Hoge beschikbaarheid en herstel na noodgevallen van IoT Hub
Als eerste stap bij het implementeren van een flexibele IoT-oplossing moeten architecten, ontwikkelaars en bedrijfseigenaren de uptimedoelstellingen definiëren voor de oplossingen die ze bouwen. Deze doelen kunnen voornamelijk worden gedefinieerd op basis van specifieke bedrijfsdoelstellingen voor elk scenario. In dit verband wordt in het artikel Technische richtlijnen voor Bedrijfscontinuïteit van Azure een algemeen framework beschreven om u te helpen nadenken over bedrijfscontinuïteit en herstel na noodgevallen. Het document herstel na noodgevallen en hoge beschikbaarheid voor Azure-toepassingen biedt architectuurrichtlijnen voor strategieën voor Azure-toepassingen om hoge beschikbaarheid (HA) en herstel na noodgevallen (DR) te bereiken.
In dit artikel worden de functies voor hoge beschikbaarheid en herstel na noodgevallen beschreven die specifiek worden aangeboden door de IoT Hub-service. De brede gebieden die in dit artikel worden besproken, zijn:
- Hoge beschikbaarheid binnen regio
- Dr voor meerdere regio's
- Hoge beschikbaarheid van regio's bereiken
Afhankelijk van de bedrijfstijddoelen die u definieert voor uw IoT-oplossingen, moet u bepalen welke van de opties die in dit artikel worden beschreven, het beste bij uw bedrijfsdoelstellingen passen. Voor het opnemen van een van deze HA/DR-alternatieven in uw IoT-oplossing is een zorgvuldige evaluatie van de afwegingen tussen:
- Tolerantieniveau dat u nodig hebt
- Implementatie- en onderhoudscomplexiteit
- COGS-impact
Hoge beschikbaarheid binnen regio
De IoT Hub-service biedt hoge beschikbaarheid binnen regio's door redundantie in bijna alle lagen van de service te implementeren. De SLA die door de IoT Hub-service wordt gepubliceerd, wordt bereikt door gebruik te maken van deze redundantie. Er is geen extra werk vereist voor de ontwikkelaars van een IoT-oplossing om te profiteren van deze ha-functies. Hoewel IoT Hub een redelijk hoge uptime-garantie biedt, kunnen tijdelijke fouten nog steeds worden verwacht zoals bij elk gedistribueerd computingplatform. Als u net aan de slag gaat met het migreren van uw oplossingen naar de cloud vanuit een on-premises oplossing, moet uw focus verschuiven van het optimaliseren van 'gemiddelde tijd tussen fouten' tot 'gemiddelde tijd om te herstellen'. Met andere woorden, tijdelijke fouten worden als normaal beschouwd terwijl ze in de mix met de cloud werken. De juiste patronen voor opnieuw proberen moeten worden ingebouwd in de onderdelen die communiceren met een cloudtoepassing om tijdelijke fouten te verwerken.
Beschikbaarheidszones
IoT Hub ondersteunt Azure-beschikbaarheidszones. Een beschikbaarheidszone is een aanbieding met hoge beschikbaarheid waarmee uw toepassingen en gegevens worden beschermd tegen storingen in datacenters. Een regio met ondersteuning voor beschikbaarheidszones bestaat uit drie zones die die regio ondersteunen. Elke zone biedt een of meer datacenters, elk op een unieke fysieke locatie met onafhankelijke voeding, koeling en netwerken. Deze configuratie biedt replicatie en redundantie binnen de regio.
Beschikbaarheidszones bieden twee voordelen: gegevenstolerantie en soepelere implementaties.
Gegevenstolerantie komt doordat de onderliggende opslagservices worden vervangen door opslag die door beschikbaarheidszones wordt ondersteund. Gegevenstolerantie is belangrijk voor IoT-oplossingen, omdat deze oplossingen vaak werken in complexe, dynamische en onzekere omgevingen waarbij fouten of onderbrekingen aanzienlijke gevolgen kunnen hebben. Of een IoT-oplossing nu ondersteuning biedt voor productievloer-, retail- of restaurantomgevingen, gezondheidszorgsystemen of infrastructuur, de beschikbaarheid en kwaliteit van gegevens is nodig om te herstellen van storingen en om betrouwbare en consistente services te bieden.
