Deductie en evaluatie van prognosemodellen
In dit artikel worden concepten geïntroduceerd die betrekking hebben op modeldeductie en evaluatie bij het voorspellen van taken. Zie AutoML instellen voor het trainen van een tijdreeksprognosemodel met SDK en CLI voor instructies en voorbeelden voor het trainen van prognosemodellen in AutoML.
Nadat u AutoML hebt gebruikt om een beste model te trainen en te selecteren, is de volgende stap het genereren van prognoses. Evalueer, indien mogelijk, de nauwkeurigheid van een testset op basis van de trainingsgegevens. Zie Training, deductie en evaluatie indelen om te zien hoe u de evaluatie van het prognosemodel instelt en uitvoert in geautomatiseerde machine learning.
Deductiescenario's
In machine learning is deductie het proces van het genereren van modelvoorspellingen voor nieuwe gegevens die niet worden gebruikt in de training. Er zijn meerdere manieren om voorspellingen te genereren in prognoses vanwege de tijdafhankelijkheid van de gegevens. Het eenvoudigste scenario is wanneer de deductieperiode onmiddellijk volgt op de trainingsperiode en u voorspellingen genereert naar de prognoseperiode. In het volgende diagram ziet u dit scenario:
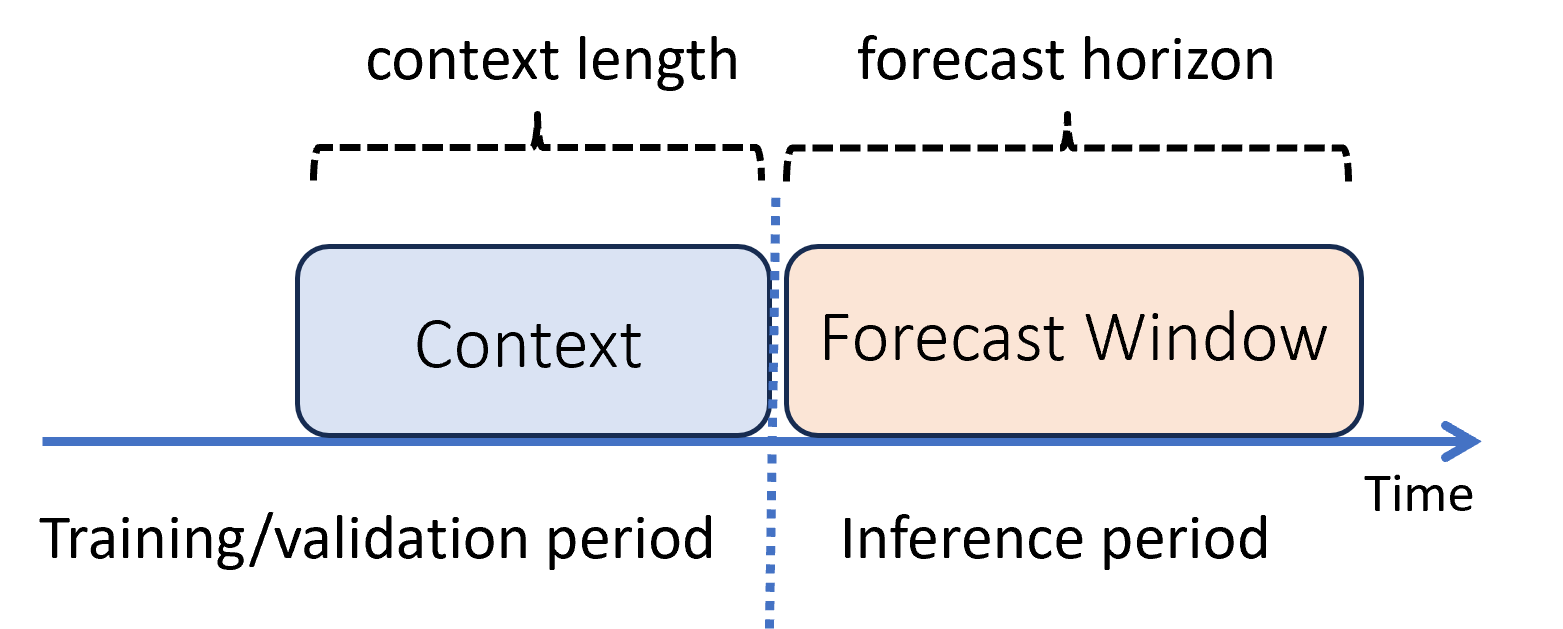
In het diagram ziet u twee belangrijke deductieparameters:
- De contextlengte is de hoeveelheid geschiedenis die het model nodig heeft om een prognose te maken.
