N-Gram-functies extraheren uit verwijzing naar tekstonderdelen
In dit artikel wordt een onderdeel in Azure Machine Learning Designer beschreven. Gebruik het onderdeel N-Gram extraheren uit tekst om ongestructureerde tekstgegevens te bevatten .
Configuratie van de N-Gram-functies extraheren uit het tekstonderdeel
Het onderdeel ondersteunt de volgende scenario's voor het gebruik van een n-gramwoordenlijst:
Maak een nieuwe n-gramwoordenlijst op basis van een kolom met vrije tekst.
Gebruik een bestaande set tekstfuncties om een kolom met vrije tekst weer te geven.
Een model beoordelen of implementeren dat gebruikmaakt van n-grammen.
Een nieuwe n-gramwoordenlijst maken
Voeg de N-Gram-functies extraheren uit het tekstonderdeel toe aan uw pijplijn en verbind de gegevensset met de tekst die u wilt verwerken.
Gebruik de kolom Tekst om een kolom met tekenreekstype te kiezen die de tekst bevat die u wilt extraheren. Omdat de resultaten uitgebreid zijn, kunt u slechts één kolom tegelijk verwerken.
Stel de woordenlijstmodus in op Maken om aan te geven dat u een nieuwe lijst met n-gram-functies maakt.
Stel de grootte N-Gram in om de maximale grootte van de n-grammen aan te geven die moeten worden geëxtraheerd en opgeslagen.
Als u bijvoorbeeld 3, unigrammen, bigrams en trigrammen invoert, worden gemaakt.
De wegingsfunctie geeft aan hoe u de documentfunctievector bouwt en hoe u vocabulaire uit documenten kunt extraheren.
Binair gewicht: wijst een binaire aanwezigheidswaarde toe aan de geëxtraheerde n-grammen. De waarde voor elke n-gram is 1 wanneer deze bestaat in het document en 0 anders.
TF-gewicht: wijst een termfrequentiescore (TF) toe aan de geëxtraheerde n-grammen. De waarde voor elke n-gram is de frequentie van het optreden in het document.
IDF-gewicht: wijst een inverse documentfrequentiescore (IDF) toe aan de geëxtraheerde n-grammen. De waarde voor elke n-gram is het logboek van de corpusgrootte gedeeld door de frequentie van het optreden in het hele corpus.
IDF = log of corpus_size / document_frequencyTF-IDF-gewicht: wijst een termfrequentie/inverse documentfrequentie (TF/IDF) score toe aan de geëxtraheerde n-grammen. De waarde voor elke n-gram is de TF-score vermenigvuldigd met de IDF-score.
Stel de minimale woordlengte in op het minimum aantal letters dat in één woord in een n-gram kan worden gebruikt.
Gebruik maximale woordlengte om het maximum aantal letters in te stellen dat in één woord in een n-gram kan worden gebruikt.
Standaard zijn maximaal 25 tekens per woord of token toegestaan.
Gebruik minimum aantal n-gramdocument absolute frequentie om de minimale exemplaren in te stellen die nodig zijn voor een n-gram die moet worden opgenomen in de n-gramwoordenlijst.
Als u bijvoorbeeld de standaardwaarde van 5 gebruikt, moet een n-gram ten minste vijf keer in het corpus worden opgenomen in de n-gramwoordenlijst.
Stel maximale documentverhouding n-gram in op de maximale verhouding van het aantal rijen dat een bepaalde n-gram bevat, over het aantal rijen in het totale corpus.
Een verhouding van 1 geeft bijvoorbeeld aan dat, zelfs als een specifieke n-gram aanwezig is in elke rij, de n-gram kan worden toegevoegd aan de n-gramwoordenlijst. Normaal gesproken wordt een woord dat in elke rij voorkomt, beschouwd als een ruiswoord en wordt deze verwijderd. Als u woorden van domeinafhankelijke ruis wilt filteren, vermindert u deze verhouding.