Soepelere implementaties zijn afkomstig van het vervangen van de onderliggende datacentrumhardware door nieuwere hardware die ondersteuning biedt voor beschikbaarheidszones. Deze hardwareverbeteringen minimaliseren de gevolgen van de klant voor de verbinding en het opnieuw verbinden van apparaten, evenals andere uitvaltijd met betrekking tot implementaties. Het technische team van IoT Hub implementeert om veiligheidsredenen meerdere updates voor elke IoT-hub, om veiligheidsredenen en om functieverbeteringen te bieden. Hardware die door beschikbaarheidszones wordt ondersteund, wordt gesplitst in 15 updatedomeinen, zodat elke update soepeler verloopt, met minimale impact op uw werkstromen. Zie Beschikbaarheidssets voor meer informatie over updatedomeinen.
Ondersteuning voor beschikbaarheidszones voor IoT Hub wordt automatisch ingeschakeld voor nieuwe IoT Hub-resources die zijn gemaakt in de volgende Azure-regio's:
| Regio | Gegevenstolerantie | Soepelere implementaties |
|---|---|---|
| Australië - oost | ||
| Brazilië - zuid | ||
| Canada - midden | ||
| India - centraal | ||
| Central US | ||
| VS - oost | ||
| Frankrijk - centraal | ||
| Duitsland - west-centraal | ||
| Japan - oost | ||
| Korea - centraal | ||
| Europa - noord | ||
| Noorwegen - oost | ||
| Qatar - centraal | ||
| VS - zuid-centraal | ||
| Azië - zuidoost | ||
| Verenigd Koninkrijk Zuid | ||
| Europa -west | ||
| VS - west 2 | ||
| US - west 3 |
Dr voor meerdere regio's
Er kunnen enkele zeldzame situaties zijn wanneer een datacenter uitgebreide storingen ondervindt vanwege stroomstoringen of andere storingen waarbij fysieke assets betrokken zijn. Dergelijke gebeurtenissen komen zelden voor, waarbij de eerder beschreven mogelijkheid binnen regio's niet altijd kan helpen. IoT Hub biedt meerdere oplossingen voor het herstellen van dergelijke uitgebreide storingen.
De herstelopties die beschikbaar zijn voor klanten in een dergelijke situatie, zijn door Microsoft geïnitieerde failover en handmatige failover. Het fundamentele verschil tussen de twee is dat Microsoft de eerste initieert en de gebruiker de laatste initieert. Handmatige failover biedt ook een lagere beoogde hersteltijd (RTO) vergeleken met de door Microsoft geïnitieerde failoveroptie. De specifieke RTO's die bij elke optie worden aangeboden, worden in de volgende secties besproken. Wanneer een van deze opties een failover van een IoT-hub vanuit de primaire regio uitvoert, wordt de hub volledig functioneel in de bijbehorende geografisch gekoppelde Azure-regio.
Beide failoveropties bieden de volgende beoogde herstelpunten (RPO's):
| Gegevenstype | Beoogde herstelpunten (RPO) |
|---|---|
| Identiteitsregister | Gegevensverlies van 0-5 minuten |
| Apparaatdubbelgegevens | Gegevensverlies van 0-5 minuten |
| Cloud-naar-apparaat-berichten1 | Gegevensverlies van 0-5 minuten |
| Bovenliggende1 - en apparaattaken | Gegevensverlies van 0-5 minuten |
| Apparaat-naar-cloud-berichten | Alle ongelezen berichten gaan verloren |
| Feedbackberichten van cloud-naar-apparaat | Alle ongelezen berichten gaan verloren |
1Cloud-naar-apparaat-berichten en bovenliggende taken worden niet hersteld als onderdeel van handmatige failover.
Zodra de failoverbewerking voor de IoT-hub is voltooid, zullen alle bewerkingen van het apparaat en de back-endtoepassingen naar verwachting blijven werken zonder handmatige tussenkomst. Dit betekent dat uw apparaat-naar-cloud-berichten moeten blijven werken en dat het hele apparaatregister intact is. Gebeurtenissen die via Event Grid worden verzonden, kunnen worden gebruikt via dezelfde abonnementen die eerder zijn geconfigureerd zolang deze Event Grid-abonnementen beschikbaar blijven. Er is geen extra verwerking vereist voor aangepaste eindpunten.