- De prognose horizon is hoe ver vooruit in de tijd dat de prognose is getraind om te voorspellen.
Bij het voorspellen van modellen wordt meestal gebruikgemaakt van historische informatie, de context, om voorspellingen vooraf te doen tot aan de prognoseperiode. Wanneer de context deel uitmaakt van de trainingsgegevens, slaat AutoML op wat er nodig is om prognoses te maken. U hoeft deze niet expliciet op te geven.
Er zijn twee andere deductiescenario's die ingewikkelder zijn:
- Voorspellingen verder genereren in de toekomst dan de prognose horizon
- Voorspellingen krijgen wanneer er een kloof is tussen de trainings- en deductieperioden
In de volgende subsecties worden deze gevallen beoordeeld.
Voorspellen langs de prognose horizon: recursieve prognose
Wanneer u prognoses nodig hebt die voorbij de horizon liggen, past AutoML het model recursief toe gedurende de deductieperiode. Voorspellingen van het model worden als invoer ingevoerd om voorspellingen te genereren voor volgende prognosevensters. In het volgende diagram ziet u een eenvoudig voorbeeld:
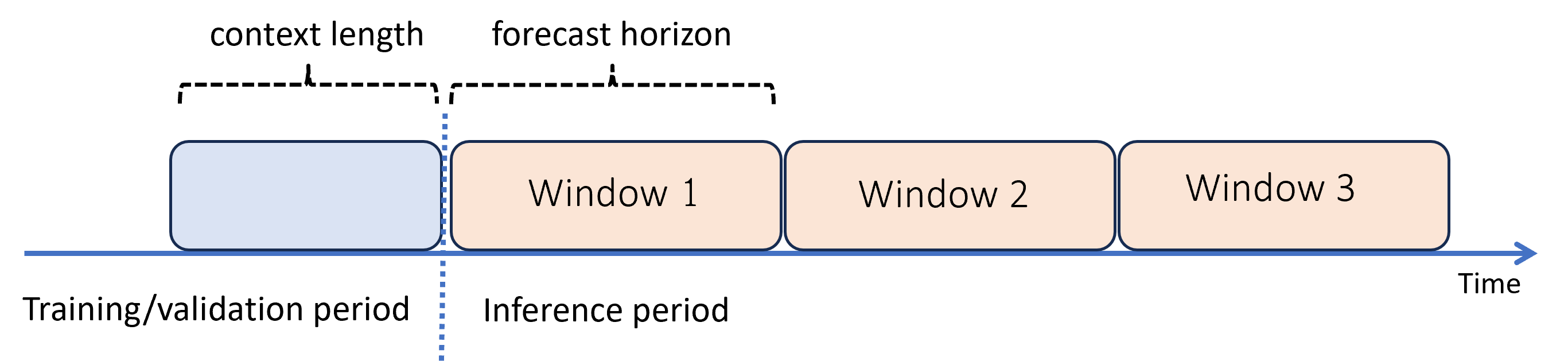
Hier genereert machine learning prognoses voor een periode van drie keer de lengte van de horizon. Er worden voorspellingen van het ene venster gebruikt als context voor het volgende venster.
Waarschuwing
Recursieve prognose van samengestelde modelleringsfouten. Voorspellingen worden minder nauwkeurig, hoe verder ze zich van de oorspronkelijke prognosehorizk bevinden. Mogelijk vindt u een nauwkeuriger model door opnieuw te trainen met een langere horizon.
