Apache Hive-query's uitvoeren met de Data Lake-hulpprogramma's voor Visual Studio
Meer informatie over het gebruik van de Data Lake-hulpprogramma's voor Visual Studio om een query uit te voeren op Apache Hive. Met de Data Lake-hulpprogramma's kunt u eenvoudig Hive-query's maken, verzenden en bewaken naar Apache Hadoop in Azure HDInsight.
Vereisten
Een Apache Hadoop-cluster in HDInsight. Zie Apache Hadoop-cluster maken in Azure HDInsight met behulp van een Resource Manager-sjabloon voor meer informatie over het maken van dit item.
Visual Studio. In de stappen in dit artikel wordt Visual Studio 2019 gebruikt.
HDInsight-hulpprogramma's voor Visual Studio of Azure Data Lake-hulpprogramma's voor Visual Studio. Zie Data Lake Tools voor Visual Studio installeren voor informatie over het installeren en configureren van de hulpprogramma's.
Apache Hive-query's uitvoeren met Visual Studio
U hebt twee opties voor het maken en uitvoeren van Hive-query's:
- Ad-hocquery's maken.
- Maak een Hive-toepassing.
Een ad-hoc Hive-query maken
Ad-hocquery's kunnen worden uitgevoerd in batch - of interactieve modus.
Start Visual Studio en selecteer Doorgaan zonder code.
Klik in Server Explorer met de rechtermuisknop op Azure, selecteer Verbinding maken met Microsoft Azure-abonnement...en voltooi het aanmeldingsproces.
Vouw HDInsight uit, klik met de rechtermuisknop op het cluster waar u de query wilt uitvoeren en selecteer vervolgens Een Hive-query schrijven.
Voer de volgende Hive-query in:
SELECT * FROM hivesampletable;Selecteer Uitvoeren. De uitvoeringsmodus wordt standaard ingesteld op Interactive.
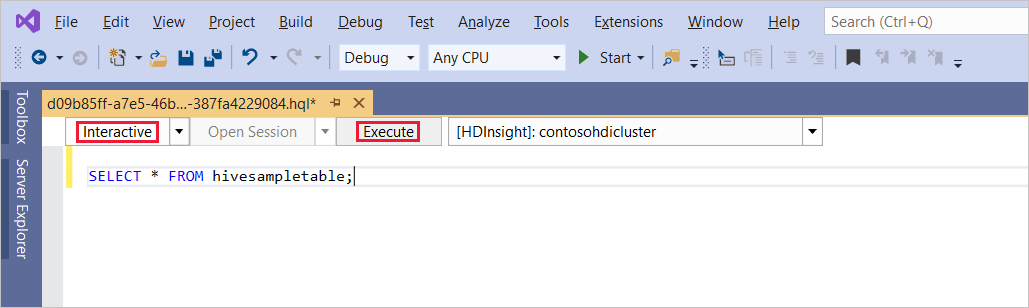
Als u dezelfde query wilt uitvoeren in de Batch-modus , schakelt u de vervolgkeuzelijst van Interactive naar Batch in. De uitvoeringsknop verandert van Uitvoeren naar Verzenden.

De Hive-editor ondersteunt IntelliSense. Data Lake Tools voor Visual Studio biedt ondersteuning voor het laden van externe metagegevens wanneer u het Hive-script bewerkt. Als u bijvoorbeeld typt
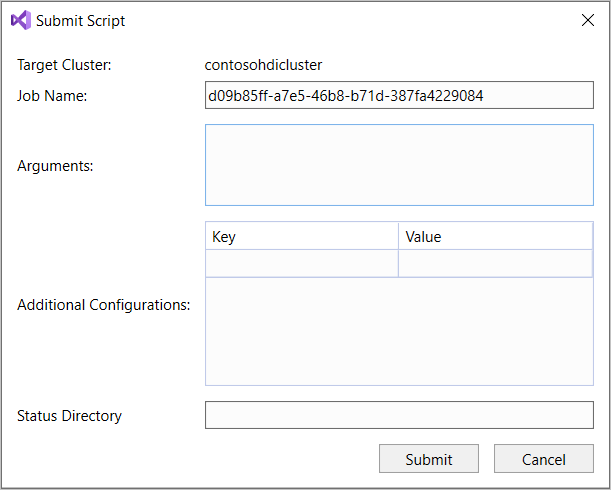
SELECT * FROM, worden intelliSense alle voorgestelde tabelnamen weergegeven. Wanneer een tabelnaam wordt opgegeven, geeft IntelliSense de kolomnamen weer. De hulpprogramma's ondersteunen de meeste DML-instructies, subquery's en ingebouwde UDF's van Hive. IntelliSense suggereert alleen de metagegevens van het cluster dat in de HDInsight-werkbalk is geselecteerd.Selecteer In de querywerkbalk (het gebied onder het querytabblad en boven de querytekst) de optie Verzenden of selecteer de vervolgkeuzepijl naast Verzenden en kies Geavanceerd in de vervolgkeuzelijst. Als u de laatste optie selecteert,
Als u de optie geavanceerd verzenden hebt geselecteerd, configureert u taaknaam, argumenten, aanvullende configuraties en statusmap in het dialoogvenster Script verzenden. Selecteer vervolgens Verzenden.
Een Hive-toepassing maken
Voer de volgende stappen uit om een Hive-query uit te voeren door een Hive-toepassing te maken:
Open Visual Studio.
Selecteer in het Startvenster de optie Een nieuw project maken.
Voer Hive in het venster Een nieuw project maken in het vak Sjablonen zoeken in. Kies vervolgens Hive-toepassing en selecteer Volgende.
Voer in het venster Uw nieuwe project configureren een projectnaam in, selecteer of maak een locatie voor het nieuwe project en selecteer vervolgens Maken.