Let op
- De event hubs-compatibele naam en het eindpunt van het ingebouwde IoT Hub-eindpunt veranderen na een failover. Wanneer u telemetrieberichten ontvangt van het ingebouwde eindpunt met behulp van de Event Hubs-client of gebeurtenisprocessorhost, moet u de IoT-hub gebruiken verbindingsreeks om de verbinding tot stand te brengen. Dit zorgt ervoor dat uw back-endtoepassingen blijven werken zonder handmatige tussenkomst na failover. Als u de event hub-compatibele naam en het eindpunt in uw toepassing rechtstreeks gebruikt, moet u het nieuwe Event Hub-compatibele eindpunt ophalen na een failover om door te gaan met bewerkingen. Zie Handmatige failover en Event Hub voor meer informatie.
- Als u Azure Functions of Azure Stream Analytics gebruikt om het ingebouwde gebeurtenisseneindpunt te verbinden, moet u mogelijk opnieuw opstarten. Dit komt doordat tijdens eerdere failover-offsets niet langer geldig zijn.
- Bij routering naar opslag raden we u aan de blobs of bestanden weer te geven en deze vervolgens te herhalen, om ervoor te zorgen dat alle blobs of bestanden worden gelezen zonder veronderstellingen van partities te maken. Het partitiebereik kan mogelijk veranderen tijdens een door Microsoft geïnitieerde failover of handmatige failover. U kunt de List Blobs-API gebruiken om de lijst met blobs of De ADLS Gen2-API voor de lijst met bestanden op te sommen. Zie Azure Storage als routeringseindpunt voor meer informatie.
Door Microsoft geïnitieerde failover
Door Microsoft geïnitieerde failover wordt in zeldzame gevallen door Microsoft uitgevoerd om een failover uit te voeren van alle IoT-hubs van een betrokken regio naar de bijbehorende geografisch gekoppelde regio. Dit proces is een standaardoptie en vereist geen tussenkomst van de gebruiker. Microsoft behoudt zich het recht voor om te bepalen wanneer deze optie wordt uitgeoefend. Dit mechanisme omvat geen gebruikerstoestemming voordat de hub van de gebruiker een failover heeft uitgevoerd. Door Microsoft geïnitieerde failover heeft een beoogde hersteltijd (RTO) van 2-26 uur.
De grote RTO is omdat Microsoft de failoverbewerking moet uitvoeren namens alle betrokken klanten in die regio. Als u een minder kritieke IoT-oplossing uitvoert die een downtime van ongeveer een dag kan behouden, is het goed dat u afhankelijk bent van deze optie om te voldoen aan de algemene doelstellingen voor herstel na noodgevallen voor uw IoT-oplossing. De totale tijd voor runtimebewerkingen om volledig operationeel te worden zodra dit proces wordt geactiveerd, wordt beschreven in de sectie Tijd om te herstellen.
Alleen gebruikers die IoT-hubs implementeren in de regio's Brazilië - zuid en Zuidoost-Azië (Singapore) kunnen zich afmelden voor deze functie. Zie Herstel na noodgevallen uitschakelen voor meer informatie.
Notitie
Azure IoT Hub slaat geen klantgegevens op of verwerkt deze buiten het geografische gebied waar u het service-exemplaar implementeert. Zie Replicatie tussen regio's in Azure voor meer informatie.
Handmatige failover
Als uw bedrijfstijddoelen niet voldoen aan de RTO die door Microsoft geïnitieerde failover biedt, kunt u overwegen om handmatige failover te gebruiken om het failoverproces zelf te activeren. De RTO die deze optie gebruikt, kan tussen de 10 minuten en een paar uur duren. De RTO is momenteel een functie van het aantal apparaten dat is geregistreerd voor het IoT Hub-exemplaar waarvoor een failover wordt uitgevoerd. U kunt verwachten dat de RTO voor een hub die ongeveer 100.000 apparaten host in het ballpark van 15 minuten is. De totale tijd voor runtimebewerkingen om volledig operationeel te worden zodra dit proces wordt geactiveerd, wordt beschreven in de sectie Tijd om te herstellen.