Voorspellen met een tussenruimte tussen trainings- en deductieperioden
Stel dat nadat u een model hebt getraind, u dit wilt gebruiken om voorspellingen te doen van nieuwe waarnemingen die nog niet beschikbaar waren tijdens de training. In dit geval is er een tijdsverschil tussen de trainings- en deductieperioden:
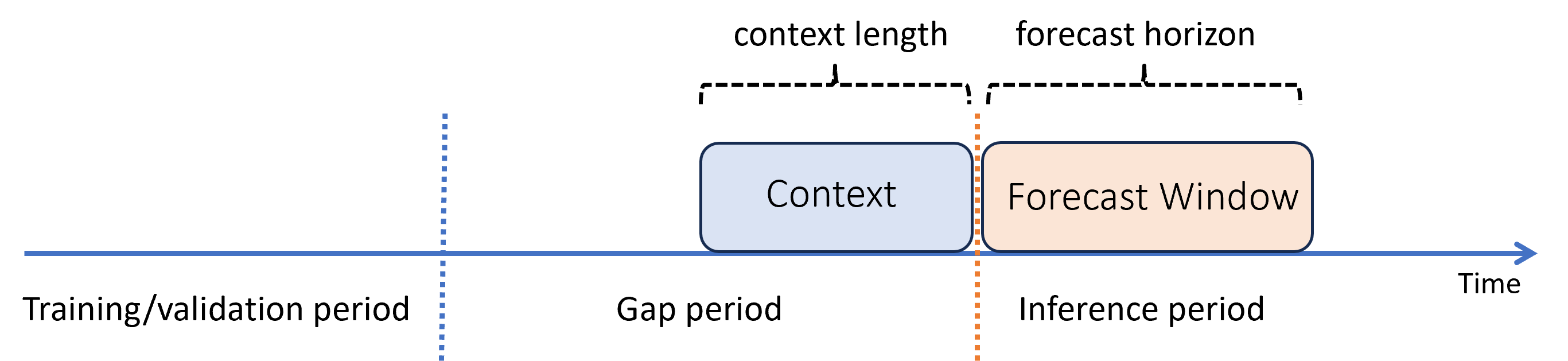
AutoML ondersteunt dit deductiescenario, maar u moet de contextgegevens in de tussenruimteperiode opgeven, zoals wordt weergegeven in het diagram. De voorspellingsgegevens die aan het deductieonderdeel worden doorgegeven, hebben waarden nodig voor functies en waargenomen doelwaarden in de kloof en ontbrekende waarden of NaN waarden voor het doel in de deductieperiode. In de volgende tabel ziet u een voorbeeld van dit patroon:
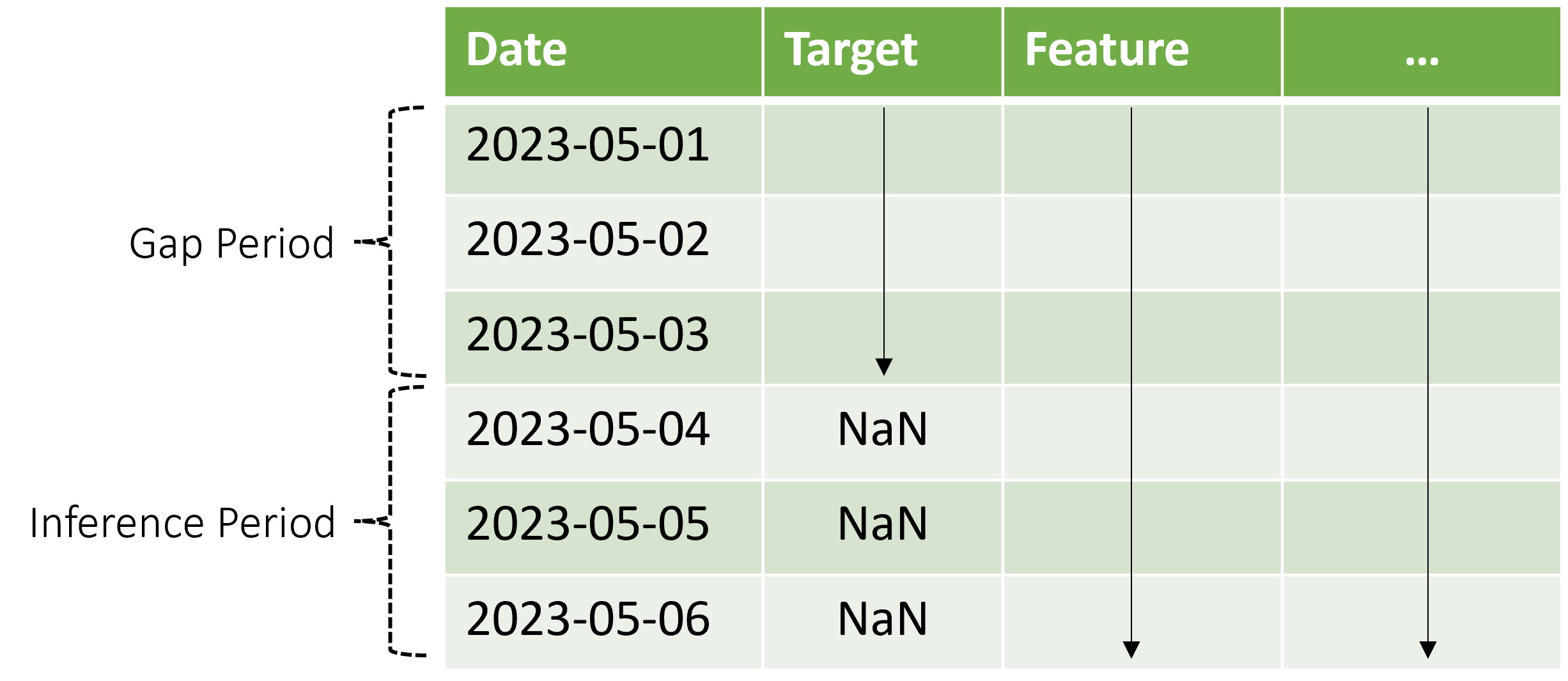
Bekende waarden van het doel en de functies worden verstrekt 2023-05-01 via 2023-05-03. Ontbrekende doelwaarden beginnend bij 2023-05-04 geven aan dat de deductieperiode begint op die datum.
AutoML gebruikt de nieuwe contextgegevens om vertraging en andere lookbackfuncties bij te werken, en ook om modellen zoals ARIMA bij te werken die een interne status behouden. Met deze bewerking worden modelparameters niet bijgewerkt of hersteld.
