Problemen met Apache Hadoop YARN oplossen met behulp van Azure HDInsight
Meer informatie over de belangrijkste problemen en hun oplossingen bij het werken met Apache Hadoop YARN-nettoladingen in Apache Ambari.
Hoe kan ik een nieuwe YARN-wachtrij maken in een cluster?
Stappen voor het oplossen
Gebruik de volgende stappen in Ambari om een nieuwe YARN-wachtrij te maken en de capaciteitstoewijzing vervolgens te verdelen over alle wachtrijen.
In dit voorbeeld worden twee bestaande wachtrijen (standaard en thriftsvr) beide gewijzigd van 50% capaciteit in 25%-capaciteit, waardoor de nieuwe wachtrij (spark) 50% capaciteit krijgt.
| Queue | Capaciteit | Maximumcapaciteit |
|---|---|---|
| default | 25% | 50% |
| thrftsvr | 25% | 50% |
| spark | 50% | 50% |
Selecteer het pictogram Ambari-weergaven en selecteer vervolgens het rasterpatroon. Selecteer vervolgens YARN Queue Manager.
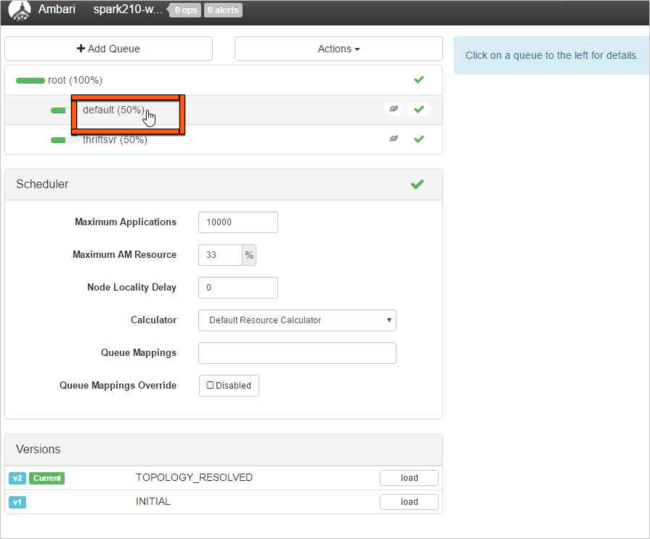
Selecteer de standaardwachtrij .
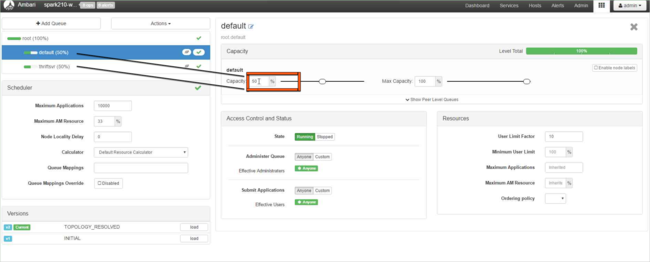
Voor de standaardwachtrij wijzigt u de capaciteit van 50% in 25%. Voor de thriftsvr-wachtrij wijzigt u de capaciteit in 25%.
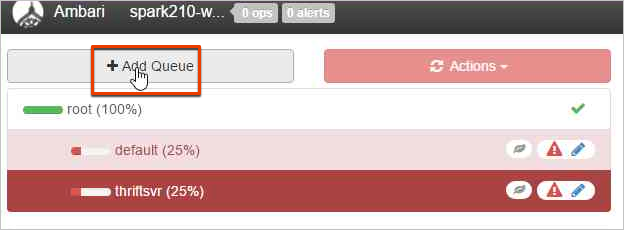
Als u een nieuwe wachtrij wilt maken, selecteert u Wachtrij toevoegen.
Geef de nieuwe wachtrij een naam.
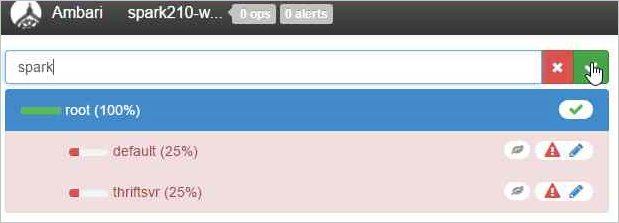
Laat de capaciteitswaarden 50% staan en selecteer vervolgens de knop Acties.