De optie voor handmatige failover is altijd beschikbaar voor gebruik, ongeacht of de primaire regio downtime ondervindt of niet. Daarom kan deze optie mogelijk worden gebruikt om geplande failovers uit te voeren. Een voorbeeld van het gebruik van geplande failovers is het uitvoeren van periodieke failoveranalyses. Een woord van voorzichtigheid is echter dat een geplande failoverbewerking resulteert in downtime voor de hub voor de periode die is gedefinieerd door de RTO voor deze optie, en ook resulteert in een gegevensverlies zoals gedefinieerd in de bovenstaande RPO-tabel. U kunt overwegen om een IoT Hub-testexemplaren in te stellen om regelmatig de geplande failoveroptie uit te voeren om vertrouwen te krijgen in uw vermogen om uw end-to-end-oplossingen actief te maken wanneer er een echte ramp optreedt.
Handmatige failover is gratis beschikbaar voor IoT-hubs die zijn gemaakt na 18 mei 2017
Zie Zelfstudie: Handmatige failover uitvoeren voor een IoT-hub voor stapsgewijze instructies
Handmatige failover en Event Hubs
De event hubs-compatibele naam en het eindpunt van het ingebouwde Eindpunt van ioT Hub-gebeurtenissen worden gewijzigd na handmatige failover. Dit komt doordat de Event Hubs-client geen inzicht heeft in IoT Hub-gebeurtenissen. Hetzelfde geldt voor andere cloudclients, zoals Functions en Azure Stream Analytics. Als u het eindpunt en de naam wilt ophalen, kunt u Azure Portal of de .NET SDK gebruiken.
Gebruik de portal
Zie Verbinding maken met het ingebouwde eindpunt voor meer informatie over het gebruik van de portal om het event hub-compatibele eindpunt en de event hub-compatibele naam op te halen.
.NET-SDK gebruiken
Als u de IoT Hub-verbindingsreeks wilt gebruiken om het eindpunt dat compatibel is met Event Hubs te herstellen, gebruikt u een voorbeeld in https://github.com/Azure/azure-sdk-for-net/tree/main/samples/iothub-connect-to-eventhubs. In het codevoorbeeld wordt de verbindingsreeks gebruikt om het nieuwe Event Hubs-eindpunt op te halen en de verbinding opnieuw tot stand te brengen. Visual Studio moet zijn geïnstalleerd.
Testanalyses uitvoeren
Testanalyses mogen niet worden uitgevoerd op IoT-hubs die worden gebruikt in uw productieomgevingen.
Gebruik geen handmatige failover om IoT Hub naar een andere regio te migreren
Handmatige failover mag niet worden gebruikt als mechanisme om uw hub permanent te migreren tussen de gekoppelde Azure-regio's. Ervan uitgaande dat de apparaten zich het dichtst bij de primaire regio van de hub bevinden, neemt de latentie voor bewerkingen die worden uitgevoerd op de IoT-hub toe wanneer de hub een failover naar een secundaire regio uitvoert.
Failback
U kunt een failback uitvoeren naar de oude primaire regio door de failoveractie een tweede keer te activeren. Als de oorspronkelijke failoverbewerking is uitgevoerd om te herstellen van een uitgebreide storing in de oorspronkelijke primaire regio, raden we aan dat de hub moet worden teruggezet naar de oorspronkelijke locatie zodra die locatie is hersteld uit de storingssituatie.
Belangrijk
- Gebruikers mogen slechts 2 geslaagde failover- en 2 geslaagde failbackbewerkingen per dag uitvoeren.
- Back-to-back-failover-/failbackbewerkingen zijn niet toegestaan. Tussen deze bewerkingen moet u 1 uur wachten.
Tijd om te herstellen
Hoewel de FQDN (en daarom de verbindingsreeks) van het IoT Hub-exemplaar dezelfde postfailover blijft, verandert het onderliggende IP-adres wel. De tijd voor de runtimebewerkingen die worden uitgevoerd op uw IoT Hub-exemplaar om volledig operationeel te worden nadat het failoverproces kan worden uitgedrukt met behulp van de volgende functie:
Tijd om te herstellen = RTO [10 min - 2 uur voor handmatige failover | 2 - 26 uur voor door Microsoft geïnitieerde failover] + VERTRAGING van DNS-doorgifte + tijd die de clienttoepassing nodig heeft om een ioT Hub-IP-adres in de cache te vernieuwen.
Belangrijk
De IoT SDK's plaatsen het IP-adres van de IoT-hub niet in de cache. Het is raadzaam dat gebruikerscode-interfacing met de SDK's het IP-adres van de IoT-hub niet in de cache moet opslaan.
