Azure Machine Learning Notebook gebruiken in Spark
Notitie
Op 31 januari 2025 wordt Azure HDInsight buiten gebruik gesteld op AKS. Vóór 31 januari 2025 moet u uw workloads migreren naar Microsoft Fabric of een gelijkwaardig Azure-product om te voorkomen dat uw workloads plotseling worden beëindigd. De resterende clusters in uw abonnement worden gestopt en verwijderd van de host.
Alleen basisondersteuning is beschikbaar tot de buitengebruikstellingsdatum.
Belangrijk
Deze functie is momenteel beschikbaar in preview. De aanvullende gebruiksvoorwaarden voor Microsoft Azure Previews bevatten meer juridische voorwaarden die van toepassing zijn op Azure-functies die bèta, in preview of anderszins nog niet beschikbaar zijn in algemene beschikbaarheid. Zie Azure HDInsight op AKS Preview-informatie voor meer informatie over deze specifieke preview. Voor vragen of suggesties voor functies dient u een aanvraag in op AskHDInsight met de details en volgt u ons voor meer updates in de Azure HDInsight-community.
Machine learning is een groeiende technologie waarmee computers automatisch kunnen leren van eerdere gegevens. Machine learning maakt gebruik van verschillende algoritmen voor het bouwen van wiskundige modellen en het maken van voorspellingen maken gebruik van historische gegevens of informatie. We hebben een model gedefinieerd tot een aantal parameters en leren is de uitvoering van een computerprogramma om de parameters van het model te optimaliseren met behulp van de trainingsgegevens of ervaring. Het model kan voorspellend zijn om in de toekomst voorspellingen te doen, of beschrijvend om kennis van gegevens te verkrijgen.
In het volgende zelfstudienotitieblok ziet u een voorbeeld van het trainen van machine learning-modellen op tabellaire gegevens. U kunt dit notebook importeren en zelf uitvoeren.