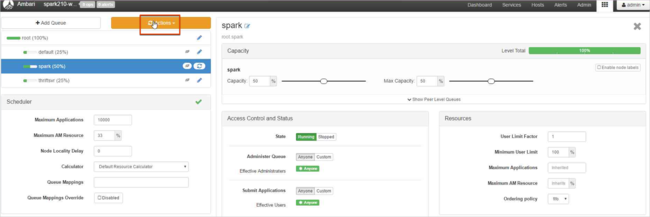
Selecteer Wachtrijen opslaan en vernieuwen.
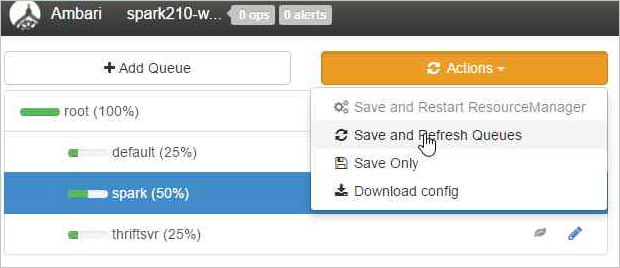
Deze wijzigingen zijn direct zichtbaar in de GEBRUIKERSinterface van YARN Scheduler.
Meer lezen
Hoe kan ik YARN-logboeken downloaden van een cluster?
Stappen voor het oplossen
Maak verbinding met het HDInsight-cluster met behulp van een SSH-client (Secure Shell). Zie Meer lezen voor meer informatie.
Als u alle toepassings-id's van de YARN-toepassingen wilt weergeven die momenteel worden uitgevoerd, voert u de volgende opdracht uit:
yarn topDe id's worden weergegeven in de kolom APPLICATIONID . U kunt logboeken downloaden uit de kolom APPLICATIONID .
YARN top - 18:00:07, up 19d, 0:14, 0 active users, queue(s): root NodeManager(s): 4 total, 4 active, 0 unhealthy, 0 decommissioned, 0 lost, 0 rebooted Queue(s) Applications: 2 running, 10 submitted, 0 pending, 8 completed, 0 killed, 0 failed Queue(s) Mem(GB): 97 available, 3 allocated, 0 pending, 0 reserved Queue(s) VCores: 58 available, 2 allocated, 0 pending, 0 reserved Queue(s) Containers: 2 allocated, 0 pending, 0 reserved APPLICATIONID USER TYPE QUEUE #CONT #RCONT VCORES RVCORES MEM RMEM VCORESECS MEMSECS %PROGR TIME NAME application_1490377567345_0007 hive spark thriftsvr 1 0 1 0 1G 0G 1628407 2442611 10.00 18:20:20 Thrift JDBC/ODBC Server application_1490377567345_0006 hive spark thriftsvr 1 0 1 0 1G 0G 1628430 2442645 10.00 18:20:20 Thrift JDBC/ODBC ServerGebruik de volgende opdracht om YARN-containerlogboeken voor alle toepassingsmodellen te downloaden:
yarn logs -applicationIdn logs -applicationId <application_id> -am ALL > amlogs.txtMet deze opdracht maakt u een logboekbestand met de naam amlogs.txt.
Gebruik de volgende opdracht om YARN-containerlogboeken te downloaden voor alleen de nieuwste toepassingsmaster:
yarn logs -applicationIdn logs -applicationId <application_id> -am -1 > latestamlogs.txtMet deze opdracht maakt u een logboekbestand met de naam latestamlogs.txt.
Gebruik de volgende opdracht om YARN-containerlogboeken voor de eerste twee toepassingsmodellen te downloaden:
yarn logs -applicationIdn logs -applicationId <application_id> -am 1,2 > first2amlogs.txtMet deze opdracht maakt u een logboekbestand met de naam first2amlogs.txt.
Gebruik de volgende opdracht om alle YARN-containerlogboeken te downloaden:
yarn logs -applicationIdn logs -applicationId <application_id> > logs.txtMet deze opdracht maakt u een logboekbestand met de naam logs.txt.