Open het script.hql-bestand dat met dit project is gemaakt en plak de volgende HiveQL-instructies:
set hive.execution.engine=tez; DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4j Logs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/example/data/'; SELECT t4 AS sev, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' AND INPUT__FILE__NAME LIKE '%.log' GROUP BY t4;Met deze instructies worden de volgende acties uitgevoerd:
DROP TABLE: Hiermee verwijdert u de tabel als deze bestaat.CREATE EXTERNAL TABLE: Hiermee maakt u een nieuwe 'externe' tabel in Hive. Externe tabellen slaan alleen de tabeldefinitie op in Hive. (De gegevens blijven op de oorspronkelijke locatie.)Notitie
Externe tabellen moeten worden gebruikt wanneer u verwacht dat de onderliggende gegevens worden bijgewerkt door een externe bron, zoals een MapReduce-taak of een Azure-service.
Als u een externe tabel verwijdert, worden de gegevens niet verwijderd, alleen de tabeldefinitie.
ROW FORMAT: Vertelt Hive hoe de gegevens zijn opgemaakt. In dit geval worden de velden in elk logboek gescheiden door een spatie.STORED AS TEXTFILE LOCATION: Vertelt Hive dat de gegevens worden opgeslagen in de voorbeeldmap/gegevensmap en dat deze als tekst worden opgeslagen.SELECT: Selecteert een telling van alle rijen waarin de kolomt4de waarde[ERROR]bevat. Deze instructie retourneert een waarde van3, omdat drie rijen deze waarde bevatten.INPUT__FILE__NAME LIKE '%.log': Geeft Hive aan om alleen gegevens te retourneren uit bestanden die eindigen op .log. Met deze component wordt de zoekopdracht beperkt tot het sample.log-bestand dat de gegevens bevat.
Selecteer op de werkbalk van het querybestand (die vergelijkbaar is met de ad-hocquerywerkbalk) het HDInsight-cluster dat u voor deze query wilt gebruiken. Wijzig vervolgens Interactive in Batch (indien nodig) en selecteer Verzenden om de instructies uit te voeren als een Hive-taak.
Het Hive-taakoverzicht wordt weergegeven en geeft informatie weer over de actieve taak. Gebruik de koppeling Vernieuwen om de taakgegevens te vernieuwen totdat de taakstatus wordt gewijzigd in Voltooid.
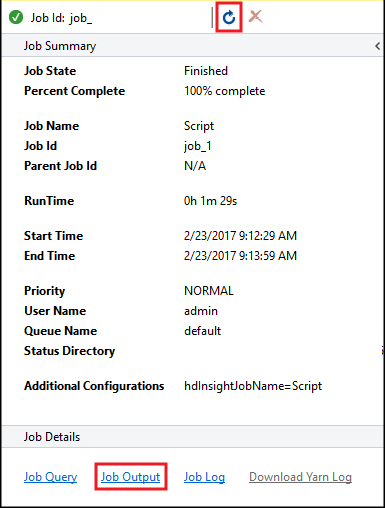
Selecteer Taakuitvoer om de uitvoer van deze taak weer te geven. Dit wordt weergegeven
[ERROR] 3. Dit is de waarde die door deze query wordt geretourneerd.
Extra voorbeeld
Het volgende voorbeeld is afhankelijk van de log4jLogs tabel die in de vorige procedure is gemaakt, een Hive-toepassing maken.
Klik in Server Explorer met de rechtermuisknop op het cluster en selecteer Een Hive-query schrijven.
Voer de volgende Hive-query in:
set hive.execution.engine=tez; CREATE TABLE IF NOT EXISTS errorLogs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) STORED AS ORC; INSERT OVERWRITE TABLE errorLogs SELECT t1, t2, t3, t4, t5, t6, t7 FROM log4jLogs WHERE t4 = '[ERROR]' AND INPUT__FILE__NAME LIKE '%.log';Met deze instructies worden de volgende acties uitgevoerd:
CREATE TABLE IF NOT EXISTS: Hiermee maakt u een tabel als deze nog niet bestaat. Omdat hetEXTERNALtrefwoord niet wordt gebruikt, maakt deze instructie een interne tabel. Interne tabellen worden opgeslagen in het Hive-datawarehouse en worden beheerd door Hive.Notitie
In tegenstelling tot
EXTERNALtabellen worden ook de onderliggende gegevens verwijderd door een interne tabel te verwijderen.STORED AS ORC: Slaat de gegevens op in de indeling geoptimaliseerde rijkolommen (ORC ). ORC is een zeer geoptimaliseerde en efficiënte indeling voor het opslaan van Hive-gegevens.INSERT OVERWRITE ... SELECT: Selecteert rijen uit delog4jLogstabel die de gegevens bevatten[ERROR]en voegt de gegevens vervolgens in deerrorLogstabel in.
Wijzig indien nodig Interactive in Batch en selecteer Verzenden.
Als u wilt controleren of de taak de tabel heeft gemaakt, gaat u naar Server Explorer en vouwt u Azure>HDInsight uit. Vouw uw HDInsight-cluster uit en vouw vervolgens de standaardwaarde voor Hive-databases>uit. De tabel errorLogs en de tabel Log4jLogs worden weergegeven.
Volgende stappen
Zoals u kunt zien, bieden de HDInsight-hulpprogramma's voor Visual Studio een eenvoudige manier om te werken met Hive-query's in HDInsight.
Zie Wat is Apache Hive en HiveQL in Azure HDInsight voor algemene informatie over Hive in HDInsight ?
Zie MapReduce gebruiken in Apache Hadoop in HDInsight voor meer informatie over andere manieren waarop u met Hadoop in HDInsight kunt werken