Modelevaluatie
Evaluatie is het proces van het genereren van voorspellingen voor een testset die wordt gehouden op basis van de trainingsgegevens en het berekenen van metrische gegevens uit deze voorspellingen die leiden tot beslissingen over modelimplementatie. Daarom is er een deductiemodus die geschikt is voor modelevaluatie: een rolling prognose.
Een best practice procedure voor het evalueren van een prognosemodel is om de getrainde prognose vooruit te rollen in de loop van de testset, het gemiddelde van de metrische foutgegevens in verschillende voorspellingsvensters. Deze procedure wordt soms een backtest genoemd. In het ideale opzicht is de testset voor de evaluatie lang ten opzichte van de horizon van de prognose van het model. Schattingen van voorspellingsfouten kunnen anders statistisch luidruchtig zijn en daarom minder betrouwbaar.
In het volgende diagram ziet u een eenvoudig voorbeeld met drie prognosevensters:
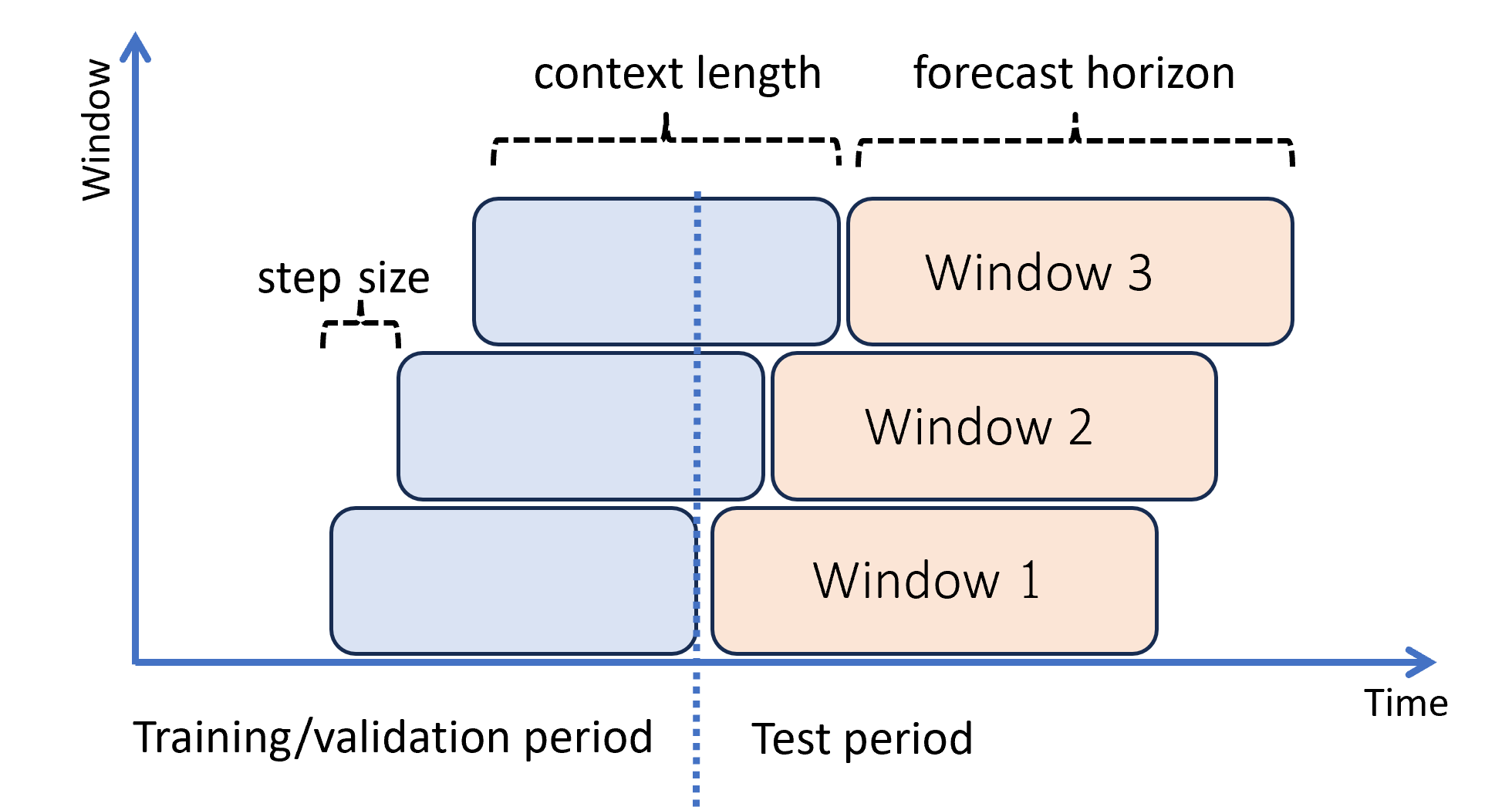
In het diagram ziet u drie rolling evaluatieparameters:
- De contextlengte is de hoeveelheid geschiedenis die het model nodig heeft om een prognose te maken.