Gebruik de volgende opdracht om het YARN-containerlogboek voor een specifieke container te downloaden:
yarn logs -applicationIdn logs -applicationId <application_id> -containerId <container_id> > containerlogs.txtMet deze opdracht maakt u een logboekbestand met de naam containerlogs.txt.
Meer artikelen
- Verbinding maken met HDInsight (Apache Hadoop) met behulp van SSH
- Concepten en toepassingen van Apache Hadoop YARN
Hoe kan ik de diagnostische gegevens van yarn-toepassingen controleren?
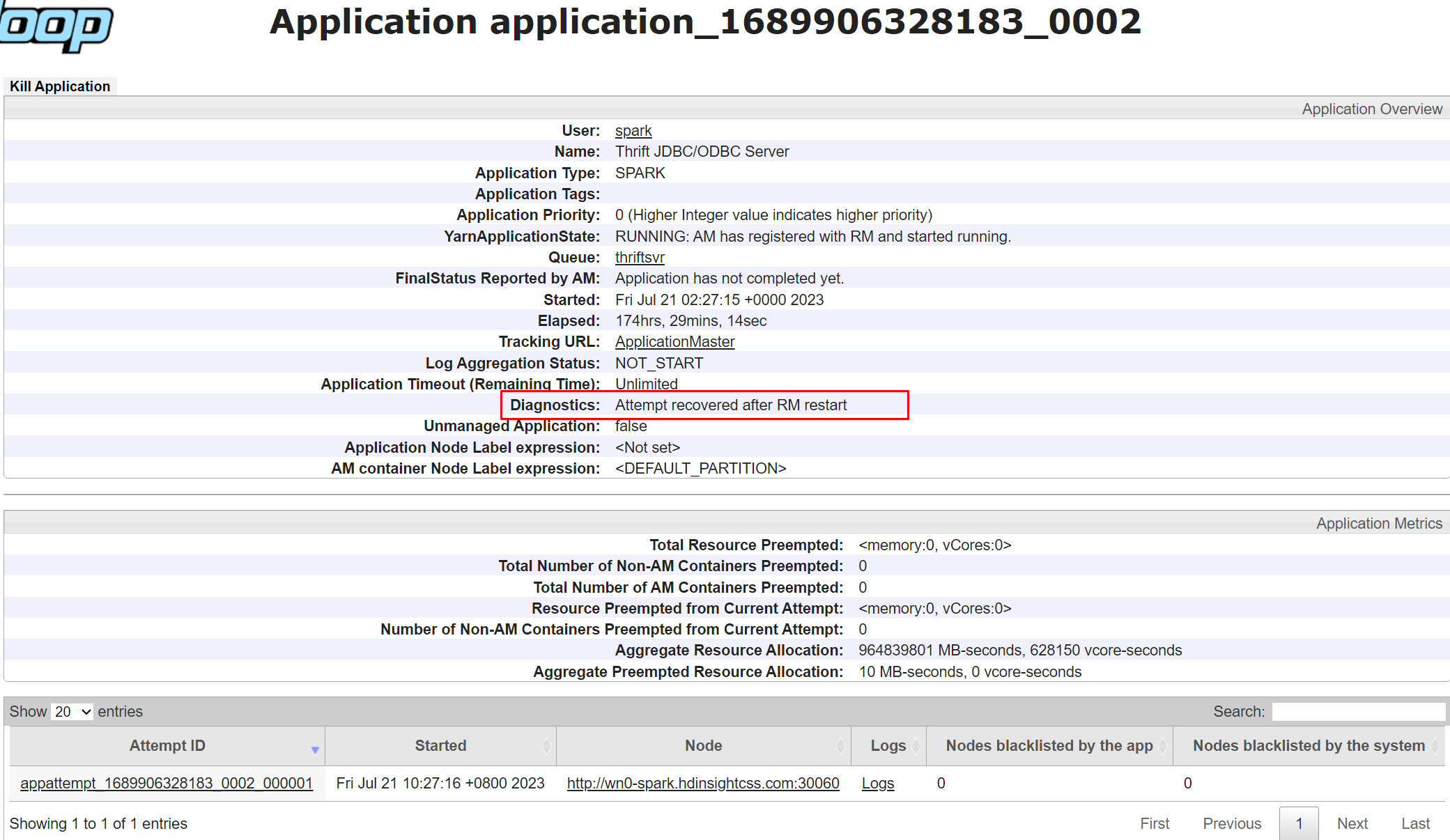
Diagnostische gegevens in de yarn-gebruikersinterface zijn een functie waarmee u de status en logboeken van uw toepassingen kunt bekijken die worden uitgevoerd op Yarn. Diagnostische gegevens kunnen u helpen bij het oplossen en opsporen van fouten in uw toepassingen, evenals het bewaken van hun prestaties en resourcegebruik.