Herstel na noodgevallen uitschakelen
IoT Hub biedt door Microsoft geïnitieerde failover en handmatige failover door gegevens te repliceren naar de gekoppelde regio voor elke IoT-hub. Voor sommige regio's kunt u gegevensreplicatie buiten de regio voorkomen door herstel na noodgevallen uit te schakelen bij het maken van een IoT-hub. De volgende regio's ondersteunen deze functie:
- Brazilië - zuid; gekoppelde regio, VS - zuid-centraal.
- Zuidoost-Azië (Singapore); gekoppelde regio, Oost-Azië (Hongkong SAR).
Als u herstel na noodgevallen wilt uitschakelen in ondersteunde regio's, moet u ervoor zorgen dat herstel na noodgevallen is ingeschakeld wanneer u uw IoT-hub maakt:
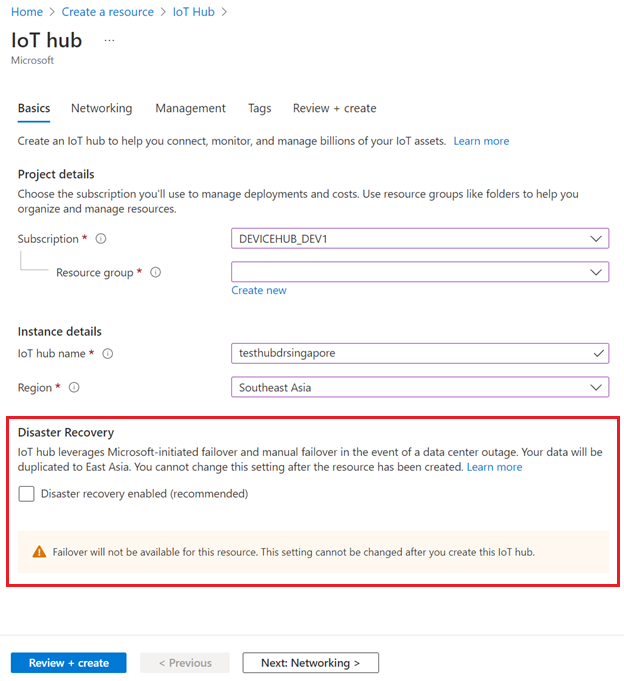
U kunt herstel na noodgevallen ook uitschakelen wanneer u een IoT-hub maakt met behulp van een ARM-sjabloon.
Failover-mogelijkheid is niet beschikbaar als u herstel na noodgevallen uitschakelt voor een IoT-hub.
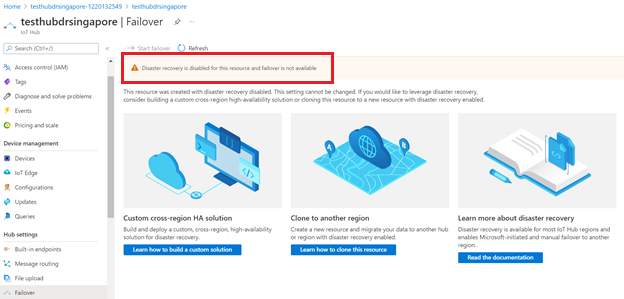
U kunt herstel na noodgevallen alleen uitschakelen om gegevensreplicatie buiten de gekoppelde regio in Brazilië - zuid of Zuidoost-Azië te voorkomen wanneer u een IoT-hub maakt. Als u uw bestaande IoT-hub wilt configureren om herstel na noodgevallen uit te schakelen, moet u een nieuwe IoT-hub maken waarvoor herstel na noodgevallen is uitgeschakeld en uw bestaande IoT-hub handmatig migreren. Zie Een IoT-hub migreren voor hulp.
Hoge beschikbaarheid voor meerdere regio's bereiken
Als uw bedrijfstijddoelen niet voldoen aan de RTO die door Microsoft geïnitieerde failover- of handmatige failoveropties bieden, kunt u overwegen om een automatisch failovermechanisme voor meerdere regio's per apparaat te implementeren. Een volledige behandeling van implementatietopologieën in IoT-oplossingen valt buiten het bereik van dit artikel. In het artikel wordt het regionale failover-implementatiemodel besproken voor hoge beschikbaarheid en herstel na noodgevallen.