- De prognose horizon is hoe ver vooruit in de tijd dat de prognose is getraind om te voorspellen.
- De stapgrootte is hoe ver vooruit in de tijd het rolling-venster verder gaat op elke iteratie in de testset.
De context wordt samen met het prognosevenster weergegeven. Werkelijke waarden uit de testset worden gebruikt om prognoses te maken wanneer ze binnen het huidige contextvenster vallen. De laatste datum van werkelijke waarden die worden gebruikt voor een bepaald prognosevenster, wordt de oorspronkelijke tijd van het venster genoemd. In de volgende tabel ziet u een voorbeelduitvoer van de rolling prognose met drie vensters met een horizon van drie dagen en een stapgrootte van één dag:
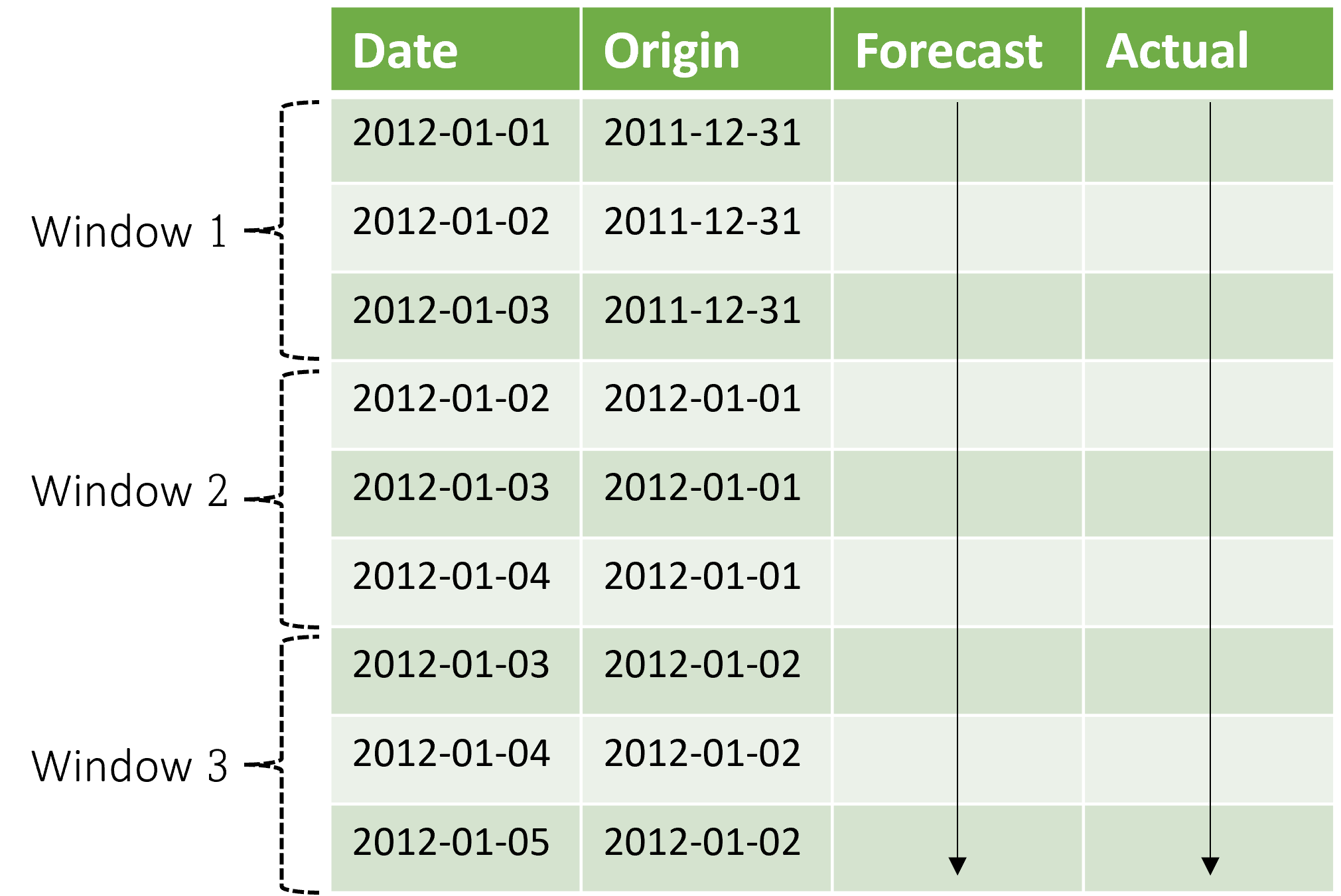
Met een dergelijke tabel kunt u de prognoses en de werkelijke waarden visualiseren en de gewenste evaluatiegegevens berekenen. AutoML-pijplijnen kunnen rolling prognoses genereren voor een testset met een deductieonderdeel.
Notitie
Wanneer de testperiode dezelfde lengte heeft als de prognose horizon, geeft een doorlopende prognose één venster van prognoses tot aan de horizon.
Metrische evaluatiegegevens