Het CSV-bestand uploaden naar uw opslag
Uw opslag- en containernaam zoeken in de JSON-weergave van de portal
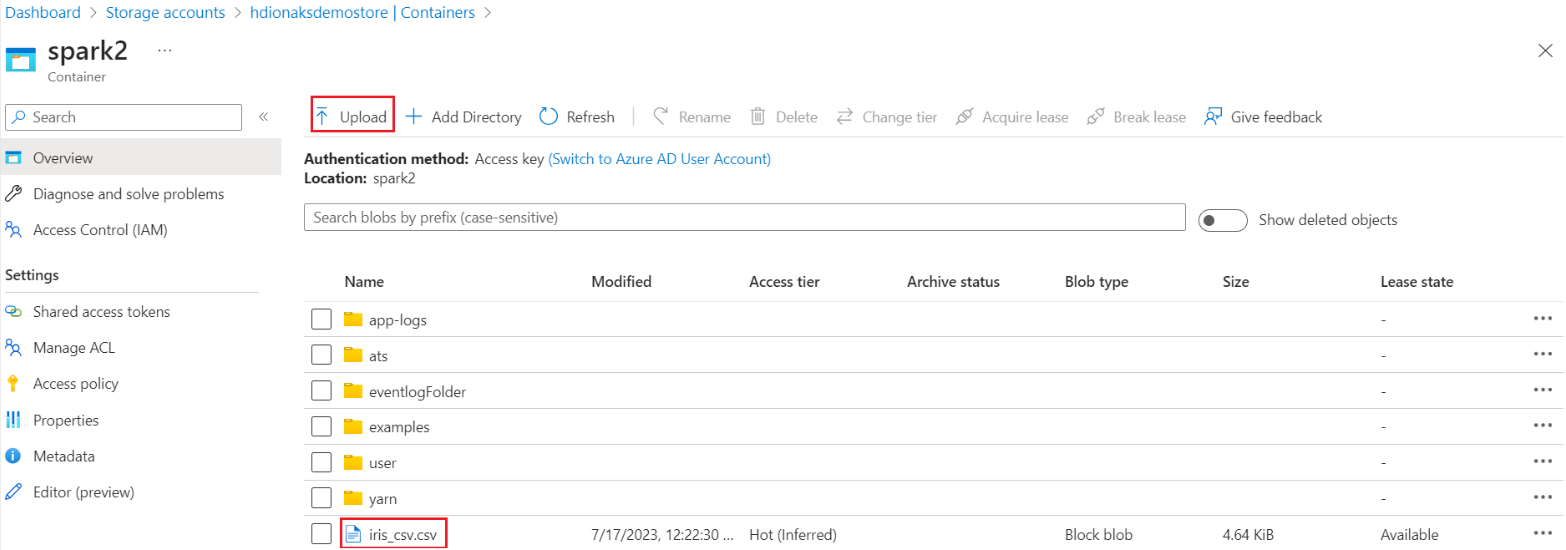
Navigeer naar de primaire basismap> van de HDI-opslagcontainer>>om het CSV-bestand te uploaden
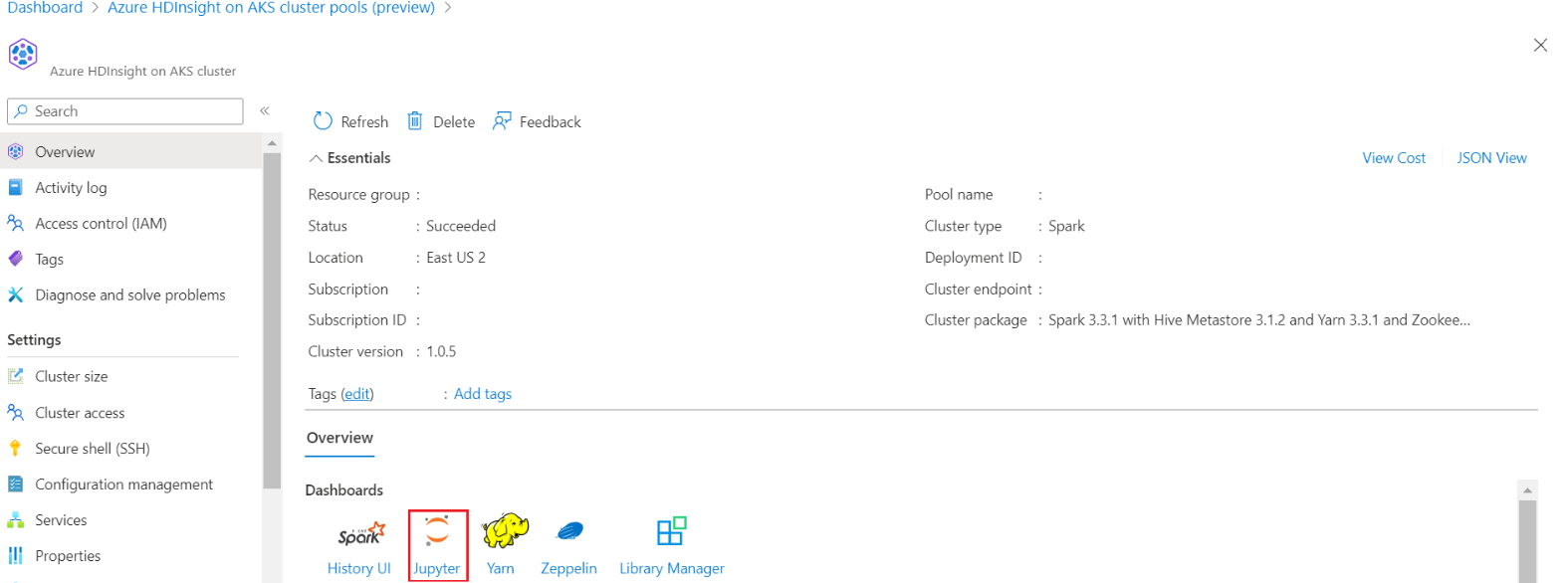
Meld u aan bij uw cluster en open Jupyter Notebook
Spark MLlib-bibliotheken importeren om de pijplijn te maken
import pyspark from pyspark.ml import Pipeline, PipelineModel from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import VectorAssembler, StringIndexer, IndexToString
Het CSV-bestand lezen in een Spark-gegevensframe
df = spark.read.("abfss:///iris_csv.csv",inferSchema=True,header=True)De gegevens splitsen voor training en testen
iris_train, iris_test = df.randomSplit([0.7, 0.3], seed=123)De pijplijn maken en het model trainen
assembler = VectorAssembler(inputCols=['sepallength', 'sepalwidth', 'petallength', 'petalwidth'],outputCol="features",handleInvalid="skip") indexer = StringIndexer(inputCol="class", outputCol="classIndex", handleInvalid="skip") classifier = LogisticRegression(featuresCol="features", labelCol="classIndex", maxIter=10, regParam=0.01) pipeline = Pipeline(stages=[assembler,indexer,classifier]) model = pipeline.fit(iris_train) # Create a test `dataframe` with predictions from the trained model test_model = model.transform(iris_test) # Taking an output from the test dataframe with predictions test_model.take(1)
De nauwkeurigheid van het model evalueren
import pyspark.ml.evaluation as ev evaluator = ev.MulticlassClassificationEvaluator(labelCol='classIndex') print(evaluator.evaluate(test_model,{evaluator.metricName: 'accuracy'}))