In een regionaal failovermodel wordt de back-end van de oplossing voornamelijk uitgevoerd op één datacenterlocatie. Een secundaire IoT-hub en back-end worden geïmplementeerd op een andere datacenterlocatie. Als de IoT-hub in de primaire regio een storing ondervindt of als de netwerkverbinding van het apparaat naar de primaire regio wordt onderbroken, gebruiken apparaten een secundair service-eindpunt. U kunt de beschikbaarheid van de oplossing verbeteren door een failovermodel voor meerdere regio's te implementeren in plaats van binnen één regio te blijven.
Als u op hoog niveau een regionaal failovermodel wilt implementeren met IoT Hub, moet u de volgende stappen uitvoeren:
Een secundaire IoT-hub- en apparaatrouteringslogica: als de service in uw primaire regio wordt onderbroken, moeten apparaten verbinding maken met uw secundaire regio. Gezien de statusbewuste aard van de meeste betrokken services, is het gebruikelijk dat oplossingsbeheerders het failoverproces tussen regio's activeren. De beste manier om het nieuwe eindpunt te communiceren met apparaten, terwijl de controle over het proces behouden blijft, is om ze regelmatig een concierge-service te laten controleren op het huidige actieve eindpunt. De concierge-service kan een webtoepassing zijn die wordt gerepliceerd en bereikbaar wordt gehouden met behulp van DNS-omleidingstechnieken (bijvoorbeeld met behulp van Azure Traffic Manager).
Notitie
IoT Hub-service is geen ondersteund eindpunttype in Azure Traffic Manager. De aanbeveling is om de voorgestelde Concierge-service te integreren met Azure Traffic Manager door de eindpuntstatustest-API te implementeren.
Replicatie van identiteitsregister: de secundaire IoT-hub moet alle apparaatidentiteiten bevatten die verbinding kunnen maken met de oplossing. De oplossing moet geo-gerepliceerde back-ups van apparaatidentiteiten behouden en deze uploaden naar de secundaire IoT-hub voordat het actieve eindpunt voor de apparaten wordt overgeschakeld. De functionaliteit voor het exporteren van apparaat-id's van IoT Hub is nuttig in deze context. Zie de ontwikkelaarshandleiding voor IoT Hub : identiteitsregister voor meer informatie.
Samenvoegingslogica: wanneer de primaire regio weer beschikbaar is, moeten alle status en gegevens die op de secundaire site zijn gemaakt, worden gemigreerd naar de primaire regio. Deze status en gegevens hebben meestal betrekking op apparaatidentiteiten en toepassingsmetagegevens, die moeten worden samengevoegd met de primaire IoT-hub en andere toepassingsspecifieke winkels in de primaire regio.
Gebruik idempotente bewerkingen om deze stap te vereenvoudigen. Idempotente bewerkingen minimaliseren de bijwerkingen van de uiteindelijke consistente distributie van gebeurtenissen, en van duplicaten of levering van gebeurtenissen buiten de volgorde. Bovendien moet de toepassingslogica zo worden ontworpen dat potentiële inconsistenties of een iets verouderde status worden getolereerd. Deze situatie kan optreden vanwege de extra tijd die het systeem nodig heeft om te herstellen op basis van herstelpuntdoelstellingen (RPO).
Kies de juiste optie voor hoge beschikbaarheid/herstel na noodgevallen
Hier volgt een overzicht van de ha/dr-opties die in dit artikel worden weergegeven, die kunnen worden gebruikt als referentiekader om de juiste optie te kiezen die geschikt is voor uw oplossing.
| Optie HA/DR | RTO | RPO | Vereist handmatige interventie? | Implementatiecomplexiteit | Gevolgen voor kosten |
|---|---|---|---|---|---|
| Door Microsoft geïnitieerde failover | 2 - 26 uur | Raadpleeg de bovenstaande RPO-tabel | Nee | Geen | Geen |
| Handmatige failover | 10 min - 2 uur | Raadpleeg de bovenstaande RPO-tabel | Ja | Heel laag. U hoeft deze bewerking alleen vanuit de portal te activeren. | Geen |
| Hoge regio's | < 1 min. | Is afhankelijk van de replicatiefrequentie van uw aangepaste HA-oplossing | Nee | Hoog | > 1x de kosten van 1 IoT-hub |