Het specifieke bedrijfsscenario bepaalt meestal de keuze van de evaluatiesamenvatting of metrische gegevens. Enkele veelvoorkomende opties zijn de volgende voorbeelden:
- Plots van waargenomen doelwaarden versus voorspelde waarden om te controleren of bepaalde dynamics van de gegevens die door het model worden vastgelegd
- Gemiddelde absolute percentagefout (MAPE) tussen werkelijke en voorspelde waarden
- Wortel van gemiddelde kwadratische fout (RMSE), mogelijk met een normalisatie, tussen werkelijke en voorspelde waarden
- Gemiddelde absolute fout (MAE), mogelijk met een normalisatie, tussen werkelijke en voorspelde waarden
Er zijn veel andere mogelijkheden, afhankelijk van het bedrijfsscenario. Mogelijk moet u uw eigen hulpprogramma's voor naverwerking maken voor het berekenen van metrische gegevens over evaluatie op basis van deductieresultaten of rolling prognoses. Zie Regressie -/prognosegegevens voor meer informatie over metrische gegevens.
Gerelateerde inhoud
- Meer informatie over het instellen van AutoML voor het trainen van een tijdreeksprognosemodel.
- Meer informatie over hoe AutoML machine learning gebruikt om prognosemodellen te bouwen.
- Lees antwoorden op veelgestelde vragen over prognoses in AutoML.