenssets raden we u aan om beheerde Spark van Azure Machine Learning te gebruiken. Dit biedt de PySpark Pandas-API.
Misschien wilt u snel herhalen op een kleinere subset van een grote gegevensset voordat u omhoog schaalt naar een externe asynchrone taak. mltable biedt ingebouwde functionaliteit voor het ophalen van voorbeelden van grote gegevens met behulp van de take_random_sample methode:
import mltable
path = {
'file': 'https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv'
}
tbl = mltable.from_delimited_files(paths=[path])
# take a random 30% sample of the data
tbl = tbl.take_random_sample(probability=.3)
df = tbl.to_pandas_dataframe()
df.head()
U kunt ook subsets van grote gegevens maken met deze bewerkingen:
Gegevens downloaden met behulp van het azcopy hulpprogramma
Gebruik het azcopy hulpprogramma om de gegevens te downloaden naar de lokale SSD van uw host (lokale machine, cloud-VM, Azure Machine Learning Compute Instance, enzovoort) in het lokale bestandssysteem. Het azcopy hulpprogramma, dat vooraf is geïnstalleerd op een Azure Machine Learning-rekenproces, verwerkt het downloaden van gegevens. Als u geen Azure Machine Learning-rekenproces of een Datawetenschap Virtual Machine (DSVM) gebruikt, moet u mogelijk installerenazcopy. Ga naar azcopy voor meer informatie.
Let op
Het wordt afgeraden om gegevens te downloaden naar de /home/azureuser/cloudfiles/code locatie op een rekenproces. Deze locatie is ontworpen om notebook- en codeartefacten op te slaan, niet gegevens. Het lezen van gegevens van deze locatie leidt tot aanzienlijke prestatieoverhead bij het trainen. In plaats daarvan raden we gegevensopslag aan in de home/azureuserlokale SSD van het rekenknooppunt.
Open een terminal en maak een nieuwe map, bijvoorbeeld:
mkdir /home/azureuser/data
Meld u aan bij azcopy met behulp van:
azcopy login
Vervolgens kunt u gegevens kopiëren met behulp van een opslag-URI
SOURCE=https://<account_name>.blob.core.windows.net/<container>/<path>
DEST=/home/azureuser/data
azcopy cp $SOURCE $DEST