Belangrijk
Het voorkomen van bepaalde woorden is niet uniform. Het verschilt van document tot document. Als u bijvoorbeeld klantopmerkingen over een specifiek product analyseert, is de productnaam mogelijk zeer vaak en dicht bij een ruiswoord, maar is het een belangrijke term in andere contexten.
Selecteer de optie N-gram-functievectoren normaliseren om de functievectoren te normaliseren. Als deze optie is ingeschakeld, wordt elke n-gram functievector gedeeld door de L2-norm.
Verzend de pijplijn.
Een bestaande n-gramwoordenlijst gebruiken
Voeg de N-Gram-functies uit het tekstonderdeel uit uw pijplijn toe en verbind de gegevensset met de tekst die u wilt verwerken met de poort Gegevensset .
Gebruik de kolom Tekst om de tekstkolom te selecteren die de tekst bevat die u wilt weergeven. Standaard selecteert het onderdeel alle kolommen van het type tekenreeks. Voor de beste resultaten verwerkt u één kolom tegelijk.
Voeg de opgeslagen gegevensset toe die een eerder gegenereerde n-gramwoordenlijst bevat en verbind deze met de invoerwoordenlijst . U kunt ook de uitvoer van het resultaatwoordschat van een upstream-exemplaar van de functies van het onderdeel N-Gram extraheren uit het onderdeel Tekst verbinden.
Voor de woordenlijst selecteert u de optie Alleen-lezen bijwerken in de vervolgkeuzelijst.
De optie ReadOnly vertegenwoordigt het invoerlichaam voor de invoerwoordenlijst. In plaats van termenfrequenties te berekenen uit de nieuwe tekstgegevensset (aan de linkerkant), worden de n-gramgewichten uit de invoerwoordschat toegepast zoals dat is.
Tip
Gebruik deze optie wanneer u een tekstclassificatie scoret.
Zie de eigenschapsbeschrijvingen in de vorige sectie voor alle andere opties.