Als u de diagnostische gegevens van een specifieke toepassing wilt bekijken, klikt u op de toepassings-id in de lijst met toepassingen. Op de pagina met toepassingsgegevens ziet u ook een lijst met alle pogingen die zijn gedaan om de toepassing uit te voeren. U kunt op elke poging klikken om meer details weer te geven, zoals de pogings-id, container-id, knooppunt-id, begintijd, eindtijd en diagnostische gegevens
Hoe kan ik veelvoorkomende problemen met YARN oplossen?
Yarn UI wordt niet geladen
Als uw YARN-gebruikersinterface niet wordt geladen of niet bereikbaar is en deze 'HTTP-fout 502.3 - Ongeldige gateway' retourneert, geeft dit ten zeerste aan dat uw Resource Manager-service niet in orde is. Volg deze stappen om het probleem te verhelpen:
- Ga naar HET YARN-OVERZICHT> van de Ambari-gebruikersinterface>en controleer of alleen de actieve Resource Manager de status Gestart heeft. Als dat niet het probleem is, probeert u dit te verhelpen door resourcebeheer opnieuw op te starten of te stoppen.
- Als stap 1 het probleem niet oplost, SSH het actieve Hoofdknooppunt van Resource Manager en controleert u de status van de garbagecollection met behulp van
jstat -gcutil <Resource Manager pid> 1000 100. Als u de toename van de FGCT in slechts een paar seconden ziet, geeft dit aan dat Resource Manager bezet is in volledige GC en dat de andere aanvragen niet kunnen worden verwerkt. - Ga naar Ambari UI>YARN>CONFIGS>Advanced en verhoog
Resource Manager java heap size. - Start de vereiste services opnieuw op in de Ambari-gebruikersinterface.
Beide resourcemanagers zijn vastgelopen in de stand-by
- Controleer het Resource Manager-logboek om te zien of er een vergelijkbare fout bestaat.
Service RMActiveServices failed in state STARTED; cause: org.apache.hadoop.service.ServiceStateException: com.google.protobuf.InvalidProtocolBufferException: Could not obtain block: BP-452067264-10.0.0.16-1608006815288:blk_1074235266_494491 file=/yarn/node-labels/nodelabel.mirror
Als de fout bestaat, controleert u of sommige bestanden onder replicatie staan of of er blokken ontbreken in de HDFS. U kunt
hdfs fsck hdfs://mycluster/uitvoerenVoer
hdfs fsck hdfs://mycluster/ -deletede HDFS te geforceerd opschonen en verwijder het probleem met de stand-by-RM. U kunt PatchYarnNodeLabel ook uitvoeren op een van de hoofdknooppunten om het cluster te patchen.
Volgende stappen
Als u uw probleem niet hebt gezien of uw probleem niet kunt oplossen, gaat u naar een van de volgende kanalen voor meer ondersteuning:
Krijg antwoorden van Azure-experts via de ondersteuning van De Azure-community.
Maak verbinding met @AzureSupport : het officiële Microsoft Azure-account voor het verbeteren van de klantervaring. De Azure-community verbinden met de juiste resources: antwoorden, ondersteuning en experts.
Als u meer hulp nodig hebt, kunt u een ondersteuningsaanvraag indienen via Azure Portal. Selecteer Ondersteuning in de menubalk of open de Help + ondersteuningshub . Raadpleeg hoe u een ondersteuning voor Azure aanvraag maakt voor meer informatie. Toegang tot abonnementsbeheer en factuurbeheer is in uw Microsoft Azure-abonnement inbegrepen, en technische ondersteuning wordt verstrekt via een van de Azure-ondersteuningsplannen.