Verzend de pijplijn.
Een deductiepijplijn bouwen die gebruikmaakt van n-grammen om een realtime-eindpunt te implementeren
Een trainingspijplijn met de functie N-gram uit tekst en scoremodel extraheren om voorspellingen te doen op de testgegevensset, is gebouwd in de volgende structuur:
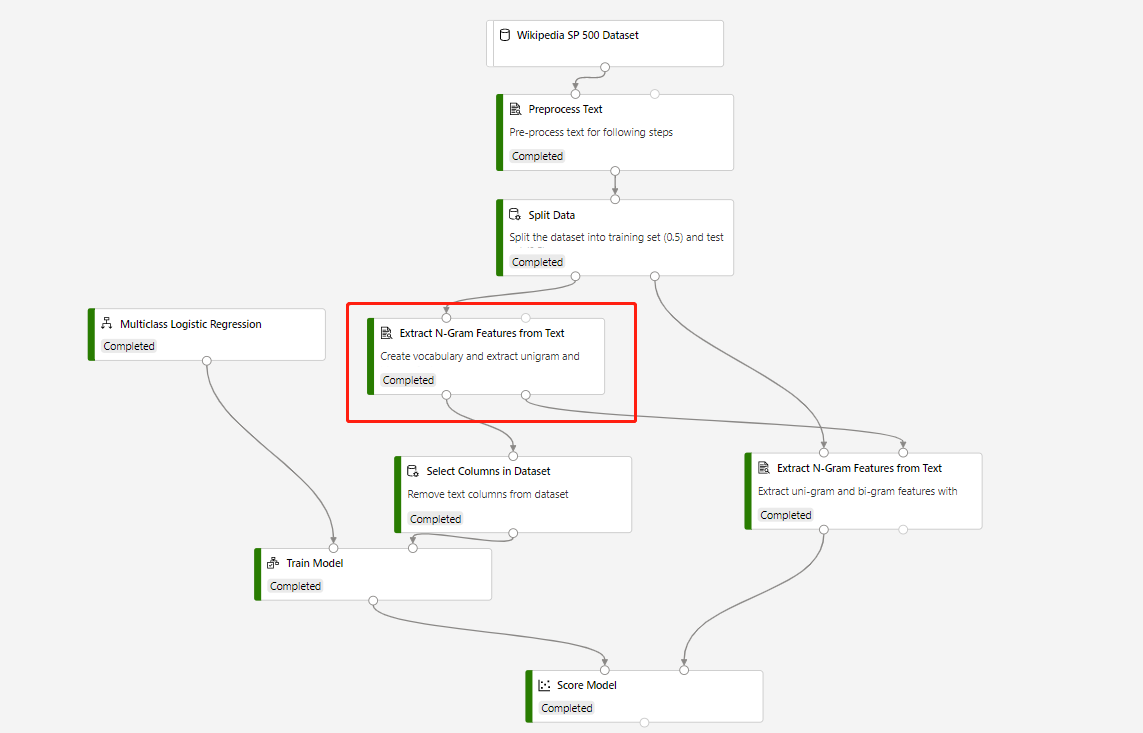
De woordenlijstmodus van de omcirkelde functie N-Gram uit tekst extraheren is Maken en de woordenlijstmodus van het onderdeel dat verbinding maakt met het onderdeel Score Model is ReadOnly.
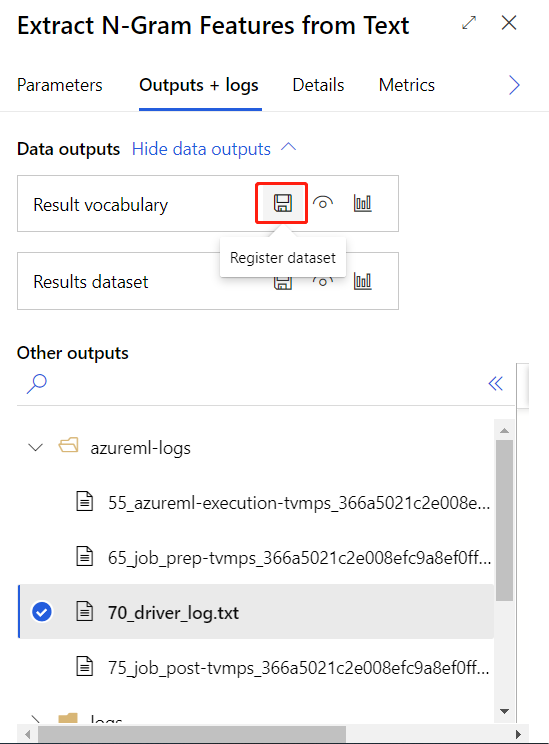
Nadat u de bovenstaande trainingspijplijn hebt ingediend, kunt u de uitvoer van het omcirkelde onderdeel registreren als gegevensset.
Vervolgens kunt u realtime deductiepijplijn maken. Nadat u een deductiepijplijn hebt gemaakt, moet u de deductiepijplijn handmatig als volgt aanpassen:
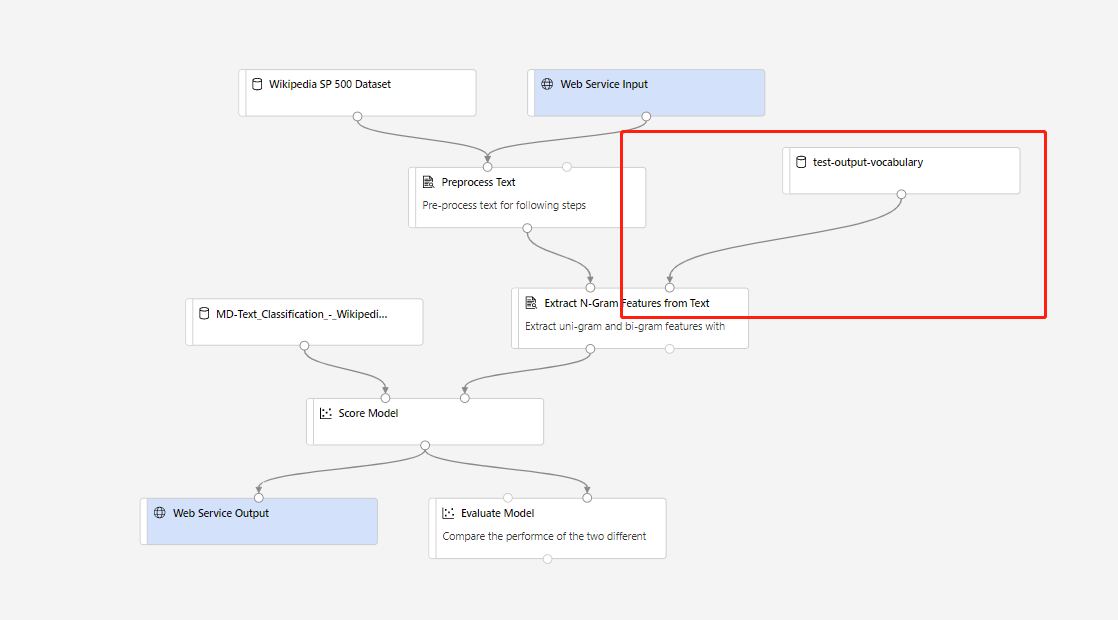
Verzend vervolgens de deductiepijplijn en implementeer een realtime-eindpunt.
Resultaten
Met het onderdeel N-Gram extraheren uit tekst worden twee typen uitvoer gemaakt:
Resultaatgegevensset: Deze uitvoer is een samenvatting van de geanalyseerde tekst in combinatie met de n-grammen die zijn geëxtraheerd. Kolommen die u niet hebt geselecteerd in de optie Tekstkolom , worden doorgegeven aan de uitvoer. Voor elke kolom met tekst die u analyseert, genereert het onderdeel deze kolommen:
- Matrix van n-gram-exemplaren: Het onderdeel genereert een kolom voor elke n-gram gevonden in het totale corpus en voegt een score toe in elke kolom om het gewicht van de n-gram voor die rij aan te geven.
Woordenlijst met resultaat: De woordenlijst bevat de werkelijke n-gramwoordenlijst, samen met de termfrequentiescores die worden gegenereerd als onderdeel van de analyse. U kunt de gegevensset opslaan voor hergebruik met een andere set invoergegevens of voor een latere update. U kunt ook het vocabulaire hergebruiken voor modellering en scoren.
Woordenlijst met resultaten
De woordenlijst bevat de n-gramwoordenlijst met de termenfrequentiescores die worden gegenereerd als onderdeel van de analyse. De DF- en IDF-scores worden gegenereerd, ongeacht andere opties.
- Id: een id die wordt gegenereerd voor elke unieke n-gram.
- NGram: De n-gram. Spaties of andere woordscheidingstekens worden vervangen door het onderstrepingsteken.
- DF: De term frequentiescore voor de n-gram in het oorspronkelijke corpus.
- IDF: De inverse documentfrequentiescore voor de n-gram in het oorspronkelijke corpus.
U kunt deze gegevensset handmatig bijwerken, maar er kunnen fouten optreden. Voorbeeld:
- Er treedt een fout op als het onderdeel dubbele rijen met dezelfde sleutel vindt in de invoerwoordenlijst. Zorg ervoor dat geen twee rijen in het vocabulaire hetzelfde woord hebben.
- Het invoerschema van de gegevenssets voor woordenlijsten moet exact overeenkomen, inclusief kolomnamen en kolomtypen.
- De id-kolom en de DF-kolom moeten van het type geheel getal zijn.
- De IDF-kolom moet van het floattype zijn.
Notitie
Verbind de gegevensuitvoer niet rechtstreeks met het onderdeel Train Model. Verwijder vrije tekstkolommen voordat ze worden ingevoerd in het trainmodel. Anders worden de kolommen met vrije tekst behandeld als categorische functies.
Volgende stappen
Bekijk de set onderdelen die beschikbaar zijn voor Azure Machine Learning.